Autor gościnny:Monica Rathbun (@SQLEspresso)
Czasami problemy z wydajnością sprzętu, takie jak opóźnienia we/wy dysku, sprowadzają się do niezoptymalizowanego obciążenia, a nie do słabego sprzętu. Wielu administratorów baz danych, w tym ja, chce natychmiast obwiniać pamięć masową za powolność. Zanim pójdziesz i wydasz mnóstwo pieniędzy na nowy sprzęt, zawsze powinieneś sprawdzić swoje obciążenie pod kątem niepotrzebnych operacji we/wy.
Rzeczy do zbadania
| Przedmiot | Wpływ we/wy | Możliwe rozwiązania |
|---|---|---|
| Nieużywane indeksy | Dodatkowe zapisy | Usuń / wyłącz indeks |
| Brakujące indeksy | Dodatkowe odczyty | Dodaj indeks / indeksy obejmujące |
| Konwersje niejawne | Dodatkowe odczyty i zapisy | Ukryj lub rzutuj pole u źródła przed oceną wartości |
| Funkcje | Dodatkowe odczyty i zapisy | Usunąłem je, przekonwertuj dane przed oceną |
| ETL | Dodatkowe odczyty i zapisy | Użyj SSIS, replikacji, zmiany przechwytywania danych, grup dostępności |
| Według zamówień i grup | Dodatkowe odczyty i zapisy | Usuń je tam, gdzie to możliwe |
Nieużywane indeksy
Wszyscy znamy siłę indeksu. Posiadanie odpowiednich indeksów może spowodować różnicę lat świetlnych w szybkości zapytań. Jednak ilu z nas stale utrzymuje swoje indeksy poza przebudową indeksu i reorganizacją? Ważne jest, aby regularnie uruchamiać skrypt indeksu, aby ocenić, które indeksy są faktycznie używane. Osobiście używam w tym celu pytań diagnostycznych Glenna Berry'ego.
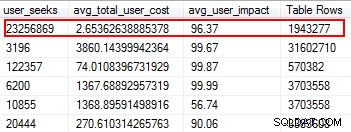
Zdziwisz się, gdy odkryjesz, że niektóre z Twoich indeksów w ogóle nie zostały przeczytane. Indeksy te obciążają zasoby, zwłaszcza w przypadku wysoce transakcyjnej tabeli. Patrząc na wyniki, zwróć uwagę na te indeksy, które mają dużą liczbę zapisów w połączeniu z małą liczbą odczytów. W tym przykładzie widać, że marnuję zapisy. Indeks nieklastrowy został zapisany 11 milionów razy, ale odczytany tylko dwa razy.

Zaczynam od wyłączenia indeksów należących do tej kategorii, a następnie usuwam je po potwierdzeniu, że nie pojawiły się żadne problemy. Regularne wykonywanie tego ćwiczenia może znacznie zmniejszyć niepotrzebne zapisy we/wy w systemie, ale należy pamiętać, że statystyki użytkowania indeksów są tak dobre, jak przy ostatnim ponownym uruchomieniu, więc przed odpisaniem upewnij się, że zbierałeś dane przez cały cykl biznesowy indeks jako „bezużyteczny”.
Brakujące indeksy
Brakujące indeksy to jedna z najłatwiejszych rzeczy do naprawienia; w końcu, kiedy uruchomisz plan wykonania, powie ci, czy jakieś indeksy nie zostały znalezione, ale byłoby to przydatne. Ale czekaj, mam nadzieję, że nie tylko arbitralnie dodajesz indeksy na podstawie tej sugestii. W ten sposób można tworzyć zduplikowane indeksy i indeksy, które mogą mieć minimalne użycie, a tym samym marnować operacje we/wy. Ponownie, wracając do skryptów Glenna, daje nam świetne narzędzie do oceny użyteczności indeksu poprzez dostarczanie wyszukiwań użytkowników, wpływu na użytkownika i liczby wierszy. Zwróć uwagę na te, które mają wysokie odczyty, a także niski koszt i wpływ. To świetne miejsce na początek, które pomoże Ci zmniejszyć liczbę operacji we/wy odczytu.
Niejawne konwersje
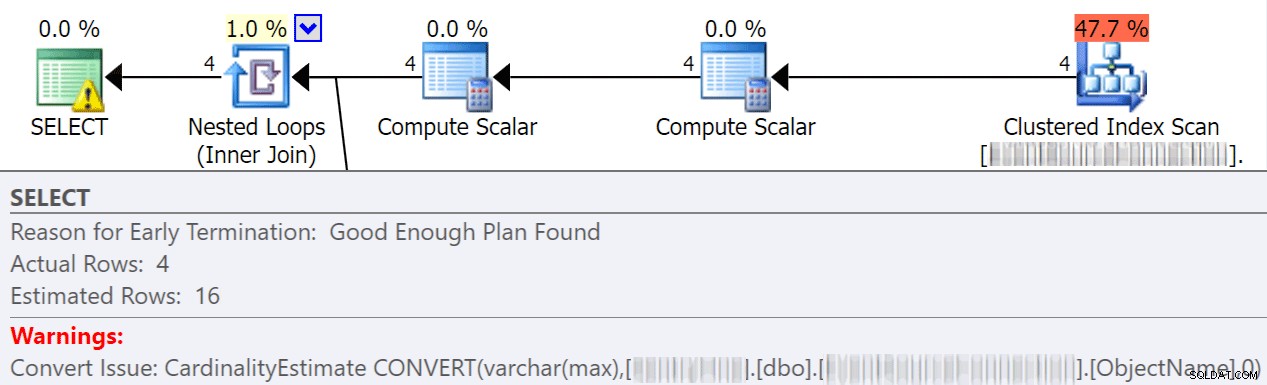
Konwersje niejawne często mają miejsce, gdy zapytanie porównuje co najmniej dwie kolumny z różnymi typami danych. W poniższym przykładzie system musi wykonać dodatkowe operacje we/wy w celu porównania kolumny varchar(max) z kolumną nvarchar(4000), co prowadzi do niejawnej konwersji i ostatecznie skanowania zamiast wyszukiwania. Naprawiając tabele tak, aby miały pasujące typy danych lub po prostu konwertując tę wartość przed oceną, możesz znacznie zmniejszyć liczbę operacji we/wy i poprawić kardynalność (szacowane wiersze, których powinien oczekiwać optymalizator).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias omawia znacznie więcej szczegółów w tym świetnym poście:„Jak drogie są niejawne konwersje po stronie kolumny?”
Funkcje
Jedną z najłatwiejszych do uniknięcia, łatwych do naprawienia rzeczy, na które natknąłem się, która pozwala zaoszczędzić na kosztach we/wy, jest usuwanie funkcji z klauzul where. Doskonałym przykładem jest porównanie dat, jak pokazano poniżej.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Niezależnie od tego, czy znajduje się w instrukcji JOIN, czy w klauzuli WHERE, powoduje to konwersję każdej kolumny przed jej oceną. Po prostu przekonwertując te kolumny przed oceną na tabelę tymczasową, możesz wyeliminować mnóstwo niepotrzebnych operacji we/wy.
Lub, jeszcze lepiej, w ogóle nie wykonuj żadnych konwersji (w tym konkretnym przypadku Aaron Bertrand mówi tutaj o unikaniu funkcji w klauzuli WHERE i zauważ, że może to być złe, mimo że konwertowanie na datę jest możliwe do sargowania).
ETL
Poświęć trochę czasu na sprawdzenie, w jaki sposób ładowane są Twoje dane. Czy przycinasz i przeładowujesz tabele? Czy można zamiast tego wdrożyć replikację, replikę AG tylko do odczytu lub wysyłanie dzienników? Czy wszystkie tabele, do których się pisze, są rzeczywiście odczytywane? Jak ładujesz dane? Czy odbywa się to za pośrednictwem procedur składowanych czy SSIS? Badanie takich rzeczy może znacznie zredukować I/O.
W moim środowisku odkryłem, że każdego ranka przycinamy 48 tabel z ponad 120 milionami wierszy. Ponadto ładowaliśmy 9,6 miliona wierszy co godzinę. Możesz sobie wyobrazić, ile niepotrzebnych I/O stworzyło. W moim przypadku wdrożenie replikacji transakcyjnej było moim wyborem. Po wdrożeniu mieliśmy znacznie mniej skarg użytkowników na spowolnienia w czasie ładowania, które początkowo przypisywano wolnej pamięci masowej.
Uporządkuj według i grupuj według
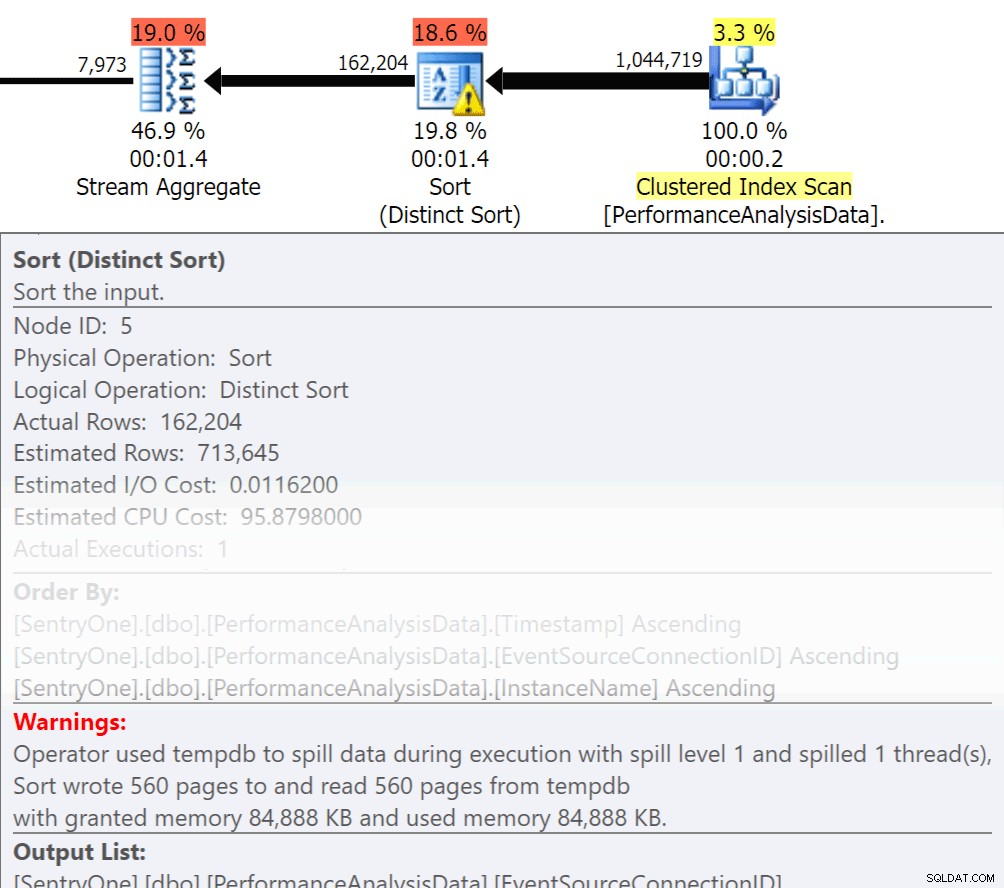 Zadaj sobie pytanie, czy te dane muszą być zwracane w kolejności? Czy naprawdę musimy grupować się w procedurze, czy poradzimy sobie z tym w raporcie lub aplikacji? Operacje Sortuj według i Grupuj według mogą powodować rozlewanie się odczytów na dysk, co powoduje dodatkowe operacje we/wy dysku. Jeśli te działania są uzasadnione, upewnij się, że masz pomocnicze indeksy i świeże statystyki dotyczące sortowanych lub grupowanych kolumn. Pomoże to optymalizatorowi podczas tworzenia planu. Ponieważ czasami używamy Order By i Group By w tabelach tymczasowych. upewnij się, że masz włączone automatyczne tworzenie statystyk dla TEMPDB, a także bazy danych użytkowników. Im bardziej aktualne są statystyki, tym lepszą kardynalność może uzyskać optymalizator, co skutkuje lepszymi planami, mniejszym rozlaniem i mniejszą liczbą operacji we/wy.
Zadaj sobie pytanie, czy te dane muszą być zwracane w kolejności? Czy naprawdę musimy grupować się w procedurze, czy poradzimy sobie z tym w raporcie lub aplikacji? Operacje Sortuj według i Grupuj według mogą powodować rozlewanie się odczytów na dysk, co powoduje dodatkowe operacje we/wy dysku. Jeśli te działania są uzasadnione, upewnij się, że masz pomocnicze indeksy i świeże statystyki dotyczące sortowanych lub grupowanych kolumn. Pomoże to optymalizatorowi podczas tworzenia planu. Ponieważ czasami używamy Order By i Group By w tabelach tymczasowych. upewnij się, że masz włączone automatyczne tworzenie statystyk dla TEMPDB, a także bazy danych użytkowników. Im bardziej aktualne są statystyki, tym lepszą kardynalność może uzyskać optymalizator, co skutkuje lepszymi planami, mniejszym rozlaniem i mniejszą liczbą operacji we/wy.
Teraz Group By zdecydowanie ma swoje miejsce, jeśli chodzi o agregowanie danych zamiast zwracania mnóstwa wierszy. Ale kluczem jest tutaj redukcja I/O, dodanie agregacji dodaje do I/O.
Podsumowanie
To tylko wierzchołki góry lodowej rzeczy do zrobienia, ale świetne miejsce do rozpoczęcia redukcji I/O. Zanim zaczniesz obwiniać sprzęt o problemy z opóźnieniami, zobacz, co możesz zrobić, aby zminimalizować ciśnienie dysku.
O autorze
 Monica Rathbun jest obecnie konsultantem w firmie Denny Cherry &Associates Consulting oraz Microsoft Data Platform MVP. Od 15 lat jest Lone DBA, zajmując się wszystkimi aspektami SQL Server i Oracle. Podróżuje, przemawiając w SQLSaturdays, pomagając innym Lone DBA z technikami, jak można wykonywać pracę wielu osób. Monica jest liderem grupy użytkowników serwera SQL Hampton Roads i jest regionalnym mentorem Mid-Atlantic Pass. Zawsze możesz znaleźć Monikę na Twitterze (@SQLEspresso) rozdającą pomocne wskazówki i triki swoim obserwatorom. Kiedy nie jest zajęta pracą, znajdziesz ją jako taksówkarza dla swoich dwóch córek na lekcjach tańca.
Monica Rathbun jest obecnie konsultantem w firmie Denny Cherry &Associates Consulting oraz Microsoft Data Platform MVP. Od 15 lat jest Lone DBA, zajmując się wszystkimi aspektami SQL Server i Oracle. Podróżuje, przemawiając w SQLSaturdays, pomagając innym Lone DBA z technikami, jak można wykonywać pracę wielu osób. Monica jest liderem grupy użytkowników serwera SQL Hampton Roads i jest regionalnym mentorem Mid-Atlantic Pass. Zawsze możesz znaleźć Monikę na Twitterze (@SQLEspresso) rozdającą pomocne wskazówki i triki swoim obserwatorom. Kiedy nie jest zajęta pracą, znajdziesz ją jako taksówkarza dla swoich dwóch córek na lekcjach tańca.