Jakość planu wykonania w dużym stopniu zależy od dokładności szacowanej liczby wierszy wyprowadzanych przez każdego operatora planu. Jeśli szacowana liczba wierszy jest znacznie odchylona od rzeczywistej liczby wierszy, może to mieć znaczący wpływ na jakość planu wykonania zapytania. Niska jakość planu może być odpowiedzialna za nadmierne operacje we/wy, zawyżony procesor, ciśnienie pamięci, zmniejszoną przepustowość i zmniejszoną ogólną współbieżność.
Przez „jakość planu” – mówię o tym, że SQL Server generuje plan wykonania, który skutkuje wyborami operatora fizycznego, które odzwierciedlają aktualny stan danych. Podejmując takie decyzje w oparciu o dokładne dane, istnieje większa szansa, że zapytanie zostanie wykonane poprawnie. Szacunkowe wartości kardynalności są używane jako dane wejściowe do kalkulacji kosztów operatora, a gdy wartości są zbyt odległe od rzeczywistości, może być wyraźny negatywny wpływ na plan wykonania. Te oszacowania są przekazywane do różnych modeli kosztów związanych z samym zapytaniem, a błędne oszacowania wierszy mogą wpływać na różne decyzje, w tym wybór indeksu, operacje wyszukiwania i skanowania, wykonywanie równoległe lub szeregowe, wybór algorytmu łączenia, wewnętrzne lub zewnętrzne łączenie fizyczne wybór (np. kompilacja a sonda), generowanie bufora, wyszukiwanie zakładek w porównaniu z pełnym dostępem do klastrów lub tabel sterty, wybór agregacji strumienia lub mieszania oraz czy modyfikacja danych wykorzystuje szeroki lub wąski plan.
Jako przykład załóżmy, że masz następujący SELECT zapytanie (za pomocą bazy danych kredytów):
SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
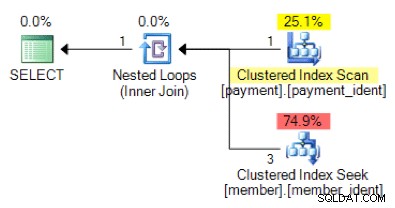
W oparciu o logikę zapytania, czy następujący kształt planu jest taki, jakiego oczekiwałbyś zobaczyć?
A co z tym alternatywnym planem, w którym zamiast zagnieżdżonej pętli mamy hash match?
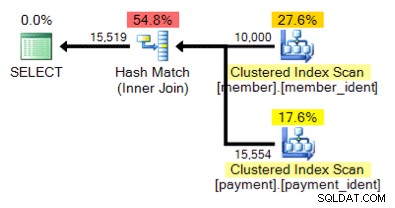
Odpowiedź „prawidłowa” zależy od kilku innych czynników – ale jednym z głównych czynników jest liczba wierszy w każdej z tabel. W niektórych przypadkach jeden algorytm łączenia fizycznego jest bardziej odpowiedni niż drugi – a jeśli początkowe założenia oszacowania kardynalności nie są poprawne, zapytanie może być nieoptymalne.
Identyfikacja kwestie oszacowania kardynalności są stosunkowo proste. Jeśli masz rzeczywisty plan wykonania, możesz porównać szacunkowe i rzeczywiste wartości liczby wierszy dla operatorów i poszukać skosów. SQL Sentry Plan Explorer upraszcza to zadanie, umożliwiając wyświetlanie rzeczywistych i szacunkowych wierszy dla wszystkich operatorów na jednej karcie drzewa planu bez konieczności najeżdżania kursorem na poszczególne operatory w planie graficznym:

Teraz odchylenia nie zawsze skutkują niską jakością planów, ale jeśli masz problemy z wydajnością zapytania i widzisz takie odchylenia w planie, jest to jeden obszar, który jest wart dalszego zbadania.
Identyfikacja problemów z oszacowaniem kardynalności jest stosunkowo prosta, ale rozwiązanie często nie jest. Istnieje wiele przyczyn, dla których mogą wystąpić problemy z oszacowaniem kardynalności. W tym poście omówię dziesięć najczęstszych przyczyn.
Brakujące lub nieaktualne statystyki
Masz nadzieję, że ze wszystkich przyczyn problemów z oszacowaniem kardynalności właśnie ta jest ta zobaczyć, jak to często jest najłatwiejsze do rozwiązania. W tym scenariuszu brakuje Twoich statystyk lub są one nieaktualne. Możesz mieć wyłączone opcje bazy danych do automatycznego tworzenia i aktualizacji statystyk, włączoną opcję „brak przeliczania” dla określonych statystyk lub mieć wystarczająco duże tabele, że automatyczne aktualizacje statystyk po prostu nie są przeprowadzane wystarczająco często.
Problemy z próbkowaniem
Może się zdarzyć, że dokładność histogramu statystyk jest niewystarczająca – na przykład, jeśli masz bardzo dużą tabelę ze znacznymi i/lub częstymi odchyleniami danych. Być może będziesz musiał zmienić próbkowanie z domyślnego, a nawet jeśli to nie pomoże – zbadaj, używając oddzielnych tabel, przefiltrowanych statystyk lub przefiltrowanych indeksów.
Korelacje ukrytych kolumn
Optymalizator zapytań zakłada, że kolumny w tej samej tabeli są niezależne. Na przykład, jeśli masz kolumnę miasta i stanu, możemy intuicyjnie wiedzieć, że te dwie kolumny są ze sobą skorelowane, ale SQL Server tego nie zrozumie, chyba że pomożemy mu za pomocą skojarzonego indeksu wielokolumnowego lub ręcznie utworzonego wielokolumnowego indeksu. statystyki kolumn. Bez pomocy optymalizatorowi w korelacji selektywność predykatów może być przesadzona.
Poniżej znajduje się przykład dwóch skorelowanych predykatów:
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
Zdarza mi się wiedzieć, że 10% z naszych 10 000 wierszy member tabela kwalifikuje się do tej kombinacji, ale optymalizator zapytań zgaduje, że jest to 1% z 10 000 wierszy:
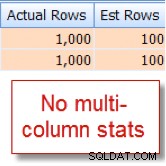
Teraz porównajmy to z odpowiednim oszacowaniem, które widzę po dodaniu statystyk wielokolumnowych:
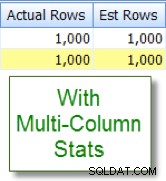
Porównania kolumn wewnątrz tabeli
Podczas porównywania kolumn w tej samej tabeli mogą wystąpić problemy z oszacowaniem liczności. To znany problem. Jeśli musisz to zrobić, możesz poprawić oszacowania liczności porównań kolumn, używając zamiast tego kolumn obliczanych lub przepisując zapytanie tak, aby używało samozłączeń lub wspólnych wyrażeń tabelowych.
Wykorzystanie zmiennej tabeli
Często używasz zmiennych tabeli? Zmienne tabeli pokazują szacunkową kardynalność wynoszącą „1” — co w przypadku niewielkiej liczby wierszy może nie stanowić problemu, ale w przypadku dużych lub niestabilnych zestawów wyników może znacząco wpłynąć na jakość planu zapytań. Poniżej znajduje się zrzut ekranu przedstawiający oszacowanie przez operatora 1 wiersza w porównaniu z rzeczywistymi 1 600 000 wierszy z @charge zmienna tabeli:

Jeśli jest to Twoja główna przyczyna, dobrze byłoby zbadać alternatywy, takie jak tabele tymczasowe lub stałe tabele pomostowe, tam gdzie to możliwe.
UDF skalarne i MSTV
Podobnie jak zmienne tabelowe, wielowyrazowe funkcje wartościujące w tabeli i funkcje skalarne są czarną skrzynką z perspektywy szacowania kardynalności. Jeśli z ich powodu napotykasz problemy z jakością planu, rozważ alternatywę dla wbudowanych funkcji tabeli – lub nawet całkowite wyciągnięcie referencji do funkcji i bezpośrednie odwoływanie się do obiektów.
Poniżej przedstawiono plan szacunkowy w porównaniu z rzeczywistym w przypadku korzystania z funkcji z wartościami w tabeli zawierającej wiele instrukcji:
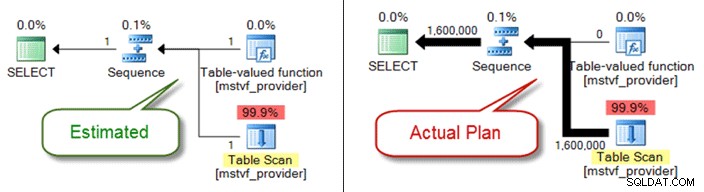
Problemy z typami danych
Niejawne problemy z typami danych w połączeniu z warunkami wyszukiwania i łączenia mogą powodować problemy z oszacowaniem liczności. Mogą również ukradkiem pochłaniać zasoby na poziomie serwera (procesor, we/wy, pamięć), dlatego ważne jest, aby zająć się nimi, gdy tylko jest to możliwe.
Złożone predykaty
Prawdopodobnie widziałeś już ten wzorzec – zapytanie z WHERE klauzula, w której każde odwołanie do kolumny tabeli jest otoczone różnymi funkcjami, operacjami konkatenacji, operacjami matematycznymi i nie tylko. I chociaż nie wszystkie zawijanie funkcji wyklucza prawidłowe oszacowanie kardynalności (takie jak dla LOWER , UPPER i GETDATE ) istnieje wiele sposobów na zakopanie predykatu do tego stopnia, że optymalizator zapytań nie będzie już w stanie dokonywać dokładnych szacunków.
Złożoność zapytań
Podobnie jak w przypadku predykatów ukrytych, czy Twoje zapytania są wyjątkowo złożone? Zdaję sobie sprawę, że „złożony” jest terminem subiektywnym i Twoja ocena może się różnić, ale większość może się zgodzić, że zagnieżdżanie widoków w widokach, które odwołują się do nakładających się tabel, prawdopodobnie nie będzie optymalne – zwłaszcza w połączeniu z ponad 10 łączeniami tabel, odwołania do funkcji i zakopane predykaty. Chociaż optymalizator zapytań wykonuje godne podziwu zadanie, nie jest to magia, a jeśli masz znaczne odchylenia, złożoność zapytań (zapytania z użyciem noża szwajcarskiego) może z pewnością uniemożliwić uzyskanie dokładnych szacunków wierszy dla operatorów.
Kwerendy rozproszone
Czy korzystasz z zapytań rozproszonych z serwerami połączonymi i widzisz znaczące problemy z oszacowaniem kardynalności? Jeśli tak, sprawdź uprawnienia skojarzone z podmiotem głównym serwera połączonego używanym do uzyskiwania dostępu do danych. Bez minimalnego db_ddladmin naprawiono rolę bazy danych dla konta połączonego serwera, ten brak widoczności zdalnych statystyk z powodu niewystarczających uprawnień może być źródłem problemów z oszacowaniem liczności.
I są inne…
Istnieją inne powody, dla których oszacowania kardynalności mogą być wypaczone, ale uważam, że omówiłem te najczęstsze. Kluczową kwestią jest zwrócenie uwagi na przekrzywienia związane ze znanymi, słabo skutecznymi zapytaniami. Nie zakładaj, że plan został wygenerowany na podstawie dokładnych warunków liczenia wierszy. Jeśli te liczby są przekrzywione, musisz najpierw spróbować rozwiązać ten problem.