W tym artykule pokazano, w jaki sposób SQL Server łączy informacje o gęstości z wielu jednokolumnowych statystyk w celu oszacowania liczności dla agregacji w wielu kolumnach. Miejmy nadzieję, że szczegóły same w sobie są interesujące. Zapewniają również wgląd w niektóre ogólne podejścia i algorytmy stosowane przez estymator kardynalności.
Rozważ następującą przykładową kwerendę bazy danych AdventureWorks, która zawiera listę pozycji zapasów produktów w każdym pojemniku na każdej półce w magazynie:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
Szacowany plan wykonania pokazuje 1069 wierszy odczytanych z tabeli, posortowanych na Shelf i Bin zamówienia, a następnie agregowane za pomocą operatora Stream Aggregate:
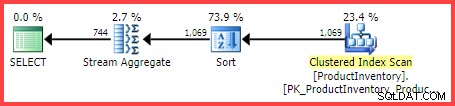
Szacowany plan wykonania
Pytanie brzmi, w jaki sposób optymalizator zapytań SQL Server uzyskał ostateczne oszacowanie 744 wierszy?
Dostępne statystyki
Podczas kompilowania powyższego zapytania optymalizator zapytań utworzy jednokolumnowe statystyki na Shelf i Bin kolumny, jeśli odpowiednie statystyki jeszcze nie istnieją. Statystyki te dostarczają między innymi informacji o liczbie różnych wartości kolumn (w wektorze gęstości):
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Wyniki podsumowano w poniższej tabeli (trzecia kolumna jest obliczana na podstawie gęstości):
| Kolumna | Gęstość | 1 / Gęstość |
|---|---|---|
| Półka | 0.04761905 | 21 |
| Kosz | 0.01612903 | 62 |
Informacje o wektorach gęstości półek i pojemników
Jak zauważa dokumentacja, odwrotnością gęstości jest liczba różnych wartości w kolumnie. Z informacji statystycznych przedstawionych powyżej, SQL Server wie, że było 21 różnych Shelf wartości i 62 różne Bin wartości w tabeli, kiedy zebrano statystyki.
Zadanie oszacowania liczby wierszy utworzonych przez GROUP BY klauzula jest trywialna, gdy w grę wchodzi tylko jedna kolumna (zakładając, że nie ma innych predykatów). Na przykład łatwo zauważyć, że GROUP BY Shelf wyprodukuje 21 rzędów; GROUP BY Bin wyprodukuje 62.
Jednak nie jest od razu jasne, w jaki sposób SQL Server może oszacować liczbę odrębnych (Shelf, Bin) kombinacje dla naszych półek GROUP BY Shelf, Bin zapytanie. Ujmując to pytanie w nieco inny sposób:biorąc pod uwagę 21 półek i 62 kosze, ile będzie unikalnych kombinacji półek i koszy? Pomijając aspekty fizyczne i inną ludzką wiedzę na temat dziedziny problemu, odpowiedź może zawierać się w dowolnym miejscu od max(21, 62) =62 do (21 * 62) =1,302. Bez dodatkowych informacji nie ma oczywistego sposobu, aby dowiedzieć się, gdzie podać oszacowanie w tym zakresie.
Jednak dla naszego przykładowego zapytania SQL Server szacuje 744.312 wiersze (zaokrąglone do 744 w widoku Eksploratora planów), ale na jakiej podstawie?
Rozszerzone wydarzenie szacowania kardynalności
Udokumentowanym sposobem przyjrzenia się procesowi szacowania liczności jest użycie zdarzenia rozszerzonego query_optimizer_estimate_cardinality (pomimo tego, że jest w kanale "debugowania"). Podczas sesji zbierającej to zdarzenie operatorzy planu wykonania zyskują dodatkową właściwość StatsCollectionId która łączy indywidualne szacunki operatora z obliczeniami, które je stworzyły. W naszym przykładowym zapytaniu identyfikator zbioru statystyk 2 jest połączony z oszacowaną licznością dla grupy za pomocą operatora agregacji.
Odpowiednie dane wyjściowe z zdarzenia rozszerzonego dla naszego zapytania testowego to:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Na pewno jest tam kilka przydatnych informacji.
Widzimy, że plan pozostawia klasę kalkulatora różnych wartości (CDVCPlanLeaf ) został wykorzystany przy użyciu statystyk jednokolumnowych na Shelf i Bin jako wejścia. Element zbierania statystyk dopasowuje ten fragment do identyfikatora (2) pokazanego w planie wykonania, który pokazuje szacunkową kardynalność wynoszącą 744.31 , a także więcej informacji o użytych identyfikatorach obiektów statystyk.
Niestety, w danych wyjściowych zdarzenia nie ma nic, co mogłoby dokładnie powiedzieć, w jaki sposób kalkulator osiągnął ostateczną wartość, co nas naprawdę interesuje.
Łączenie różnych liczb
Idąc mniej udokumentowaną trasą, możemy poprosić o szacunkowy plan zapytania z flagami śledzenia 2363 i 3604 włączone:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Spowoduje to zwrócenie informacji debugowania na kartę Komunikaty w programie SQL Server Management Studio. Ciekawa część jest reprodukowana poniżej:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Pokazuje to w dużej mierze te same informacje, co zdarzenie rozszerzone, w (prawdopodobnie) łatwiejszym do wykorzystania formacie:
- Wejściowy operator relacyjny do obliczenia szacunkowej liczności dla (
LogOp_GbAgg– grupowanie logiczne według agregatu) - Użyty kalkulator (
CDVCPlanLeaf) i statystyki wejściowe - Szczegóły zebranych statystyk wynikowych
Ciekawą nową informacją jest część dotycząca używania kardynalności otoczenia do łączenia odrębnych liczb .
To wyraźnie pokazuje, że użyto wartości 21, 62 i 1069, ale (frustrująco) nadal nie do końca dokładnie, które obliczenia zostały wykonane, aby uzyskać 744.312 wynik.
Do debugera!
Dołączenie debugera i użycie symboli publicznych pozwala nam szczegółowo zbadać ścieżkę kodu, którą podążamy podczas kompilowania przykładowego zapytania.
Poniższy zrzut ekranu pokazuje górną część stosu wywołań w reprezentatywnym punkcie procesu:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Jest tu kilka interesujących szczegółów. Pracując od dołu do góry, widzimy, że liczność jest obliczana przy użyciu zaktualizowanego CE (CCardFrameworkSQL12 ) dostępne w SQL Server 2014 i nowszych (oryginalny CE to CCardFrameworkSQL7 ), dla grupy przez zagregowany operator logiczny (CLogOp_GbAgg ).
Obliczanie odrębnej kardynalności polega na łączeniu (mungingu) wielu danych wejściowych przy użyciu próbkowania bez zastępowania.
Odniesienie do H a logarytm (naturalny) w drugiej metodzie od góry pokazuje użycie Entropii Shannona w obliczeniach:
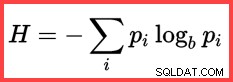
Entropia Shannona
Entropię można wykorzystać do oszacowania korelacji informacyjnej (informacji wzajemnych) między dwiema statystykami:
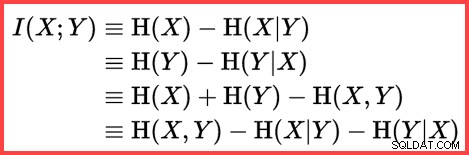
Wzajemne informacje
Łącząc to wszystko razem, możemy skonstruować skrypt obliczeniowy T-SQL pasujący do sposobu, w jaki SQL Server używa próbkowania bez zastępowania, entropii Shannona i wzajemnych informacji aby uzyskać ostateczne oszacowanie kardynalności.
Zaczynamy od liczb wejściowych (liczność otoczenia i liczba odrębnych wartości w każdej kolumnie):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; Częstotliwość każdej kolumny to średnia liczba wierszy na odrębną wartość:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Próbkowanie bez zastępowania (SWR) to prosta kwestia odjęcia średniej liczby wierszy na odrębną wartość (częstotliwość) od całkowitej liczby wierszy:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Oblicz entropie (N log N) i wzajemne informacje:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Teraz oszacowaliśmy, jak skorelowane są te dwa zestawy statystyk, możemy obliczyć ostateczne oszacowanie:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
Wynik obliczenia to 744.311823994677, czyli 744.312 zaokrąglone do trzech miejsc po przecinku.
Dla wygody, oto cały kod w jednym bloku:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Ostateczne myśli
Ostateczne oszacowanie jest w tym przypadku niedoskonałe – przykładowe zapytanie faktycznie zwraca 441 wiersze.
Aby uzyskać lepsze oszacowanie, możemy dostarczyć optymalizatorowi lepsze informacje o gęstości Bin i Shelf kolumny przy użyciu statystyki wielokolumnowej. Na przykład:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Mając tę statystykę (jako podaną, albo jako efekt uboczny dodania podobnego indeksu wielokolumnowego), oszacowanie kardynalności dla przykładowego zapytania jest dokładnie poprawne. Rzadko jednak zdarza się obliczyć tak prostą agregację. Z dodatkowymi predykatami statystyka wielokolumnowa może być mniej skuteczna. Niemniej jednak ważne jest, aby pamiętać, że dodatkowe informacje o gęstości dostarczane przez statystyki wielokolumnowe mogą być przydatne do agregacji (jak również do porównań równości).
Bez statystyki wielokolumnowej zapytanie agregujące z dodatkowymi predykatami może nadal korzystać z podstawowej logiki przedstawionej w tym artykule. Na przykład, zamiast stosować formułę do liczności tabeli, można ją zastosować do wprowadzania histogramów krok po kroku.
Treść powiązana:Szacowanie liczności dla predykatu w wyrażeniu COUNT