Ogólnie rzecz biorąc, najlepszy rodzaj sortowania to taki, którego całkowicie się unika. Dzięki starannemu indeksowaniu i czasami kreatywnemu pisaniu zapytań, często możemy wyeliminować potrzebę stosowania operatora Sort z planów wykonania. Tam, gdzie dane do sortowania są duże, unikanie tego rodzaju sortowania może przynieść bardzo znaczną poprawę wydajności.
Drugim najlepszym rodzajem sortowania jest ten, którego nie możemy uniknąć, ale który rezerwuje odpowiednią ilość pamięci i wykorzystuje ją w całości lub w większości do zrobienia czegoś wartościowego. Być wartym może przybierać różne formy. Czasami sortowanie może więcej niż zapłacić za siebie, umożliwiając późniejszą operację, która działa znacznie wydajniej na posortowanych danych wejściowych. Innym razem sortowanie jest po prostu konieczne, a my musimy po prostu uczynić go tak wydajnym, jak to tylko możliwe.
Następnie przychodzą sorty, których zwykle chcemy uniknąć:te, które rezerwują znacznie więcej pamięci niż potrzebują, i te, które rezerwują zbyt mało. Na tym drugim przypadku skupia się większość ludzi. Przy niewystarczającej ilości zarezerwowanej (lub dostępnej) pamięci do ukończenia wymaganej operacji sortowania w pamięci, operator Sort, z kilkoma wyjątkami, rozleje wiersze danych do tempdb . W rzeczywistości prawie zawsze oznacza to zapisywanie stron sortowania do pamięci fizycznej (i oczywiście odczytywanie ich później).
We współczesnych wersjach SQL Server rozlane sortowanie powoduje wyświetlenie ikony ostrzeżenia w planach powykonawczych, które mogą zawierać szczegóły dotyczące ilości rozlanych danych, liczby zaangażowanych wątków i poziomu rozlania.
Tło:Poziomy wycieków
Rozważ zadanie sortowania 4000 MB danych, gdy mamy tylko 500 MB dostępnej pamięci. Oczywiście nie możemy od razu posortować całego zestawu w pamięci, ale możemy rozbić zadanie:
Najpierw odczytujemy 500 MB danych, sortujemy zestaw w pamięci, a następnie zapisujemy wynik na dysku. Wykonanie tego w sumie 8 razy zajmuje całe 4000 MB danych wejściowych, co daje 8 zestawów posortowanych danych o rozmiarze 500 MB. Drugim krokiem jest wykonanie 8-kierunkowego scalania posortowanych zestawów danych. Zwróć uwagę, że scal jest wymagane, a nie proste łączenie zestawów, ponieważ dane są gwarantowane tylko zgodnie z wymaganiami w ramach określonego zestawu 500 MB na etapie pośrednim.
W zasadzie moglibyśmy czytać i scalać po jednym wierszu na raz z każdego z ośmiu przebiegów sortowania, ale nie byłoby to zbyt wydajne. Zamiast tego czytamy pierwszą część każdego sortowania z powrotem do pamięci, powiedzmy 60 MB. Zużywa to 8 x 60 MB =480 MB z 500 MB, które mamy do dyspozycji. Następnie możemy przez jakiś czas sprawnie wykonać 8-kierunkowe scalanie w pamięci, buforując ostatecznie posortowane dane wyjściowe przy wciąż dostępnej pamięci 20 MB. Gdy każdy z buforów pamięci sortowania jest pusty, czytamy nową sekcję tego sortowania w pamięci. Gdy wszystkie przebiegi sortowania zostaną wykorzystane, sortowanie jest zakończone.
Istnieje kilka dodatkowych szczegółów i optymalizacji, które możemy uwzględnić, ale jest to podstawowy zarys wycieku poziomu 1, znanego również jako wyciek jednoprzebiegowy. Jedno dodatkowe przejście przez dane jest wymagane do uzyskania ostatecznego posortowania danych wyjściowych.
Teraz scalanie n-drożne mogłoby teoretycznie pomieścić dowolny rozmiar, w dowolnej ilości pamięci, po prostu zwiększając liczbę pośrednich, posortowanych lokalnie zbiorów. Problem polega na tym, że wraz ze wzrostem „n” czytamy i zapisujemy mniejsze porcje danych. Na przykład posortowanie 400 GB danych w 500 MB pamięci oznaczałoby coś w rodzaju scalania na 800 sposobów, przy czym tylko około 0,6 MB z każdego posortowanego zestawu pośredniego w pamięci w dowolnym momencie (800 x 0,6 MB =480 MB, pozostawiając trochę miejsca na bufor wyjściowy).
Aby obejść ten problem, można użyć wielu przebiegów scalania. Ogólną ideą jest stopniowe łączenie małych fragmentów w większe, aż będziemy mogli wydajnie wytworzyć ostatecznie posortowany strumień wyjściowy. W tym przykładzie może to oznaczać łączenie 40 z 800 zestawów posortowanych przy pierwszym przebiegu, co daje 20 większych fragmentów, które można następnie ponownie scalić w celu utworzenia danych wyjściowych. Przy dwóch dodatkowych przejściach nad danymi byłby to wyciek poziomu 2 i tak dalej. Na szczęście liniowy wzrost poziomu rozlania umożliwia wykładniczy wzrost rozmiaru sortowania, więc poziomy rozlania głębokiego sortowania rzadko są konieczne.
Wyciek „Poziomu 15 000”
W tym momencie możesz się zastanawiać, jaka kombinacja niewielkiego przydziału pamięci i ogromnego rozmiaru danych może spowodować rozlanie sortowania na poziomie 15 000. Próbujesz posortować cały Internet w 1 MB pamięci? Możliwe, ale jest to zbyt trudne do demonstracji. Szczerze mówiąc, nie mam pojęcia, czy naprawdę wysoki poziom wycieku jest możliwy w SQL Server. Celem tutaj (oszustwo, na pewno) jest skłonienie SQL Server do raportowania rozlanie na poziomie 15 000.
Kluczowym składnikiem jest partycjonowanie. Od SQL Server 2012 dopuszczono (wygodne) maksymalnie 15 000 partycji na obiekt (obsługa 15 000 partycji jest również dostępna w 2008 SP2 i 2008 R2 SP1, ale musisz włączyć ją ręcznie dla każdej bazy danych i mieć świadomość wszystkich zastrzeżenia).
Pierwszą rzeczą, której będziemy potrzebować, jest funkcja partycji 15 000 elementów i powiązany schemat partycji. Aby uniknąć naprawdę ogromnego bloku kodu w wierszu, poniższy skrypt używa dynamicznego SQL do generowania wymaganych instrukcji:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Skrypt jest dość łatwy do zmodyfikowania do niższej liczby w przypadku problemów z konfiguracją 15 000 partycji (szczególnie z punktu widzenia pamięci, jak zobaczymy wkrótce). Kolejne kroki to utworzenie normalnej (nie podzielonej na partycje) tabeli sterty z pojedynczą kolumną liczb całkowitych, a następnie wypełnienie jej liczbami całkowitymi od 1 do 15 000 włącznie:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; To powinno zakończyć się za około 100 ms. Jeśli masz dostępną tabelę liczb, możesz jej użyć, aby uzyskać bardziej oparte na zestawach doświadczenie. Sposób wypełnienia tabeli bazowej nie ma znaczenia. Aby uzyskać rozlew na 15 000 poziomów, wystarczy teraz utworzyć podzielony na partycje indeks klastrowy w tabeli:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Czas wykonania zależy w dużej mierze od używanego systemu pamięci masowej. Na moim laptopie, używając dość typowego konsumenckiego dysku SSD sprzed kilku lat, zajmuje to około 20 sekund, co jest dość znaczące, biorąc pod uwagę, że w sumie mamy do czynienia tylko z 15 000 wierszy. Na dość niskiej maszynie wirtualnej platformy Azure z dość straszną wydajnością we/wy ten sam test zajął około 20 minut.
Analiza
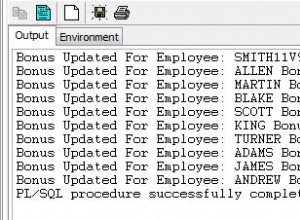
Plan wykonania budowy indeksu to:
Skanowanie tabeli odczytuje 15 000 wierszy z naszej tabeli sterty. Compute Scalar oblicza numer partycji indeksu docelowego dla każdego wiersza za pomocą funkcji wewnętrznej RangePartitionNew() . Sortowanie to najciekawsza część planu, więc przyjrzymy się jej bardziej szczegółowo.
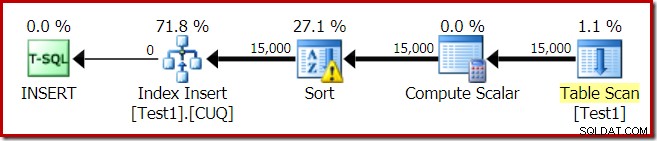
Najpierw ostrzeżenie dotyczące sortowania, wyświetlane w Eksploratorze planów:

Podobne ostrzeżenie z SSMS (pobrane z innego uruchomienia skryptu):
Pierwszą rzeczą, na którą należy zwrócić uwagę, jest raport o poziomie rozlania rzędu 15 000, zgodnie z obietnicą. Nie jest to do końca dokładne, ale szczegóły są dość interesujące. Sortowanie w tym planie ma Partition ID właściwość, która normalnie nie występuje:
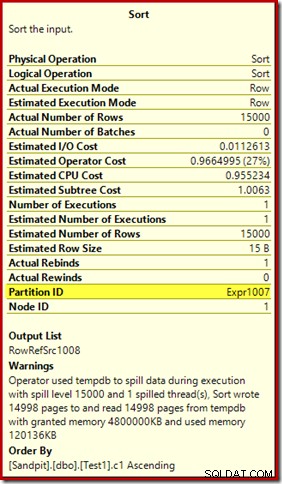
Ta właściwość jest równa definicji funkcji partycjonowania wewnętrznego w obliczeniach skalarnych.
To jest kompilacja indeksu niewyrównanego , ponieważ źródło i miejsce docelowe mają różne układy partycjonowania. W tym przypadku ta różnica powstaje, ponieważ tabela sterty źródłowej nie jest partycjonowana, ale indeks docelowy jest. W rezultacie w czasie wykonywania tworzonych jest 15 000 oddzielnych sortowań:jeden na niepustą partycję docelową. Każdy z tych rodzajów rozlewa się do poziomu 1, a SQL Server sumuje wszystkie te rozlania, aby uzyskać ostateczny poziom rozlania sortowania wynoszący 15 000.
15 000 oddzielnych sortowań wyjaśnia duży przydział pamięci. Każda instancja sortowania ma minimalny rozmiar 40 stron, czyli 40 x 8KB =320KB. 15 000 sortowań wymaga zatem co najmniej 15 000 x 320 KB =4 800 000 KB pamięci. To tylko mniej niż 4,6 GB pamięci RAM zarezerwowanej wyłącznie dla zapytania sortującego 15 000 wierszy zawierających pojedynczą kolumnę liczb całkowitych. I każdy rodzaj rozlewa się na dysk, mimo że otrzymuje tylko jeden rząd! Jeśli do kompilacji indeksu użyto równoległości, przyznanie pamięci może być dodatkowo zawyżone o liczbę wątków. Należy również zauważyć, że pojedynczy wiersz jest zapisany na stronie, co wyjaśnia liczbę stron zapisanych i odczytanych z tempdb. Wygląda na to, że istnieje sytuacja wyścigu, co oznacza, że zgłoszona liczba stron często wynosi kilka mniej niż 15 000.
Ten przykład oczywiście odzwierciedla przypadek brzegowy, ale nadal trudno jest zrozumieć, dlaczego każde sortowanie rozlewa jeden wiersz zamiast sortować w pamięci, którą otrzymał. Być może z jakiegoś powodu jest to zgodne z projektem, a może to po prostu błąd. Niezależnie od przypadku, nadal jest dość zabawne, gdy widzimy, że kilkaset KB danych zajmuje tak dużo czasu, z 4,6 GB przyznanej pamięci i 15 000 poziomów rozlewu. Chyba że spotkasz go w środowisku produkcyjnym. W każdym razie jest to coś, o czym należy pamiętać.
Wprowadzający w błąd raport o rozlaniu 15 000 poziomów w dużej mierze sprowadza się do ograniczeń reprezentacji w wynikach planu pokazu. Fundamentalną kwestią jest coś, co pojawia się w wielu miejscach, w których występują powtarzające się akcje, na przykład po wewnętrznej stronie zagnieżdżonych pętli. Z pewnością przydałoby się w takich przypadkach zobaczyć dokładniejszy podział zamiast ogólnej sumy. Z biegiem czasu ten obszar nieco się poprawił, więc teraz mamy więcej informacji o planie na wątek lub na partycję dla niektórych operacji. Przed nami jeszcze długa droga.
Nadal mniej niż pomocne jest to, że 15 000 oddzielnych wycieków poziomu 1 jest zgłaszanych tutaj jako pojedynczy wyciek 15 000 poziomu.
Odmiany testowe
W tym artykule chodzi bardziej o podkreślenie ograniczeń informacji o planie i potencjalnej niskiej wydajności, gdy używana jest ekstremalna liczba partycji, niż o to, aby konkretna przykładowa operacja była bardziej wydajna, ale jest też kilka interesujących odmian, którym również chcę się przyjrzeć .
Online, Sortuj w tempdb
Wykonywanie tej samej operacji tworzenia indeksu partycjonowanego z ONLINE = ON, SORT_IN_TEMPDB = ON nie cierpi z powodu tego samego ogromnego przyrostu pamięci i rozlewania:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Pamiętaj, że używając ONLINE samo w sobie nie wystarczy. W rzeczywistości daje to ten sam plan, co poprzednio, z tymi samymi problemami, plus dodatkowy narzut na budowanie każdej partycji indeksu online. Dla mnie oznacza to czas wykonania grubo ponad minutę. Bóg wie, ile czasu zajęłoby to niskiej specyfikacji instancji Azure z okropną wydajnością we/wy.
W każdym razie plan wykonania z ONLINE = ON, SORT_IN_TEMPDB = ON jest:

Sortowanie jest wykonywane przed obliczeniem numeru partycji docelowej. Nie ma właściwości Partition ID, więc jest to zwykłe sortowanie. Cała operacja trwa około dziesięciu sekund (jest jeszcze wiele partycji do utworzenia). Rezerwuje mniej niż 3 MB pamięci i wykorzystuje maksymalnie 816 KB. Spora poprawa w porównaniu z 4,6 GB i 15 000 wycieków.
Najpierw indeks, potem dane
Podobne wyniki można uzyskać, zapisując najpierw dane do tabeli sterty:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Następnie utwórz pustą podzieloną na partycje tabelę klastrową i wstaw dane ze sterty:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Zajmuje to około dziesięciu sekund, z przyznaniem 2 MB pamięci i bez rozlewania:
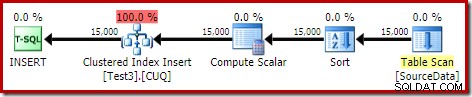
Oczywiście sortowania można również całkowicie uniknąć, indeksując (nie podzieloną na partycje) tabelę źródłową i wstawiając dane w kolejności indeksowania (pamiętaj, że najlepszym sortowaniem jest brak sortowania).
Podzielona sterta, potem dane, potem indeks
W przypadku tej ostatniej odmiany najpierw tworzymy partycjonowaną stertę i ładujemy 15 000 testowych wierszy:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Ten skrypt działa przez sekundę lub dwie, co jest całkiem niezłe. Ostatnim krokiem jest utworzenie partycjonowanego indeksu klastrowego:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
To kompletna katastrofa, zarówno z punktu widzenia wydajności, jak i informacji o planie pokazu. Sama operacja trwa niecałą minutę, z następującym planem wykonania:

To jest wspólny plan wstawiania. Skanowanie ciągłe zawiera wiersz dla każdego identyfikatora partycji. Wewnętrzna strona pętli wyszukuje bieżący podział sterty (tak, wyszukiwanie na stercie). Sortowanie ma właściwość identyfikatora partycji (pomimo tego, że jest stała na iterację pętli), więc istnieje sortowanie według partycji i niepożądane zachowanie rozlewania. Ostrzeżenie statystyk w tabeli sterty jest fałszywe.
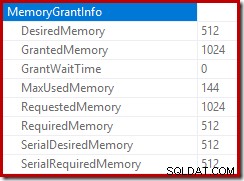
Katalog główny planu wstawiania wskazuje, że zarezerwowano przydział pamięci w wysokości 1 MB, przy czym wykorzystano maksymalnie 144 KB:
Operator sortowania nie zgłasza rozlania na poziomie 15 000, ale poza tym powoduje kompletny bałagan związany z matematyką iteracji na pętlę:

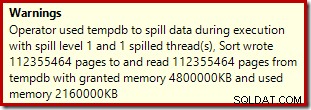
Monitorowanie pamięci przydziela DMV podczas wykonywania pokazuje, że to zapytanie faktycznie rezerwuje tylko 1 MB, z maksymalnie 144 KB używanymi w każdej iteracji pętli. (Dla kontrastu, rezerwacja pamięci 4,6 GB w pierwszym teście jest absolutnie autentyczna.) To oczywiście mylące.
Problem (jak wspomniano wcześniej) polega na tym, że SQL Server nie wie, jak najlepiej raportować to, co wydarzyło się w wielu iteracjach. Prawdopodobnie nie jest praktyczne uwzględnienie informacji o wydajności planu na partycję na iterację, ale nie można uciec od faktu, że obecny układ czasami daje mylące wyniki. Możemy mieć tylko nadzieję, że pewnego dnia uda się znaleźć lepszy sposób zgłaszania tego typu informacji w bardziej spójnym formacie.