W zeszłym tygodniu opublikowałem post o nazwie #BackToBasics:DATEFROMPARTS() , gdzie pokazałem, jak używać tej funkcji 2012+ do czystszych, możliwych do sargowania zapytań dotyczących zakresu dat. Użyłem go, aby zademonstrować, że jeśli używasz otwartego predykatu daty i masz indeks w odpowiedniej kolumnie daty/godziny, możesz uzyskać znacznie lepsze wykorzystanie indeksu i niższe I/O (lub, w najgorszym przypadku , to samo, jeśli z jakiegoś powodu nie można użyć wyszukiwania lub jeśli nie istnieje odpowiedni indeks):
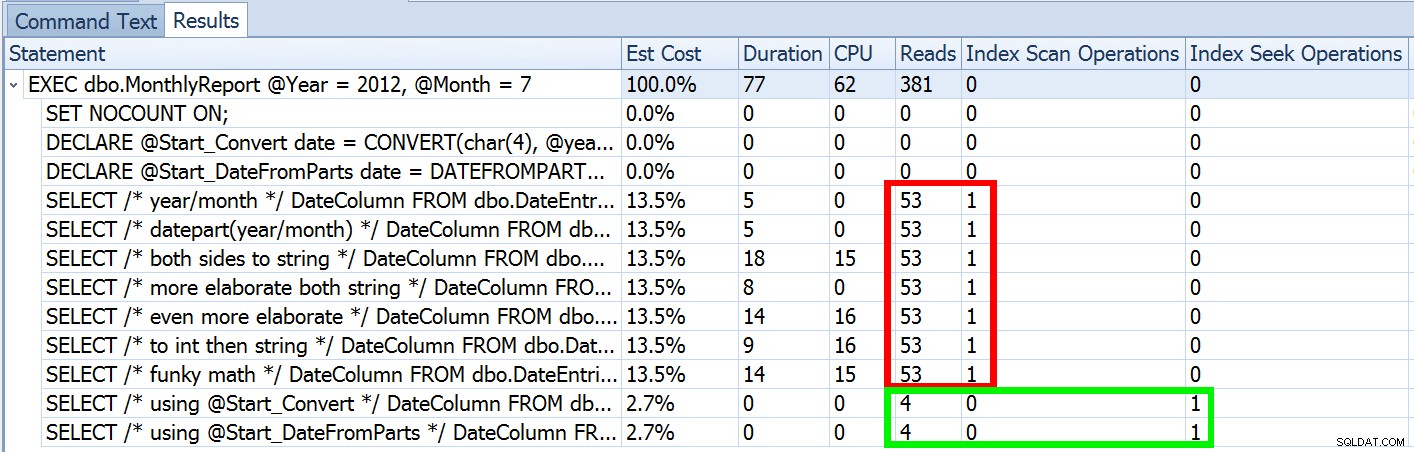
Ale to tylko część historii (a żeby było jasne, DATEFROMPARTS() nie jest technicznie wymagane, aby uzyskać seek, w tym przypadku jest po prostu czystsze). Jeśli trochę pomniejszymy, zauważymy, że nasze szacunki są dalekie od dokładności, złożoność, której nie chciałem wprowadzać w poprzednim poście:
Nie jest to rzadkie zarówno w przypadku predykatów nierówności, jak i wymuszonych skanów. I oczywiście, czy sugerowana przeze mnie metoda nie dawałaby najbardziej niedokładnych statystyk? Oto podstawowe podejście (możesz uzyskać schemat tabeli, indeksy i przykładowe dane z mojego poprzedniego postu):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Teraz niedokładne szacunki nie zawsze będą problemem, ale mogą powodować problemy z nieefektywnymi wyborami planów na dwóch skrajnościach. Pojedynczy plan może nie być optymalny, gdy wybrany zakres da bardzo mały lub bardzo duży procent tabeli lub indeksu, a to może być bardzo trudne do przewidzenia przez SQL Server, kiedy rozkład danych jest nierównomierny. Joseph Sack opisał bardziej typowe rzeczy, które mogą wpłynąć na złe szacunki w swoim poście:„Dziesięć typowych zagrożeń dla jakości planu wykonania”
„[…] złe oszacowania wierszy mogą wpływać na różne decyzje, w tym wybór indeksu, operacje wyszukiwania i skanowania, wykonywanie równoległe lub szeregowe, wybór algorytmu łączenia, wybór łączenia fizycznego i zewnętrznego (np. kompilacja lub sonda), generowanie bufora, wyszukiwania zakładek a pełny dostęp do klastrów lub tabel sterty, wybór agregacji strumienia lub skrótu oraz to, czy modyfikacja danych korzysta z szerokiego lub wąskiego planu”.
Są też inne, takie jak granty pamięci, które są zbyt duże lub zbyt małe. Następnie opisuje niektóre z najczęstszych przyczyn złych szacunków, ale w tym przypadku brakuje na jego liście głównej przyczyny:przewidywań. Ponieważ używamy zmiennej lokalnej do zmiany przychodzącego int parametry do jednej lokalnej date zmienna, SQL Server nie wie, jaka będzie wartość, więc wykonuje standardowe domysły liczności na podstawie całej tabeli.
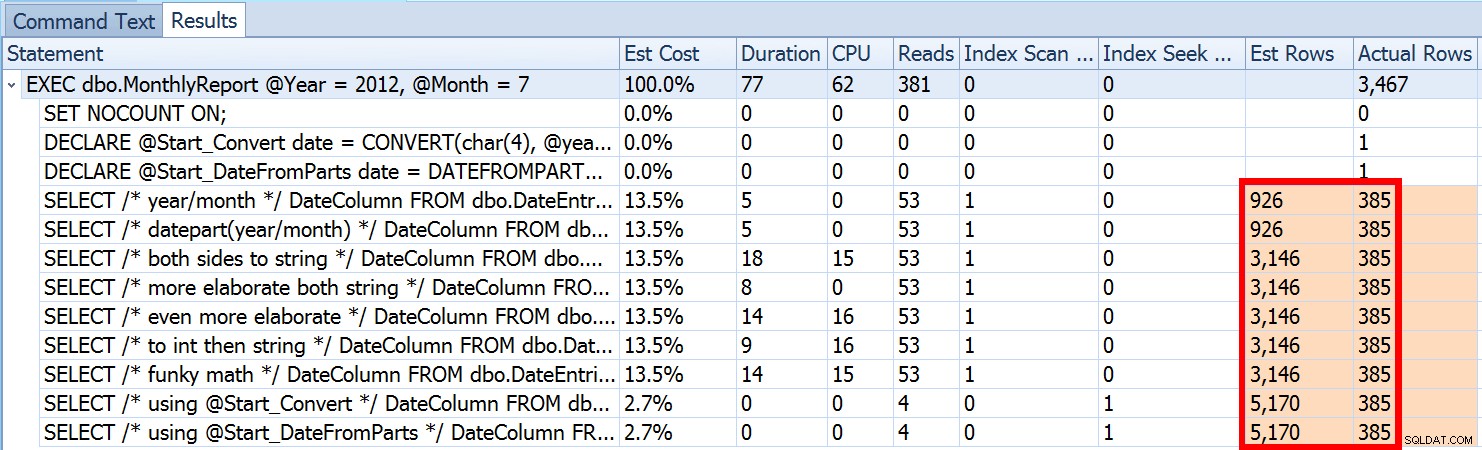
Widzieliśmy powyżej, że oszacowanie dla sugerowanego przeze mnie podejścia to 5170 wierszy. Teraz wiemy, że z predykatem nierówności, a SQL Server nie znając wartości parametrów, zgadnie 30% tabeli. 31,645 * 0.3 nie wynosi 5170. Podobnie 31,465 * 0.3 * 0.3 , gdy pamiętamy, że w rzeczywistości istnieją dwa predykaty działające przeciwko tej samej kolumnie. Skąd więc bierze się ta wartość 5170?
Jak opisuje Paul White w swoim poście „Oszacowanie kardynalności dla wielu predykatów”, nowy estymator kardynalności w SQL Server 2014 używa wykładniczego wycofywania, więc mnoży liczbę wierszy w tabeli (31 465) przez selektywność pierwszego predykatu (0,3) , a następnie mnoży to przez pierwiastek kwadratowy selektywności drugiego predykatu (~0,547723).
31 645 * (0,3) * PIERWIASTEK (0,3) ~=5 170,227Tak więc teraz możemy zobaczyć, gdzie SQL Server wpadł na swoje oszacowanie; jakie są metody, których możemy użyć, aby coś z tym zrobić?
- Przekaż parametry daty. Jeśli to możliwe, możesz zmienić aplikację tak, aby przekazywała odpowiednie parametry daty zamiast oddzielnych parametrów całkowitych.
- Użyj procedury opakowania. Odmianą metody nr 1 – na przykład, jeśli nie możesz zmienić aplikacji – byłoby utworzenie drugiej procedury składowanej, która akceptuje skonstruowane parametry daty z pierwszej.
- Użyj
OPTION (RECOMPILE). Przy niewielkim koszcie kompilacji za każdym razem, gdy zapytanie jest wykonywane, zmusza to SQL Server do optymalizacji na podstawie prezentowanych wartości za każdym razem, zamiast optymalizacji pojedynczego planu dla nieznanych, pierwszych lub średnich wartości parametrów. (Aby zapoznać się z dokładnym omówieniem tego tematu, zobacz „Parameter Sniffing, Embedding and the RECOMPILE Options” Paula White'a."
- Użyj dynamicznego SQL. Mając dynamiczny SQL zaakceptuj skonstruowaną
datezmienna wymusza właściwą parametryzację (tak jakbyś wywołał procedurę składowaną zdateparametru), ale jest trochę brzydkie i trudniejsze w utrzymaniu.
- Bałagan z podpowiedziami i flagami śledzenia. Paul White mówi o niektórych z nich we wspomnianym poście.
Nie zamierzam sugerować, że jest to wyczerpująca lista i nie zamierzam powtarzać rad Paula dotyczących podpowiedzi lub znaczników śledzenia, więc skupię się tylko na pokazaniu, w jaki sposób pierwsze cztery podejścia mogą złagodzić problem ze złymi szacunkami .
1. Parametry daty
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Procedura owijania
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. OPCJA (REKOMPILUJ)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. Dynamiczny SQL
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Testy
Mając wdrożone cztery zestawy procedur, łatwo było skonstruować testy, które pokazałyby mi plany i szacunki opracowane przez SQL Server. Ponieważ niektóre miesiące są bardziej zajęte niż inne, wybrałem trzy różne miesiące i wykonałem je wiele razy.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Wynik? Każdy plan daje takie samo wyszukiwanie indeksu, ale szacunki są poprawne tylko we wszystkich trzech zakresach dat w OPTION (RECOMPILE) wersja. Reszta nadal korzysta z szacunków pochodzących z pierwszego zestawu parametrów (lipiec 2012 r.), więc chociaż uzyskują lepsze oszacowania dla pierwszego wykonanie, to oszacowanie niekoniecznie będzie lepsze dla kolejnego egzekucje z różnymi parametrami (klasyczny, podręcznikowy przypadek podsłuchiwania parametrów):
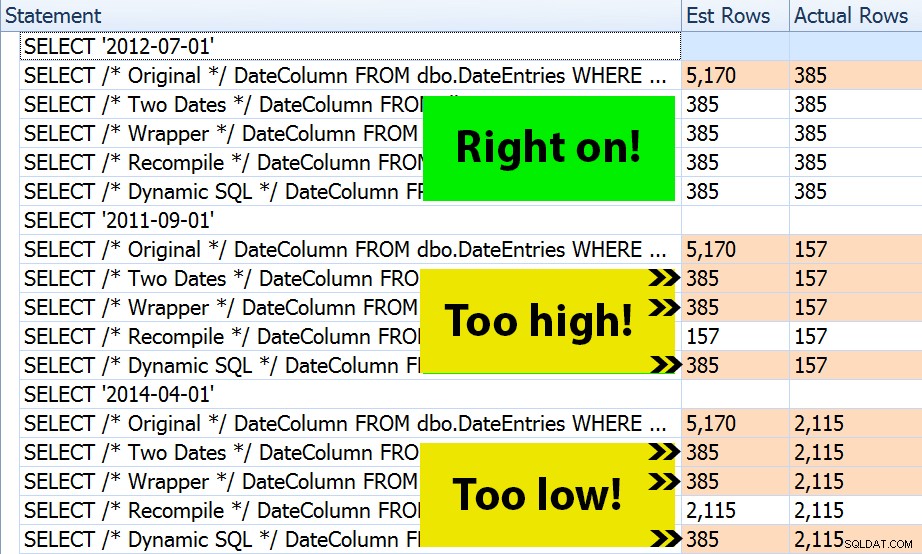
Zauważ, że powyższe nie jest *dokładnym* wynikiem programu SQL Sentry Plan Explorer — na przykład usunąłem wiersze drzewa instrukcji, które pokazywały zewnętrzne wywołania procedur składowanych i deklaracje parametrów.
Od Ciebie zależy, czy taktyka kompilacji za każdym razem jest dla Ciebie najlepsza, czy też musisz coś „naprawić” w pierwszej kolejności. Tutaj skończyliśmy z tymi samymi planami i bez zauważalnych różnic w metrykach wydajności w czasie wykonywania. Jednak w przypadku większych tabel, z bardziej skośnym rozkładem danych i większymi rozbieżnościami w wartościach predykatów (np. rozważ raport, który może obejmować tydzień, rok i wszystko pomiędzy), może to być warte zbadania. I zauważ, że możesz tutaj łączyć metody – na przykład możesz przełączyć się na odpowiednie parametry daty *i* dodać OPTION (RECOMPILE) , jeśli chcesz.
Wniosek
W tym konkretnym przypadku, który jest celowym uproszczeniem, wysiłek związany z uzyskaniem poprawnych szacunków tak naprawdę się nie opłacił – nie otrzymaliśmy innego planu, a wydajność w czasie wykonywania była taka sama. Z pewnością istnieją jednak inne przypadki, w których będzie to miało znaczenie, i ważne jest, aby rozpoznać rozbieżność w szacunkach i określić, czy może to stać się problemem, gdy twoje dane rosną i/lub twoja dystrybucja się zniekształca. Niestety, nie ma czarno-białej odpowiedzi, ponieważ wiele zmiennych wpływa na to, czy narzut kompilacji jest uzasadniony – tak jak w wielu scenariuszach, IT DEPENDS™ …