Na tej stronie znajduje się wiele wpisów na blogu związanych ze statystykami oczekiwania; są to jedne z najważniejszych metryk, których można używać podczas rozwiązywania problemów z wydajnością w programie SQL Server. Statystyki oczekiwania zostały udostępnione w SQL Server 2005 i tradycyjnie reprezentują oczekiwania na poziomie instancji za pośrednictwem sys.dm_os_wait_statistics. Ta informacja jest świetna podczas ogólnego rozwiązywania problemów z wydajnością systemu, ale patrząc na wydajność zapytań, informacje o oczekiwaniu można zobaczyć tylko wtedy, gdy zapytanie było wykonywane i jeśli czekało na zasób za pośrednictwem sys.dm_os_waiting_tasks. Dane w sys.dm_os_waiting_tasks są nietrwałe (to właśnie czeka teraz) i nie jest łatwo je przechwycić i zachować przez całe życie zapytania w celu dostrojenia wydajności w późniejszym czasie.
W SQL Server 2016 ujawniono nowy DMV, sys.dm_exec_session_wait_stats, który zawiera informacje o oczekiwaniach na istniejącą, aktywną sesję. Jeśli znasz identyfikator session_id, możesz śledzić czas oczekiwania na zapytanie, kiedy się ono rozpoczyna i kończy (przechwyć informacje na początku i na końcu zapytania, a następnie porównuj informacje). Wyzwanie polega na tym, że musisz znać identyfikator sesji dla zapytania i musisz wcześniej skonfigurować przechwytywanie danych – co nie jest trywialne, gdy znajdujesz się w środku problemu o wysokim priorytecie.
Informacje statystyki oczekiwania istnieją w rzeczywistym planie wykonania, począwszy od dodatku SP1 dla programu SQL Server 2016. Przechwycone jest tylko 10 najważniejszych oczekiwań i istnieją ograniczenia dotyczące tego, co reprezentują te dane. Na przykład pakiet CXPACKET jest ignorowany i nie jest uwzględniany w danych wyjściowych, ale zostanie uwzględniony w 2016 SP2 i 2017 CU3 i nowszych — gdzie nieistotne oczekiwania na równoległość są zamiast tego przechwytywane przez CXCONSUMER (które nie zostaną uwzględnione w rzeczywistych oczekiwaniach planu).
Jak więc możemy zobaczyć, na co naprawdę czeka konkretne zapytanie? Możemy użyć Query Store! SQL Server 2017 obejmuje przechwytywanie informacji statystycznych oczekiwania w magazynie zapytań, a ta funkcja jest również dostępna w Azure SQL Database. Statystyki oczekiwania są powiązane z planem zapytań i są rejestrowane w czasie, podobnie jak statystyki środowiska uruchomieniowego. Dodanie statystyk oczekiwania w Query Store było najważniejszym żądaniem funkcji po jego pierwszym wydaniu, a wszystkie te informacje razem tworzą potężne możliwości rozwiązywania problemów.
Pierwsze kroki
Przechwytywanie statystyk oczekiwania w magazynie zapytań jest domyślnie włączone dla Azure SQL Database. Gdy nowa baza danych jest tworzona w programie SQL Server 2017 lub baza danych jest uaktualniana z programu SQL Server 2014 lub wcześniejszego, magazyn zapytań jest domyślnie wyłączony…, a zatem przechwytywanie statystyk oczekiwania jest wyłączone. Gdy baza danych jest aktualizowana z SQL Server 2016, jeśli ma włączoną opcję Magazyn zapytań, po uaktualnieniu zostanie włączone zbieranie statystyk oczekiwania dla Magazynu zapytań.
W celach demonstracyjnych przywróciłem bazę danych WideWorldImporters, a następnie wykonałem poniższe zapytania, aby włączyć Query Store i wyczyścić wszelkie dane, które mogły istnieć wcześniej (konieczne tylko, ponieważ jest to przykładowa baza danych):
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE ); GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE CLEAR; GO
W przypadku powyższych instrukcji używane są ustawienia domyślne, a jeśli chcesz zmienić którąkolwiek z opcji, możesz to zrobić za pomocą interfejsu użytkownika lub instrukcji ALTER DATABASE. Teraz, gdy magazyn zapytań jest włączony, rozpocznie przechwytywanie danych zapytań, w tym tekstu zapytania, planów, statystyk czasu wykonywania i statystyk oczekiwania.
Oglądanie statystyk oczekiwania
Aby wygenerować niektóre dane, utworzymy procedurę składowaną, która wielokrotnie uruchamia równoległe zapytanie.
DROP PROCEDURE IF EXISTS [Sales].[OrderInfo];
GO
CREATE PROCEDURE [Sales].[OrderInfo]
AS
BEGIN
WHILE 1=1
BEGIN
SELECT *
FROM Sales.OrderLines ol
INNER JOIN Warehouse.StockItems s
ON ol.StockItemID = s.StockItemID
OPTION (QUERYTRACEON 8649);
END
END Następnie utwórz plik .cmd z następującym kodem:
start sqlcmd -S WIN2016\SQL2017 -d WideWorldImporters -q"EXECUTE [Sprzedaż].[OrderInfo];"exit
To pozwala nam nie uruchom SP wewnątrz Management Studio, co powoduje znaczne oczekiwanie ASYNC_NETWORK_IO; chcemy zobaczyć oczekiwania związane z równoległością. Zapisz plik .cmd, a następnie kliknij dwukrotnie, aby uruchomić. Możesz wygenerować dodatkowe obciążenie, uruchamiając wiele plików. W tym scenariuszu zobaczymy przede wszystkim oczekiwania związane z tym zapytaniem, ponieważ nie mamy innego obciążenia. Zachęcamy do jednoczesnego wykonywania innych zapytań w bazie danych WideWorldImporters, jeśli chcesz wygenerować jeszcze więcej danych oczekiwania.
Po kilku minutach zatrzymaj pliki poleceń i rozwiń bazę danych WideWorldImporters w Management Studio, aby wyświetlić folder Query Store i raporty znajdujące się pod spodem. Jeśli otworzysz raport Najczęstsze zapytania zużywające zasoby, jako główne zapytanie powinno zostać wyświetlone zapytanie procedury składowanej.
Domyślny widok tego raportu przedstawia zapytania o najdłuższym łącznym czasie trwania. Aby wyświetlić zapytania na podstawie statystyk oczekiwania, możemy wybrać przycisk Konfiguruj i zmienić go na Czas oczekiwania (ms).
 Przycisk Konfiguruj w widoku raportu (prawy górny róg)
Przycisk Konfiguruj w widoku raportu (prawy górny róg) 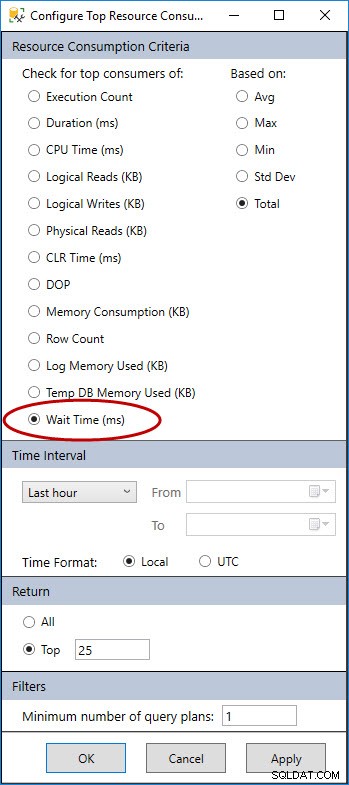 Zmiana zasobu raportu Pamiętaj, że możesz również skonfigurować interwał czasowy i liczbę zwracanych zapytań. W tym przykładzie dopuszczalna jest ostatnia godzina.
Zmiana zasobu raportu Pamiętaj, że możesz również skonfigurować interwał czasowy i liczbę zwracanych zapytań. W tym przykładzie dopuszczalna jest ostatnia godzina. Jeśli najedziesz kursorem na pasek przy pierwszym zapytaniu, zobaczysz czas oczekiwania na zapytanie. Ten widok jest obecnie jedynym sposobem wyświetlenia informacji o oczekiwaniu w interfejsie użytkownika, ale mamy nadzieję, że w przyszłej wersji Management Studio pojawią się dodatkowe raporty dotyczące statystyk oczekiwania.
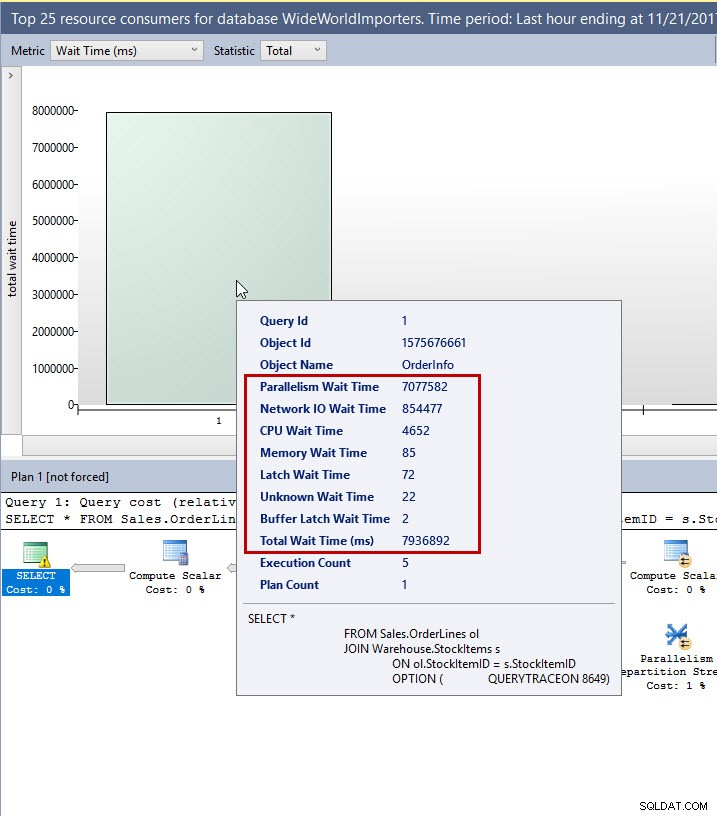 Czekaj na informacje w interfejsie
Czekaj na informacje w interfejsie
Ci z was, którzy przez jakiś czas pracowali ze statystykami oczekiwania, zauważą, że opisy typów oczekiwania są inne. Oznacza to, że zamiast typu oczekiwania CXPACKET, aby wskazać równoległość, zobaczysz po prostu „Typ oczekiwania równoległego”. Jest to podstawowa różnica w magazynie zapytań:typy oczekiwania są pogrupowane w kategorie. W tym momencie w SQL Server istnieje ponad 900 różnych typów oczekiwania, a próba śledzenia każdego z nich z osobna jest niezwykle kosztowna. Ponadto Query Store został zaprojektowany z myślą o wszystkich specjalistach ds. danych — niezależnie od tego, czy jesteś ekspertem w dostrajaniu wydajności, czy dopiero zaczynasz rozumieć, jak działa SQL Server, powinieneś być w stanie użyć Query Store, aby łatwo znaleźć zapytania o niskiej wydajności. Oznacza to również, że informacje dotyczące oczekiwania będą łatwiejsze do zrozumienia. Aby uzyskać pełną listę kategorii oczekiwania i typów oczekiwania w obrębie, odwiedź dokumentację sys.query_store_wait_stats.
Możesz również wyświetlić informacje o oczekiwaniu za pomocą T-SQL. Przykładowe zapytanie to to poniżej, które zawiera zapytanie, identyfikator(y) planu dla tego zapytania i statystyki oczekiwania dla danego przedziału czasu:
SELECT TOP (10)
[ws].[wait_category_desc],
[ws].[avg_query_wait_time_ms],
[ws].[total_query_wait_time_ms],
[ws].[plan_id],
[qt].[query_sql_text],
[rsi].[start_time],
[rsi].[end_time]
FROM [sys].[query_store_query_text] [qt]
JOIN [sys].[query_store_query] [q]
ON [qt].[query_text_id] = [q].[query_text_id]
JOIN [sys].[query_store_plan] [qp]
ON [q].[query_id] = [qp].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [qp].[plan_id] = [rs].[plan_id]
JOIN [sys].[query_store_runtime_stats_interval] [rsi]
ON [rs].[runtime_stats_interval_id] = [rsi].[runtime_stats_interval_id]
JOIN [sys].[query_store_wait_stats] [ws]
ON [ws].[runtime_stats_interval_id] = [rs].[runtime_stats_interval_id]
AND [ws].[plan_id] = [qp].[plan_id]
WHERE [rsi].[end_time] > DATEADD(MINUTE, -5, GETUTCDATE())
AND [ws].[execution_type] = 0
ORDER BY [ws].[avg_query_wait_time_ms] DESC;
 Wyjście zapytania
Wyjście zapytania
Chociaż możesz teraz zobaczyć wszystkie oczekiwania na dane zapytanie i jego plan, nadal będziesz musiał zagłębić się w wydajność, aby zrozumieć, na przykład, dlaczego zapytanie działa równolegle (jeśli być może tego nie chcesz) lub co może blokować zapytanie. Należy zauważyć, że statystyki oczekiwania, podobnie jak statystyki środowiska uruchomieniowego, są powiązane z planem kwerend w czasie. W tych danych wyjściowych długość interwału dla magazynu zapytań jest ustawiona na 10 minut, więc statystyki oczekiwania dotyczą każdego planu dla tego 10-minutowego interwału (23:50 w dniu 21 listopada 2017 r. do północy 22 listopada 2017 r.). Domyślnie długość interwału po włączeniu magazynu zapytań wynosi 60 minut.
Podsumowanie
Statystyki oczekiwania w połączeniu z indywidualnymi planami zapytań sprawiają, że Query Store jest jeszcze bardziej potężnym narzędziem do rozwiązywania problemów z wydajnością systemu i zapytań. Magazyn zapytań to jedyna funkcja, która umożliwia natywne przechwytywanie zapytań, planów, metryk wydajności i statystyk oczekiwania w jednym miejscu. Dla tych z was, którzy są przyzwyczajeni do niezliczonych typów oczekiwania, dostosowanie się do kategorii używanych w magazynie zapytań powinno być bezproblemowe. Dla każdego nowego w statystykach oczekiwania kategorie są świetnym miejscem do rozpoczęcia zrozumienia zasobu, na który czeka zapytanie.



