Od czasu do czasu widzę, jak ktoś wyraża żądanie stworzenia losowej liczby dla klucza. Zwykle ma to na celu utworzenie pewnego rodzaju zastępczego identyfikatora klienta lub identyfikatora użytkownika, który jest unikalnym numerem z pewnego zakresu, ale nie jest nadawany sekwencyjnie i dlatego jest znacznie mniej możliwy do odgadnięcia niż IDENTITY wartość.
NEWID() rozwiązuje problem zgadywania, ale spadek wydajności jest zwykle przełomem, zwłaszcza w przypadku klastrowania:znacznie szersze klucze niż liczby całkowite i podziały stron ze względu na wartości niesekwencyjne. NEWSEQUENTIALID() rozwiązuje problem podziału strony, ale nadal jest bardzo szerokim kluczem i ponownie wprowadza problem, który umożliwia odgadnięcie następnej wartości (lub ostatnio wydanych wartości) z pewnym poziomem dokładności.
W związku z tym chcą techniki generowania losowych i unikalna liczba całkowita. Samo generowanie losowej liczby nie jest trudne, używając metod takich jak RAND() lub CHECKSUM(NEWID()) . Problem pojawia się, gdy trzeba wykryć kolizje. Rzućmy okiem na typowe podejście, zakładając, że chcemy wartości CustomerID od 1 do 1 000 000:
DECLARE @rc INT =0, @CustomerID INT =ABS(SPRAWDZENIE(NEWID())) % 1000000 + 1; -- lub ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1; -- lub CONVERT(INT, RAND() * 1000000) + 1;WHILE @rc =0BEGIN IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID =@CustomerID) BEGIN INSERT dbo.Customers(CustomerID) SELECT @CustomerID; USTAW @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @rc =0; KONIEC
W miarę powiększania się tabeli nie tylko sprawdzanie duplikatów staje się droższe, ale także zwiększają się szanse na wygenerowanie duplikatu. Tak więc takie podejście może wydawać się skuteczne, gdy stół jest mały, ale podejrzewam, że z czasem musi boleć coraz bardziej.
Inne podejście
Jestem wielkim fanem stolików pomocniczych; Od dziesięciu lat piszę publicznie o tablicach kalendarzowych i tablicach liczbowych i używam ich znacznie dłużej. I to jest przypadek, w którym myślę, że wstępnie wypełniony stół może się bardzo przydać. Po co polegać na generowaniu liczb losowych w czasie wykonywania i radzeniu sobie z potencjalnymi duplikatami, skoro możesz z wyprzedzeniem wypełnić wszystkie te wartości i mieć pewność – ze 100% pewnością, jeśli chronisz swoje tabele przed nieautoryzowanym DML – że następna wybrana wartość nigdy nie była używane wcześniej?
CREATE TABLE dbo.RandomNumbers1(RowID INT, Value INT, --UNIQUE, PRIMARY KEY (RowID, Value)); Z x AS (WYBIERZ TOP (1000000) s1.[object_id] FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id])INSERT dbo.RandomNumbers(RowID, Value)SELECT r =ROW_NUMBER( ) OVER (ORDER BY [identyfikator_obiektu]), n =ROW_NUMBER() OVER (ORDER BY NEWID())FROM xORDER BY r;
Tworzenie tej populacji zajęło 9 sekund (w maszynie wirtualnej na laptopie) i zajmowało około 17 MB na dysku. Dane w tabeli wyglądają tak:
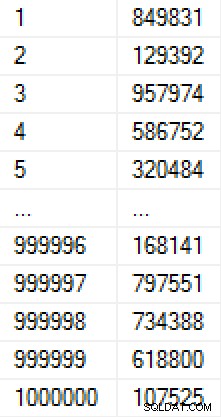
(Gdybyśmy martwili się, w jaki sposób liczby są zapełniane, moglibyśmy dodać ograniczenie unikatowości w kolumnie Wartość, co spowodowałoby, że tabela miałaby 30 MB. Gdybyśmy zastosowali kompresję strony, byłoby to odpowiednio 11 MB lub 25 MB. )
Utworzyłem kolejną kopię tabeli i wypełniłem ją tymi samymi wartościami, abym mógł przetestować dwie różne metody wyprowadzenia następnej wartości:
CREATE TABLE dbo.RandomNumbers2(RowID INT, Value INT, -- UNIKALNY KLUCZ PODSTAWOWY (RowID, Value)); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Teraz, za każdym razem, gdy chcemy nową liczbę losową, możemy po prostu zdjąć jedną ze stosu istniejących liczb i ją usunąć. Dzięki temu nie musimy martwić się o duplikaty i możemy pobierać liczby – przy użyciu indeksu klastrowego – które w rzeczywistości są już w losowej kolejności. (Ściśle mówiąc, nie musimy usuwać liczby, jak ich używamy; moglibyśmy dodać kolumnę, aby wskazać, czy wartość została użyta – ułatwiłoby to przywrócenie i ponowne użycie tej wartości w przypadku, gdy klient zostanie później usunięty lub coś pójdzie nie tak poza tą transakcją, ale zanim zostaną w pełni utworzone.)
DECLARE @holding TABLE(CustomerID INT); DELETE TOP (1) dbo.RandomNumbers1OUTPUT usunięto.Value INTO @holding; INSERT dbo.Customers(CustomerID, ...inne kolumny...) SELECT CustomerID, ...inne parametry... FROM @holding;
Użyłem zmiennej tabeli do przechowywania danych wyjściowych pośrednich, ponieważ istnieją różne ograniczenia dotyczące komponowania DML, które mogą uniemożliwić wstawianie do tabeli Klienci bezpośrednio z DELETE (na przykład obecność kluczy obcych). Mimo to, przyznając, że nie zawsze będzie to możliwe, chciałem również przetestować tę metodę:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT został usunięty.Value, ...inne parametry... INTO dbo.Customers(CustomerID, ...inne kolumny...);
Zauważ, że żadne z tych rozwiązań nie gwarantuje losowej kolejności, szczególnie jeśli tabela liczb losowych ma inne indeksy (takie jak unikalny indeks w kolumnie Wartość). Nie ma możliwości zdefiniowania zamówienia dla DELETE używając TOP; z dokumentacji:
Jeśli więc chcesz zagwarantować losowe zamawianie, możesz zamiast tego zrobić coś takiego:
DECLARE @holding TABLE(CustomerID INT);;WITH x AS ( SELECT TOP (1) Wartość FROM dbo.RandomNumbers2 ORDER BY RowID)DELETE x OUTPUT usunięto.Value INTO @holding; INSERT dbo.Customers(CustomerID, ...inne kolumny...) SELECT CustomerID, ...inne parametry... FROM @holding;
Inną kwestią jest to, że w przypadku tych testów tabele Customers mają klastrowany klucz podstawowy w kolumnie CustomerID; z pewnością doprowadzi to do podziałów stron, gdy wstawisz losowe wartości. W prawdziwym świecie, gdybyś miał taki wymóg, prawdopodobnie skończyłoby się klastrowaniem w innej kolumnie.
Zauważ, że pominąłem tutaj również transakcje i obsługę błędów, ale one również powinny być brane pod uwagę w przypadku kodu produkcyjnego.
Testowanie wydajności
Aby narysować realistyczne porównania wydajności, stworzyłem pięć procedur składowanych, reprezentujących następujące scenariusze (testowanie szybkości, rozkładu i częstotliwości kolizji różnych metod losowych, a także szybkość używania predefiniowanej tabeli liczb losowych):
- Generowanie środowiska wykonawczego za pomocą
CHECKSUM(NEWID()) - Generowanie środowiska wykonawczego za pomocą
CRYPT_GEN_RANDOM() - Generowanie środowiska wykonawczego za pomocą
RAND() - Predefiniowana tabela liczb ze zmienną tabeli
- Predefiniowana tabela liczb z bezpośrednim wstawianiem
Używają tabeli rejestrowania do śledzenia czasu trwania i liczby kolizji:
CREATE TABLE dbo.CustomerLog( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, kolizje INT, czas trwania INT -- mikrosekundy);
Kod procedur jest następujący (kliknij, aby pokazać/ukryć):
/* Runtime przy użyciu CHECKSUM(NEWID()) */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BEGIN JEŚLI NIE ISTNIEJE ( WYBIERZ 1 FROM dbo.Customers_Runtime_Checksum WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID; USTAW @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @collisions +=1, @rc =0; END END SELECT @czas trwania =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, kolizje, czas trwania) SELECT 1, @collisions, @duration;ENDGO /* runtime przy użyciu CRYPT_GEN_RANDOM() */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BEGIN JEŚLI NIE ISTNIEJE ( WYBIERZ 1 FROM dbo.Customers_Runtime_CryptGen WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID; USTAW @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions +=1, @rc =0; END END SELECT @czas trwania =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, kolizje, czas trwania) SELECT 2, @collisions, @duration;ENDGO /* runtime przy użyciu RAND() */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =CONVERT(INT, RAND() * 1000000) + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BEGIN JEŚLI NIE ISTNIEJE ( WYBIERZ 1 FROM dbo.Customers_Runtime_Rand WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID; USTAW @rc =1; END ELSE BEGIN SELECT @CustomerID =CONVERT(INT, RAND() * 1000000) + 1, @collisions +=1, @rc =0; END END SELECT @czas trwania =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, kolizje, czas trwania) SELECT 3, @collisions, @duration;ENDGO /* predefiniowane za pomocą zmiennej tabeli */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT; DECLARE @holding TABLE(CustomerID INT); DELETE TOP (1) dbo.RandomNumbers1 OUTPUT został usunięty.Wartość INTO @holding; INSERT dbo.Customers_Predefined_TableVariable(CustomerID) SELECT CustomerID FROM @holding; SELECT @ czas trwania =DATEDIFF (MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, czas trwania) SELECT 4, @duration;ENDGO /* predefiniowane za pomocą bezpośredniego wstawiania */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT; USUŃ GÓRĘ (1) dbo.RandomNumbers2 WYJŚCIE usunięto.WARTOŚĆ DO dbo.Customers_Predefined_Direct; SELECT @ czas trwania =DATEDIFF (MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, czas trwania) SELECT 5, @duration;ENDGO
Aby to przetestować, uruchomiłbym każdą procedurę składowaną 1 000 000 razy:
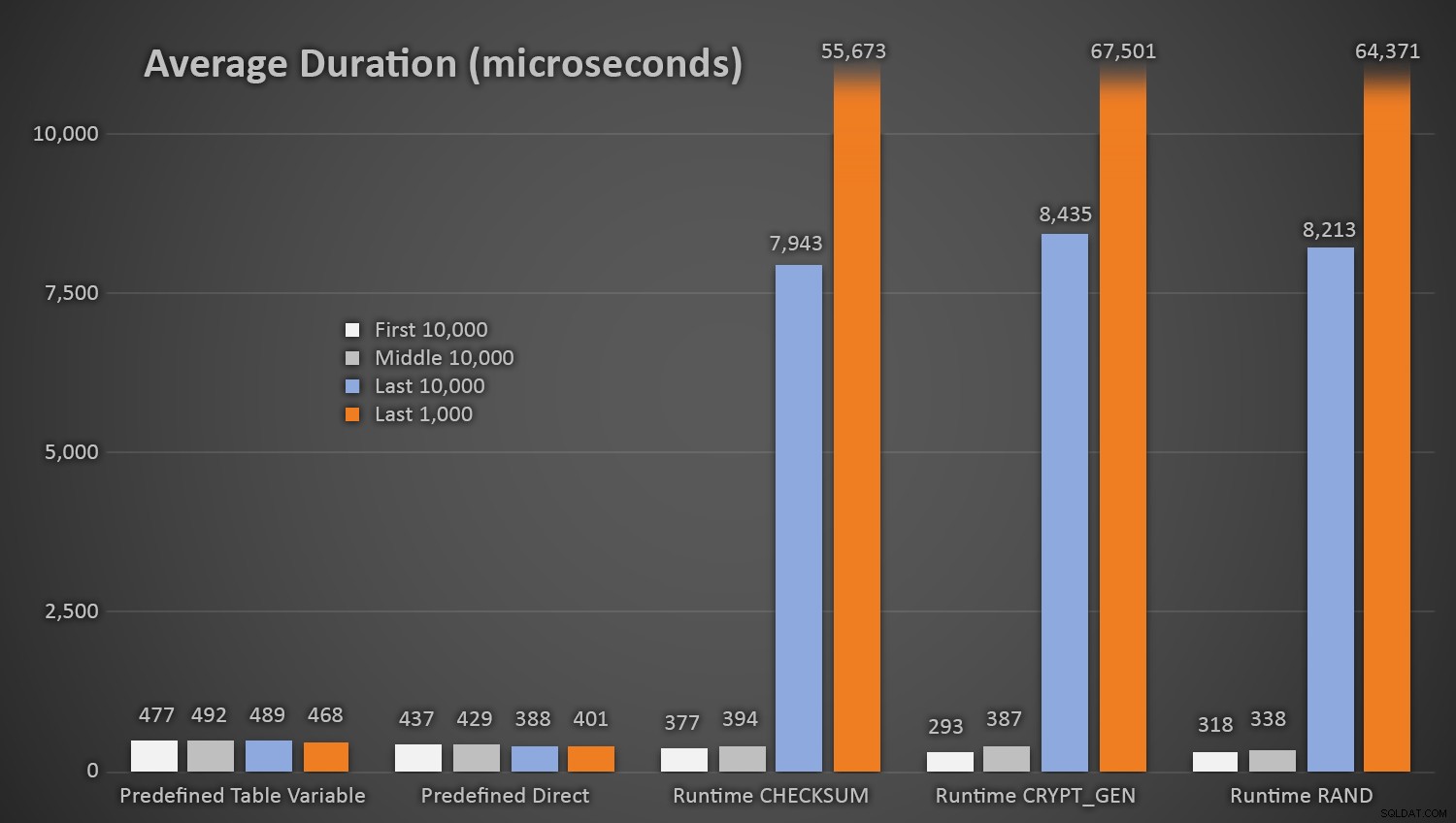
EXEC dbo.AddCustomer_Runtime_Checksum;EXEC dbo.AddCustomer_Runtime_CryptGen;EXEC dbo.AddCustomer_Runtime_Rand;EXEC dbo.AddCustomer_Predefined_TableVariable;EXEC dbo.AddCustomer_Predefined_Direct>GO 1000000Nic dziwnego, że metody korzystające z predefiniowanej tabeli liczb losowych zajęły nieco więcej czasu *na początku testu*, ponieważ musiały za każdym razem wykonywać zarówno odczyt, jak i zapis. Pamiętaj, że te liczby są podane w mikrosekundach , oto średnie czasy trwania dla każdej procedury, w różnych odstępach czasu (uśrednione dla pierwszych 10 000 wykonań, środkowych 10 000 wykonań, ostatnich 10 000 wykonań i ostatnich 1000 wykonań):
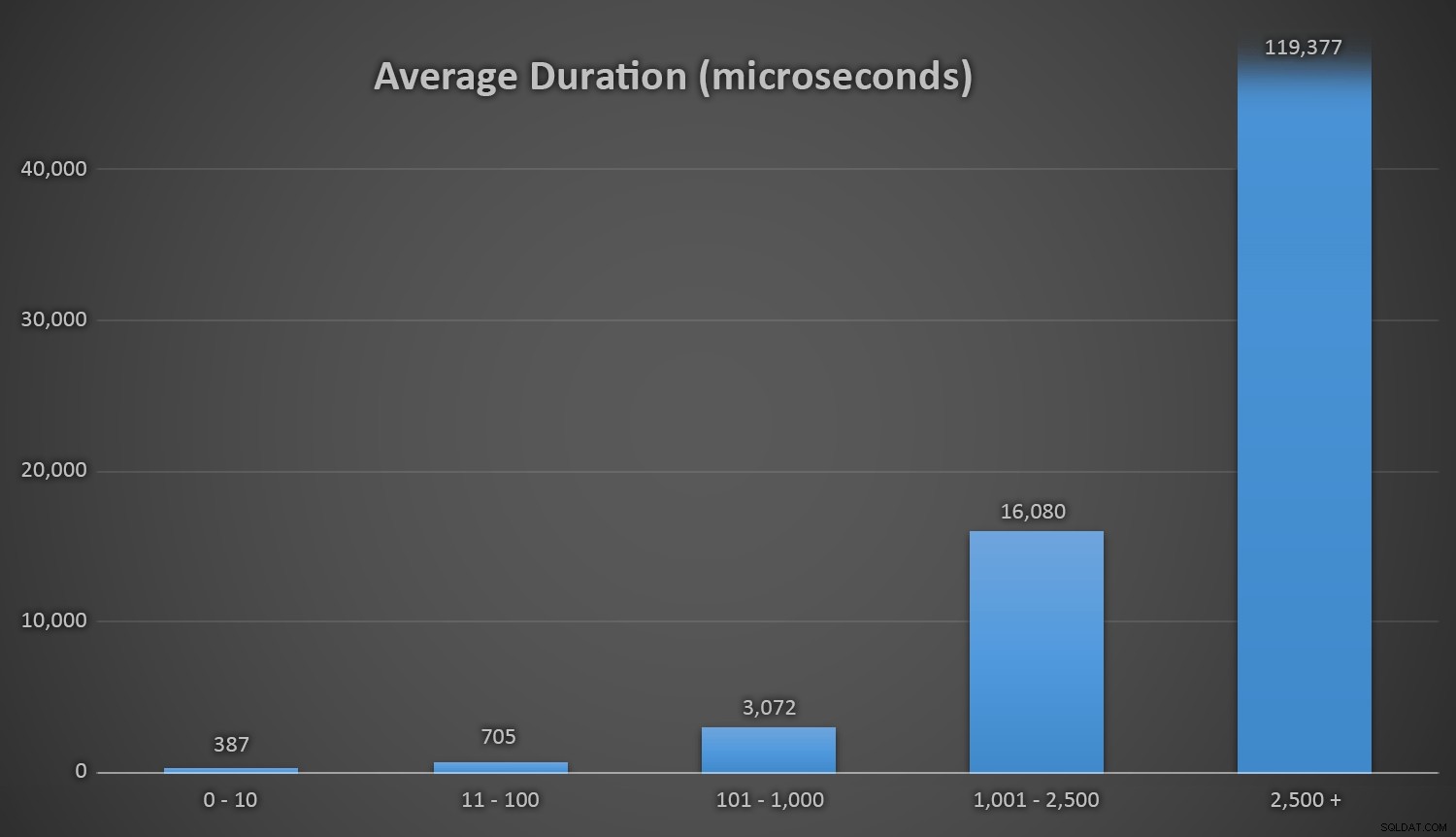
Średni czas trwania (w mikrosekundach) losowego generowania przy użyciu różnych podejśćSprawdza się to dobrze dla wszystkich metod, gdy w tabeli Customers jest kilka wierszy, ale w miarę jak tabela staje się coraz większa, koszt sprawdzania nowej liczby losowej z istniejącymi danymi za pomocą metod runtime znacznie wzrasta, zarówno ze względu na wzrost I /O, a także dlatego, że wzrasta liczba kolizji (zmuszając do ponownych prób). Porównaj średni czas trwania w następujących zakresach liczby kolizji (i pamiętaj, że ten wzorzec wpływa tylko na metody wykonawcze):
Średni czas trwania (w mikrosekundach) podczas różnych zakresów kolizjiSzkoda, że nie ma prostego sposobu na wykreślenie czasu trwania w stosunku do liczby kolizji. Zostawię cię z tą ciekawostką:podczas ostatnich trzech wstawek następujące metody wykonawcze musiały wykonać tyle prób, zanim w końcu natknęły się na ostatni unikalny identyfikator, którego szukały, a oto ile czasu to zajęło:
| Liczba kolizji | Czas trwania (mikrosekundy) | ||
|---|---|---|---|
| SUM(NEWID()) | od trzeciego do ostatniego wiersza | 63 545 | 639.358 |
| od drugiego do ostatniego wiersza | 164 807 | 1,605,695 | |
| Ostatni wiersz | 30 630 | 296.207 | |
| CRYPT_GEN_RANDOM() | od trzeciego do ostatniego wiersza | 219 766 | 2229166 |
| od drugiego do ostatniego wiersza | 255 463 | 2,681,468 | |
| Ostatni wiersz | 136.342 | 1,434,725 | |
| RAND() | od trzeciego do ostatniego wiersza | 129 764 | 1215 994 |
| od drugiego do ostatniego wiersza | 220 195 | 2.088.992 | |
| Ostatni wiersz | 440 765 | 4,161,925 | |
Nadmierny czas trwania i kolizje na końcu linii
Warto zauważyć, że ostatni wiersz nie zawsze jest tym, który daje największą liczbę kolizji, więc może to stać się prawdziwym problemem na długo przed zużyciem ponad 999 000 wartości.
Kolejna uwaga
Możesz rozważyć skonfigurowanie pewnego rodzaju alertu lub powiadomienia, gdy tabela liczb losowych zacznie spadać poniżej pewnej liczby wierszy (w którym to momencie możesz ponownie wypełnić tabelę nowym zestawem na przykład od 1 000 001 do 2 000 000). Musiałbyś zrobić coś podobnego, gdybyś generował losowe liczby w locie – jeśli utrzymujesz to w zakresie od 1 do 1 000 000, musiałbyś zmienić kod, aby generować liczby z innego zakresu, gdy tylko będziesz” zużyłem wszystkie te wartości.
Jeśli używasz losowej metody w czasie wykonywania, możesz uniknąć tej sytuacji, stale zmieniając rozmiar puli, z której losujesz liczbę (co powinno również ustabilizować się i drastycznie zmniejszyć liczbę kolizji). Na przykład zamiast:
DECLARE @CustomerID INT =ABS(SUM.KONTROLNA(NEWID())) % 1000000 + 1;
Możesz oprzeć pulę na liczbie wierszy już w tabeli:
DECLARE @total INT =1000000 + ISNULL((SELECT SUM(row_count) FROM sys.dm_db_partition_stats WHERE [object_id] =OBJECT_ID('dbo.Customers') AND index_id =1),0);
Teraz jedynym prawdziwym zmartwieniem jest zbliżanie się do górnej granicy dla INT …
Uwaga:ostatnio napisałem również wskazówkę na ten temat na MSSQLTips.com.