Prawie rok temu opublikowałem moje rozwiązanie do stronicowania w SQL Server, które polegało na użyciu CTE do zlokalizowania tylko wartości kluczy dla danego zestawu wierszy, a następnie dołączeniu z powrotem z CTE do tabeli źródłowej w celu pobrania pozostałe kolumny tylko dla tej „strony” wierszy. Okazało się to najbardziej korzystne, gdy istniał wąski indeks, który wspierał kolejność żądaną przez użytkownika lub gdy kolejność była oparta na kluczu klastrowania, ale nawet działała trochę lepiej bez indeksu obsługującego wymagane sortowanie.
Od tego czasu zastanawiałem się, czy indeksy ColumnStore (zarówno klastrowane, jak i nieklastrowane) mogą pomóc w którymkolwiek z tych scenariuszy. TL;DR :Na podstawie tego eksperymentu w izolacji, odpowiedź na tytuł tego posta brzmi:zdecydowane NIE . Jeśli nie chcesz zobaczyć konfiguracji testu, kodu, planów wykonania ani wykresów, możesz przejść do mojego podsumowania, pamiętając, że moja analiza opiera się na bardzo konkretnym przypadku użycia.
Konfiguracja
Na nowej maszynie wirtualnej z zainstalowanym SQL Server 2016 CTP 3.2 (13.0.900.73) uruchomiłem mniej więcej taką samą konfigurację jak poprzednio, tylko tym razem z trzema tabelami. Po pierwsze, tradycyjna tabela z wąskim kluczem klastrowania i wieloma pomocniczymi indeksami:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Następnie tabela z klastrowanym indeksem ColumnStore:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
I na koniec tabela z nieklastrowym indeksem ColumnStore obejmującym wszystkie kolumny:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Zauważ, że dla obu tabel z indeksami ColumnStore pominąłem indeks, który obsługiwałby szybsze wyszukiwania w sortowaniu „Książka telefoniczna” (nazwisko, imię).
Dane testowe
Następnie wypełniłem pierwszą tabelę 1 000 000 losowych wierszy, w oparciu o skrypt, którego użyłem ponownie z poprzednich postów:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Następnie użyłem tej tabeli do wypełnienia pozostałych dwóch dokładnie tymi samymi danymi i odbudowałem wszystkie indeksy:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Całkowity rozmiar każdej tabeli:
| Tabela | Zarezerwowane | Dane | Indeks |
|---|---|---|---|
| Klienci | 463 200 KB | 154 344 KB | 308 576 KB |
| Customers_CCI | 117 280 KB | 30 288 KB | 86 536 KB |
| Klienci_NCCI | 349 480 KB | 154 344 KB | 194 976 KB |
I liczba wierszy/liczba stron odpowiednich indeksów (unikalny indeks w wiadomościach e-mail był dla mnie bardziej potrzebny do nadzorowania mojego własnego skryptu generowania danych niż cokolwiek innego):
| Tabela | Indeks | Wiersze | Strony |
|---|---|---|---|
| Klienci | PK_Klienci | 1.000.000 | 19 377 |
| Klienci | Książka telefoniczna_Klienci | 1.000.000 | 17 209 |
| Klienci | Aktywni_klienci | 808.012 | 13 977 |
| Customers_CCI | PK_CustomersCCI | 1.000.000 | 2737 |
| Customers_CCI | Klienci_CCI | 1.000.000 | 3826 |
| Klienci_NCCI | PK_CustomersNCCI | 1.000.000 | 19 377 |
| Klienci_NCCI | Klienci_NCCI | 1.000.000 | 16 971 |
Procedury
Następnie, aby sprawdzić, czy indeksy ColumnStore wtrącą się i poprawią którykolwiek ze scenariuszy, uruchomiłem ten sam zestaw zapytań co poprzednio, ale teraz dla wszystkich trzech tabel. Stałem się przynajmniej trochę mądrzejszy i stworzyłem dwie procedury składowane z dynamicznym SQL, aby zaakceptować źródło tabeli i porządek sortowania. (Dobrze zdaję sobie sprawę z wstrzykiwania SQL; nie robiłbym tego w środowisku produkcyjnym, gdyby te ciągi pochodziły od użytkownika końcowego, więc nie traktuj tego jako zalecenia, aby to zrobić. Ufam sobie wystarczająco w moim zamkniętym środowisku, które nie jest problemem dla tych testów.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Następnie stworzyłem trochę bardziej dynamicznego SQL, aby wygenerować wszystkie kombinacje wywołań, które musiałbym wykonać, aby wywołać zarówno starą, jak i nową procedurę składowaną, we wszystkich trzech żądanych porządkach sortowania i przy różnych numerach stron (aby zasymulować potrzebę stronę w pobliżu początku, środka i końca porządku sortowania). Abym mógł skopiować PRINT wyprowadzić i wkleić go do SQL Sentry Plan Explorer w celu uzyskania metryk środowiska uruchomieniowego, uruchomiłem tę partię dwa razy, raz z procedures CTE przy użyciu P_Old , a następnie ponownie za pomocą P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Dało to takie dane wyjściowe (w sumie 36 wywołań dla starej metody (P_Old ) i 36 wywołań nowej metody (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Wiem, to wszystko jest bardzo niewygodne; niedługo przejdziemy do puenty, obiecuję.
Wyniki
Wziąłem te dwa zestawy 36 instrukcji i rozpocząłem dwie nowe sesje w Eksploratorze planów, uruchamiając każdy zestaw wiele razy, aby upewnić się, że otrzymujemy dane z ciepłej pamięci podręcznej i pobieramy średnie (mógłbym również porównać zimną i ciepłą pamięć podręczną, ale myślę, że są wystarczająca ilość zmiennych tutaj).
Mogę Ci od razu powiedzieć kilka prostych faktów, nie pokazując nawet wykresów lub planów:
- W żadnym scenariuszu „stara” metoda nie pokonała nowej metody CTE Awansowałem w poprzednim poście, bez względu na to, jakie indeksy były obecne. Ułatwia to praktycznie zignorowanie połowy wyników, przynajmniej pod względem czasu trwania (który jest jednym z parametrów, na którym najbardziej zależy użytkownikom końcowym).
- Brak indeksu ColumnStore wypadł dobrze podczas stronicowania pod koniec wyniku – przynosiły korzyści tylko na początku i tylko w kilku przypadkach.
- Podczas sortowania według klucza podstawowego (zgrupowane lub nie), obecność indeksów ColumnStore nie pomogła – znowu pod względem czasu trwania.
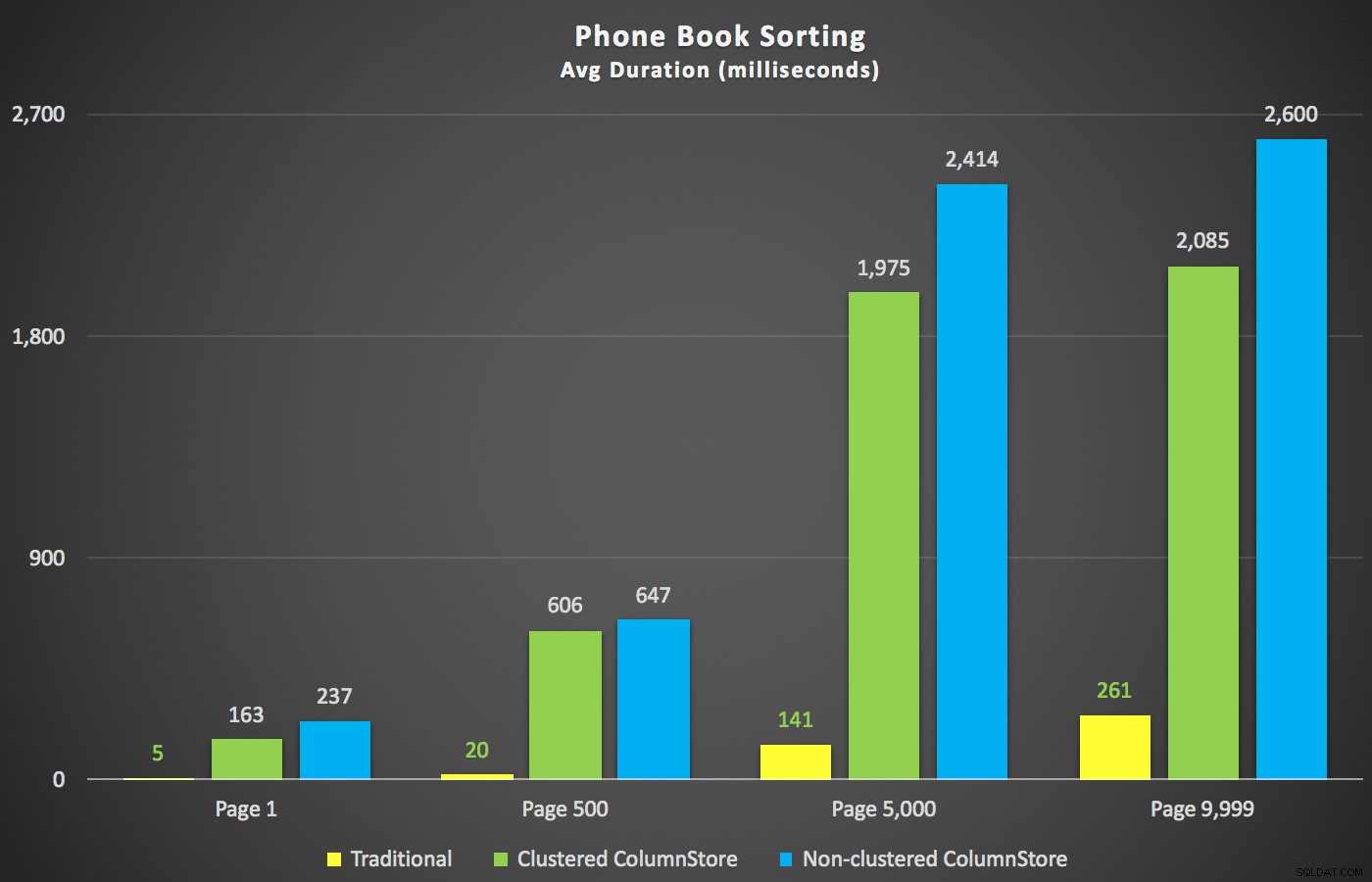
Pomijając te podsumowania, przyjrzyjmy się kilku przekrojom danych czasu trwania. Najpierw wyniki zapytania uporządkowane według imienia malejąco, potem e-mail, bez nadziei na użycie istniejącego indeksu do sortowania. Jak widać na wykresie, wydajność była niespójna – przy niższych numerach stron najlepiej radził sobie nieklastrowany ColumnStore; przy wyższych numerach stron zawsze wygrywał tradycyjny indeks:
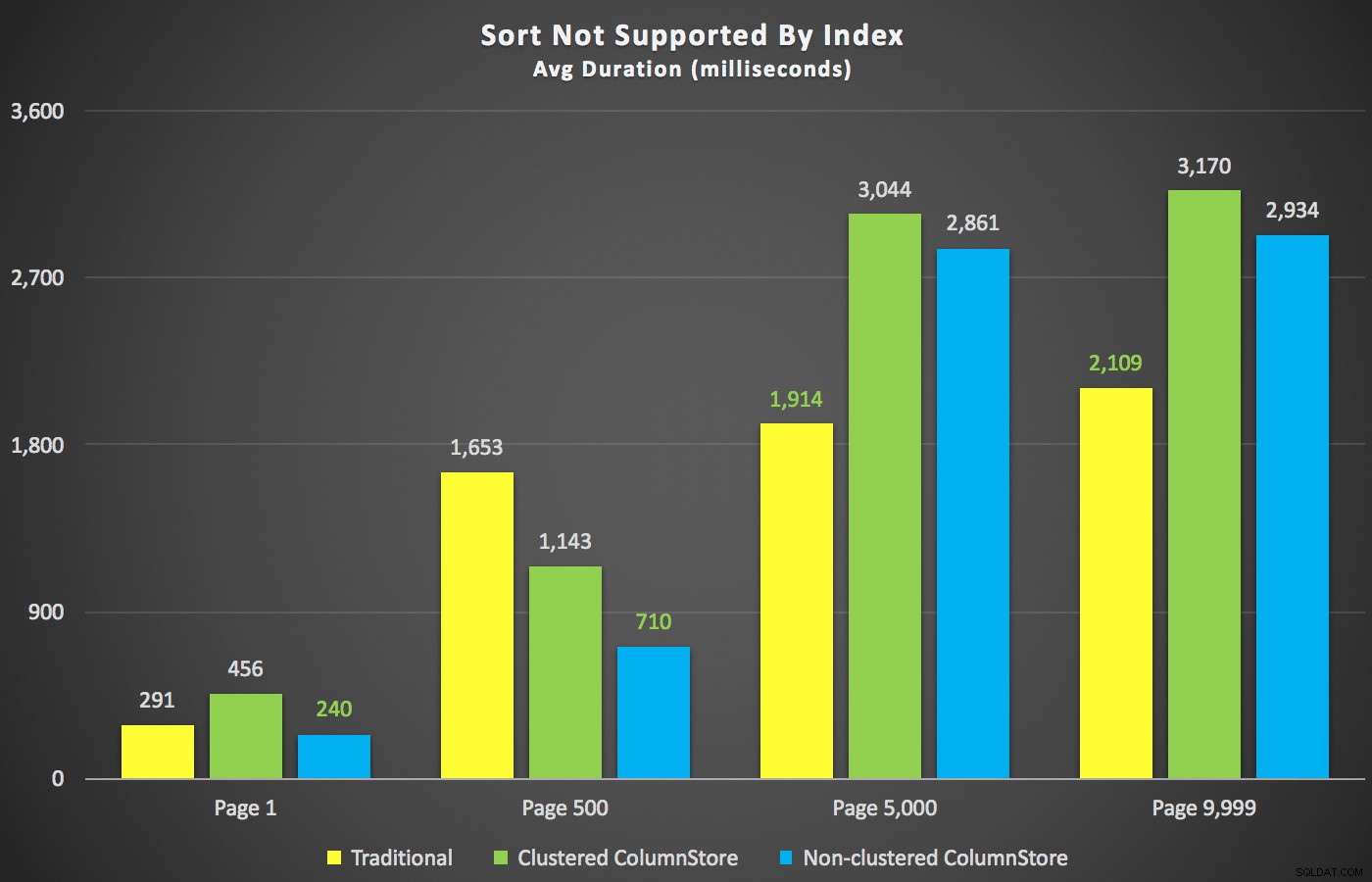 Czas trwania (milisekundy) dla różnych numerów stron i różnych typów indeksów
Czas trwania (milisekundy) dla różnych numerów stron i różnych typów indeksów
A potem trzy plany reprezentujące trzy różne typy indeksów (ze skalą szarości dodaną przez Photoshop w celu podkreślenia głównych różnic między planami):
 Plan dla tradycyjnego indeksu
Plan dla tradycyjnego indeksu
 Plan dla klastrowanego indeksu ColumnStore
Plan dla klastrowanego indeksu ColumnStore
 Plan dla nieklastrowanego indeksu ColumnStore
Plan dla nieklastrowanego indeksu ColumnStore
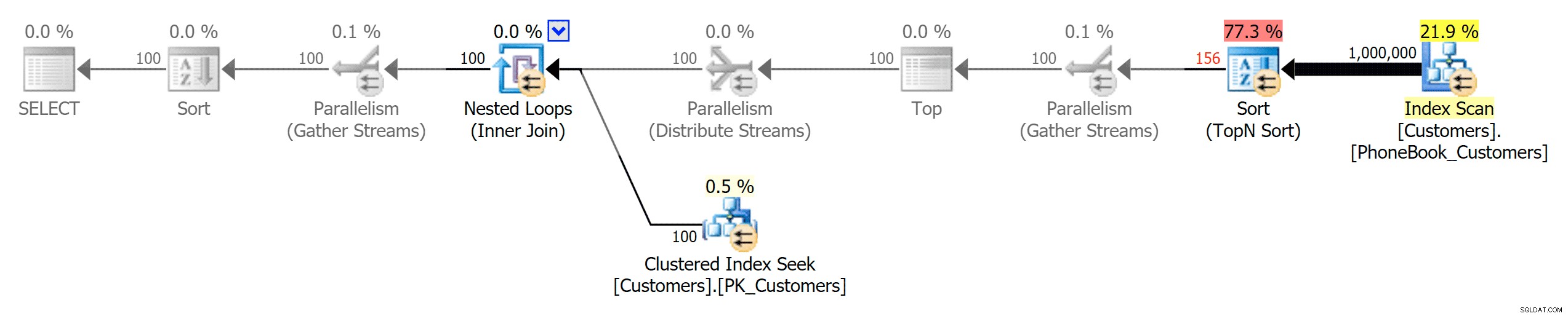
Scenariuszem, który mnie bardziej interesował, jeszcze zanim zacząłem testować, było podejście do sortowania książki telefonicznej (nazwisko, imię). W tym przypadku indeksy ColumnStore były w rzeczywistości dość szkodliwe dla wydajności wyniku:
Plany ColumnStore tutaj są zbliżone do lustrzanych odbić dwóch planów ColumnStore pokazanych powyżej dla nieobsługiwanego sortowania. Powód jest taki sam w obu przypadkach:drogie skany lub sortowanie z powodu braku indeksu wspomagającego sortowanie.
Więc następnie stworzyłem obsługę indeksów „PhoneBook” w tabelach z indeksami ColumnStore, aby sprawdzić, czy mogę namówić inny plan i/lub krótsze czasy wykonania w dowolnym z tych scenariuszy. Utworzyłem te dwa indeksy, a następnie ponownie przebudowałem:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Oto nowe czasy trwania:
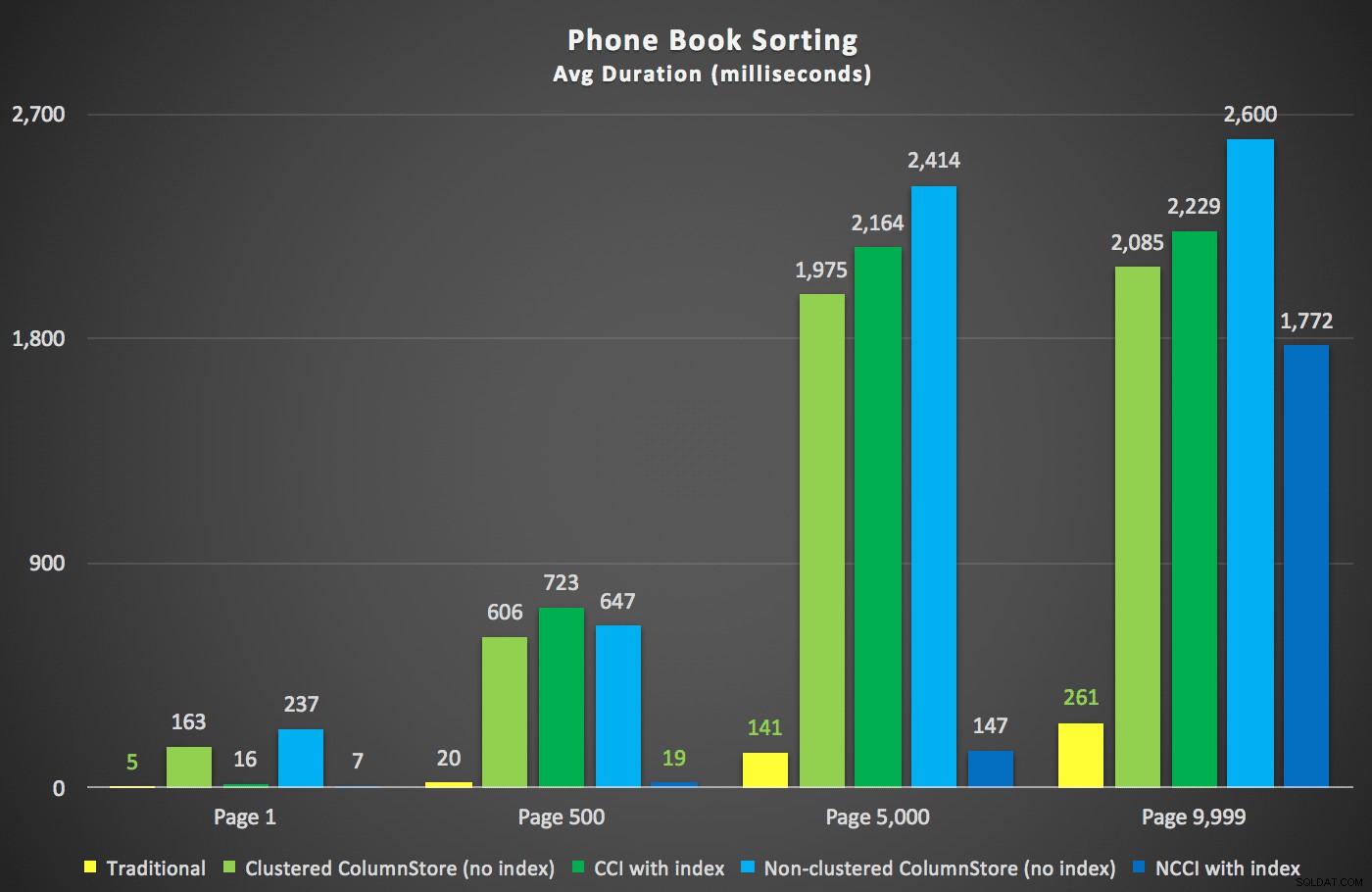
Najbardziej interesujące jest tutaj to, że teraz zapytanie stronicujące dotyczące tabeli z nieklastrowanym indeksem ColumnStore wydaje się dotrzymywać kroku tradycyjnemu indeksowi, dopóki nie wyjdziemy poza środek tabeli. Patrząc na plany, widzimy, że na stronie 5 000 zastosowano tradycyjne skanowanie indeksu, a indeks ColumnStore jest całkowicie ignorowany:
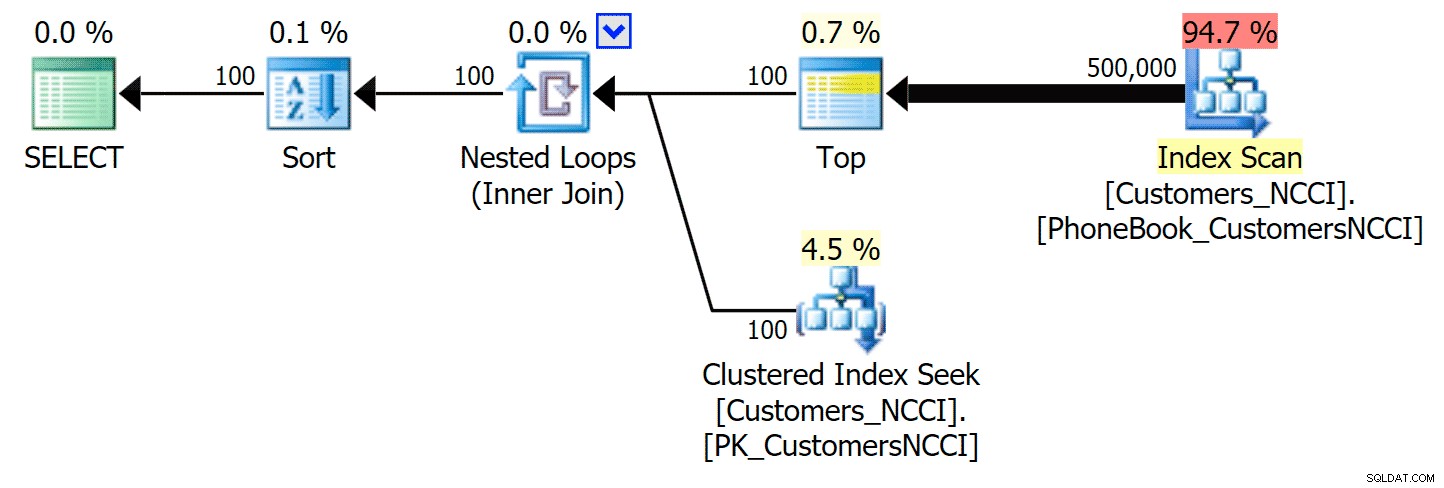 Plan Książka telefoniczna ignorujący nieklastrowany indeks ColumnStore
Plan Książka telefoniczna ignorujący nieklastrowany indeks ColumnStore
Jednak gdzieś pomiędzy środkiem 5000 stron a „końcem” tabeli na 9999 stronach optymalizator osiągnął rodzaj punktu krytycznego i – dla dokładnie tego samego zapytania – wybiera teraz skanowanie nieklastrowanego indeksu ColumnStore :
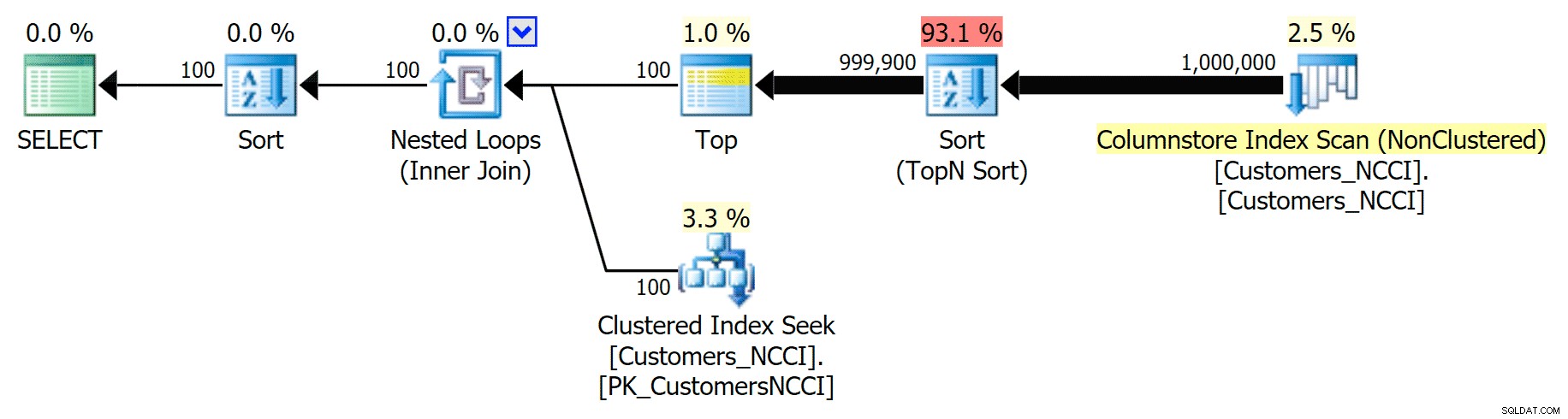 Wskazówki dotyczące planu książki telefonicznej i korzysta z indeksu ColumnStore
Wskazówki dotyczące planu książki telefonicznej i korzysta z indeksu ColumnStore
Okazuje się, że to niezbyt dobra decyzja optymalizatora, głównie ze względu na koszt operacji sortowania. Możesz zobaczyć, o ile lepszy będzie czas trwania, jeśli wskażesz zwykły indeks:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Daje to następujący plan, prawie identyczny z pierwszym planem powyżej (jednak nieco wyższy koszt skanowania, po prostu dlatego, że jest więcej wyników):
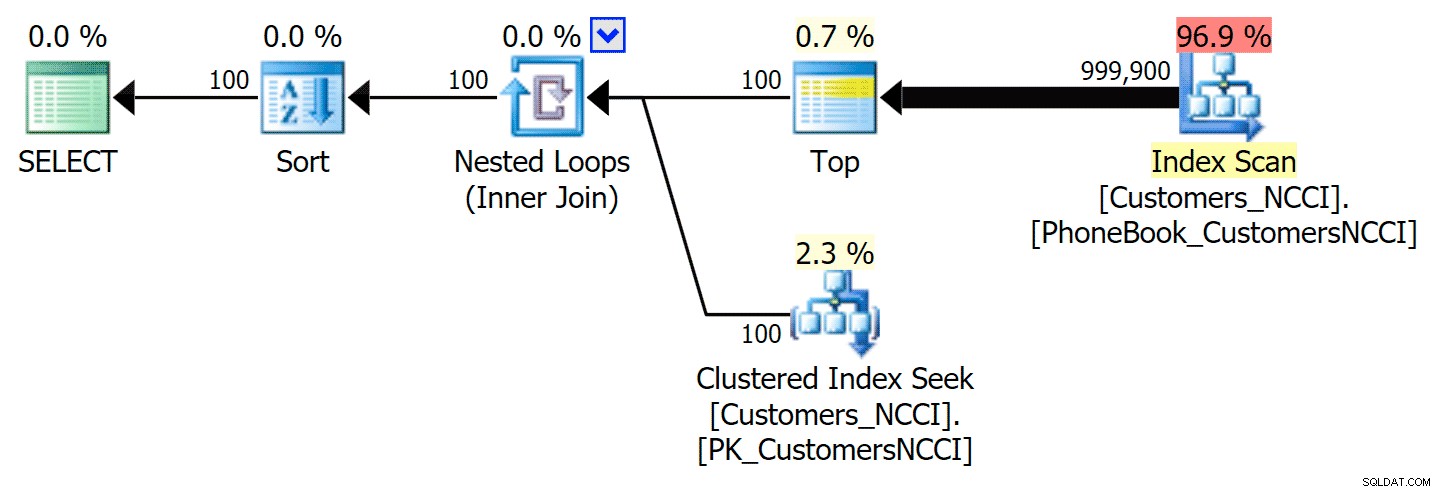 Plan książki telefonicznej z indeksem podpowiedzi
Plan książki telefonicznej z indeksem podpowiedzi
Możesz osiągnąć to samo, używając OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) zamiast wyraźnej wskazówki dotyczącej indeksu. Pamiętaj tylko, że jest to równoznaczne z brakiem indeksu ColumnStore.
Wniosek
Chociaż istnieje kilka skrajnych przypadków powyżej, w których indeks ColumnStore może (ledwo) się opłacać, nie wydaje mi się, aby były one dobrze dopasowane do tego konkretnego scenariusza paginacji. Myślę, że co najważniejsze, chociaż ColumnStore wykazuje znaczną oszczędność miejsca dzięki kompresji, wydajność środowiska wykonawczego nie jest fantastyczna ze względu na wymagania dotyczące sortowania (nawet jeśli szacuje się, że te sortowania działają w trybie wsadowym, nowa optymalizacja dla SQL Server 2016).
Ogólnie rzecz biorąc, może to oznaczać znacznie więcej czasu poświęconego na badania i testy; w oparciu o poprzednie artykuły, chciałem zmienić jak najmniej. Na przykład chciałbym znaleźć ten punkt krytyczny i chciałbym również przyznać, że nie są to testy na dużą skalę (ze względu na rozmiar maszyny wirtualnej i ograniczenia pamięci) i że zostawiłem ci zgadywanie o wielu metryki czasu wykonywania (głównie dla zwięzłości, ale nie wiem, czy wykres odczytów, które nie zawsze są proporcjonalne do czasu trwania, naprawdę by ci powiedział). Testy te zakładają również luksusy dysków SSD, wystarczającą ilość pamięci, zawsze ciepłą pamięć podręczną i środowisko jednego użytkownika. Naprawdę chciałbym przeprowadzić większą liczbę testów na większej ilości danych, na większych serwerach z wolniejszymi dyskami i instancjami z mniejszą ilością pamięci, cały czas z symulowaną współbieżnością.
To powiedziawszy, może to być również scenariusz, którego ColumnStore nie zaprojektowano, aby pomóc rozwiązać w pierwszej kolejności, ponieważ bazowe rozwiązanie z tradycyjnymi indeksami jest już dość wydajne w wyciąganiu wąskiego zestawu wierszy – nie dokładnie w sterówce ColumnStore. Być może inną zmienną, którą należy dodać do macierzy, jest rozmiar strony – wszystkie powyższe testy pobierają 100 wierszy na raz, ale co, jeśli szukamy 10 000 lub 100 000 wierszy na raz, niezależnie od tego, jak duża jest tabela pod spodem?
Czy masz sytuację, w której obciążenie OLTP zostało ulepszone po prostu przez dodanie indeksów ColumnStore? Wiem, że są one przeznaczone do obciążeń w stylu hurtowni danych, ale jeśli zauważyłeś korzyści gdzie indziej, chciałbym usłyszeć o twoim scenariuszu i zobaczyć, czy mogę włączyć jakieś wyróżniki do mojego stanowiska testowego.