Patrząc na wydajność zapytań, istnieje wiele świetnych źródeł informacji w SQL Server, a jednym z moich ulubionych jest sam plan zapytań. W ostatnich kilku wydaniach, w szczególności począwszy od SQL Server 2012, każda nowa wersja zawierała więcej szczegółów w planach wykonania. Chociaż lista ulepszeń wciąż rośnie, oto kilka atrybutów, które uważam za cenne:
- NonParallelPlanReason (SQL Server 2012)
- Diagnostyka predykatów resztkowych predykatów (SQL Server 2012 z dodatkiem SP3, SQL Server 2014 z dodatkiem SP2, SQL Server 2016 z dodatkiem SP1)
- Diagnostyka rozlania tempdb (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Włączono flagi śledzenia (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Statystyka wykonywania zapytań przez operatora (SQL Server 2014 SP2, SQL Server 2016)
- Maksymalna ilość pamięci włączona dla pojedynczego zapytania (SQL Server 2014 SP2, SQL Server 2016 SP1)
Aby zobaczyć, co istnieje dla każdej wersji SQL Server, odwiedź stronę Showplan Schema, gdzie można znaleźć schemat dla każdej wersji od SQL Server 2005.
Chociaż uwielbiam te wszystkie dodatkowe dane, ważne jest, aby pamiętać, że niektóre informacje są bardziej istotne dla rzeczywistego planu wykonania niż szacowanego (np. informacje o rozlaniu tempdb). W niektóre dni możemy przechwycić i wykorzystać rzeczywisty plan do rozwiązywania problemów, innym razem musimy użyć planu szacunkowego. Bardzo często otrzymujemy ten szacunkowy plan – plan, który został użyty do potencjalnie problematycznych realizacji – z pamięci podręcznej planów SQL Server. A ściąganie poszczególnych planów jest właściwe podczas dostrajania konkretnego zapytania, zestawu lub zapytań. Ale co, jeśli chcesz mieć pomysły na to, na czym skoncentrować swoje wysiłki związane ze strojeniem pod kątem wzorców?
Pamięć podręczna planu SQL Server jest niesamowitym źródłem informacji, jeśli chodzi o dostrajanie wydajności, i nie mam na myśli po prostu rozwiązywania problemów i próby zrozumienia, co działa w systemie. W tym przypadku mówię o wydobywaniu informacji z samych planów, które znajdują się w sys.dm_exec_query_plan, przechowywane jako XML w kolumnie query_plan.
Kiedy połączysz te dane z informacjami z sys.dm_exec_sql_text (abyś mógł łatwo przeglądać tekst zapytania) i sys.dm_exec_query_stats (statystyki wykonania), możesz nagle zacząć szukać nie tylko tych zapytań, które są najcięższymi trafieniami lub są wykonywane najczęściej, ale te plany, które zawierają określony typ złączenia lub skanowanie indeksu, lub te, które mają najwyższy koszt. Jest to powszechnie określane jako wydobywanie pamięci podręcznej planu i istnieje kilka postów na blogu, które mówią o tym, jak to zrobić. Mój kolega, Jonathan Kehayias, mówi, że nie znosi pisać XML, ale ma kilka postów z zapytaniami o wydobycie pamięci podręcznej planu:
- Dostrajanie „próg kosztów dla równoległości” z pamięci podręcznej planów
- Znajdowanie niejawnych konwersji kolumn w pamięci podręcznej planów
- Sprawdzanie, które zapytania w pamięci podręcznej planu używają określonego indeksu
- Zagłębianie się w pamięć podręczną planów SQL:znajdowanie brakujących indeksów
- Znajdowanie kluczowych wyszukiwań w pamięci podręcznej planów
Jeśli nigdy nie sprawdzałeś, co znajduje się w pamięci podręcznej planu, zapytania w tych postach są dobrym początkiem. Jednak pamięć podręczna planu ma swoje ograniczenia. Na przykład możliwe jest wykonanie zapytania i nie umieszczenie planu w pamięci podręcznej. Jeśli na przykład masz włączoną opcję optymalizacji dla obciążeń adhoc, to przy pierwszym wykonaniu skompilowany odcinek planu jest przechowywany w pamięci podręcznej planu, a nie w pełni skompilowany plan. Ale największym wyzwaniem jest to, że pamięć podręczna planu jest tymczasowa. Istnieje wiele zdarzeń w SQL Server, które mogą całkowicie wyczyścić pamięć podręczną planów lub wyczyścić ją dla bazy danych, a plany mogą zostać przestarzałe z pamięci podręcznej, jeśli nie są używane, lub usunięte po ponownej kompilacji. Aby temu zaradzić, zazwyczaj trzeba regularnie wysyłać zapytania do pamięci podręcznej planu lub wykonywać zrzuty zawartości w tabeli zgodnie z harmonogramem.
Zmienia się to w SQL Server 2016 z Query Store.
Gdy baza danych użytkownika ma włączoną opcję Magazyn zapytań, tekst i plany zapytań wykonywanych względem tej bazy danych są przechwytywane i przechowywane w tabelach wewnętrznych. Zamiast tymczasowego widoku tego, co jest aktualnie wykonywane, mamy długoterminowy obraz tego, co zostało wykonane wcześniej. Ilość przechowywanych danych jest określana przez ustawienie CLEANUP_POLICY, które domyślnie wynosi 30 dni. W porównaniu z pamięcią podręczną planu, która może reprezentować tylko kilka godzin wykonywania zapytania, dane magazynu zapytań zmieniają grę.
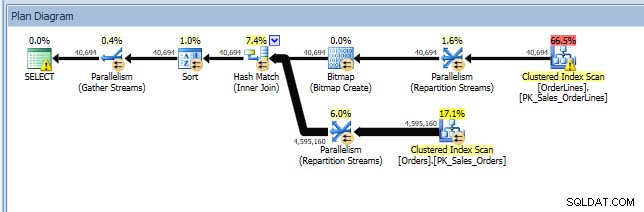
Rozważ scenariusz, w którym przeprowadzasz analizę indeksu — niektóre indeksy nie są używane i masz kilka zaleceń z brakujących indeksów DMV. Brakujące pliki DMV indeksu nie zawierają żadnych szczegółów na temat tego, jakie zapytanie wygenerowało zalecenie dotyczące brakującego indeksu. Możesz wysłać zapytanie do pamięci podręcznej planu, używając zapytania z postu Jonathana Finding Missing Indexes. Jeśli wykonam to na mojej lokalnej instancji SQL Server, otrzymam kilka wierszy danych wyjściowych związanych z niektórymi zapytaniami, które uruchomiłem wcześniej.

Mogę otworzyć plan w Eksploratorze planów i widzę ostrzeżenie na operatorze SELECT, który dotyczy brakującego indeksu:
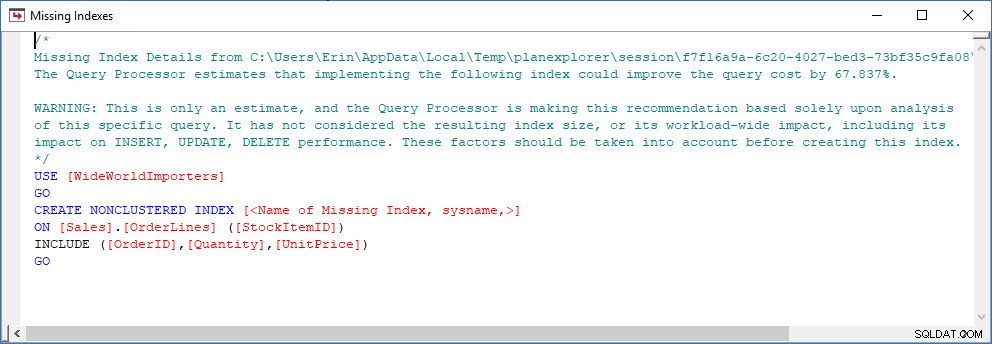
To świetny początek, ale znowu moje wyniki zależą od tego, co jest w pamięci podręcznej. Mogę wziąć zapytanie Jonathana i zmodyfikować je dla Query Store, a następnie uruchomić je w mojej demonstracyjnej bazie danych WideWorldImporters:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
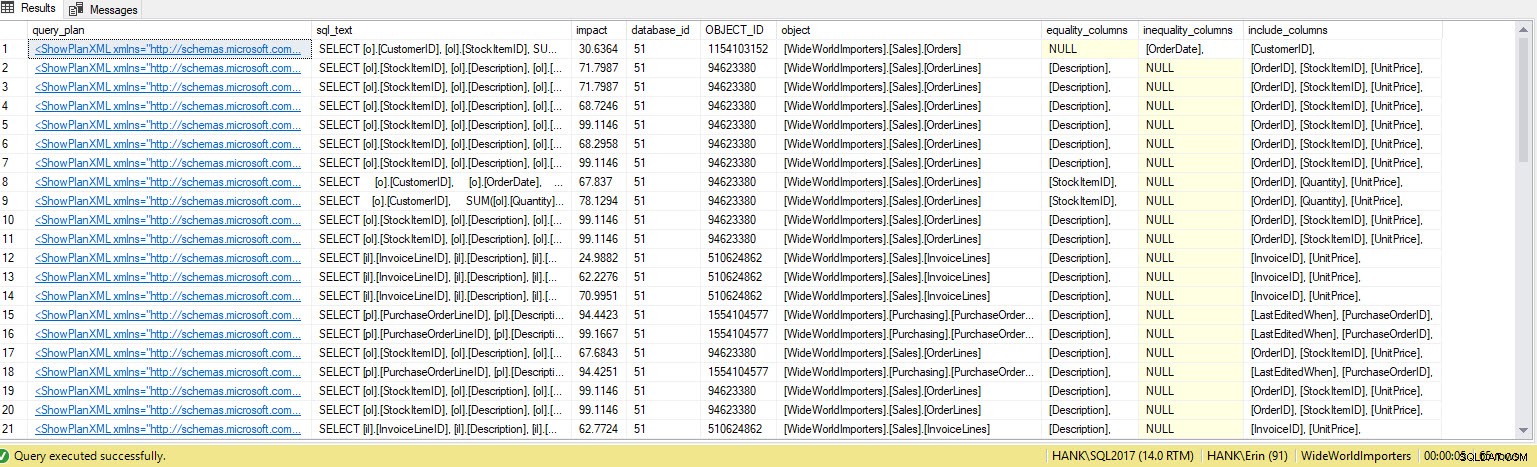
Na wyjściu pojawia się o wiele więcej wierszy. Ponownie, dane magazynu zapytań reprezentują szerszy widok zapytań wykonywanych w systemie, a użycie tych danych daje nam wszechstronną metodę określania nie tylko brakujących indeksów, ale także zapytań, które te indeksy mogłyby obsłużyć. Stąd możemy zagłębić się w skład zapytań i przyjrzeć się metrykom wydajności i częstotliwości wykonywania, aby zrozumieć wpływ tworzenia indeksu i zdecydować, czy zapytanie jest wykonywane wystarczająco często, aby uzasadnić indeks.
Jeśli nie używasz Query Store, ale SentryOne, możesz wydobyć te same informacje z bazy danych SentryOne. Plan zapytania jest przechowywany w tabeli dbo.PerformanceAnalysisPlan w formacie skompresowanym, więc zapytanie, którego używamy, jest podobną odmianą do powyższego, ale zauważysz, że używana jest również funkcja DECOMPRESS:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; W jednym systemie SentryOne miałem następujące dane wyjściowe (i oczywiście kliknięcie dowolnej wartości query_plan spowoduje otwarcie planu graficznego):

Kilka zalet SentryOne w porównaniu z Query Store polega na tym, że nie trzeba włączać tego typu kolekcji na bazę danych, a monitorowana baza danych nie musi spełniać wymagań dotyczących przechowywania, ponieważ wszystkie dane są przechowywane w repozytorium. Możesz również przechwycić te informacje we wszystkich obsługiwanych wersjach programu SQL Server, a nie tylko tych, które obsługują magazyn zapytań. Pamiętaj jednak, że SentryOne zbiera tylko zapytania, które przekraczają progi, takie jak czas trwania i odczyty. Możesz dostosować te domyślne progi, ale podczas eksploracji bazy danych SentryOne należy pamiętać:nie wszystkie zapytania mogą zostać zebrane. Ponadto funkcja DECOMPRESS nie jest dostępna do SQL Server 2016; w przypadku starszych wersji SQL Server możesz:
- Utwórz kopię zapasową bazy danych SentryOne i przywróć ją na SQL Server 2016 lub nowszym, aby uruchomić zapytania;
- bcp dane z tabeli dbo.PerformanceAnalysisPlan i zaimportuj je do nowej tabeli w instancji SQL Server 2016;
- przeszukuj bazę danych SentryOne za pośrednictwem połączonego serwera z instancji SQL Server 2016; lub,
- przeszukuj bazę danych z kodu aplikacji, która może analizować określone rzeczy po dekompresji.
Dzięki SentryOne masz możliwość wydobywania nie tylko pamięci podręcznej planu, ale także danych przechowywanych w repozytorium SentryOne. Jeśli używasz SQL Server 2016 lub nowszego i masz włączoną opcję Query Store, możesz również znaleźć te informacje w sys.query_store_plan . Nie jesteś ograniczony tylko do tego przykładu znajdowania brakujących indeksów; wszystkie zapytania z innych wpisów w pamięci podręcznej planu Jonathana można zmodyfikować tak, aby były używane do wydobywania danych z SentryOne lub z Query Store. Co więcej, jeśli jesteś wystarczająco zaznajomiony z XQuery (lub chcesz się uczyć), możesz użyć schematu Showplan, aby dowiedzieć się, jak przeanalizować plan, aby znaleźć żądane informacje. Daje to możliwość znajdowania wzorców i antywzorców w planach zapytań, które zespół może naprawić, zanim staną się problemem.