Twoje obowiązki jako DBA (lub DBCC CHECKDB . Możesz się tam dostać, tworząc prosty plan konserwacji z „Zadaniem sprawdzania integralności bazy danych” – jednak moim zdaniem jest to tylko zaznaczenie pola wyboru.
Jeśli przyjrzysz się bliżej, niewiele możesz zrobić, aby kontrolować działanie zadania. Nawet dość obszerny panel Właściwości ujawnia całą masę ustawień dla podplanu konserwacji, ale praktycznie nic na temat DBCC polecenia, które będzie uruchamiał. Osobiście uważam, że powinieneś przyjąć znacznie bardziej proaktywne i kontrolowane podejście do tego, jak wykonujesz swoją CHECKDB operacje w środowiskach produkcyjnych, tworząc własne zadania i ręcznie tworząc swój DBCC polecenia. Możesz dostosować swój harmonogram lub same polecenia do różnych baz danych – na przykład baza danych członkostwa ASP.NET prawdopodobnie nie jest tak ważna jak baza danych sprzedaży i może tolerować rzadsze i/lub mniej dokładne kontrole.
Ale w przypadku twoich kluczowych baz danych, pomyślałem, że stworzę post, aby szczegółowo opisać niektóre rzeczy, które zbadam, aby zminimalizować zakłócenia DBCC komendy mogą powodować – i jakich mitów i marketingowych bałaganów należy się wystrzegać. I chcę podziękować Paulowi „Mr. DBCC” Randalowi (@PaulRandal) za dostarczenie cennego wkładu – nie tylko w ten konkretny post, ale także za niekończące się porady, które udziela na swoim blogu, #sqlhelp i podczas szkolenia SQLskills Immersion.
Wszystkie te pomysły należy traktować z przymrużeniem oka i dołożyć wszelkich starań, aby przeprowadzić odpowiednie testy w swoim środowisku — nie wszystkie z tych sugestii zapewnią lepszą wydajność we wszystkich środowiskach. Ale jesteś to winien sobie, swoim użytkownikom i interesariuszom przynajmniej rozważenie wpływu, jaki Twoja CHECKDB mogą wystąpić operacje i podejmij kroki w celu złagodzenia tych skutków tam, gdzie to możliwe – bez wprowadzania niepotrzebnego ryzyka poprzez niesprawdzanie właściwych rzeczy.
Zmniejsz hałas i zużyj wszystkie błędy
Bez względu na to, gdzie używasz CHECKDB , zawsze używaj WITH NO_INFOMSGS opcja. To po prostu tłumi wszystkie nieistotne dane wyjściowe, które po prostu mówią ci, ile wierszy znajduje się w każdej tabeli; jeśli interesują Cię te informacje, możesz je uzyskać z prostych zapytań do DMV, a nie podczas DBCC biegnie. Pominięcie danych wyjściowych znacznie zmniejsza prawdopodobieństwo przeoczenia krytycznej wiadomości ukrytej w tych wszystkich szczęśliwych wynikach.
Podobnie, zawsze powinieneś używać WITH ALL_ERRORMSGS opcja, ale szczególnie jeśli używasz SQL Server 2008 RTM lub SQL Server 2005 (w takich przypadkach możesz zobaczyć listę błędów na obiekt obcięty do 200). Dla każdej CHECKDB operacji innych niż szybkie sprawdzanie ad-hoc, powinieneś rozważyć skierowanie wyjścia do pliku. Management Studio jest ograniczone do 1000 linii danych wyjściowych z DBCC CHECKDB , więc możesz pominąć niektóre błędy, jeśli przekroczysz tę liczbę.
Chociaż nie jest to wyłącznie problem z wydajnością, użycie tych opcji uniemożliwi ponowne uruchomienie procesu. Jest to szczególnie ważne, jeśli jesteś w trakcie odzyskiwania po awarii.
Odciążaj kontrole logiczne tam, gdzie to możliwe
W większości przypadków CHECKDB spędza większość czasu na logicznym sprawdzaniu danych. Jeśli masz możliwość wykonania tych sprawdzeń na prawdziwej kopii danych, możesz skoncentrować swoje wysiłki na fizycznej strukturze swoich systemów produkcyjnych i użyć serwera pomocniczego do obsługi wszystkich kontroli logicznych i odciążenia głównego. Przez serwer pomocniczy , mam na myśli tylko następujące:
- Miejsce, w którym testujesz pełne przywracanie – ponieważ testujesz przywracanie, prawda?
Inni ludzie (w szczególności gigantyczna siła marketingowa, jaką jest Microsoft) mogli przekonać Cię, że inne formy serwerów pomocniczych są odpowiednie dla DBCC czeki. Na przykład:
- dodatkowa czytelna dla grupy dostępności AlwaysOn;
- zdjęcie lustrzanej bazy danych;
- dziennik wysłany jako drugorzędny;
- dublowanie sieci SAN;
- lub inne odmiany…
Niestety tak nie jest i żadne z tych drugorzędnych nie jest prawidłowymi, niezawodnymi miejscami do przeprowadzania kontroli jako alternatywy dla podstawowego. Tylko kopia zapasowa jeden do jednego może służyć jako prawdziwa kopia; wszystko inne, które opiera się na takich rzeczach, jak stosowanie kopii zapasowych dziennika w celu uzyskania spójnego stanu, nie będzie rzetelnie odzwierciedlać problemów z integralnością na podstawowym.
Więc zamiast próbować przenieść kontrole logiczne na drugorzędne i nigdy nie wykonywać ich na podstawowej, oto co sugeruję:
- Upewnij się, że często testujesz przywracanie pełnych kopii zapasowych. I nie, to nie obejmuje
COPY_ONLYkopie zapasowe z pomocniczego AG, z tych samych powodów, co powyżej — byłoby to ważne tylko w przypadku, gdy właśnie zainicjowano pomocniczy z pełnym przywracaniem. - Uruchom
DBCC CHECKDBczęsto przeciwko pełnemu przywrócić, zanim zrobisz cokolwiek innego. Ponownie, ponowne odtworzenie zapisów dziennika w tym momencie unieważni tę bazę danych jako prawdziwą kopię źródła. - Uruchom
DBCC CHECKDBw stosunku do głównego, być może podzielonego w sposób, który sugeruje Paul Randal, i/lub według rzadszego harmonogramu i/lub przy użyciuPHYSICAL_ONLYczęściej niż nie. Może to zależeć od tego, jak często i niezawodnie wykonujesz (2). - Nigdy nie zakładaj, że kontrole w przypadku drugorzędnych są wystarczające. Nawet w przypadku dokładnej repliki podstawowej bazy danych nadal występują problemy fizyczne, które mogą wystąpić w podsystemie we/wy podstawowego, które nigdy nie zostaną rozprzestrzenione do pomocniczego.
- Zawsze analizuj
DBCCwyjście. Samo uruchomienie go i zignorowanie, aby zaznaczyć to na jakiejś liście, jest tak samo pomocne, jak uruchamianie kopii zapasowych i deklarowanie sukcesu bez testowania, czy w razie potrzeby można przywrócić tę kopię zapasową.
Eksperymentuj z flagami śledzenia 2549, 2562 i 2566
Przeprowadziłem gruntowne testy dwóch flag śledzenia (2549 i 2562) i stwierdziłem, że mogą one przynieść znaczną poprawę wydajności, jednak Lonny informuje, że nie są już potrzebne ani użyteczne. Jeśli korzystasz z wersji 2016 lub nowszej, pomiń całą sekcję . Jeśli korzystasz ze starszej wersji, te dwie flagi śledzenia są opisane bardziej szczegółowo w KB #2634571, ale w skrócie:
- Flaga śledzenia 2549
- Optymalizuje to proces sprawdzania bazy danych, traktując każdy pojedynczy plik bazy danych jako znajdujący się na unikalnym dysku bazowym. Jest to w porządku, jeśli Twoja baza danych zawiera pojedynczy plik danych lub jeśli wiesz, że każdy plik bazy danych znajduje się w rzeczywistości na osobnym dysku. Jeśli baza danych zawiera wiele plików i współdzielą one jedno, bezpośrednio podłączone wrzeciono, należy uważać na tę flagę śledzenia, ponieważ może ona wyrządzić więcej szkody niż pożytku.
WAŻNE :sql.sasquatch zgłasza regresję tego zachowania flagi śledzenia w programie SQL Server 2014.
- Optymalizuje to proces sprawdzania bazy danych, traktując każdy pojedynczy plik bazy danych jako znajdujący się na unikalnym dysku bazowym. Jest to w porządku, jeśli Twoja baza danych zawiera pojedynczy plik danych lub jeśli wiesz, że każdy plik bazy danych znajduje się w rzeczywistości na osobnym dysku. Jeśli baza danych zawiera wiele plików i współdzielą one jedno, bezpośrednio podłączone wrzeciono, należy uważać na tę flagę śledzenia, ponieważ może ona wyrządzić więcej szkody niż pożytku.
- Flaga śledzenia 2562
- Ta flaga traktuje cały proces checkdb jako pojedynczą partię, kosztem wyższego wykorzystania bazy danych tempdb (do 5% rozmiaru bazy danych).
- Używa lepszego algorytmu do określenia sposobu odczytywania stron z bazy danych, zmniejszając rywalizację o zatrzask (szczególnie dla
DBCC_MULTIOBJECT_SCANNER). Należy zauważyć, że to konkretne ulepszenie znajduje się w ścieżce kodu programu SQL Server 2012, więc skorzystasz z niej nawet bez flagi śledzenia. Pozwala to uniknąć błędów, takich jak:
Wystąpił limit czasu podczas oczekiwania na zatrzask:klasa „DBCC_MULTIOBJECT_SCANNER”.
- Powyższe dwie flagi śledzenia są dostępne w następujących wersjach:
- Zbiorcza aktualizacja dodatku Service Pack 2 dla programu SQL Server 2008 9+
(10.0.4330 -> 10.0.5499)SQL Server 2008 Service Pack 3 Zbiorcza aktualizacja 4+
(10.00.5775+)Zbiorcza aktualizacja programu SQL Server 2008 R2 RTM 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 Zbiorcza aktualizacja 4+
(10.50.2796 -> 10.50.3999)Dodatek Service Pack 2 dla SQL Server 2008 R2
(10.50.4000+)SQL Server 2012, wszystkie wersje
(11.0.2100+) - Flaga śledzenia 2566
- Jeśli nadal korzystasz z programu SQL Server 2005, ta flaga śledzenia, wprowadzona w 2005 SP2 CU#9 (9.00.3282) (choć nie udokumentowana w artykule bazy wiedzy tej aktualizacji zbiorczej, KB #953752), próbuje poprawić niską wydajność z
DATA_PURITYsprawdza w systemach x64. W pewnym momencie więcej szczegółów można było zobaczyć w KB #945770, ale wydaje się, że artykuł został usunięty zarówno ze strony pomocy technicznej Microsoftu, jak iz maszyny WayBack. Ta flaga śledzenia nie powinna być potrzebna w nowszych wersjach SQL Server, ponieważ problem w procesorze zapytań został naprawiony.
- Jeśli nadal korzystasz z programu SQL Server 2005, ta flaga śledzenia, wprowadzona w 2005 SP2 CU#9 (9.00.3282) (choć nie udokumentowana w artykule bazy wiedzy tej aktualizacji zbiorczej, KB #953752), próbuje poprawić niską wydajność z
Jeśli zamierzasz użyć którejkolwiek z tych flag śledzenia, zdecydowanie zalecam ustawienie ich na poziomie sesji za pomocą DBCC TRACEON zamiast jako flaga śledzenia uruchamiania. Pozwala to nie tylko na ich wyłączenie bez konieczności cyklicznego uruchamiania SQL Server, ale także pozwala na ich implementację tylko podczas wykonywania określonej CHECKDB poleceń, w przeciwieństwie do operacji wykorzystujących jakikolwiek rodzaj naprawy.
Zmniejsz wpływ we/wy:zoptymalizuj bazę danych
DBCC CHECKDB może intensywnie korzystać z tempdb, więc upewnij się, że planujesz tam wykorzystanie zasobów. W każdym razie jest to zwykle dobre rozwiązanie. Dla CHECKDB będziesz chciał odpowiednio przydzielić miejsce do tempdb; ostatnią rzeczą, jakiej potrzebujesz, jest CHECKDB postęp (i wszelkie inne równoczesne operacje), aby czekać na automatyczny wzrost. Możesz uzyskać pomysł na wymagania za pomocą WITH ESTIMATEONLY , jak wyjaśnia tutaj Paweł. Pamiętaj tylko, że oszacowanie może być dość niskie z powodu błędu w SQL Server 2008 R2. Również jeśli używasz flagi śledzenia 2562, pamiętaj, aby uwzględnić dodatkowe wymagania dotyczące miejsca.
I oczywiście wszystkie typowe porady dotyczące optymalizacji tempdb w prawie każdym systemie są również odpowiednie:upewnij się, że tempdb jest na swoim własnym zestawie szybkim wrzeciona, upewnij się, że ma rozmiar, aby pomieścić wszystkie inne współbieżne działania bez konieczności rozbudowy, upewnij się, że używasz optymalnej liczby plików danych itp. Kilka innych zasobów, które możesz wziąć pod uwagę:
- Optymalizacja wydajności tempdb (MSDN)
- Planowanie pojemności dla tempdb (MSDN)
- Mit SQL Server DBA na co dzień:(12/30) tempdb powinien zawsze mieć jeden plik danych na rdzeń procesora
Zmniejsz wpływ we/wy:kontroluj migawkę
Aby uruchomić CHECKDB , nowoczesne wersje programu SQL Server będą próbowały utworzyć ukrytą migawkę bazy danych na tym samym dysku (lub na wszystkich dyskach, jeśli pliki danych obejmują wiele dysków). Nie możesz kontrolować tego mechanizmu, ale jeśli chcesz kontrolować, gdzie CHECKDB działa, najpierw utwórz własną migawkę (wymagana wersja Enterprise) na dowolnym dysku, a następnie uruchom DBCC polecenie na migawce. W obu przypadkach warto uruchomić tę operację podczas względnego przestoju, aby zminimalizować aktywność kopiowania przy zapisie, która przejdzie przez migawkę. I nie chcesz, aby ten harmonogram kolidował z jakimikolwiek ciężkimi operacjami zapisu, takimi jak konserwacja indeksu lub ETL.
Być może widziałeś sugestie, aby wymusić CHECKDB do uruchomienia w trybie offline za pomocą WITH TABLOCK opcja. Zdecydowanie odradzam takie podejście. Jeśli Twoja baza danych jest aktywnie używana, wybranie tej opcji spowoduje tylko frustrację użytkowników. A jeśli baza danych nie jest aktywnie używana, nie oszczędzasz miejsca na dysku, unikając migawek, ponieważ nie będzie żadnej operacji kopiowania przy zapisie do zapisania.
Zmniejsz wpływ we/wy:unikaj błędów 665 / 1450 / 1452
W niektórych przypadkach możesz zobaczyć jeden z następujących błędów:
System operacyjny zwrócił błąd 1450 (niewystarczające zasoby systemowe do ukończenia żądanej usługi) do programu SQL Server podczas zapisu pod przesunięciem 0x[…] w pliku z uchwytem 0x[…]. Zwykle jest to stan tymczasowy i SQL Server będzie nadal ponawiał operację. Jeśli stan się utrzymuje, należy podjąć natychmiastowe działania, aby go naprawić.
System operacyjny zwrócił błąd 665 (żądana operacja nie mogła zostać ukończona z powodu ograniczeń systemu plików) do SQL Server podczas zapisu z przesunięciem 0x[…] w pliku '[plik]'
Jest tutaj kilka wskazówek, jak zmniejszyć ryzyko wystąpienia tych błędów podczas CHECKDB operacji i ogólnie zmniejszenie ich wpływu – z kilkoma dostępnymi poprawkami, w zależności od systemu operacyjnego i wersji SQL Server:
- Nieliczne błędy plików:1450 lub 665 z powodu fragmentacji pliku:poprawki i obejścia
- SQL Server zgłasza błąd systemu operacyjnego 1450 lub 1452 lub 665 (powtórzenia)
Zmniejsz wpływ procesora
DBCC CHECKDB jest domyślnie wielowątkowy (ale tylko w Enterprise Edition). Jeśli twój system jest związany z procesorem lub po prostu chcesz CHECKDB aby zużywać mniej procesora kosztem dłuższego działania, można rozważyć zmniejszenie równoległości na kilka różnych sposobów:
- Używaj programu Resource Governor w wersji 2008 i nowszej, o ile korzystasz z wersji Enterprise Edition. Aby kierować tylko polecenia DBCC dla określonej puli zasobów lub grupy obciążenia, musisz napisać funkcję klasyfikatora, która może identyfikować sesje, które będą wykonywać tę pracę (np. określony login lub identyfikator zadania).
- Użyj flagi śledzenia 2528, aby wyłączyć równoległość dla
DBCC CHECKDB(jak równieżCHECKFILEGROUPiCHECKTABLE). Flaga śledzenia 2528 jest opisana tutaj. Oczywiście dotyczy to tylko wersji Enterprise, ponieważ wbrew temu, co obecnie mówi Books Online, prawda jest taka, że CHECKDBnie działa równolegle w wersji Standard Edition. - Podczas gdy
DBCCsamo polecenie nie obsługujeMAXDOP(przynajmniej przed SQL Server 2014 SP2) respektuje ustawienie globalnemax degree of parallelism. Prawdopodobnie nie jest to coś, co zrobiłbym w środowisku produkcyjnym, gdybym nie miał innych opcji, ale jest to jeden nadrzędny sposób kontrolowania pewnychDBCCpoleceń, jeśli nie możesz ich wyraźniej określić.
Prosiliśmy o lepszą kontrolę nad liczbą procesorów, które DBCC CHECKDB używa, ale były wielokrotnie odrzucane aż do dodatku SP2 dla programu SQL Server 2014. Możesz więc teraz dodać WITH MAXDOP = n do polecenia.
Moje ustalenia
Chciałem zademonstrować kilka z tych technik w środowisku, które mogłem kontrolować. Zainstalowałem AdventureWorks2012, a następnie rozszerzyłem go za pomocą skryptu powiększającego AW napisanego przez Jonathana Kehayiasa (blog | @SQLPoolBoy), który powiększył bazę danych do około 7 GB. Następnie uruchomiłem serię CHECKDB rozkazy przeciwko niemu i mierzyli je w czasie. Użyłem zwykłego waniliowego DBCC CHECKDB samodzielnie, to wszystkie inne komendy użyły WITH NO_INFOMSGS, ALL_ERRORMSGS . Następnie cztery testy z (a) bez znaczników śledzenia, (b) 2549, (c) 2562 i (d) zarówno 2549, jak i 2562. Następnie powtórzyłem te cztery testy, ale dodałem PHYSICAL_ONLY opcja, która omija wszystkie kontrole logiczne. Wyniki (uśrednione z 10 przebiegów testowych) mówią:
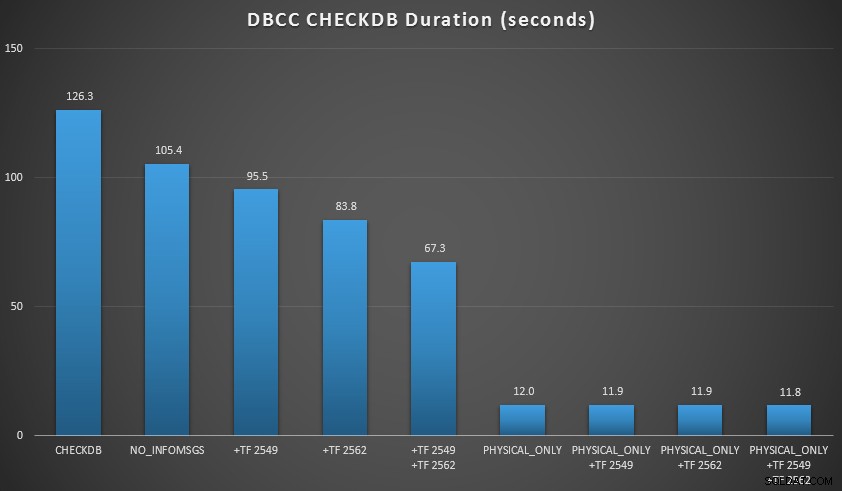
SPRAWDŹ wyniki w bazie danych 7 GB
Potem jeszcze bardziej rozszerzyłem bazę danych, wykonując wiele kopii dwóch powiększonych tabel, co doprowadziło do rozmiaru bazy na północ od 70 GB, i ponownie przeprowadziłem testy. Wyniki, ponownie uśrednione z 10 przebiegów testowych:
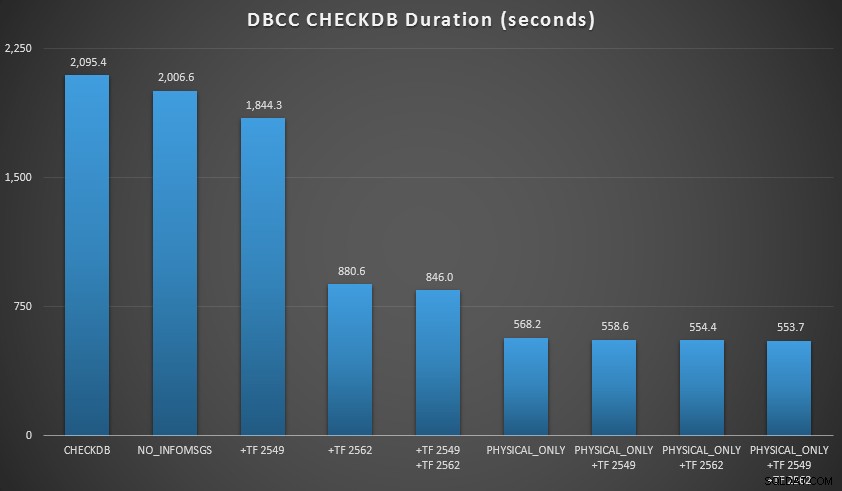
SPRAWDŹ wyniki w bazie danych o pojemności 70 GB
W tych dwóch scenariuszach nauczyłem się następujących rzeczy (znowu pamiętając, że Twój przebieg może się różnić i że będziesz musiał przeprowadzić własne testy, aby wyciągnąć jakiekolwiek sensowne wnioski):
- Kiedy muszę przeprowadzić kontrolę logiczną:
- Przy małych rozmiarach bazy danych
NO_INFOMSGSopcja może znacznie skrócić czas przetwarzania, gdy kontrole są uruchamiane w SSMS. Jednak w przypadku większych baz danych korzyść ta maleje, ponieważ czas i praca poświęcona na przekazywanie informacji stają się tak nieznaczną częścią całkowitego czasu trwania. 21 sekund z 2 minut jest znaczne; 88 sekund na 35 minut, nie tak dużo. - Dwie flagi śledzenia, które testowałem, miały znaczący wpływ na wydajność – reprezentując skrócenie czasu działania o 40-60%, gdy oba były używane razem.
- Przy małych rozmiarach bazy danych
- Kiedy mogę przekazać kontrole logiczne do serwera pomocniczego (ponownie, przy założeniu, że przeprowadzam kontrole logiczne gdzie indziej w odniesieniu do prawdziwej kopii ):
- Mogę skrócić czas przetwarzania w mojej podstawowej instancji o 70-90% w porównaniu ze standardową
CHECKDBzadzwoń bez opcji. - W moim scenariuszu flagi śledzenia miały bardzo mały wpływ na czas trwania podczas wykonywania
PHYSICAL_ONLYczeki.
- Mogę skrócić czas przetwarzania w mojej podstawowej instancji o 70-90% w porównaniu ze standardową
Oczywiście, i nie mogę tego wystarczająco podkreślić, są to stosunkowo małe bazy danych i używane tylko po to, abym mógł wykonać powtarzane, mierzone testy w rozsądnym czasie. Ten serwer miał 80 logicznych procesorów i 128 GB RAM, a ja byłem jedynym użytkownikiem. Czas trwania i interakcja z innymi obciążeniami w systemie może nieco zniekształcić te wyniki. Oto krótkie spojrzenie na typowe użycie procesora przy użyciu SQL Sentry podczas jednego z CHECKDB operacje (i żadna z opcji tak naprawdę nie zmieniła ogólnego wpływu na procesor, tylko czas trwania):
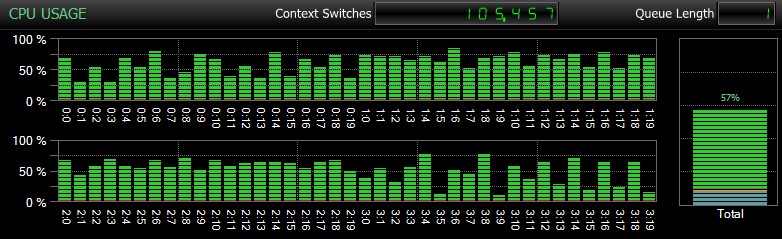
Wpływ procesora podczas CHECKDB – tryb przykładowy
A oto kolejny widok, pokazujący podobne profile procesora dla trzech różnych próbek CHECKDB operacje w trybie historycznym (nałożyłem opis trzech próbkowanych testów z tego zakresu):
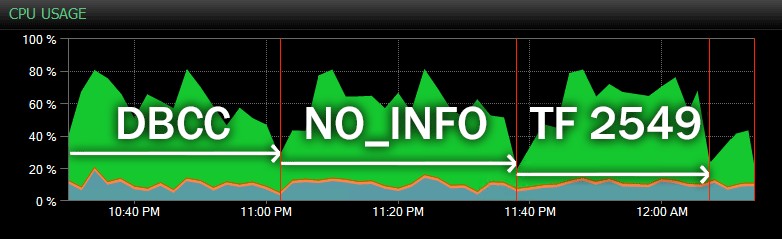
Wpływ procesora podczas CHECKDB – tryb historyczny
W jeszcze większych bazach danych, hostowanych na bardziej obciążonych serwerach, możesz zauważyć różne efekty, a Twój przebieg prawdopodobnie będzie się różnił. Dlatego przed podjęciem decyzji o podejściu do CHECKDB należy przeprowadzić analizę due diligence i przetestować te opcje i flagi śledzenia podczas typowego jednoczesnego obciążenia .
Wniosek
DBCC CHECKDB to bardzo ważna, ale często niedoceniana część Twojej odpowiedzialności jako DBA lub architekta i kluczowa dla ochrony danych Twojej firmy. Nie lekceważ tej odpowiedzialności i dokładaj wszelkich starań, aby nie poświęcać niczego w celu zmniejszenia wpływu na instancje produkcyjne. Co najważniejsze:wyjdź poza arkusze danych marketingowych, aby upewnić się, że w pełni rozumiesz, jak ważne są te obietnice i czy jesteś gotów postawić na nie dane swojej firmy. Pomijanie niektórych kontroli lub przenoszenie ich do nieprawidłowych lokalizacji drugorzędnych może być katastrofą, która może się wydarzyć.
Powinieneś również rozważyć przeczytanie tych artykułów PSS:
- Szybszy CHECKDB – część I
- Szybszy CHECKDB – część II
- Szybszy CHECKDB – część III
- Szybszy CHECKDB – część IV (SQL CLR UDT)
I ten post od Brenta Ozara:
- 3 sposoby na szybsze uruchomienie DBCC CHECKDB
Na koniec, jeśli masz nierozwiązane pytanie dotyczące DBCC CHECKDB , opublikuj go w tagu hash #sqlhelp na Twitterze. Paul często sprawdza ten tag, a ponieważ jego zdjęcie powinno pojawić się w głównym artykule w Books Online, jest prawdopodobne, że jeśli ktoś może na nie odpowiedzieć, to i on. Jeśli jest zbyt złożony dla 140 znaków, możesz zapytać tutaj (a upewnię się, że Paul w pewnym momencie go zobaczy) lub opublikować na stronie forum, takiej jak Database Administrators Stack Exchange.



