Prawie każdy problem z wydajnością związany z kolumnami obliczeniowymi, jaki napotkałem na przestrzeni lat, miał jedną (lub więcej) z następujących przyczyn źródłowych:
- Ograniczenia implementacji
- Brak obsługi modelu kosztów w optymalizatorze zapytań
- Rozszerzanie definicji kolumny obliczeniowej przed rozpoczęciem optymalizacji
Przykład ograniczenia implementacji nie jest w stanie utworzyć filtrowanego indeksu w kolumnie wyliczanej (nawet jeśli jest utrwalony). Niewiele możemy zrobić z tą kategorią problemów; musimy zastosować obejścia, czekając na nadejście ulepszeń produktu.
Brak optymalizacji obsługi modelu kosztów oznacza, że SQL Server przypisuje niewielki stały koszt do obliczeń skalarnych, niezależnie od złożoności lub implementacji. W konsekwencji serwer często decyduje się na ponowne obliczenie zapisanej wartości kolumny wyliczonej zamiast bezpośredniego odczytywania utrwalonej lub indeksowanej wartości. Jest to szczególnie bolesne, gdy wyliczane wyrażenie jest drogie, na przykład gdy wymaga wywołania skalarnej funkcji zdefiniowanej przez użytkownika.
Problemy związane z rozszerzaniem definicji są nieco bardziej zaangażowane i mają dalekosiężne efekty.
Problemy rozszerzania kolumny obliczeniowej
SQL Server zwykle rozszerza kolumny obliczeniowe do ich podstawowych definicji podczas fazy wiązania normalizacji zapytania. Jest to bardzo wczesna faza procesu kompilacji zapytań, na długo przed podjęciem jakichkolwiek decyzji dotyczących wyboru planu (w tym planu trywialnego).
Teoretycznie wykonanie wczesnej ekspansji może umożliwić optymalizacje, które w innym przypadku zostałyby pominięte. Na przykład optymalizator może być w stanie zastosować uproszczenia, biorąc pod uwagę inne informacje w zapytaniu i metadane (np. ograniczenia). Jest to ten sam rodzaj rozumowania, który prowadzi do rozwinięcia definicji widoków (chyba że NOEXPAND używana jest wskazówka).
W dalszej części procesu kompilacji (ale jeszcze przed rozważeniem nawet trywialnego planu) optymalizator stara się dopasować wyrażenia wstecz do utrwalonych lub indeksowanych kolumn obliczeniowych. Problem polega na tym, że działania optymalizatora w międzyczasie mogły zmienić rozszerzone wyrażenia tak, że dopasowanie wsteczne nie jest już możliwe.
W takim przypadku ostateczny plan wykonania wygląda tak, jakby optymalizator przegapił „oczywistą” możliwość użycia utrwalonej lub indeksowanej kolumny obliczeniowej. W planach wykonania jest kilka szczegółów, które mogą pomóc w ustaleniu przyczyny, co sprawia, że jest to potencjalnie frustrujący problem do debugowania i naprawy.
Dopasowywanie wyrażeń do kolumn obliczanych
Warto szczególnie wyraźnie zaznaczyć, że istnieją tutaj dwa oddzielne procesy:
- Wczesne rozwinięcie kolumn obliczeniowych; i
- Później próbuje dopasować wyrażenia do wyliczonych kolumn.
W szczególności zauważ, że każde wyrażenie zapytania może być później dopasowane do odpowiedniej kolumny wyliczanej, a nie tylko wyrażenia powstałe w wyniku rozwinięcia kolumn wyliczanych.
Dopasowywanie wyrażeń kolumny obliczanej może umożliwić ulepszenia planu, nawet jeśli nie można zmodyfikować tekstu oryginalnego zapytania. Na przykład utworzenie kolumny wyliczanej w celu dopasowania znanego wyrażenia zapytania umożliwia optymalizatorowi użycie statystyk i indeksów skojarzonych z kolumną wyliczaną. Ta funkcja jest koncepcyjnie podobna do indeksowanego dopasowywania widoków w wersji Enterprise Edition. Dopasowywanie kolumn obliczeniowych działa we wszystkich wydaniach.
Z praktycznego punktu widzenia, z własnego doświadczenia wynika, że dopasowanie ogólnych wyrażeń zapytań do kolumn obliczeniowych może rzeczywiście korzystnie wpłynąć na wydajność, wydajność i stabilność planu wykonania. Z drugiej strony rzadko (jeśli w ogóle) uważałem, że rozwinięcie kolumny obliczeniowej jest opłacalne. Po prostu nigdy nie daje żadnych użytecznych optymalizacji.
Kolumny obliczeniowe
Kolumny obliczane, które są ani utrwalone ani indeksowane mają prawidłowe zastosowania. Na przykład mogą obsługiwać statystyki automatyczne, jeśli kolumna jest deterministyczna i precyzyjna (brak elementów zmiennoprzecinkowych). Mogą być również używane do oszczędzania miejsca w pamięci (kosztem dodatkowego wykorzystania procesora wykonawczego). Jako ostatni przykład mogą zapewnić zgrabny sposób na zapewnienie, że proste obliczenia są zawsze wykonywane poprawnie, zamiast za każdym razem wyraźnie zapisywać je w zapytaniach.
Utrzymywane Kolumny wyliczane zostały dodane do produktu specjalnie po to, aby umożliwić budowanie indeksów na deterministycznych, ale „nieprecyzyjnych” (zmiennoprzecinkowych) kolumnach. Z mojego doświadczenia wynika, że takie zamierzone użycie jest stosunkowo rzadkie. Może to po prostu dlatego, że nie spotykam się zbyt często z danymi zmiennoprzecinkowymi.
Pomijając indeksy zmiennoprzecinkowe, utrwalone kolumny są dość powszechne. Do pewnego stopnia może to być spowodowane tym, że niedoświadczeni użytkownicy zakładają, że wyliczona kolumna musi być zawsze utrwalona, zanim będzie można ją zindeksować. Bardziej doświadczeni użytkownicy mogą korzystać z utrwalonych kolumn po prostu dlatego, że odkryli, że w ten sposób wydajność jest zwykle lepsza.
Zindeksowany kolumny wyliczane (uparte lub nie) mogą być wykorzystane do zapewnienia porządku i wydajnej metody dostępu. Przydatne może być przechowywanie obliczonej wartości w indeksie bez utrwalania jej w tabeli podstawowej. Podobnie, odpowiednie kolumny wyliczane mogą być również zawarte w indeksach, a nie jako kolumny kluczowe.
Słaba wydajność
Główną przyczyną niskiej wydajności jest po prostu niepowodzenie użycia indeksowanej lub utrwalonej wartości kolumny obliczeniowej zgodnie z oczekiwaniami. Straciłem rachubę pytań, które zadałem przez lata, pytając, dlaczego optymalizator wybrałby fatalny plan wykonania, skoro istnieje oczywiście lepszy plan wykorzystujący zindeksowaną lub utrwaloną kolumnę obliczeniową.
Dokładna przyczyna w każdym przypadku jest różna, ale prawie zawsze jest to albo błędna decyzja oparta na kosztach (ponieważ skalarom przypisywany jest niski koszt stały); lub niepowodzenie dopasowania rozszerzonego wyrażenia z powrotem do utrwalonej kolumny wyliczanej lub indeksu.
Szczególnie interesujące są dla mnie niepowodzenia dopasowania, ponieważ często wiążą się ze złożonymi interakcjami z funkcjami silnika ortogonalnego. Równie często niepowodzenie „dopasowania wstecznego” pozostawia wyrażenie (a nie kolumnę) na pozycji w wewnętrznym drzewie zapytań, która uniemożliwia dopasowanie ważnej reguły optymalizacji. W obu przypadkach wynik jest taki sam:nieoptymalny plan wykonania.
Teraz myślę, że można uczciwie powiedzieć, że ludzie zazwyczaj indeksują lub utrzymują obliczoną kolumnę z silnym oczekiwaniem, że przechowywana wartość będzie rzeczywiście używana. Może to być szokujące, gdy SQL Server za każdym razem ponownie oblicza podstawowe wyrażenie, ignorując celowo dostarczoną przechowywaną wartość. Ludzie nie zawsze są bardzo zainteresowani interakcjami wewnętrznymi i niedociągnięciami modeli kosztów, które doprowadziły do niepożądanych wyników. Nawet tam, gdzie istnieją obejścia, ich odkrycie i przetestowanie wymaga czasu, umiejętności i wysiłku.
W skrócie:wiele osób po prostu wolałoby, aby SQL Server używał wartości utrwalonej lub indeksowanej. Zawsze.
Nowa opcja
Historycznie nie było sposobu, aby zmusić SQL Server, aby zawsze używał przechowywanej wartości (brak odpowiednika NOEXPAND wskazówka dotycząca poglądów). W pewnych okolicznościach przewodnik po planie będzie działał, ale nie zawsze jest możliwe wygenerowanie wymaganego kształtu planu, a nie wszystkie elementy i pozycje planu można wymusić (na przykład filtry i obliczanie skalarów).
Nadal nie ma schludnego, w pełni udokumentowanego rozwiązania, ale niedawna aktualizacja SQL Server 2016 zapewniła interesujące nowe podejście. Dotyczy to wystąpień SQL Server 2016 z poprawkami co najmniej Zbiorcza aktualizacja 2 dla SQL Server 2016 SP1 lub Zbiorcza aktualizacja 4 dla SQL Server 2016 RTM.
Odpowiednia aktualizacja jest udokumentowana w:NAPRAW:Nie można odbudować partycji online dla tabeli zawierającej obliczoną kolumnę partycjonowania w SQL Server 2016
Jak to często bywa z dokumentacją pomocy technicznej, nie mówi ona dokładnie, co zostało zmienione w silniku w celu rozwiązania problemu. Z pewnością nie wygląda to strasznie na nasze obecne obawy, sądząc po tytule i opisie. Niemniej jednak ta poprawka wprowadza nową obsługiwaną flagę śledzenia 176 , który jest sprawdzany w metodzie kodu o nazwie FDontExpandPersistedCC . Jak sugeruje nazwa metody, zapobiega to rozwijaniu utrwalonej kolumny obliczeniowej.
Istnieją trzy ważne zastrzeżenia:
- Wyliczona kolumna musi być utrwalona . Nawet jeśli zindeksowana, kolumna musi być również utrwalona.
- Dopasowanie wsteczne z ogólnych wyrażeń zapytań do utrwalonych kolumn obliczanych jest wyłączone .
- Dokumentacja nie opisuje funkcji flagi śledzenia i nie zaleca jej żadnego innego zastosowania. Jeśli zdecydujesz się użyć flagi śledzenia 176, aby zapobiec rozszerzaniu utrwalonych kolumn obliczeniowych, zrobisz to na własne ryzyko.
Ta flaga śledzenia jest skuteczna jako startowa –T opcja, zarówno w zakresie globalnym, jak i sesji przy użyciu DBCC TRACEON i na zapytanie z OPTION (QUERYTRACEON) .
Przykład
Jest to uproszczona wersja pytania (opartego na rzeczywistym problemie), na które kilka lat temu odpowiedziałem na Stack Exchange administratorów baz danych. Definicja tabeli zawiera utrwaloną kolumnę obliczeniową:
CREATE TABLE dbo.T
(
ID integer IDENTITY NOT NULL,
A varchar(20) NOT NULL,
B varchar(20) NOT NULL,
C varchar(20) NOT NULL,
D date NULL,
Computed AS A + '-' + B + '-' + C PERSISTED,
CONSTRAINT PK_T_ID
PRIMARY KEY CLUSTERED (ID),
);
GO
INSERT dbo.T WITH (TABLOCKX)
(A, B, C, D)
SELECT
A = STR(SV.number % 10, 2),
B = STR(SV.number % 20, 2),
C = STR(SV.number % 30, 2),
D = DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())
FROM master.dbo.spt_values AS SV
WHERE SV.[type] = N'P'; Poniższe zapytanie zwraca wszystkie wiersze z tabeli w określonej kolejności, a jednocześnie zwraca następną wartość kolumny D w tej samej kolejności:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D; Oczywistym indeksem pokrycia, wspierającym ostateczną kolejność i wyszukiwania w podzapytaniu, jest:
CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
Plan wykonania dostarczony przez optymalizator jest zaskakujący i rozczarowujący:
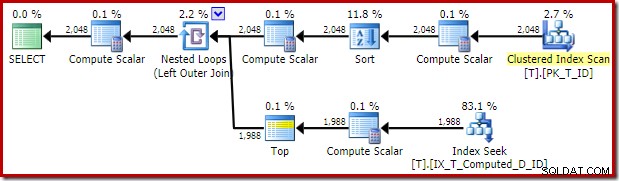
Wyszukiwanie indeksu po wewnętrznej stronie łączenia zagnieżdżonych pętli wydaje się być dobre. Jednak skanowanie indeksu klastrowego i sortowanie na zewnętrznych danych wejściowych jest nieoczekiwane. Mieliśmy nadzieję, że zamiast tego zobaczymy uporządkowany skan naszego obejmującego indeksu nieklastrowanego.
Możemy zmusić optymalizator do używania indeksu nieklastrowego za pomocą wskazówki dotyczącej tabeli:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
WITH (INDEX(IX_T_Computed_D_ID)) -- New!
ORDER BY
T1.Computed, T1.D; Wynikowy plan wykonania to:
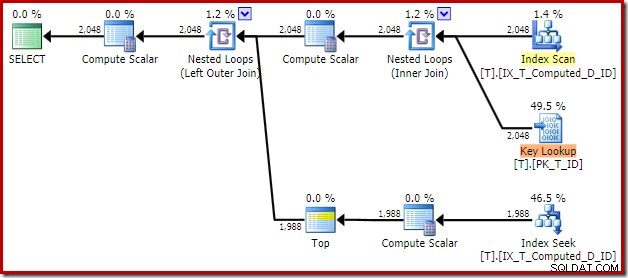
Skanowanie indeksu nieklastrowego usuwa sortowanie, ale dodaje wyszukiwanie klucza! Wyszukiwania w tym nowym planie są zaskakujące, biorąc pod uwagę, że nasz indeks zdecydowanie obejmuje wszystkie kolumny wymagane przez zapytanie.
Patrząc na właściwości operatora Key Lookup:
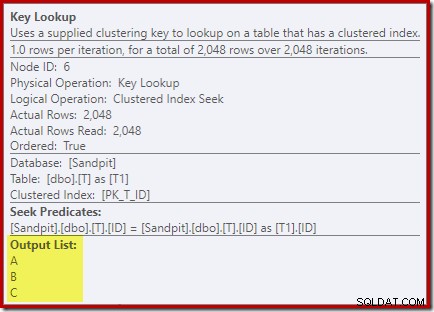
Z jakiegoś powodu optymalizator zdecydował, że trzy kolumny niewymienione w zapytaniu muszą zostać pobrane z tabeli bazowej (ponieważ z założenia nie są one obecne w naszym indeksie nieklastrowym).
Rozglądając się po planie wykonania, odkrywamy, że wyszukane kolumny są potrzebne po wewnętrznej stronie Index Seek:

Pierwsza część tego predykatu seek odpowiada korelacji T2.Computed = T1.Computed w pierwotnym zapytaniu. Optymalizator rozszerzył definicje obu kolumn wyliczanych, ale zdołał dopasować z powrotem tylko utrwaloną i indeksowaną kolumnę wyliczoną dla wewnętrznego aliasu T1 . Pozostawienie T2 Odwołanie rozwinięte spowodowało, że zewnętrzna strona złączenia musiała podać kolumny tabeli bazowej (A , B i C ) potrzebne do obliczenia tego wyrażenia dla każdego wiersza.
Jak to czasami bywa, możliwe jest przepisanie tego zapytania, aby problem zniknął (jedna opcja jest pokazana w mojej starej odpowiedzi na pytanie Stack Exchange). Korzystając z SQL Server 2016, możemy również wypróbować flagę śledzenia 176, aby zapobiec rozszerzaniu wyliczonych kolumn:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D
OPTION (QUERYTRACEON 176); -- New! Plan wykonania został znacznie ulepszony:
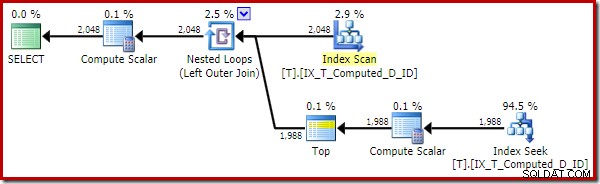
Ten plan wykonania zawiera tylko odwołania do wyliczonych kolumn. Skalary obliczeniowe nie robią nic użytecznego i zostałyby wyczyszczone, gdyby optymalizator był nieco bardziej uporządkowany w domu.
Ważną kwestią jest to, że optymalny indeks jest teraz używany poprawnie, a sortowanie i wyszukiwanie kluczy zostały wyeliminowane. Wszystko przez uniemożliwienie SQL Serverowi robienia czegoś, czego nigdy byśmy się nie spodziewali (rozwijając utrwaloną i indeksowaną kolumnę obliczeniową).
Korzystanie z LEAD
Pierwotne pytanie Stack Exchange było skierowane do SQL Server 2008, gdzie LEAD jest niedostępne. Spróbujmy wyrazić wymagania dla SQL Server 2016 przy użyciu nowszej składni:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed; Plan wykonania SQL Server 2016 to:
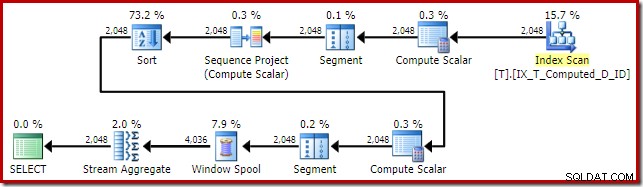
Ten kształt planu jest dość typowy dla prostej funkcji okna trybu wiersza. Jedynym nieoczekiwanym elementem jest operator Sort pośrodku. Gdyby zestaw danych był duży, to sortowanie może mieć duży wpływ na wydajność i wykorzystanie pamięci.
Problemem, po raz kolejny, jest obliczanie rozszerzania kolumn. W tym przypadku jedno z rozwiniętych wyrażeń znajduje się w pozycji, która uniemożliwia normalną logikę optymalizatora upraszczającą sortowanie.
Próbowanie dokładnie tego samego zapytania z flagą śledzenia 176:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed
OPTION (QUERYTRACEON 176); Tworzy plan:
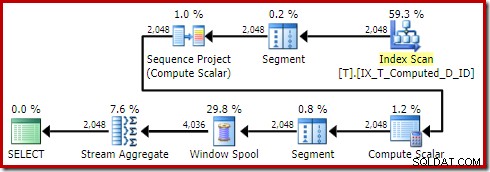
Sort zniknął tak, jak powinien. Zauważ też mimochodem, że to zapytanie kwalifikuje się do trywialnego planu, całkowicie unikając optymalizacji opartej na kosztach.
Wyłączone dopasowywanie wyrażeń ogólnych
Jednym ze wspomnianych wcześniej zastrzeżeń było to, że flaga śledzenia 176 wyłącza również dopasowywanie wyrażeń w zapytaniu źródłowym do utrwalonych kolumn obliczeniowych.
Aby to zilustrować, rozważ następującą wersję przykładowego zapytania. LEAD obliczenie zostało usunięte, a odniesienia do obliczonej kolumny w SELECT i ORDER BY klauzule zostały zastąpione podstawowymi wyrażeniami. Uruchom go najpierw bez flagi śledzenia 176:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C; Wyrażenia są dopasowywane do utrwalonej kolumny obliczeniowej, a plan wykonania to prosty uporządkowany skan indeksu nieklastrowanego:
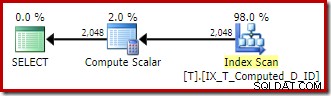
Skalar obliczeniowy jest po raz kolejny pozostałością architektonicznych śmieci.
Teraz wypróbuj to samo zapytanie z włączoną flagą śledzenia 176:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); -- New! Nowy plan wykonania to:
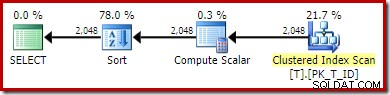
Skanowanie indeksu nieklastrowego zostało zastąpione skanowaniem indeksu klastrowego. Obliczenia skalarne ocenia wyrażenie, a kolejność sortowania według wyniku. Pozbawiony możliwości dopasowywania wyrażeń do utrwalonych kolumn wyliczanych, optymalizator nie może korzystać z utrwalonej wartości lub indeksu nieklastrowanego.
Pamiętaj, że ograniczenie dopasowania wyrażeń dotyczy tylko utrwalonych kolumny obliczane, gdy flaga śledzenia 176 jest aktywna. Jeśli sprawimy, że wyliczona kolumna będzie indeksowana, ale nie utrwalona, dopasowywanie wyrażeń działa poprawnie.
Aby usunąć utrwalony atrybut, najpierw musimy usunąć indeks nieklastrowany. Po dokonaniu zmiany możemy od razu przywrócić indeks (ponieważ wyrażenie jest deterministyczne i precyzyjne):
DROP INDEX IX_T_Computed_D_ID ON dbo.T; GO ALTER TABLE dbo.T ALTER COLUMN Computed DROP PERSISTED; GO CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
Optymalizator nie ma teraz problemów z dopasowaniem wyrażenia zapytania do kolumny wyliczanej, gdy flaga śledzenia 176 jest aktywna:
-- Computed column no longer persisted
-- but still indexed. TF 176 active.
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); Plan wykonania powraca do optymalnego nieklastrowego skanowania indeksu bez sortowania:
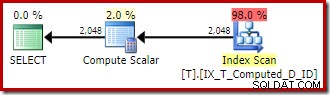
Podsumowując:flaga śledzenia 176 zapobiega utrwalonemu rozszerzaniu kolumn obliczanych. Jako efekt uboczny zapobiega również dopasowywaniu wyrażeń zapytania tylko do utrwalonych kolumn obliczeniowych.
Metadane schematu są ładowane tylko raz, podczas fazy wiązania. Flaga śledzenia 176 zapobiega rozwinięciu, więc definicja kolumny wyliczanej nie jest ładowana w tym czasie. Późniejsze dopasowywanie wyrażeń do kolumn nie może działać bez definicji kolumny wyliczanej, do której należy dopasować.
Początkowe ładowanie metadanych wprowadza wszystkie kolumny, a nie tylko te, do których odwołuje się zapytanie (ta optymalizacja jest wykonywana później). Dzięki temu wszystkie kolumny obliczeniowe są dostępne do dopasowania, co jest generalnie dobrą rzeczą. Niestety, jeśli jedna z załadowanych kolumn wyliczanych zawiera skalarną funkcję zdefiniowaną przez użytkownika, jej obecność wyłącza równoległość dla całego zapytania, nawet gdy problematyczna kolumna nie jest używana. Flaga śledzenia 176 może również w tym pomóc, jeśli dana kolumna jest utrwalona. Nie wczytując definicji, skalarna funkcja zdefiniowana przez użytkownika nigdy nie jest obecna, więc równoległość nie jest wyłączona.
Ostateczne myśli
Wydaje mi się, że świat SQL Server byłby lepszym miejscem, gdyby optymalizator traktował utrwalone lub indeksowane kolumny obliczeniowe bardziej jak zwykłe kolumny. W prawie wszystkich przypadkach byłoby to lepiej dopasowane do oczekiwań deweloperów niż w obecnym układzie. Rozszerzanie kolumn obliczeniowych do ich podstawowych wyrażeń, a później próba ich dopasowania nie jest tak skuteczna w praktyce, jak mogłaby sugerować teoria.
Dopóki SQL Server nie zapewni specyficznej obsługi, aby zapobiec utrwalonemu lub indeksowanemu rozszerzaniu kolumn obliczeniowych, nowa flaga śledzenia 176 jest kuszącą opcją dla użytkowników SQL Server 2016, aczkolwiek niedoskonałą. To trochę niefortunne, że wyłącza ogólne dopasowanie wyrażeń jako efekt uboczny. Szkoda też, że wyliczona kolumna musi być utrwalona podczas indeksowania. Istnieje wtedy ryzyko użycia flagi śledzenia do celów innych niż udokumentowane do rozważenia.
Można śmiało powiedzieć, że większość problemów z zapytaniami dotyczącymi kolumn obliczeniowych można ostatecznie rozwiązać w inny sposób, biorąc pod uwagę wystarczającą ilość czasu, wysiłku i wiedzy. Z drugiej strony, flaga śledzenia 176 często wydaje się działać jak magia. Wybór, jak mówią, należy do Ciebie.
Aby zakończyć, oto kilka interesujących problemów z kolumnami obliczeniowymi, które korzystają z flagi śledzenia 176:
- Nieużywany indeks kolumn obliczonych
- PERSISTED kolumna obliczeniowa nie jest używana podczas partycjonowania funkcji okien
- Utrzymująca się kolumna obliczeniowa powodująca skanowanie
- Wyliczany indeks kolumn nie jest używany z typami danych MAX
- Poważny problem z wydajnością z utrwalonymi kolumnami obliczeniowymi i połączeniami
- Dlaczego SQL Server „oblicza skalarne”, kiedy WYBIERAM utrwaloną kolumnę obliczeniową?
- Kolumny podstawowe używane zamiast utrwalonych kolumn obliczonych przez silnik
- Kolumna obliczana z UDF wyłącza równoległość dla zapytań dotyczących *innych* kolumn