Dwie poważne luki w zabezpieczeniach (nazwa kodowa Meltdown i Spectre) zostały ujawnione kilka tygodni temu. Wstępne testy sugerowały, że wpływ łagodzenia skutków (dodanych w jądrze) na wydajność może wynosić do ~30% dla niektórych obciążeń, w zależności od szybkości wywołań systemowych.
Te wczesne szacunki musiały zostać wykonane szybko, a więc opierały się na ograniczonej liczbie testów. Co więcej, poprawki w jądrze ewoluowały i ulepszały się z biegiem czasu, a teraz otrzymaliśmy także retpoline które powinno dotyczyć Spectre v2. Ten post przedstawia dane z dokładniejszych testów, miejmy nadzieję, że zapewnią bardziej wiarygodne szacunki dla typowych obciążeń PostgreSQL.
W porównaniu z wczesną oceną poprawek Meltdown, którą Simon opublikował 10 stycznia, dane przedstawione w tym poście są bardziej szczegółowe, ale ogólne wyniki meczów przedstawione w tym poście.
Ten post koncentruje się na obciążeniach PostgreSQL i chociaż może być przydatny w innych systemach z wysokimi współczynnikami przełączania wywołań systemowych/kontekstu, z pewnością nie jest w jakiś sposób uniwersalny. Jeśli jesteś zainteresowany bardziej ogólnym wyjaśnieniem luk w zabezpieczeniach i oceną wpływu, Brendan Gregg opublikował kilka dni temu doskonały artykuł KPTI/KAISER Meltdown Meltdown Initial Performance Regressions. Właściwie może być przydatne, aby najpierw go przeczytać, a następnie kontynuować ten post.
Uwaga: Ten post nie ma na celu zniechęcenia do instalowania poprawek, ale pokazania, jaki może być wpływ na wydajność. Powinieneś zainstalować wszystkie poprawki, aby Twoje środowisko było bezpieczne, i skorzystaj z tego posta, aby zdecydować, czy konieczna będzie aktualizacja sprzętu itp.
Jakie testy zrobimy?
Przyjrzymy się dwóm typowym podstawowym typom obciążenia — OLTP (małe proste transakcje) i OLAP (złożone zapytania przetwarzające duże ilości danych). Większość systemów PostgreSQL może być modelowana jako połączenie tych dwóch typów obciążenia.
W przypadku OLTP użyliśmy pgbench, dobrze znanego narzędzia do testów porównawczych dostarczanego z PostgreSQL. Testowaliśmy oba w trybie tylko do odczytu (-S ) oraz do odczytu i zapisu (-N ) tryby, z trzema różnymi skalami – pasującymi do shared_buffers, do RAM i większych niż RAM.
W przypadku OLAP użyliśmy testu porównawczego dbt-3, który jest dość zbliżony do TPC-H, z dwoma różnymi rozmiarami danych – 10 GB, który mieści się w pamięci RAM i 50 GB, który jest większy niż pamięć RAM (biorąc pod uwagę indeksy itp.).
Wszystkie prezentowane liczby pochodzą z serwera z 2x Xeon E5-2620v4, 64 GB pamięci RAM i Intel SSD 750 (400 GB). System działał z Gentoo z jądrem 4.15.3, skompilowanym za pomocą GCC 7.3 (potrzebne, aby włączyć pełne retpoline naprawić). Te same testy przeprowadzono również na starszym/mniejszym systemie z procesorem i5-2500k, 8 GB pamięci RAM i 6x Intel S3700 SSD (w RAID-0). Ale zachowanie i wnioski są prawie takie same, więc nie będziemy przedstawiać tutaj danych.
Jak zwykle, kompletne skrypty/wyniki dla obu systemów są dostępne na github.
Ten post dotyczy wpływu złagodzenia na wydajność, więc nie skupiajmy się na liczbach bezwzględnych, a zamiast tego przyjrzyjmy się wydajności w stosunku do systemu niezałatanego (bez złagodzenia jądra). Wszystkie wykresy w sekcji OLTP pokazują
(throughput with patches) / (throughput without patches)
Spodziewamy się liczb od 0% do 100%, przy czym wyższe wartości są lepsze (mniejszy wpływ środków łagodzących), 100% oznacza „brak wpływu”.
Uwaga: Oś y zaczyna się od 75%, aby różnice były bardziej widoczne.
OLTP / tylko do odczytu
Najpierw zobaczmy wyniki dla pgbench tylko do odczytu, wykonanego za pomocą tego polecenia
pgbench -n -c 16 -j 16 -S -T 1800 test
i ilustruje to poniższa tabela:
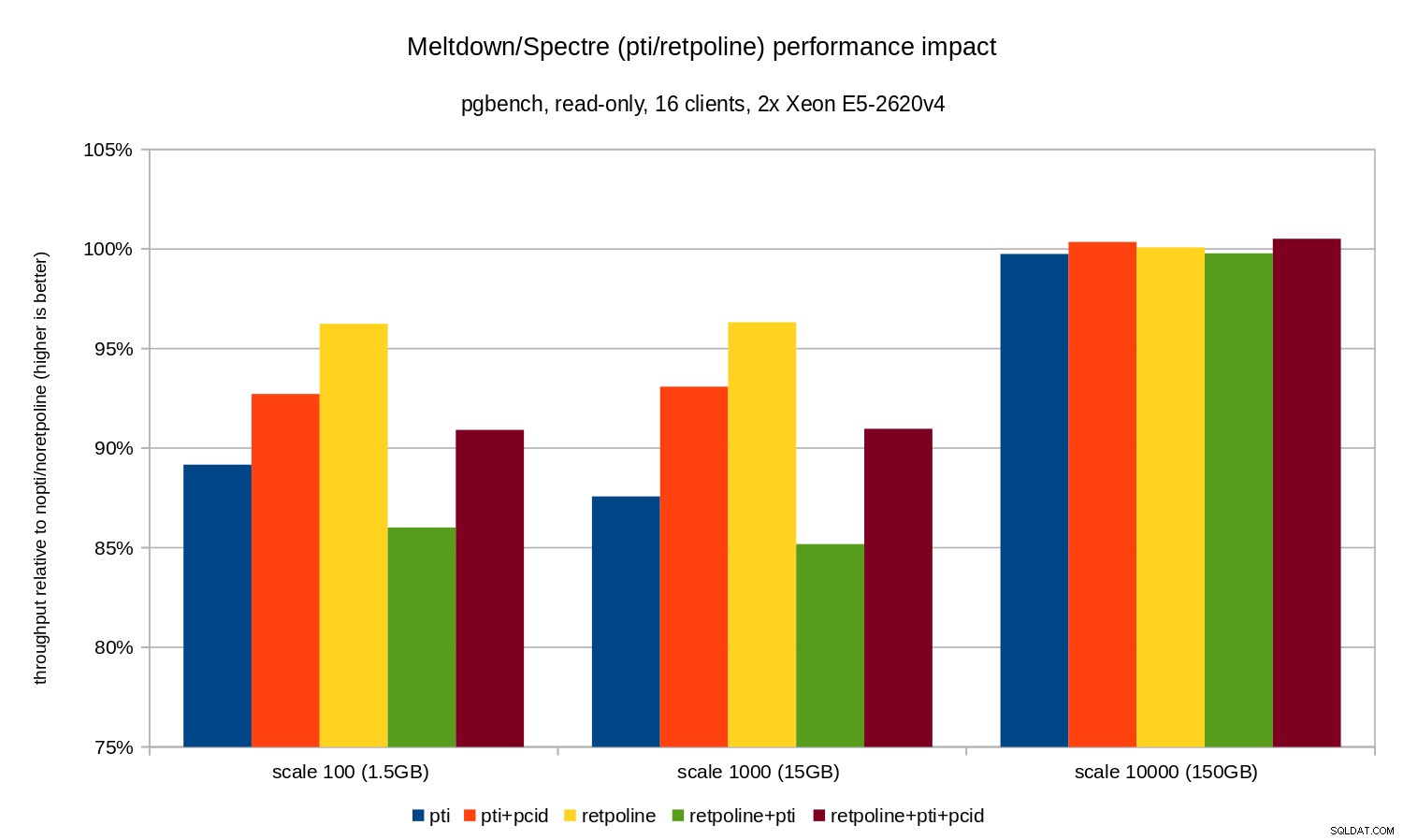
Jak widać, wpływ pti na wydajność dla skal, które mieszczą się w pamięci, wynosi około 10-12% i jest prawie niemierzalne, gdy obciążenie staje się związane z we/wy. Co więcej, regresja jest znacznie zmniejszona (lub całkowicie znika), gdy pcid jest włączony. Jest to zgodne z twierdzeniem, że PCID jest obecnie krytyczną funkcją wydajności/bezpieczeństwa na x86. Wpływ retpoline jest znacznie mniejszy – mniej niż 4% w najgorszym przypadku, co łatwo może być spowodowane hałasem.
OLTP / odczyt-zapis
Testy odczytu i zapisu zostały wykonane przez pgbench polecenie podobne do tego:
pgbench -n -c 16 -j 16 -N -T 3600 test
Czas trwania był wystarczająco długi, aby objąć wiele punktów kontrolnych, a -N został użyty do wyeliminowania rywalizacji o blokady w wierszach w (malutkiej) tabeli rozgałęzień. Względną wydajność ilustruje poniższy wykres:
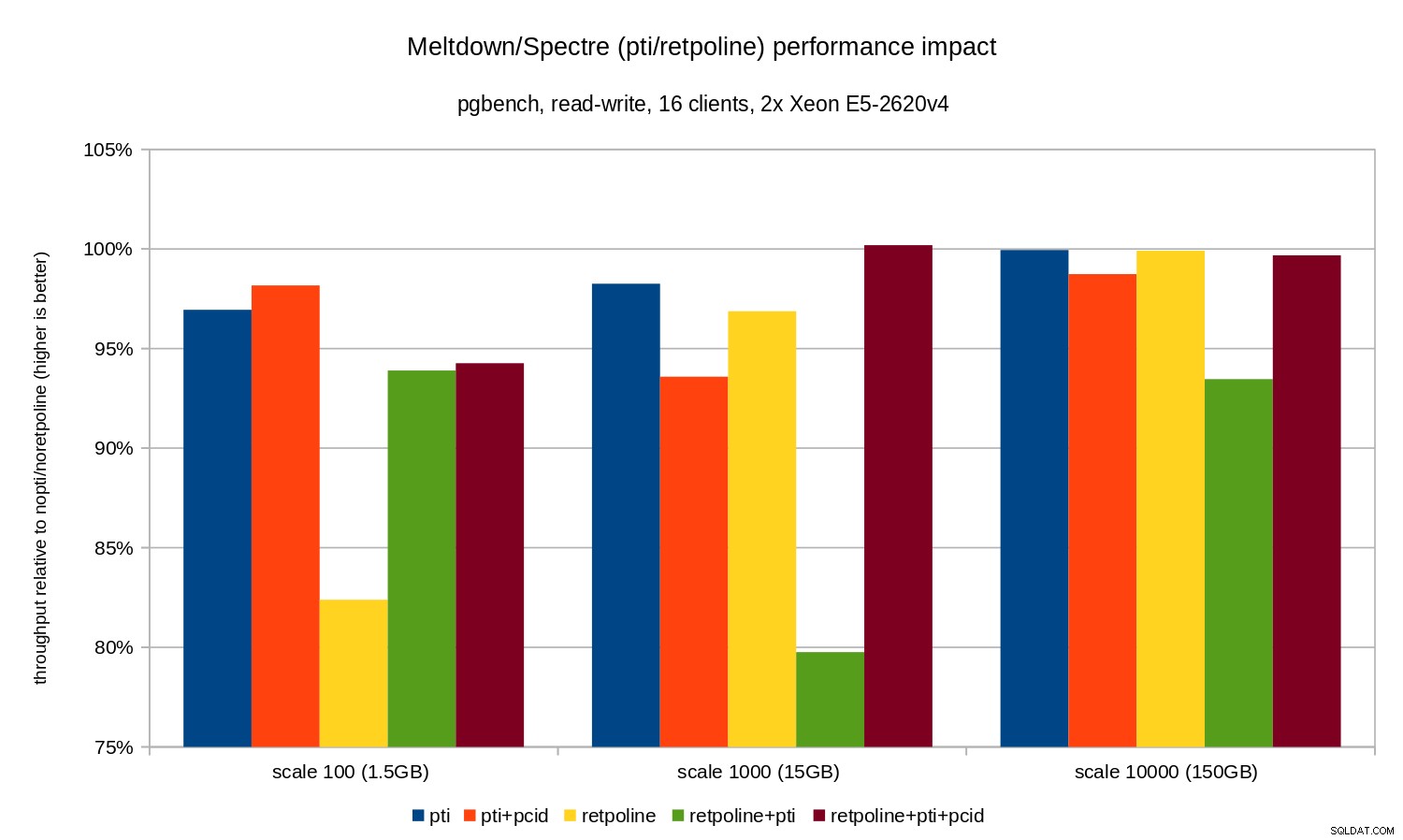
Regresje są nieco mniejsze niż w przypadku tylko do odczytu – mniej niż 8% bez pcid i mniej niż 3% z pcid włączony. Jest to naturalna konsekwencja spędzania większej ilości czasu na wykonywaniu operacji we/wy podczas zapisywania danych do WAL, opróżniania zmodyfikowanych buforów podczas punktu kontrolnego itp.
Są jednak dwa dziwne fragmenty. Po pierwsze, wpływ retpoline jest nieoczekiwanie duży (blisko 20%) dla skali 100 i to samo stało się dla retpoline+pti w skali 1000. Przyczyny nie są do końca jasne i będą wymagały dodatkowego zbadania.
OLAP
Obciążenie analityczne zostało wymodelowane przez benchmark dbt-3. Najpierw spójrzmy na wyniki w skali 10 GB, które w całości mieszczą się w pamięci RAM (w tym wszystkie indeksy itp.). Podobnie jak w przypadku OLTP nie interesują nas liczby bezwzględne, które w tym przypadku byłyby czasem trwania poszczególnych zapytań. Zamiast tego przyjrzymy się spowolnieniu w porównaniu do nopti/noretpoline , czyli:
(duration without patches) / (duration with patches)
Zakładając, że działania łagodzące spowodują spowolnienie, otrzymamy wartości od 0% do 100%, gdzie 100% oznacza „brak wpływu”. Wyniki wyglądają tak:
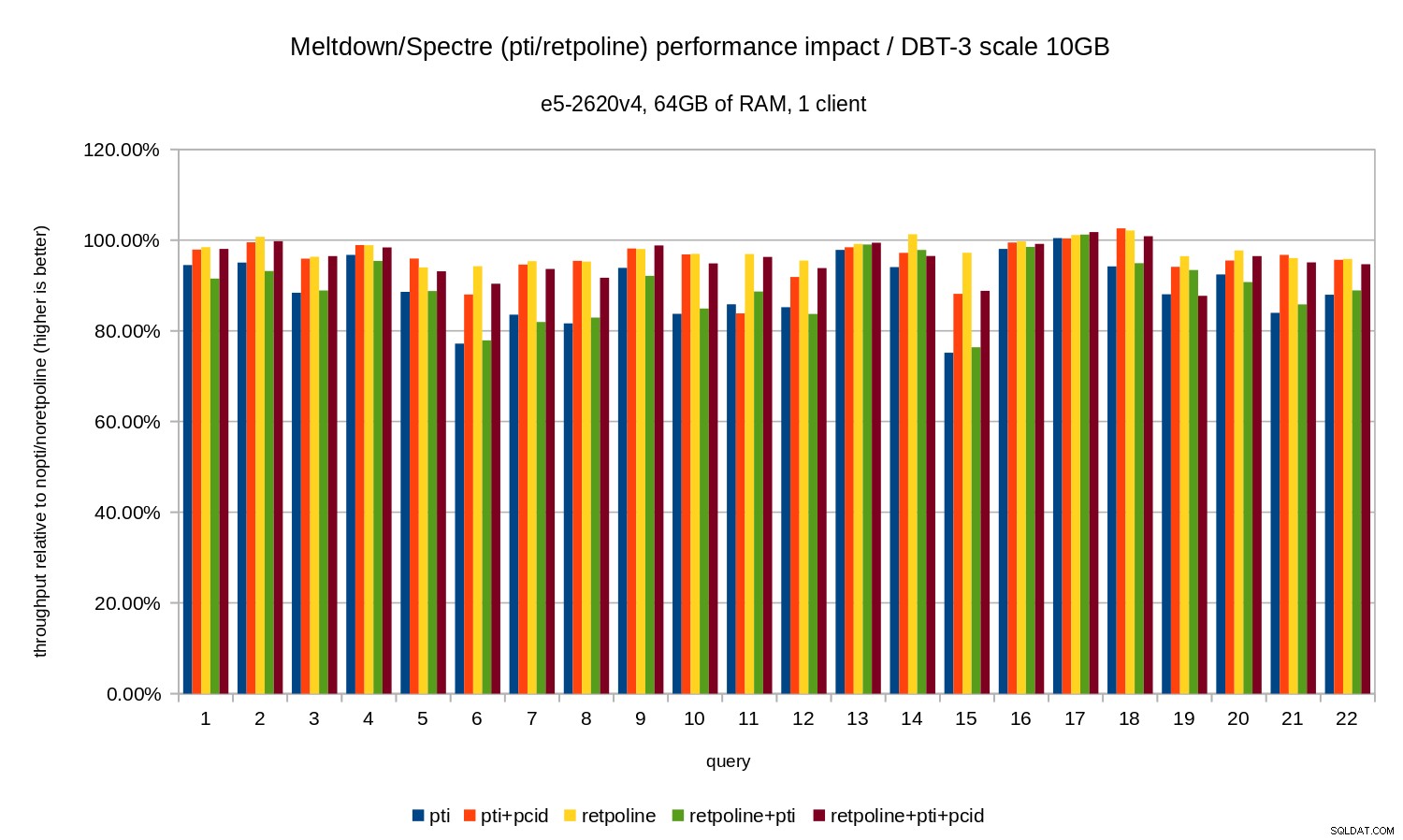
To znaczy bez pcid regresja zazwyczaj mieści się w zakresie 10-20%, w zależności od zapytania. I z pcid regresja spada do mniej niż 5% (i ogólnie blisko 0%). Po raz kolejny potwierdza to znaczenie pcid funkcja.
Dla zestawu danych 50 GB (czyli około 120 GB ze wszystkimi indeksami itp.) wpływ wygląda następująco:
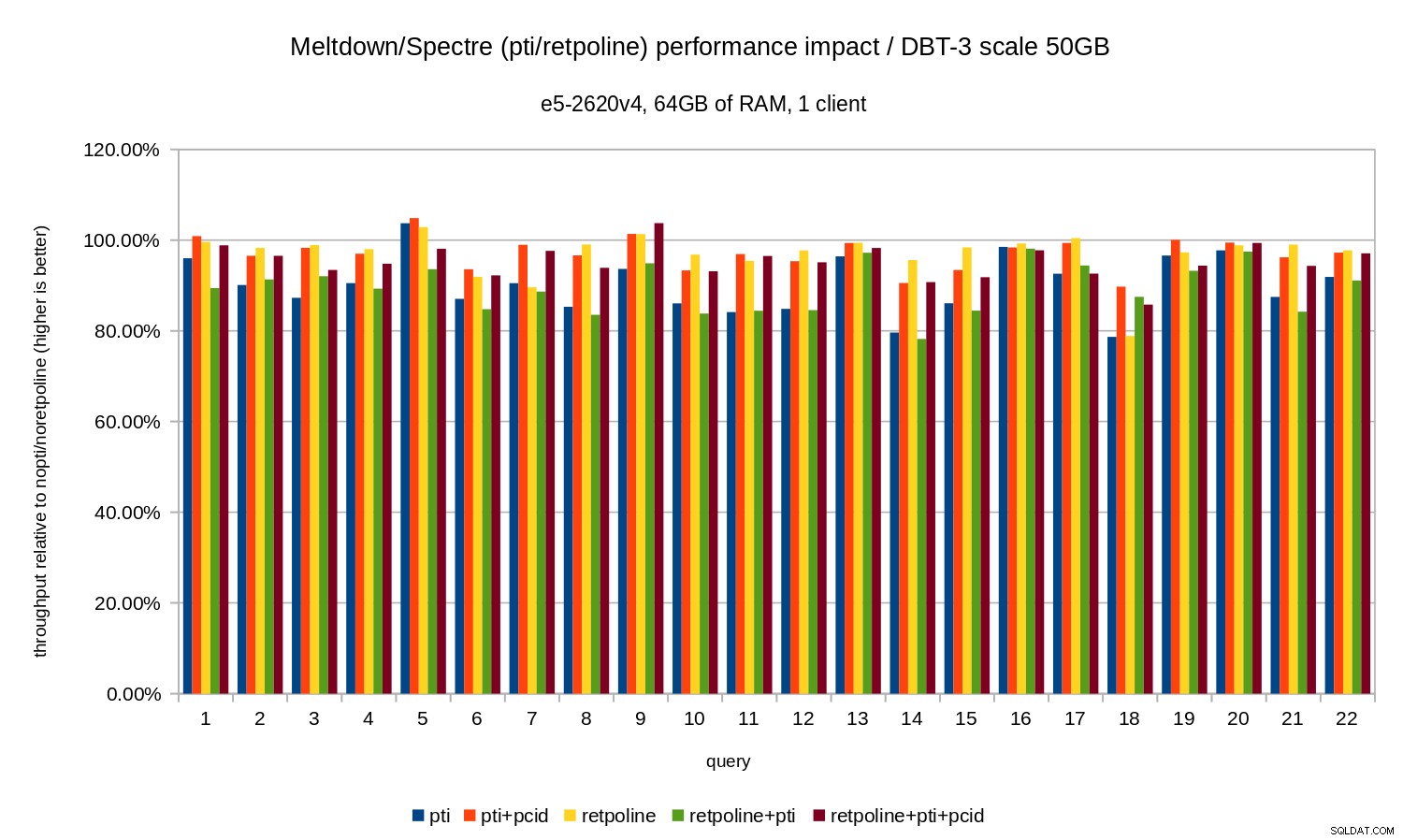
Tak jak w przypadku 10 GB, regresje są poniżej 20% i pcid znacznie je zmniejsza – w większości przypadków blisko 0%.
Poprzednie wykresy są nieco zaśmiecone – są 22 zapytania i 5 serii danych, czyli trochę za dużo jak na pojedynczy wykres. Oto wykres pokazujący wpływ tylko dla wszystkich trzech funkcji (pti , pcid i retpoline ), dla obu rozmiarów zestawów danych.
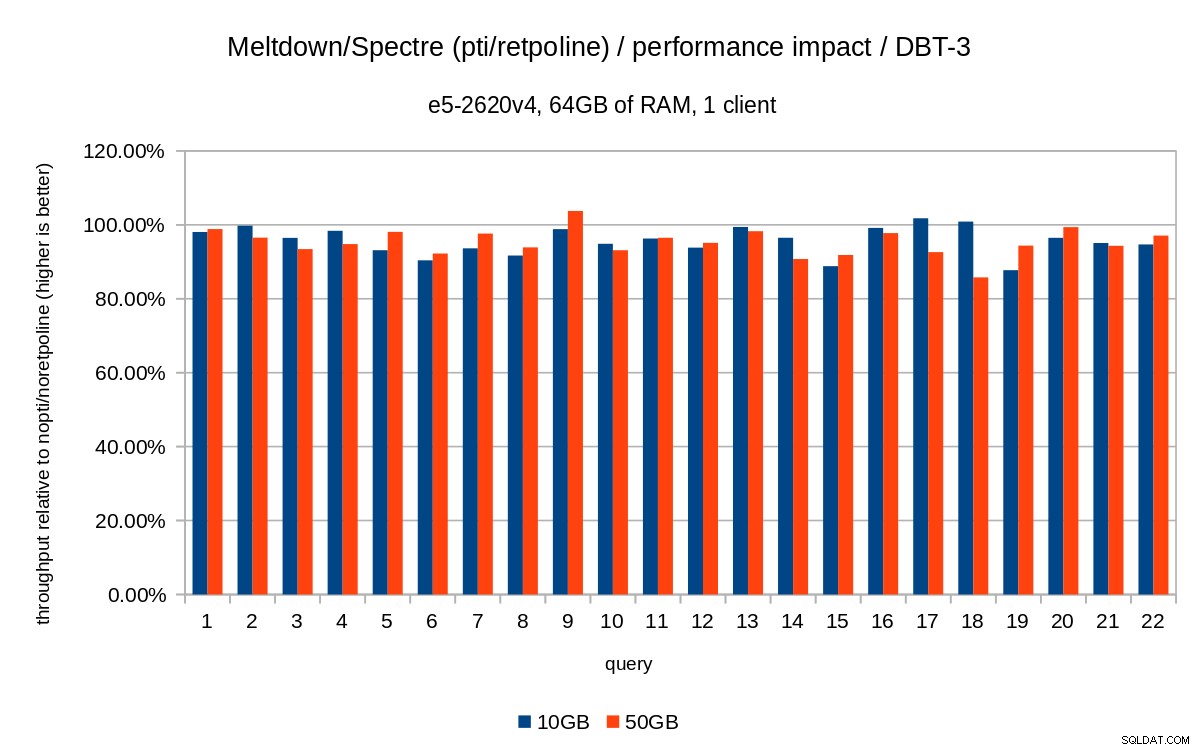
Wniosek
Krótko podsumowując wyniki:
retpolinema bardzo mały wpływ na wydajność- OLTP – regresja wynosi około 10-15% bez
pcidi około 1-5% zpcid. - OLAP – regresja wynosi do 20% bez
pcidi około 1-5% zpcid. - W przypadku obciążeń związanych z we/wy (np. OLTP z największym zbiorem danych) Meltdown ma znikomy wpływ.
Wpływ wydaje się być znacznie niższy niż wstępne szacunki sugerujące (30%), przynajmniej dla testowanych obciążeń. Wiele systemów działa z 70-80% CPU w okresach szczytowych, a 30% całkowicie nasyciłoby moc CPU. Ale w praktyce wpływ wydaje się być niższy niż 5%, przynajmniej gdy pcid używana jest opcja.
Nie zrozum mnie źle, 5% spadek to wciąż poważna regresja. Z pewnością jest to coś, na czym nam zależy podczas tworzenia PostgreSQL, m.in. przy ocenie wpływu proponowanych poprawek. Ale jest to coś, co istniejące systemy powinny dobrze sobie radzić – jeśli 5% wzrost wykorzystania procesora sprawi, że Twój system przewyższy egde, masz problemy nawet bez Meltdown/Spectre.
Oczywiście to nie koniec poprawek Meltdown/Spectre. Twórcy jądra wciąż pracują nad poprawą zabezpieczeń i dodaniem nowych, a Intel i inni producenci procesorów pracują nad aktualizacjami mikrokodu. I nie jest tak, że wiemy o wszystkich możliwych wariantach luk, ponieważ naukowcom udało się znaleźć nowe warianty ataków.
A więc jest więcej w przyszłości i ciekawie będzie zobaczyć, jaki będzie wpływ na wydajność.