 Dorastając uwielbiałem gry testujące pamięć i umiejętność dopasowywania wzorców. Kilku moich przyjaciół miało Simona, a ja miałem podróbkę o imieniu Einstein. Inni mieli Atari Touch Me, co już wtedy wiedziałem, że było wątpliwą decyzją dotyczącą nazewnictwa. Obecnie dopasowywanie wzorców oznacza dla mnie coś zupełnie innego i może być kosztowną częścią codziennych zapytań do bazy danych.
Dorastając uwielbiałem gry testujące pamięć i umiejętność dopasowywania wzorców. Kilku moich przyjaciół miało Simona, a ja miałem podróbkę o imieniu Einstein. Inni mieli Atari Touch Me, co już wtedy wiedziałem, że było wątpliwą decyzją dotyczącą nazewnictwa. Obecnie dopasowywanie wzorców oznacza dla mnie coś zupełnie innego i może być kosztowną częścią codziennych zapytań do bazy danych.
Niedawno natknąłem się na kilka komentarzy na temat Stack Overflow, w których użytkownik stwierdził, jakby w rzeczywistości, że CHARINDEX działa lepiej niż LEFT lub LIKE . W jednym przypadku osoba zacytowała artykuł Davida Łozińskiego „SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX”. Tak, artykuł pokazuje, że w wymyślonym przykładzie CHARINDEX działał najlepiej. Jednakże, ponieważ zawsze jestem sceptyczny wobec takich ogólnych instrukcji i nie mogłem wymyślić logicznego powodu, dla którego jedna funkcja łańcuchowa miałaby zawsze osiągają lepsze wyniki niż inne, przy czym wszystkie inne są równe , przeprowadziłem jego testy. Rzeczywiście, miałem powtarzalnie różne wyniki na moim komputerze (kliknij, aby powiększyć):
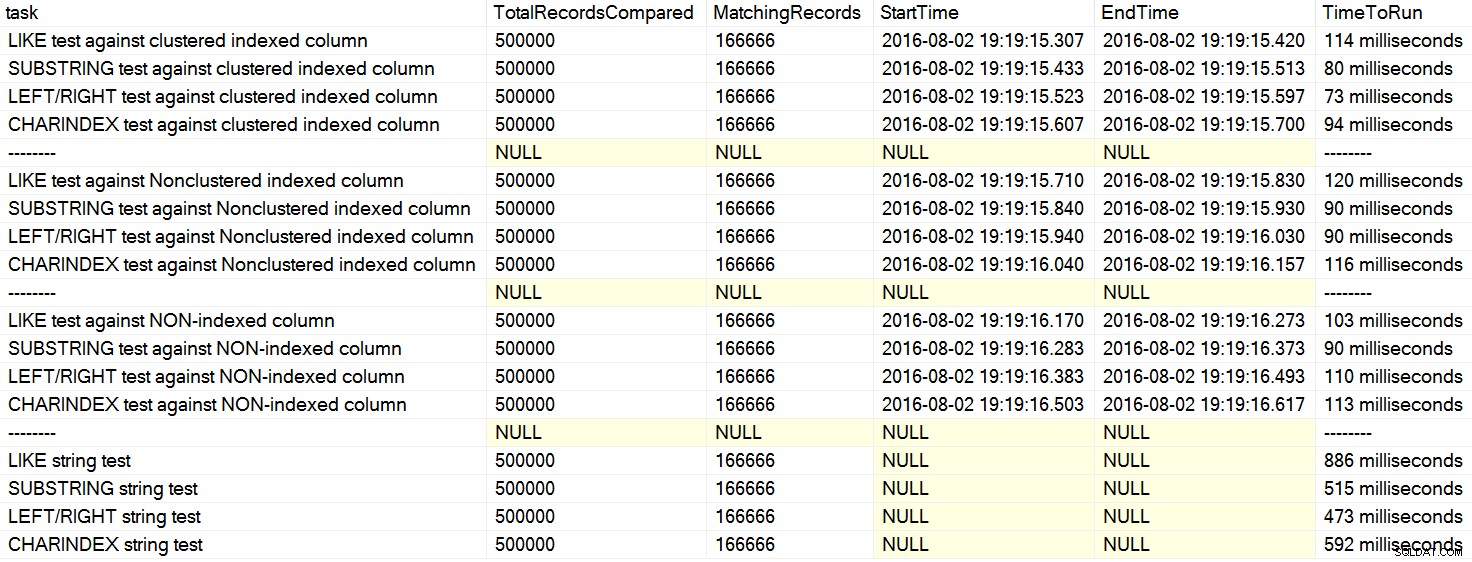 Na moim komputerze CHARINDEX był wolniejszy niż LEFT/RIGHT/SUBSTRING.
Na moim komputerze CHARINDEX był wolniejszy niż LEFT/RIGHT/SUBSTRING.
Testy Davida zasadniczo porównywały te struktury zapytań – szukając wzorca ciągu na początku lub na końcu wartości kolumny – pod względem nieprzetworzonego czasu trwania:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
Wystarczy spojrzeć na te klauzule, aby zobaczyć, dlaczego CHARINDEX może być mniej wydajny — tworzy wiele dodatkowych wywołań funkcjonalnych, których inne podejścia nie muszą wykonywać. Dlaczego to podejście sprawdzało się najlepiej na komputerze Davida, nie jestem pewien; może uruchomił kod dokładnie tak, jak został opublikowany i tak naprawdę nie upuszczał buforów między testami, tak że te ostatnie korzystały z danych z pamięci podręcznej.
Teoretycznie CHARINDEX można było wyrazić prościej, np.:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(Ale w moich testach wypadło to jeszcze gorzej).
I dlaczego są to nawet OR warunki, nie jestem pewien. Realistycznie rzecz biorąc, przez większość czasu wykonujesz jeden z dwóch typów wyszukiwania wzorców:zaczyna się od lub zawiera (o wiele rzadziej szukanie kończy się na ). W większości przypadków użytkownik ma tendencję do określania z góry, czy chce, aby zaczynał się od lub zawiera , przynajmniej w każdej aplikacji, w której brałem udział w mojej karierze.
Sensowne jest oddzielenie ich jako oddzielnych typów zapytań, zamiast używania LUB warunkowe, ponieważ zaczyna się od może korzystać z indeksu (jeśli taki istnieje, który jest wystarczająco odpowiedni do wyszukiwania lub jest cieńszy niż indeks klastrowy), podczas gdy kończy się nie może (i LUB warunki zwykle rzucają klucze na optymalizator). Jeśli mogę zaufać LUBIE aby używać indeksu, kiedy to możliwe, i działać tak samo lub lepiej niż inne powyższe rozwiązania w większości lub we wszystkich przypadkach, mogę bardzo uprościć tę logikę. Procedura składowana może przyjmować dwa parametry — wyszukiwany wzorzec i typ wyszukiwania do wykonania (ogólnie istnieją cztery typy dopasowywania ciągów — rozpoczyna się od, kończy się, zawiera lub dokładne dopasowanie).
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Obsługuje to każdy potencjalny przypadek bez użycia dynamicznego SQL; OPTION (RECOMPILE) istnieje, ponieważ nie chciałbyś, aby plan zoptymalizowany pod kątem „kończy się na” (który prawie na pewno będzie musiał zostać zeskanowany) został ponownie wykorzystany do zapytania „zaczyna się od” lub odwrotnie; zapewni również poprawność szacunków („zaczyna się od S” prawdopodobnie ma znacznie inną kardynalność niż „zaczyna się od QX”). Nawet jeśli masz scenariusz, w którym użytkownicy wybierają jeden typ wyszukiwania w 99% przypadków, możesz użyć dynamicznego SQL tutaj zamiast ponownej kompilacji, ale w takim przypadku nadal będziesz narażony na podsłuchiwanie parametrów. W wielu warunkowych zapytaniach logicznych rekompilacja i/lub pełny dynamiczny SQL są często najbardziej rozsądnym podejściem (zobacz mój post o "zlewie kuchennym").
Testy
Ponieważ niedawno zacząłem przyglądać się nowej przykładowej bazie danych WideWorldImporters, postanowiłem przeprowadzić tam własne testy. Trudno było znaleźć przyzwoitą tabelę bez indeksu ColumnStore lub tabeli historii czasowej, ale Sales.Invoices , który ma 70 510 wierszy, ma prosty nvarchar(20) kolumna o nazwie CustomerPurchaseOrderNumber które postanowiłem wykorzystać do testów. (Dlaczego jest to nvarchar(20) kiedy każda pojedyncza wartość jest liczbą 5-cyfrową, nie mam pojęcia, ale dopasowanie wzorców tak naprawdę nie ma znaczenia, czy bajty poniżej reprezentują liczby czy ciągi.)
| Sales.Faktury CustomerPurchaseOrderNumber | ||
|---|---|---|
| Wzór | Liczba wierszy | % tabeli |
| Zaczyna się od „1” | 70 505 | 99,993% |
| Zaczyna się od „2” | 5 | 0,007% |
| Kończy się na „5” | 6897 | 9,782% |
| Kończy się na „30” | 749 | 1,062% |
Poszperałem w wartościach w tabeli, aby znaleźć wiele kryteriów wyszukiwania, które dawałyby bardzo różną liczbę wierszy, mając nadzieję, że ujawnią jakiekolwiek zachowanie w punkcie krytycznym przy danym podejściu. Po prawej stronie znajdują się zapytania, na które trafiłem.
Chciałem sobie udowodnić, że powyższa procedura była niezaprzeczalnie lepsza ogólnie dla wszystkich możliwych wyszukiwań niż jakiekolwiek z zapytań używających OR warunkowe, niezależnie od tego, czy używają LIKE , LEFT/RIGHT , SUBSTRING lub CHARINDEX . Wziąłem podstawowe struktury zapytań Davida i umieściłem je w procedurach składowanych (z zastrzeżeniem, że tak naprawdę nie mogę przetestować "zawiera" bez jego danych wejściowych i że musiałem utworzyć jego OR logika nieco bardziej elastyczna, aby uzyskać taką samą liczbę wierszy), wraz z wersją mojej logiki. Planowałem również przetestować procedury z indeksem i bez, które utworzyłbym w kolumnie wyszukiwania oraz pod ciepłą i zimną pamięcią podręczną.
Procedury:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Stworzyłem również wersje procedur Davida zgodne z jego pierwotnymi intencjami, zakładając, że wymaganie naprawdę polega na znalezieniu dowolnych wierszy, w których wzorzec wyszukiwania znajduje się na początku *lub* na końcu łańcucha. Zrobiłem to po prostu, aby móc porównać wydajność różnych podejść, dokładnie tak, jak je napisał, aby sprawdzić, czy w tym zestawie danych moje wyniki pasują do moich testów jego oryginalnego skryptu w moim systemie. W tym przypadku nie było powodu, aby wprowadzać własną wersję, ponieważ pasowałaby po prostu do jego LIKE % + @pattern OR LIKE @pattern + % odmiana.
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO Mając odpowiednie procedury, mogłem wygenerować kod testowy – co często jest tak samo zabawne, jak oryginalny problem. Najpierw tabela logowania:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
Następnie kod, który wykonałby wybrane operacje przy użyciu różnych procedur i argumentów:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; Wyniki
Testy te przeprowadziłem na maszynie wirtualnej z systemem Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), z 4 procesorami i 32 GB pamięci RAM. Każdy zestaw testów wykonałem 11 razy; w przypadku testów ciepłej pamięci podręcznej wyrzuciłem pierwszy zestaw wyników, ponieważ niektóre z nich były naprawdę testami zimnej pamięci podręcznej.
Miałem problemy z wykreśleniem wyników, aby pokazać wzorce, głównie dlatego, że po prostu nie było wzorców. Prawie każda metoda była najlepsza w jednym scenariuszu, a najgorsza w innym. W poniższych tabelach wyróżniłem najlepszą i najgorszą procedurę dla każdej kolumny i widać, że wyniki są dalekie od rozstrzygających:
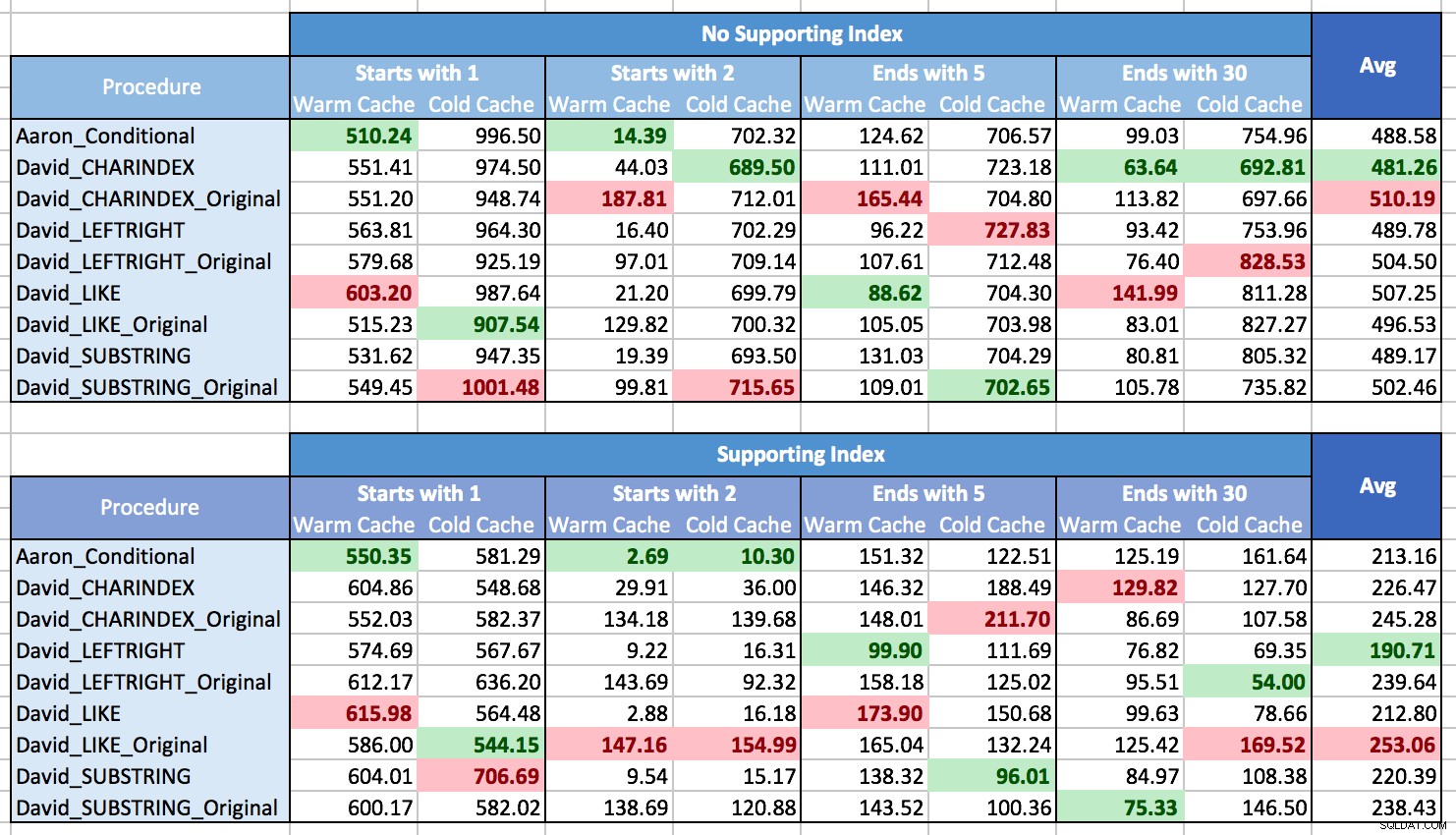 W tych testach czasami wygrywał CHARINDEX, a czasami nie.
W tych testach czasami wygrywał CHARINDEX, a czasami nie.
Nauczyłem się, że ogólnie rzecz biorąc, jeśli będziesz miał do czynienia z wieloma różnymi sytuacjami (różne typy dopasowywania wzorców, z indeksem pomocniczym lub bez, dane nie zawsze mogą znajdować się w pamięci), tak naprawdę nie ma wyraźny zwycięzca, a zakres wydajności jest średnio niewielki (w rzeczywistości, ponieważ ciepła pamięć podręczna nie zawsze pomagała, podejrzewam, że na wyniki bardziej wpłynął koszt renderowania wyników niż ich pobierania). W przypadku indywidualnych scenariuszy nie polegaj na moich testach; samodzielnie przeprowadź testy porównawcze, biorąc pod uwagę sprzęt, konfigurację, dane i wzorce użytkowania.
Ostrzeżenia
Kilka rzeczy, których nie wziąłem pod uwagę w tych testach:
- Sklastrowane a nieklastrowane . Ponieważ jest mało prawdopodobne, że Twój indeks klastrowy będzie znajdował się w kolumnie, w której przeprowadzasz wyszukiwania dopasowujące do wzorca względem początku lub końca ciągu, a wyszukiwanie będzie w dużej mierze takie samo w obu przypadkach (a różnice między skanami będą w dużej mierze być funkcją szerokości indeksu w stosunku do szerokości tabeli), przetestowałem wydajność tylko przy użyciu indeksu nieklastrowego. Jeśli masz konkretne scenariusze, w których sama ta różnica znacząco wpływa na dopasowanie wzorców, daj mi znać.
- MAKS. typów . Jeśli szukasz ciągów w
varchar(max)/nvarchar(max), nie można ich indeksować, więc jeśli nie używasz kolumn obliczeniowych do reprezentowania części wartości, wymagane będzie skanowanie — niezależnie od tego, czy szukasz zaczyna się od, kończy się, czy zawiera. Nie testowałem, czy obciążenie wydajności jest skorelowane z rozmiarem łańcucha, czy też dodatkowe obciążenie jest wprowadzane po prostu ze względu na typ.
- Wyszukiwanie pełnotekstowe . Bawiłem się tą funkcją tutaj i tam, i potrafię to przeliterować, ale jeśli moje rozumienie jest prawidłowe, może to być pomocne tylko wtedy, gdy szukasz całych słów bez przerwy i nie przejmujesz się tym, gdzie w ciągu się one znajdują znaleziony. Nie byłoby przydatne, gdybyś przechowywał akapity tekstu i chciał znaleźć wszystkie te, które zaczynają się na „Y”, zawierają słowo „the” lub kończą się znakiem zapytania.
Podsumowanie
Jedyne ogólne stwierdzenie, jakie mogę zrobić, odchodząc od tego testu, to to, że nie ma ogólnych stwierdzeń na temat tego, jaki jest najskuteczniejszy sposób wykonywania dopasowywania wzorców ciągów. Chociaż skłaniam się ku mojemu warunkowemu podejściu do elastyczności i łatwości konserwacji, nie we wszystkich scenariuszach było to zwycięzcą wydajności. Dla mnie, chyba że natrafię na wąskie gardło wydajności i podążam wszystkimi ścieżkami, będę nadal używał mojego podejścia do spójności. Jak zasugerowałem powyżej, jeśli masz bardzo wąski scenariusz i jesteś bardzo wrażliwy na niewielkie różnice w czasie trwania, będziesz chciał przeprowadzić własne testy, aby określić, która metoda jest dla Ciebie najskuteczniejsza.



