Service Pack 2 dla SQL Server 2014 został wydany w zeszłym miesiącu (przeczytaj uwagi do wydania tutaj) i zawiera nową instrukcję DBCC:DBCC CLONEDATABASE . Byłem bardzo podekscytowany wprowadzeniem tego polecenia, ponieważ zapewnia ono bardzo łatwe sposób kopiowania schematu bazy danych, w tym statystyk , który może być używany do testowania wydajności zapytań bez konieczności zajmowania miejsca na dane w bazie danych. W końcu znalazłem trochę czasu na przetestowanie DBCC CLONEDATABASE i rozumiem ograniczenia, i muszę powiedzieć, że było to raczej zabawne.
Podstawy
Zacząłem od utworzenia klonu bazy danych AdventureWorks2014 i uruchomienia zapytania względem źródłowej bazy danych, a następnie bazy danych klonu:
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE'); GO SET STATISTICS IO ON; GO SET STATISTICS TIME ON; GO SET STATISTICS XML ON; GO USE [AdventureWorks2014]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO USE [AdventureWorks2014_CLONE]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO SET STATISTICS IO OFF; GO SET STATISTICS TIME OFF; GO SET STATISTICS XML OFF; GO
Jeśli spojrzę na dane wyjściowe I/O i TIME, widzę, że zapytanie do źródłowej bazy danych trwało dłużej i generowało znacznie więcej I/O, z których oba są oczekiwane, ponieważ baza danych klonu nie zawiera żadnych danych:
/* baza danych SOURCE */
Czasy wykonywania programu SQL Server:
Czas procesora =0 ms, czas, który upłynął =0 ms.
Czas analizy i kompilacji SQL Server:
Czas procesora =0 ms, czas, który upłynął =4 ms.
(121317 wierszy, których dotyczy problem)
Tabela „Nagłówek zamówienia sprzedaży”. Liczba skanów 0, odczyty logiczne 371567, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne modułu 0, odczyty fizyczne modułu 0, odczyty modułu z wyprzedzeniem 0.
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Szczegóły zamówienia sprzedaży”. Liczba skanów 5, odczyty logiczne 1361, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne modułu 0, odczyty fizyczne modułu 0, odczyty modułu z wyprzedzeniem 0.
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
(1 wiersz(e) dotyczy)
Czasy wykonywania programu SQL Server:
Czas procesora =686 ms, czas, który upłynął =2548 ms.
/* Baza danych KLONOWANIA */
Czasy wykonywania programu SQL Server:
Czas procesora =0 ms, czas, który upłynął =0 ms.
Czas parsowania i kompilacji SQL Server:
Czas procesora =12 ms, czas, który upłynął =12 ms.
(0 wierszy dotkniętych)
Stół „Stół roboczy”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Nagłówek zamówienia sprzedaży”. Liczba skanów 0, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Szczegóły zamówienia sprzedaży”. Liczba skanów 5, odczyty logiczne 0, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne modułu 0, odczyty fizyczne modułu 0, odczyty modułu z wyprzedzeniem 0.
(1 wiersz(e) dotyczy)
Czasy wykonywania programu SQL Server:
Czas procesora =0 ms, czas, który upłynął =83 ms.
Jeśli spojrzę na plany wykonania, są one takie same dla obu baz danych, z wyjątkiem rzeczywistych wartości (ilości danych, które faktycznie przeszły przez plan):
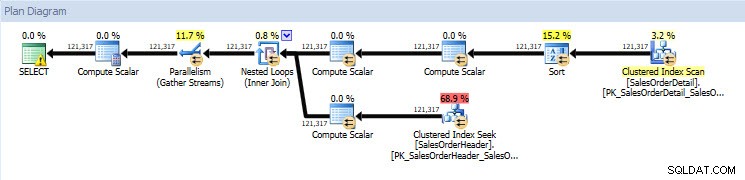 Plan zapytań do bazy danych AdventureWorks2014
Plan zapytań do bazy danych AdventureWorks2014
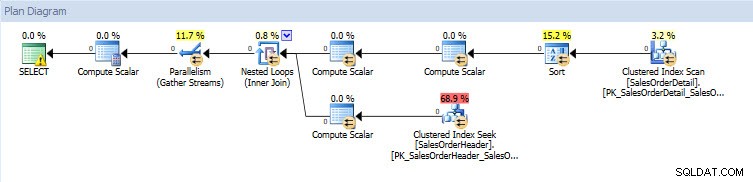 Plan zapytań do bazy danych AdventureWorks2014_CLONE
Plan zapytań do bazy danych AdventureWorks2014_CLONE
W tym miejscu wartość DBCC CLONEDATABASE jest oczywiste – mogę otrzymać pustą kopię bazy danych każdemu (pomoc techniczna firmy Microsoft, mój kolega administrator danych itp.) i poprosić ich o odtworzenie i zbadanie problemu, i nie potrzebują do tego potencjalnie setek GB miejsca na dysku to. Lipcowy wpis Melissy o T-SQL we wtorek zawiera szczegółowe informacje o tym, co dzieje się podczas procesu klonowania, więc polecam go przeczytać, aby uzyskać więcej informacji.
Czy o to chodzi?
Ale… czy mogę zrobić więcej z DBCC CLONEDATABASE? ? To znaczy, to jest świetne, ale myślę, że jest wiele innych rzeczy, które mogę zrobić z pustą kopią bazy danych. Jeśli przeczytałeś dokumentację dla DBCC CLONEDATABASE , zobaczysz tę linię:
Moja pierwsza myśl brzmiała:„Optymalizator zapytań – hmm… czy mogę użyć tego jako opcji do testowania uaktualnień ?”
Cóż, sklonowana baza danych jest tylko do odczytu, ale pomyślałem, że i tak spróbuję zmienić niektóre opcje. Na przykład, gdybym mógł zmienić tryb zgodności, byłoby to naprawdę fajne, ponieważ wtedy mógłbym przetestować zmiany CE zarówno w SQL Server 2014, jak i SQL Server 2016.
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
Pojawia się błąd:
Msg 3906, Poziom 16, Stan 1Nie udało się zaktualizować bazy danych „AdventureWorks2014_CLONE”, ponieważ baza danych jest tylko do odczytu.
Msg 5069, Poziom 16, Stan 1
Instrukcja ALTER DATABASE nie powiodła się.
Hm. Czy mogę zmienić model odzyskiwania?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
Mogę. To nie wydaje się sprawiedliwe. Cóż, jest tylko do odczytu, czy mogę to zmienić?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
TAK! Zanim się zbytnio podekscytujesz, pozwól, że zostawię tę notatkę z dokumentacji tutaj:
Uwaga Nowo wygenerowana baza danych wygenerowana z DBCC CLONEDATABASE nie jest obsługiwana do użycia jako produkcyjna baza danych i jest przeznaczona głównie do rozwiązywania problemów i celów diagnostycznych. Zalecamy odłączenie sklonowanej bazy danych po utworzeniu bazy danych.Powtórzę ten wiersz z dokumentacji, pogrubię go i zaznaczę na czerwono jako przyjazny, ale niezwykle ważny przypomnienie:
Nowo wygenerowana baza danych wygenerowana z DBCC CLONEDATABASE nie jest obsługiwana do użycia jako produkcyjna baza danych i jest przeznaczona głównie do rozwiązywania problemów i celów diagnostycznych.Cóż, to w porządku, zdecydowanie nie zamierzałem używać tego do produkcji, ale teraz mogę go użyć do testów! TERAZ mogę zmienić tryb zgodności, a TERAZ mogę wykonać kopię zapasową i przywrócić ją na innej instancji w celu przetestowania!
USE [master]; GO BACKUP DATABASE [AdventureWorks2014_CLONE] TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full'; GO /* restore on SQL Server 2016 */ RESTORE DATABASE [AdventureWorks2014_CLONE] FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf', MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf', NOUNLOAD, REPLACE, STATS = 5; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130; GO
TO JEST DUŻE.
W moim ostatnim poście mówiłem o flagi śledzenia 2389 i testowaniu za pomocą nowego modułu szacowania kardynalizacji, ponieważ, przyjaciele, potrzebujesz do testowania z nowym CE przed aktualizacją. Jeśli nie przeprowadzisz testów i zmienisz tryb zgodności na 120 (SQL Server 2014) lub 130 (SQL Server 2016) w ramach uaktualnienia, ryzykujesz pracę w trybie przeciwpożarowym, jeśli natkniesz się na regresje z nowym CE. Teraz możesz być w porządku, a wydajność może być jeszcze lepsza po uaktualnieniu. Ale… czy nie chciałbyś mieć pewności?
Bardzo często, gdy wspominam o testowaniu przed aktualizacją, słyszę, że nie ma środowiska, w którym można przeprowadzać testy. Wiem, że niektórzy z was mają środowisko testowe. Niektórzy z was mają Test, Dev, QA, UAT i kto wie co jeszcze. Masz szczęście.
Dla tych z was, którzy twierdzą, że w ogóle nie ma środowiska testowego, w którym można by testować, podaję DBCC CLONEDATABASE . Dzięki temu poleceniu nie masz wymówki, aby nie uruchamiać najczęściej wykonywanych zapytań i silnych trafień przeciwko klonowi Twojej bazy danych. Nawet jeśli nie masz środowiska testowego, masz własną maszynę. Utwórz kopię zapasową bazy danych klonów z produkcji, upuść klon, przywróć kopię zapasową do lokalnej instancji, a następnie przetestuj. Baza danych klonów zajmuje bardzo mało miejsca na dysku i nie narażasz się na rywalizację o pamięć ani we/wy, ponieważ nie ma danych. będziesz mieć możliwość sprawdzania poprawności planów zapytań z klonu względem planów z produkcyjnej bazy danych. Co więcej, jeśli przywracasz dane na SQL Server 2016, możesz włączyć Query Store do swoich testów! Włącz magazyn zapytań, przeprowadź testowanie w oryginalnym trybie zgodności, a następnie uaktualnij tryb zgodności i przetestuj ponownie. Możesz użyć Query Store do porównywania zapytań obok siebie! (Czy możesz powiedzieć, że teraz tańczę na krześle?)
Rozważania
Ponownie, nie powinno to być coś, czego można by użyć w środowisku produkcyjnym i wiem, że tego nie zrobiłbyś, ale trzeba to powtórzyć, ponieważ w obecnym stanie DBCC CLONEDATABASE nie jest w pełni kompletny . Zostało to odnotowane w artykule KB w obszarze obsługiwanych obiektów; obiekty, takie jak tabele zoptymalizowane pod kątem pamięci i tabele plików, nie są kopiowane, pełny tekst nie jest obsługiwany itp.
Teraz baza danych klonów nie jest pozbawiona wad. Jeśli przypadkowo uruchomisz odbudowę indeksu lub aktualizację statystyk w tej bazie danych, właśnie wyczyściłeś dane testowe. Stracisz oryginalne statystyki, których prawdopodobnie chciałeś w pierwszej kolejności. Na przykład, jeśli teraz sprawdzę statystyki dla indeksu klastrowego w SalesOrderHeader, otrzymam to:
USE [AdventureWorks2014_CLONE]; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Oryginalne statystyki dla SalesOrderHeader
Oryginalne statystyki dla SalesOrderHeader
Teraz, jeśli zaktualizuję statystyki względem tej tabeli, otrzymuję:
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Zaktualizowane (puste) statystyki dla SalesOrderHeader
Zaktualizowane (puste) statystyki dla SalesOrderHeader
Jako dodatkowe zabezpieczenie, prawdopodobnie dobrym pomysłem jest wyłączenie automatycznych aktualizacji statystyk:
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
Jeśli zdarzy ci się przypadkowo zaktualizować statystyki, uruchom DBCC CLONEDATABASE a przejście przez proces tworzenia kopii zapasowej i przywracania nie jest takie trudne, a zautomatyzujesz go w mgnieniu oka.
Możesz dodać dane do bazy danych. Może to być przydatne, jeśli chcesz poeksperymentować ze statystykami (np. różne częstotliwości próbkowania, filtrowane statystyki) i masz wystarczająco dużo miejsca na przechowywanie kopii danych z tabeli.
Bez danych w bazie danych oczywiście nie uzyskasz rzetelnie reprezentatywnego czasu trwania i danych we/wy. W porządku. Jeśli potrzebujesz danych o rzeczywistym wykorzystaniu zasobów, potrzebujesz kopii swojej bazy danych ze wszystkimi zawartymi w niej danymi. DBCC CLONEDATABASE tak naprawdę dotyczy testowania wydajności zapytań; Otóż to. W żaden sposób nie zastępuje tradycyjnego testowania aktualizacji — jest to jednak nowa opcja sprawdzania, w jaki sposób SQL Server optymalizuje zapytanie z różnymi wersjami i trybami zgodności. Miłego testowania!