Widzę wiele rad, które mówią coś w stylu „Zmień kursor na operację opartą na zbiorach; to przyspieszy to”. Chociaż często tak się dzieje, nie zawsze jest to prawdą. Jednym z przypadków użycia, który widzę, w którym kursor wielokrotnie przewyższa typowe podejście oparte na zbiorach, jest obliczanie sum bieżących. Dzieje się tak dlatego, że podejście oparte na zbiorach zwykle musi przyglądać się pewnej części danych bazowych więcej niż jeden raz, co może być wykładniczo złe, gdy dane stają się większe; podczas gdy kursor – jakkolwiek bolesny może to zabrzmieć – może przejść przez każdy wiersz/wartość dokładnie raz.
To są nasze podstawowe opcje w większości popularnych wersji SQL Server. Jednak w SQL Server 2012 wprowadzono kilka ulepszeń funkcji okienkowych i klauzuli OVER, głównie wynikających z kilku świetnych sugestii przedstawionych przez innego MVP Itzika Ben-Gana (tutaj jest jedna z jego sugestii). W rzeczywistości Itzik ma nową książkę MS-Press, która szczegółowo omawia wszystkie te ulepszenia, zatytułowaną „Microsoft SQL Server 2012 High-Performance T-SQL using Window Functions”.
Więc naturalnie byłam ciekawa; czy nowe funkcje okienek sprawią, że techniki kursora i samodzielnego łączenia staną się przestarzałe? Czy byłyby łatwiejsze do zakodowania? Czy byłyby szybsze we wszystkich (nieważne we wszystkich) przypadkach? Jakie inne podejścia mogą być ważne?
Konfiguracja
Aby przeprowadzić testy, skonfigurujmy bazę danych:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO A następnie wypełnij tabelę 10 000 wierszy, które możemy wykorzystać do wykonania kilku bieżących sum. Nic zbyt skomplikowanego, tylko tabela podsumowująca z wierszem dla każdej daty i liczbą reprezentującą liczbę wystawionych mandatów za przekroczenie prędkości. Od kilku lat nie miałem mandatu za przekroczenie prędkości, więc nie wiem, dlaczego był to mój podświadomy wybór dla uproszczonego modelu danych, ale tak jest.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Wyniki skrócone:
A więc znowu 10 000 wierszy całkiem prostych danych – małe wartości INT i seria dat od 1984 do maja 2011.
Podejścia
Teraz moje zadanie jest stosunkowo proste i typowe dla wielu aplikacji:zwraca zestaw wyników, który zawiera wszystkie 10 000 dat, wraz ze skumulowaną sumą wszystkich mandatów za przekroczenie prędkości do tej daty włącznie. Większość ludzi najpierw spróbowałaby czegoś takiego (nazwiemy to „połączeniem wewnętrznym " metoda):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
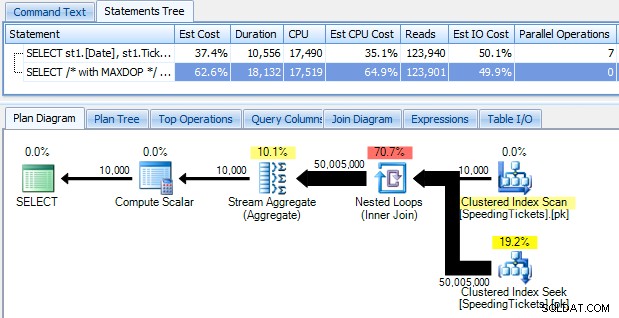
…i bądź zszokowany, gdy odkryjesz, że bieganie trwa prawie 10 sekund. Zbadajmy szybko, dlaczego, przeglądając graficzny plan wykonania za pomocą SQL Sentry Plan Explorer:

Duże, grube strzałki powinny natychmiast wskazywać, co się dzieje:zagnieżdżona pętla odczytuje jeden wiersz dla pierwszej agregacji, dwa wiersze dla drugiego, trzy wiersze dla trzeciego i tak dalej przez cały zestaw 10 000 wierszy. Oznacza to, że powinniśmy zobaczyć mniej więcej (10000 * (10000 + 1)) / 2) wierszy przetworzonych po przejściu całego zestawu, co wydaje się zgadzać z liczbą wierszy pokazaną w planie.
Należy zauważyć, że uruchomienie zapytania bez równoległości (przy użyciu podpowiedzi do zapytania OPCJA (MAXDOP 1)) sprawia, że kształt planu jest nieco prostszy, ale nie pomaga w ogóle ani w czasie wykonywania, ani we/wy; jak pokazano w planie, czas trwania właściwie prawie się podwaja, a odczyty zmniejszają się tylko o bardzo mały procent. W porównaniu z poprzednim planem:
Istnieje wiele innych podejść, które ludzie próbowali uzyskać w celu uzyskania efektywnych sum biegowych. Jednym z przykładów jest „metoda podzapytania ", który po prostu używa skorelowanego podzapytania w taki sam sposób, jak opisana powyżej metoda łączenia wewnętrznego:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Porównanie tych dwóch planów:
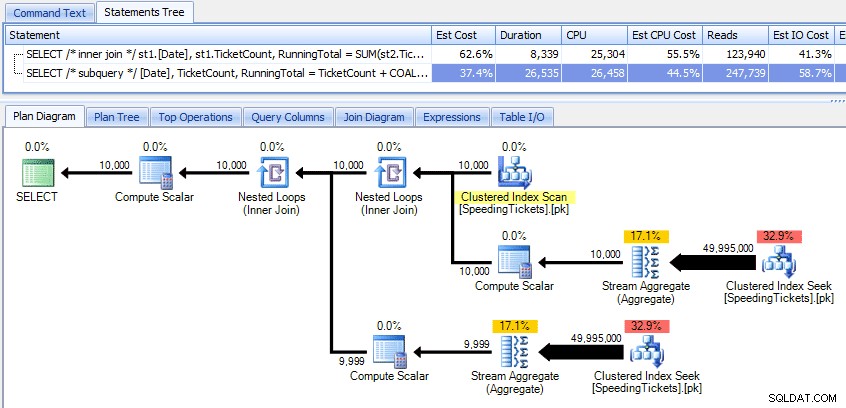
Więc chociaż metoda podzapytania wydaje się mieć bardziej wydajny ogólny plan, jest gorzej tam, gdzie ma to znaczenie:czas trwania i I/O. Możemy zobaczyć, co się do tego przyczynia, zagłębiając się nieco głębiej w plany. Przechodząc do zakładki Top Operations, widzimy, że w metodzie inside join wyszukiwanie indeksu klastrowego jest wykonywane 10 000 razy, a wszystkie inne operacje są wykonywane tylko kilka razy. Jednak kilka operacji jest wykonywanych 9999 lub 10000 razy w metodzie podzapytania:
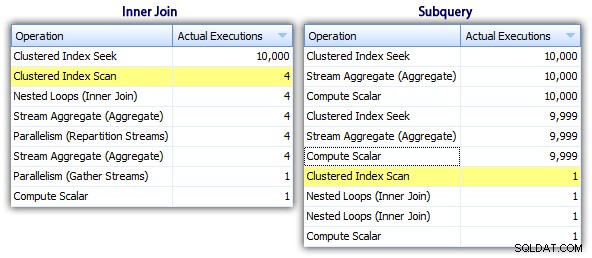
Tak więc podejście podzapytania wydaje się gorsze, a nie lepsze. Następną metodą, którą wypróbujemy, będę nazywać „dziwaczną aktualizacją ". To nie jest do końca gwarantowane działanie i nigdy nie polecałbym jej do kodu produkcyjnego, ale dołączam ją dla kompletności. Zasadniczo dziwaczna aktualizacja wykorzystuje fakt, że podczas aktualizacji można przekierować przypisanie i matematykę, więc że zmienna rośnie za kulisami, gdy każdy wiersz jest aktualizowany.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Powtórzę, że nie wierzę, że takie podejście jest bezpieczne dla produkcji, niezależnie od zeznań, jakie usłyszysz od ludzi, że to „nigdy nie zawodzi”. O ile zachowanie nie jest udokumentowane i gwarantowane, staram się trzymać z daleka od założeń opartych na zaobserwowanym zachowaniu. Nigdy nie wiadomo, kiedy jakaś zmiana w ścieżce decyzyjnej optymalizatora (oparta na zmianie statystyki, zmianie danych, dodatku Service Pack, flagi śledzenia, wskazówce dotyczącej zapytania, co masz) drastycznie zmieni plan i potencjalnie doprowadzi do innej kolejności. Jeśli naprawdę podoba ci się to nieintuicyjne podejście, możesz poczuć się trochę lepiej, używając opcji zapytania FORCE ORDER (a to spowoduje próbę użycia uporządkowanego skanowania PK, ponieważ jest to jedyny dopuszczalny indeks w zmiennej tabeli):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
Aby uzyskać nieco większą pewność przy nieco wyższych kosztach we/wy, możesz przywrócić oryginalny stół do gry i upewnić się, że używane są PK na stole podstawowym:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Osobiście nie sądzę, że jest to o wiele bardziej gwarantowane, ponieważ część operacji SET może potencjalnie wpływać na optymalizator niezależnie od reszty zapytania. Ponownie, nie polecam tego podejścia, zamieszczam tylko porównanie dla kompletności. Oto plan z tego zapytania:
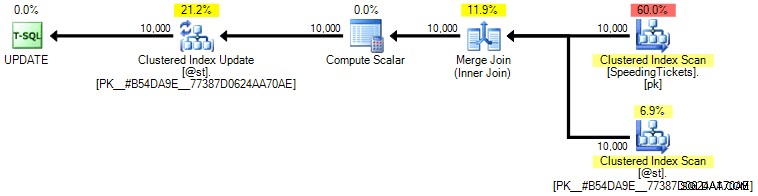
Na podstawie liczby egzekucji, które widzimy w zakładce Najważniejsze operacje (oszczędzę ci zrzut ekranu; jest to 1 na każdą operację), jasne jest, że nawet jeśli wykonamy sprzężenie, aby poczuć się lepiej podczas zamawiania, dziwaczne aktualizacja umożliwia obliczanie bieżących sum w jednym przebiegu danych. W porównaniu z poprzednimi zapytaniami jest znacznie bardziej wydajny, mimo że najpierw zrzuca dane do zmiennej tabeli i jest rozdzielony na wiele operacji:

To prowadzi nas do „rekurencyjnego CTE metoda. Ta metoda wykorzystuje wartość daty i opiera się na założeniu, że nie ma luk. Ponieważ wypełniliśmy te dane powyżej, wiemy, że jest to w pełni ciągła seria, ale w wielu scenariuszach nie można tego zrobić założenie.Tak więc, chociaż uwzględniłem to dla kompletności, to podejście nie zawsze będzie prawidłowe.W każdym razie używa rekurencyjnego CTE z pierwszą (znaną) datą w tabeli jako kotwicą i rekurencyjną porcja określona przez dodanie jednego dnia (dodanie opcji MAXRECURSION, bo wiemy dokładnie ile mamy wierszy):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
To zapytanie działa tak samo wydajnie, jak dziwaczna metoda aktualizacji. Możemy to porównać z podzapytaniami i metodami łączenia wewnętrznego:

Podobnie jak w przypadku dziwacznej metody aktualizacji, nie zalecałbym tego podejścia CTE w środowisku produkcyjnym, chyba że możesz absolutnie zagwarantować, że w Twojej kolumnie klucza nie ma luk. Jeśli możesz mieć luki w swoich danych, możesz skonstruować coś podobnego za pomocą ROW_NUMBER(), ale nie będzie to bardziej wydajne niż powyższa metoda samodzielnego łączenia.
A potem mamy „kursor " podejście:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; …czyli dużo więcej kodu, ale wbrew temu, co może sugerować popularna opinia, wraca w ciągu 1 sekundy. Możemy zobaczyć, dlaczego z niektórych szczegółów planu powyżej:większość innych podejść kończy się czytaniem tych samych danych w kółko, podczas gdy podejście kursora odczytuje każdy wiersz raz i utrzymuje bieżącą sumę w zmiennej zamiast obliczania sumy w kółko i znowu. Możemy to zobaczyć, patrząc na stwierdzenia uchwycone podczas generowania rzeczywistego planu w Eksploratorze planów:
Widzimy, że zebrano ponad 20 000 wyciągów, ale jeśli posortujemy według szacunkowych lub rzeczywistych wierszy malejąco, okaże się, że są tylko dwie operacje, które obsługują więcej niż jeden wiersz. Co jest dalekie od kilku z powyższych metod, które powodują odczyty wykładnicze z powodu ciągłego czytania tych samych poprzednich wierszy dla każdego nowego wiersza.
Przyjrzyjmy się teraz nowym ulepszeniom okien w SQL Server 2012. W szczególności możemy teraz obliczyć SUMA OVER() i określić zestaw wierszy względem bieżącego wiersza. Na przykład:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Te dwa zapytania dają tę samą odpowiedź, z poprawnymi sumami bieżącymi. Ale czy działają dokładnie tak samo? Plany sugerują, że nie. Wersja z ROWS ma dodatkowy operator, projekt sekwencji 10 000 wierszy:
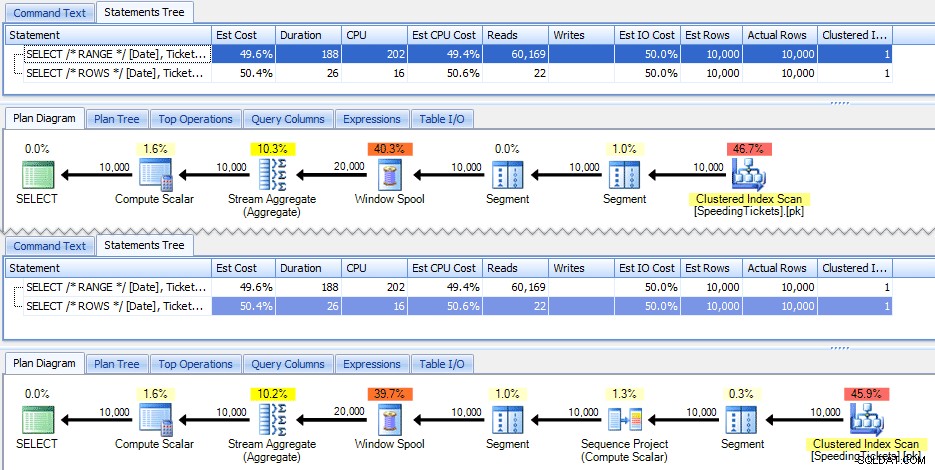
I to jest wielkość różnicy w planie graficznym. Ale jeśli przyjrzysz się trochę bliżej rzeczywistym metrykom czasu wykonywania, zobaczysz niewielkie różnice w czasie trwania i procesorze oraz ogromną różnicę w odczytach. Dlaczego to? Cóż, dzieje się tak dlatego, że RANGE używa buforu na dysku, podczas gdy ROWS używa buforu w pamięci. Przy małych zestawach różnica jest prawdopodobnie znikoma, ale koszt szpuli na dysku może z pewnością stać się bardziej widoczny w miarę powiększania się zestawów. Nie chcę zepsuć zakończenia, ale można podejrzewać, że jedno z tych rozwiązań sprawdzi się lepiej niż drugie w dokładniejszym teście.
Na marginesie, następująca wersja zapytania daje te same wyniki, ale działa jak wolniejsza wersja RANGE powyżej:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Tak więc podczas zabawy z nowymi funkcjami okienek warto pamiętać o takich ciekawostkach:skrócona wersja zapytania lub ta, którą napisałeś jako pierwsza, niekoniecznie jest tą, którą chcesz przenieść do produkcji.
Rzeczywiste testy
Aby przeprowadzić rzetelne testy, stworzyłem procedurę składowaną dla każdego podejścia i mierzyłem wyniki, przechwytując oświadczenia na serwerze, na którym już monitorowałem za pomocą SQL Sentry (jeśli nie korzystasz z naszego narzędzia, możesz zbierać zdarzenia SQL:BatchCompleted w podobny sposób przy użyciu programu SQL Server Profiler).
Przez „uczciwe testy” rozumiem, że na przykład dziwaczna metoda aktualizacji wymaga rzeczywistej aktualizacji danych statycznych, co oznacza zmianę bazowego schematu lub użycie tymczasowej tabeli / zmiennej tabeli. Tak więc ustrukturyzowałem procedury składowane tak, aby każda tworzyła własną zmienną tabeli i albo przechowywała tam wyniki, albo przechowywała tam surowe dane, a następnie aktualizowała wynik. Innym problemem, który chciałem wyeliminować, było zwracanie danych do klienta – więc każda procedura ma parametr debugowania określający, czy nie zwracać żadnych wyników (domyślnie), góra/dół 5, czy wszystkie. W testach wydajności ustawiłem go tak, aby nie zwracał żadnych wyników, ale oczywiście sprawdziłem każdy, aby upewnić się, że zwracają właściwe wyniki.
Wszystkie procedury składowane są modelowane w ten sposób (dołączyłem skrypt, który tworzy bazę danych i procedury składowane, więc dla zwięzłości dołączam tutaj szablon):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO I nazwałem je w partii w następujący sposób:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Szybko zdałem sobie sprawę, że niektóre z tych wywołań nie pojawiały się w Top SQL, ponieważ domyślny próg to 5 sekund. Zmieniłem to na 100 milisekund (coś, czego nigdy nie chcesz robić w systemie produkcyjnym!) w następujący sposób:
Powtarzam:to zachowanie nie jest tolerowane w przypadku systemów produkcyjnych!
Nadal zauważyłem, że jedno z powyższych poleceń nie zostało złapane przez próg Top SQL; była to wersja Windowed_Rows. Więc dodałem tylko do tej partii:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
A teraz otrzymywałem wszystkie 7 wierszy zwróconych w Top SQL. Tutaj są one uporządkowane według wykorzystania procesora malejąco:
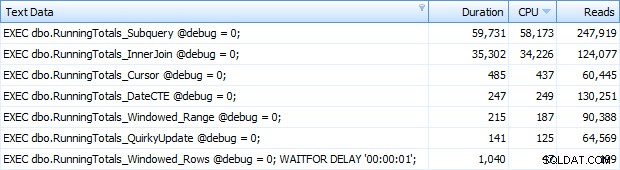
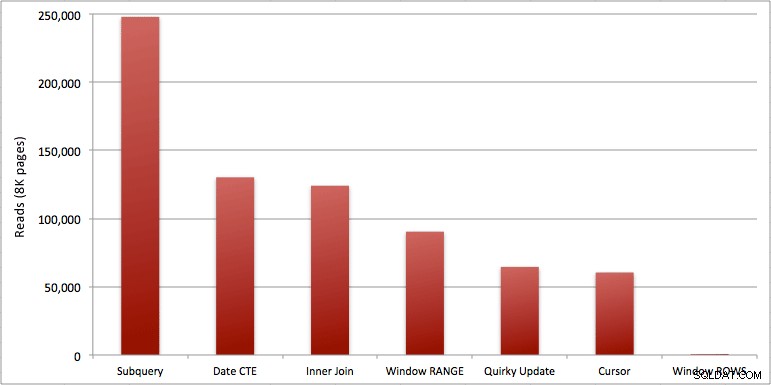
Możesz zobaczyć dodatkową sekundę, którą dodałem do partii Windowed_Rows; nie został złapany przez próg Top SQL, ponieważ zakończył się w zaledwie 40 milisekund! Jest to oczywiście nasz najlepszy produkt i jeśli mamy dostępny SQL Server 2012, powinna to być metoda, której używamy. Kursor też nie jest w połowie zły, biorąc pod uwagę wydajność lub inne problemy z pozostałymi rozwiązaniami. Wykreślanie czasu trwania na wykresie jest dość bezsensowne – dwa szczyty i pięć nieodróżnialnych dołków. Ale jeśli I/O jest Twoim wąskim gardłem, wizualizacja odczytów może być interesująca:
Wniosek
Z tych wyników możemy wyciągnąć kilka wniosków:
- Agregacje okienkowe w programie SQL Server 2012 sprawiają, że problemy z wydajnością związane z wykonywaniem obliczeń sumarycznych (i wielu innych problemów z kolejnymi wierszami/poprzednimi wierszami) są alarmująco bardziej wydajne. Kiedy zobaczyłem małą liczbę odczytów, pomyślałem, że na pewno jest jakiś błąd, że musiałem zapomnieć o wykonaniu jakiejkolwiek pracy. Ale nie, otrzymasz tę samą liczbę odczytów, jeśli twoja procedura składowana wykona po prostu zwykły SELECT z tabeli SpeedingTickets. (Możesz przetestować to samodzielnie za pomocą STATISTICS IO).
- Problemy, o których wspomniałem wcześniej, dotyczące RANGE vs. ROWS, dają nieco inne czasy działania (różnica czasu trwania około 6x – pamiętaj, aby zignorować drugą, którą dodałem za pomocą WAITFOR), ale różnice w odczycie są astronomiczne ze względu na buforowanie na dysku. Jeśli agregacja okienkowa może być rozwiązana za pomocą ROWS, unikaj RANGE, ale powinieneś sprawdzić, czy oba dają ten sam wynik (lub przynajmniej, że ROWS daje poprawną odpowiedź). Należy również pamiętać, że jeśli używasz podobnego zapytania i nie określisz RANGE ani ROWS, plan będzie działał tak, jakbyś określił RANGE).
- Podzapytanie i metody sprzężenia wewnętrznego są stosunkowo kiepskie. 35 sekund do minuty, aby wygenerować te bieżące podsumowania? I to było na jednym, chudym stole bez zwracania wyników klientowi. Te porównania można wykorzystać, aby pokazać ludziom, dlaczego rozwiązanie oparte wyłącznie na zbiorach nie zawsze jest najlepszą odpowiedzią.
- Spośród szybszych podejść, zakładając, że nie jesteś jeszcze gotowy na SQL Server 2012 i zakładając, że odrzucisz zarówno dziwaczną metodę aktualizacji (nieobsługiwaną), jak i metodę daty CTE (nie może zagwarantować ciągłej sekwencji), wykonuje tylko kursor do przyjęcia. Ma najdłuższy czas trwania „szybszych” rozwiązań, ale najmniejszą liczbę odczytów.
Mam nadzieję, że te testy pomogą lepiej docenić ulepszenia okien, które Microsoft dodał do SQL Server 2012. Nie zapomnij podziękować Itzikowi, jeśli zobaczysz go online lub osobiście, ponieważ był on siłą napędową tych zmian. Ponadto mam nadzieję, że pomoże to niektórym uświadomić sobie, że kursor nie zawsze może być złym i przerażającym rozwiązaniem, za które często się przedstawia.
(Jako dodatek przetestowałem funkcję CLR oferowaną przez Pavla Pawłowskiego, a charakterystyka wydajności była prawie identyczna jak w rozwiązaniu SQL Server 2012 przy użyciu ROWS. Odczyty były identyczne, procesor wynosił 78 vs. 47, a całkowity czas trwania wynosił 73 zamiast 40. Więc jeśli w najbliższej przyszłości nie będziesz przechodzić na SQL Server 2012, możesz dodać rozwiązanie Pavela do swoich testów.)
Załączniki:RunningTotals_Demo.sql.zip (2kb)