W marcu rozpocząłem serię na temat wszechobecnych mitów dotyczących wydajności w SQL Server. Od czasu do czasu spotykam się z przekonaniem, że można przewymiarować kolumny varchar lub nvarchar bez żadnych kar.
Załóżmy, że przechowujesz adresy e-mail. W poprzednim życiu dość często się tym zajmowałem – w tamtym czasie RFC 3696 twierdził, że adres e-mail może mieć 320 znaków (64chars@255znaków). Nowszy dokument RFC nr 5321 potwierdza teraz, że 254 znaki to najdłuższy adres e-mail. A jeśli ktoś z was ma tak długi adres, to może powinniśmy porozmawiać. :-)
Teraz, niezależnie od tego, czy idziesz według starego czy nowego standardu, musisz wspierać możliwość, że ktoś użyje wszystkich dozwolonych postaci. Co oznacza, że musisz użyć 254 lub 320 znaków. Ale widziałem, jak ludzie w ogóle nie zawracają sobie głowy badaniem standardu i po prostu zakładają, że muszą obsługiwać 1000 znaków, 4000 znaków, a nawet więcej.
Przyjrzyjmy się więc, co się dzieje, gdy mamy tabele z kolumną adresu e-mail o różnej wielkości, ale przechowujące dokładnie te same dane:
CREATE TABLE dbo.Email_V320( id int IDENTITY PRIMARY KEY, e-mail varchar(320)); CREATE TABLE dbo.Email_V1000( id int IDENTITY PRIMARY KEY, e-mail varchar(1000)); CREATE TABLE dbo.Email_V4000( id int IDENTITY PRIMARY KEY, e-mail varchar(4000)); CREATE TABLE dbo.Email_Vmax( id int IDENTITY PRIMARY KEY, e-mail varchar(max));
Teraz wygenerujmy 10 000 fikcyjnych adresów e-mail z metadanych systemu i wypełnijmy wszystkie cztery tabele tymi samymi danymi:
INSERT dbo.Email_V320(e-mail) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') Z sys.all_columns AS c WEWNĘTRZNE DOŁĄCZENIE sys.all_objects AS o WŁ. c.[object_id] =o.[object_id] WEWNĘTRZNE DOŁĄCZENIE sys.all_columns JAKO c2 WŁ. c.[object_id] =c2.[object_id] ZAMÓWIENIE PRZEZ NOWYID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320;INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320;INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- odbudujmy ALTER INDEX WSZYSTKO W ODBUDOWANIU dbo.Email_V320; ZMIEŃ INDEKS WSZYSTKO W ODBUDOWANIU dbo.Email_V1000; ZMIEŃ INDEKS WSZYSTKO W ODBUDOWANIU dbo.Email_V4000; ZMIEŃ INDEKS WSZYSTKO W ODBUDOWANIU dbo.Email_VmaxAby sprawdzić, czy każda tabela zawiera dokładnie te same dane:
SELECT AVG(LEN(e-mail)), MAX(LEN(e-mail)) FROM dbo.Email_; Wszystkie cztery dają mi 35 i 77; Twój przebieg może się różnić. Upewnijmy się również, że wszystkie cztery tabele zajmują taką samą liczbę stron na dysku:
SELECT o.name, COUNT(p.[object_id]) FROM sys.objects AS o CROSS APPLY sys.dm_db_database_page_allocations (DB_ID(), o.object_id, 1, NULL, „LIMITED”) AS p WHERE o.name LIKE N'Email[_]V[^2]%' GROUP WG o.name;Wszystkie cztery z tych zapytań dają 89 stron (ponownie, Twój przebieg może się różnić).
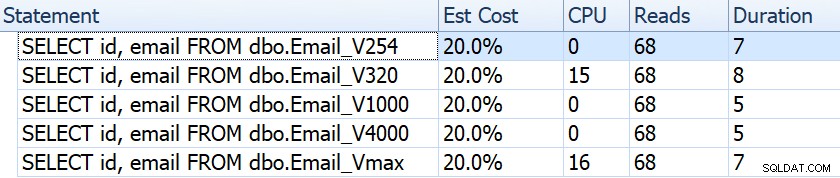
Teraz weźmy typowe zapytanie, które skutkuje skanowaniem indeksu klastrowego:
SELECT id, e-mail FROM dbo.Email_; Jeśli spojrzymy na takie rzeczy, jak czas trwania, odczyty i szacunkowe koszty, wszystkie wydają się takie same:
Może to uśpić ludzi do fałszywego założenia, że w ogóle nie ma to wpływu na wydajność. Ale jeśli przyjrzymy się trochę bliżej, w podpowiedzi do skanowania indeksu klastrowego w każdym planie, zauważymy różnicę, która może mieć znaczenie w innych, bardziej skomplikowanych zapytaniach:
Stąd widzimy, że im większa definicja kolumny, tym wyższy szacowany rozmiar wiersza i danych. W tym prostym zapytaniu koszt we/wy (0.0512731) jest taki sam we wszystkich zapytaniach, niezależnie od definicji, ponieważ skanowanie indeksu klastrowego i tak musi odczytać wszystkie dane.
Istnieją jednak inne scenariusze, w których ten szacowany rozmiar wiersza i łączny rozmiar danych będzie miał wpływ:operacje wymagające dodatkowych zasobów, takich jak sortowanie. Weźmy to śmieszne zapytanie, które nie służy żadnemu celowi poza wymaganiem wielu operacji sortowania:
SELECT /* V*/ ROW_NUMBER() OVER (PARTYCJA PRZEZ e-mail ORDER BY e-mail DESC), e-mail, REVERSE(e-mail), SUBSTRING(e-mail, 1, CHARINDEX('@', e-mail)) FROM dbo .Email_V GROUP BY REVERSE(e-mail), e-mail, SUBSTRING(email, 1, CHARINDEX('@', email)) ORDER BY REVERSE(e-mail), e-mail; Uruchamiamy te cztery zapytania i widzimy, że wszystkie plany wyglądają tak:
Jednak ta ikona ostrzegawcza na operatorze SELECT pojawia się tylko w tabelach 4000/max. Jakie jest ostrzeżenie? Jest to ostrzeżenie o nadmiernym przyznaniu pamięci, wprowadzone w SQL Server 2016. Oto ostrzeżenie dla varchar(4000):
A dla varchar(max):
Przyjrzyjmy się trochę bliżej i zobaczmy, co się dzieje, przynajmniej według sys.dm_exec_query_stats:
SELECT [tabela] =SUBSTRING(t.[tekst], 1, CHARINDEX(N'*/', t.[tekst])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kbFROM sys.dm_exec_query_stats AS s KRZYŻ ZASTOSUJ sys.dm_exec_sql_text(s.sql_handle) AS tWHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ZAMÓWIENIE PRZEZ s.last_grant_kb;Wyniki:
W moim scenariuszu na czas trwania nie miały wpływu różnice w przyznawaniu pamięci (z wyjątkiem przypadku max), ale wyraźnie widać postęp liniowy, który pokrywa się z zadeklarowanym rozmiarem kolumny. Którego można użyć do ekstrapolacji tego, co by się stało w systemie z niewystarczającą pamięcią. Lub bardziej rozbudowane zapytanie dotyczące znacznie większego zestawu danych. Lub znacząca współbieżność. Każdy z tych scenariuszy może wymagać rozlania w celu przetworzenia operacji sortowania, co prawie na pewno wpłynie na czas trwania.
Ale skąd biorą się te większe granty pamięci? Pamiętaj, to to samo zapytanie, z dokładnie tymi samymi danymi. Problem polega na tym, że w przypadku niektórych operacji SQL Server musi brać pod uwagę, ile danych *może* znajdować się w kolumnie. Nie robi tego na podstawie faktycznego profilowania danych i nie może przyjmować żadnych założeń na podstawie wartości kroku histogramu <=201. Zamiast tego musi oszacować, że każdy wiersz zawiera wartość połowę deklarowanego rozmiaru kolumny . Tak więc dla varchar(4000) zakłada się, że każdy adres e-mail ma długość 2000 znaków.
Kiedy nie jest możliwe posiadanie adresu e-mail dłuższego niż 254 lub 320 znaków, nie ma nic do zyskania przez przewymiarowanie, a jest wiele do stracenia. Późniejsze zwiększenie rozmiaru kolumny o zmiennej szerokości jest znacznie łatwiejsze niż zajmowanie się teraz wszystkimi wadami.
Oczywiście przewymiarowanie
charlubncharkolumny mogą mieć znacznie bardziej oczywiste kary.