SQL Server wprowadził obiekty OLTP w pamięci w SQL Server 2014. W początkowej wersji było wiele ograniczeń; niektóre zostały rozwiązane w SQL Server 2016 i oczekuje się, że więcej zostanie rozwiązanych w następnej wersji, ponieważ funkcja będzie nadal ewoluować. Jak dotąd przyjęcie In-Memory OLTP nie wydaje się zbyt rozpowszechnione, ale w miarę dojrzewania funkcji spodziewam się, że więcej klientów zacznie pytać o wdrożenie. Podobnie jak w przypadku każdej większej zmiany schematu lub kodu, zalecam dokładne przetestowanie, aby określić, czy OLTP w pamięci zapewni oczekiwane korzyści. Mając to na uwadze, chciałem zobaczyć, jak zmieniła się wydajność dla bardzo prostych instrukcji INSERT, UPDATE i DELETE z OLTP w pamięci. Miałem nadzieję, że gdybym mógł wykazać, że blokowanie lub blokowanie jest problemem w przypadku tabel opartych na dyskach, wówczas tabele w pamięci zapewnią rozwiązanie, ponieważ są wolne od blokad i blokad.
Opracowałem następujący test przypadki:
- Tablica dyskowa z tradycyjnymi procedurami składowanymi dla DML.
- Tabela w pamięci z tradycyjnymi procedurami składowanymi dla DML.
- Tabela w pamięci z natywnie skompilowanymi procedurami dla DML.
Byłem zainteresowany porównaniem wydajności tradycyjnych procedur składowanych i procedur kompilowanych natywnie, ponieważ jednym z ograniczeń procedury kompilowanej natywnie jest to, że wszystkie tabele, do których się odwołują, muszą znajdować się w pamięci. Chociaż jednowierszowe, pojedyncze modyfikacje mogą być powszechne w niektórych systemach, często widzę modyfikacje zachodzące w ramach większej procedury składowanej z wieloma instrukcjami (SELECT i DML) uzyskującymi dostęp do jednej lub większej liczby tabel. Dokumentacja OLTP w pamięci zdecydowanie zaleca używanie natywnie skompilowanych procedur, aby uzyskać jak największe korzyści pod względem wydajności. Chciałem zrozumieć, jak bardzo poprawiło to wydajność.
Konfiguracja
Stworzyłem bazę danych z grupą plików zoptymalizowaną pod kątem pamięci, a następnie utworzyłem trzy różne tabele w bazie danych (jedna na dysku, dwie w pamięci):
- Tabela dysków
- InMemory_Temp1
- InMemory_Temp2
DDL był prawie taki sam dla wszystkich obiektów, uwzględniając w stosownych przypadkach na dysku i w pamięci. DiskTable DDL a DDL w pamięci:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Stworzyłem również dziewięć procedur składowanych – po jednej dla każdej kombinacji tabeli/modyfikacji.
- DiskTable_Insert
- Aktualizacja tabeli dysków
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Aktualizacja
- InMemRegularSP _Usuń
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Każda procedura składowana akceptuje dane wejściowe w postaci liczb całkowitych w pętli dla tej liczby modyfikacji. Procedury składowane miały ten sam format, wariacje dotyczyły tylko dostępnej tabeli i tego, czy obiekt został skompilowany natywnie, czy nie. Pełny kod do tworzenia bazy danych i obiektów można znaleźć tutaj , z przykładowymi instrukcjami INSERT i UPDATE poniżej:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Uwaga:tabele IDs_* zostały ponownie wypełnione po zakończeniu każdego zestawu INSERT i były specyficzne dla trzech różnych scenariuszy.
Metodologia testowania
Testy przeprowadzono przy użyciu skryptów .cmd, które używały sqlcmd do wywoływania skryptu, który wykonywał procedurę składowaną, na przykład:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"wyjście
Użyłem tego podejścia do stworzenia jednego lub więcej połączeń do bazy danych, które będą działały współbieżnie. Oprócz zrozumienia podstawowych zmian wydajności, chciałem również zbadać wpływ różnych obciążeń. Skrypty te zostały zainicjowane z oddzielnej maszyny, aby wyeliminować obciążenie związane z tworzeniem połączeń. Każda procedura składowana została wykonana 1000 razy przez połączenie, a ja przetestowałem 1 połączenie, 10 połączeń i 100 połączeń (odpowiednio 1000, 10000 i 100000 modyfikacji). Przechwyciłem metryki wydajności za pomocą Query Store, a także przechwyciłem statystyki oczekiwania. Dzięki Query Store mogłem uchwycić średni czas trwania i procesor dla każdej procedury składowanej. Dane statystyczne oczekiwania zostały przechwycone dla każdego połączenia za pomocą dm_exec_session_wait_stats, a następnie zagregowane dla całego testu.
Przeprowadziłem każdy test cztery razy, a następnie obliczyłem ogólne średnie dla danych użytych w tym poście. Skrypty używane do testowania obciążenia można pobrać stąd.
Wyniki
Jak można było przewidzieć, wydajność z obiektami w pamięci była lepsza niż z obiektami dyskowymi. Jednak tabela w pamięci ze zwykłą procedurą składowaną miała czasami porównywalną lub tylko nieznacznie lepszą wydajność w porównaniu z tabelą dyskową ze zwykłą procedurą składowaną. Pamiętaj:chciałem dowiedzieć się, czy naprawdę potrzebuję skompilowanej procedury składowanej, aby uzyskać duże korzyści z tabeli w pamięci. W tym scenariuszu zrobiłem. We wszystkich przypadkach tabela w pamięci z natywnie skompilowaną procedurą miała znacznie lepszą wydajność. Dwa poniższe wykresy przedstawiają te same dane, ale z różnymi skalami dla osi x, aby zademonstrować wydajność w przypadku zwykłych procedur składowanych, które modyfikują dane pogorszonej przy większej liczbie współbieżnych połączeń.
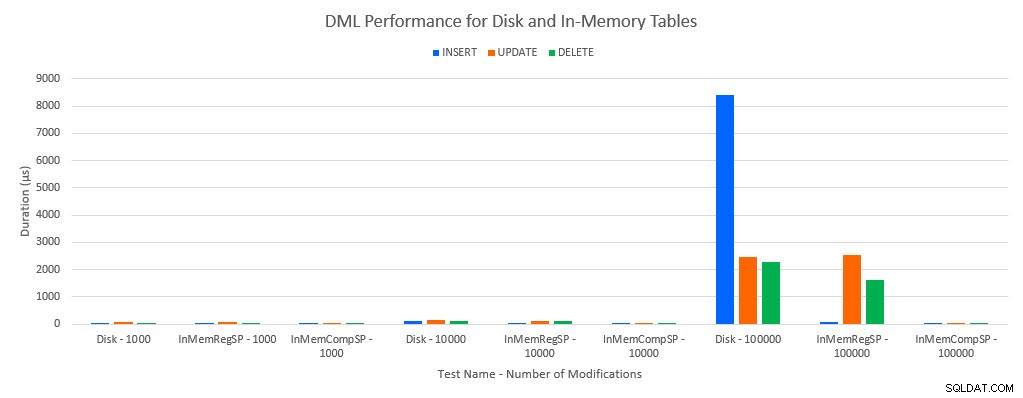
Wydajność DML według testów i obciążenia
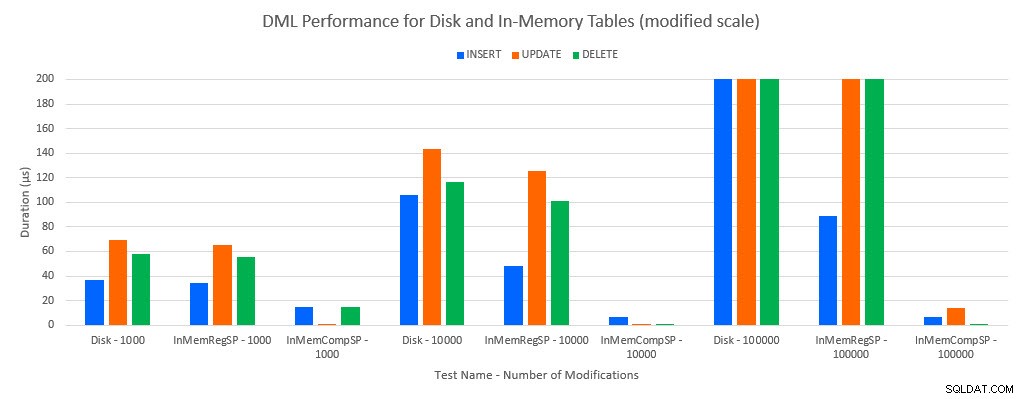
Wydajność DML według testów i obciążenia [zmodyfikowana skala]
Wyjątkiem są wstawki INSERT do tabeli w pamięci za pomocą zwykłej procedury składowanej. Przy 100 połączeniach średni czas trwania wynosi ponad 8 ms dla tabeli opartej na dysku, ale mniej niż 100 mikrosekund dla tabeli In-Memory. Prawdopodobną przyczyną jest brak blokowania i blokowania w tabeli w pamięci, co jest obsługiwane przez dane statystyczne oczekiwania:
| Test | WSTAW | AKTUALIZACJA | USUŃ |
|---|---|---|---|
| Tabela dysków – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 1000 | WRITELOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Tabela dysków – 10 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 10 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 10 000 | WRITELOG | WRITELOG | MEMORY_ALLOCATION_EXT |
| Tabela dysków – 100 000 | PAGELATCH_EX | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 100 000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_CompiledSP – 100 000 | WRITELOG | WRITELOG | WRITELOG |
Statystyki oczekiwania według testu
Dane statystyczne oczekiwania są wymienione w tym miejscu na podstawie całkowitego czasu oczekiwania zasobu (co generalnie przekłada się również na najwyższy średni czas zasobu, ale były wyjątki). Typ oczekiwania WRITELOG jest czynnikiem ograniczającym w tym systemie przez większość czasu. Jednak PAGELATCH_EX czeka na 100 równoczesnych połączeń z instrukcjami INSERT sugeruje, że przy dodatkowym obciążeniu zachowanie blokowania i blokowania, które występuje w przypadku tabel opartych na dyskach, może być czynnikiem ograniczającym. W scenariuszach UPDATE i DELETE z 10 i 100 połączeniami dla testów tabeli opartej na dyskach, średni czas oczekiwania zasobu był najwyższy dla blokad (LCK_M_X).
Wniosek
In-Memory OLTP może absolutnie zapewnić wzrost wydajności przy odpowiednim obciążeniu. Testowane tutaj przykłady są jednak niezwykle proste i nie powinny być oceniane jako jedyny powód do migracji do rozwiązania In-Memory. Wciąż istnieje wiele ograniczeń, które należy wziąć pod uwagę, a przed migracją należy przeprowadzić dokładne testy (szczególnie dlatego, że migracja do tabeli w pamięci jest procesem offline). Ale we właściwym scenariuszu ta nowa funkcja może zapewnić wzrost wydajności. Tak długo, jak rozumiesz, że nadal będą istnieć pewne podstawowe ograniczenia, takie jak szybkość dziennika transakcji dla trwałych tabel, choć najprawdopodobniej w ograniczony sposób – niezależnie od tego, czy tabela istnieje na dysku, czy w pamięci.