Klucze podstawowe i obce są podstawowymi cechami relacyjnych baz danych, jak pierwotnie zauważono w artykule E.F. Codda „A Relational Model of Data for Large Shared Data Banks”, opublikowanym w 1970 roku. Często powtarzany cytat brzmi:„Klucz, cały klucz, i tylko klucz, więc pomóż mi Codd."
Tło:Klucze podstawowe
Klucz podstawowy to ograniczenie w SQL Server, które działa w celu jednoznacznej identyfikacji każdego wiersza w tabeli. Klucz może być zdefiniowany jako pojedyncza kolumna o wartości innej niż NULL lub jako kombinacja kolumn o wartości innej niż NULL, która generuje unikatową wartość i jest używana do wymuszania integralności jednostki dla tabeli. Tabela może mieć tylko jeden klucz podstawowy, a po zdefiniowaniu ograniczenia klucza podstawowego dla tabeli tworzony jest unikalny indeks. Ten indeks będzie domyślnie indeksem klastrowym, chyba że zostanie określony jako indeks nieklastrowy, gdy zdefiniowane jest ograniczenie klucza podstawowego.
Rozważ Sales.SalesOrderHeader tabela w AdventureWorks2012 Baza danych. Ta tabela zawiera podstawowe informacje o zamówieniu sprzedaży, w tym datę zamówienia i identyfikator klienta, a każda sprzedaż jest jednoznacznie identyfikowana przez SalesOrderID , który jest kluczem podstawowym tabeli. Za każdym razem, gdy do tabeli dodawany jest nowy wiersz, ograniczenie klucza podstawowego (o nazwie PK_SalesOrderHeader_SalesOrderID ) jest sprawdzane, aby upewnić się, że nie istnieje już żaden wiersz o tej samej wartości dla SalesOrderID .
Klucze obce
Oddzielone od kluczy podstawowych, ale bardzo powiązane, są klucze obce. Klucz obcy to kolumna lub kombinacja kolumn, która jest taka sama jak klucz podstawowy, ale znajduje się w innej tabeli. Klucze obce służą do definiowania relacji i egzekwowania integralności między dwiema tabelami.
Aby kontynuować korzystanie z powyższego przykładu, SalesOrderID kolumna istnieje jako klucz obcy w Sales.SalesOrderDetail tabeli, w której przechowywane są dodatkowe informacje o sprzedaży, takie jak identyfikator produktu i cena. Gdy nowa sprzedaż zostanie dodana do SalesOrderHeader tabeli, nie jest wymagane dodawanie wiersza dla tej sprzedaży do SalesOrderDetail tabela Jednak podczas dodawania wiersza do SalesOrderDetail tabeli, odpowiedni wiersz dla SalesOrderID musi istnieją w SalesOrderHeader tabela.
I odwrotnie, podczas usuwania danych wiersz dla określonego SalesOrderID można usunąć w dowolnym momencie z SalesOrderDetail tabeli, ale w celu usunięcia wiersza z SalesOrderHeader tabela, powiązane wiersze z SalesOrderDetail należy najpierw usunąć.
W przeciwieństwie do ograniczeń klucza podstawowego, gdy ograniczenie klucza obcego jest zdefiniowane dla tabeli, indeks nie jest tworzony domyślnie przez SQL Server. Jednak często zdarza się, że programiści i administratorzy baz danych dodają je ręcznie. Klucz obcy może być częścią złożonego klucza podstawowego tabeli, w którym to przypadku indeks klastrowy będzie istniał z kluczem obcym jako częścią klucza klastrowego. Alternatywnie zapytania mogą wymagać indeksu zawierającego klucz obcy i co najmniej jednej dodatkowej kolumny w tabeli, więc indeks nieklastrowany zostanie utworzony do obsługi tych zapytań. Co więcej, indeksy kluczy obcych mogą zapewniać korzyści w zakresie wydajności łączenia tabel z kluczem podstawowym i obcym, a także mogą wpływać na wydajność, gdy wartość klucza podstawowego zostanie zaktualizowana lub jeśli wiersz zostanie usunięty.
W AdventureWorks2012 baza danych, jest jedna tabela, SalesOrderDetail , z SalesOrderID jako klucz obcy. Dla SalesOrderDetail tabela, SalesOrderID i SalesOrderDetailID połączyć, tworząc klucz podstawowy, obsługiwany przez indeks klastrowy. Jeśli SalesOrderDetail tabela nie miała indeksu w SalesOrderID kolumna, to gdy wiersz zostanie usunięty z SalesOrderHeader , SQL Server musiałby sprawdzić, czy nie ma wierszy dla tego samego SalesOrderID wartość istnieje. Bez żadnych indeksów zawierających SalesOrderID kolumna, SQL Server musiałby wykonać pełne skanowanie tabeli SalesOrderDetail . Jak możesz sobie wyobrazić, im większa tabela, do której się odnosi, tym dłużej trwa usuwanie.
Przykład
Możemy to zobaczyć w poniższym przykładzie, który wykorzystuje kopie wyżej wymienionych tabel z AdventureWorks2012 bazy danych, które zostały rozbudowane za pomocą skryptu, który można znaleźć tutaj. Skrypt został opracowany przez Jonathana Kehayiasa (blog | @SQLPoolBoy) i tworzy SalesOrderHeaderEnlarged tabela z 1 258 600 wierszami i SalesOrderDetailEnlarged stół z 4 852 680 rzędami. Po uruchomieniu skryptu ograniczenie klucza obcego zostało dodane za pomocą poniższych instrukcji. Zauważ, że ograniczenie jest tworzone za pomocą ON DELETE CASCADE opcja. Dzięki tej opcji, gdy aktualizacja lub usunięcie zostanie wydane względem SalesOrderHeaderEnlarged tabela, wiersze w odpowiednich tabelach – w tym przypadku po prostu SalesOrderDetailEnlarged – są aktualizowane lub usuwane.
Ponadto domyślny indeks klastrowy dla SalesOrderDetailEnglarged został usunięty i odtworzony, aby po prostu mieć SalesOrderDetailID jako klucz podstawowy, ponieważ reprezentuje typowy projekt.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
Z ograniczeniem klucza obcego i brakiem indeksu pomocniczego wydano jedno usunięcie względem SalesOrderHeaderEnlarged tabeli, co spowodowało usunięcie jednego wiersza z SalesOrderHeaderEnlarged i 72 wiersze z SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Statystyki IO i informacje o czasie przedstawiały się następująco:
Czas parsowania i kompilacji SQL Server:Czas procesora =8 ms, upływ czasu =8 ms.
Tabela „Szczegóły zamówienia sprzedaży powiększone”. Liczba skanów 1, odczyty logiczne 50647, odczyty fizyczne 8, odczyty z wyprzedzeniem 50667, odczyty logiczne modułu 0, odczyty fizyczne modułu 0, odczyty z wyprzedzeniem modułu 0.
Tabela „Tabela robocza”. Liczba skanów 2, odczyty logiczne 7, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „SalesOrderHeaderEnlarged”. Liczba skanów 0, odczyty logiczne 15, odczyty fizyczne 14, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty lobu z wyprzedzeniem 0.
Czasy wykonania serwera SQL:
Czas procesora =1045 ms, upływ czasu =1898 ms.
Używając Eksploratora planów SQL Sentry, plan wykonania pokazuje klastrowane skanowanie indeksu względem SalesOrderDetailEnlarged ponieważ nie ma indeksu w SalesOrderID :
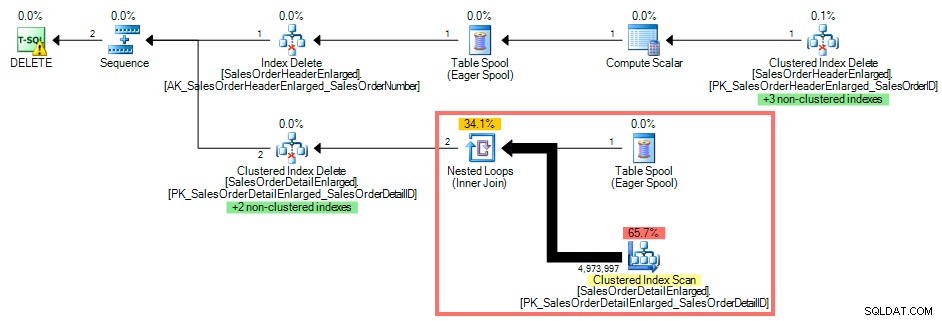
Plan zapytań bez indeksu klucza obcego
Indeks nieklastrowy do obsługi SalesOrderDetailEnlarged został następnie utworzony za pomocą następującego oświadczenia:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Wykonano kolejne usunięcie dla SalesOrderID który wpłynął na jeden wiersz w SalesOrderHeaderEnlarged i 72 wiersze w SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Statystyki IO i informacje o czasie wykazały znaczną poprawę:
Czas parsowania i kompilacji SQL Server:Czas procesora =0 ms, upływ czasu =7 ms.
Tabela „Szczegóły zamówienia sprzedaży powiększone”. Liczba skanów 1, odczyty logiczne 48, odczyty fizyczne 13, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „Tabela robocza”. Liczba skanów 2, odczyty logiczne 7, odczyty fizyczne 0, odczyty z wyprzedzeniem 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty z wyprzedzeniem lobu 0.
Tabela „SalesOrderHeaderEnlarged”. Liczba skanów 0, odczyty logiczne 15, odczyty fizyczne 15, odczyty z wyprzedzeniem 0, odczyty logiczne modułu 0, odczyty fizyczne modułu 0, odczyty modułu z wyprzedzeniem 0.
Czasy wykonania serwera SQL:
Czas procesora =0 ms, upływ czasu =27 ms.
A plan zapytań pokazał wyszukiwanie indeksu indeksu nieklastrowego na SalesOrderID , zgodnie z oczekiwaniami:
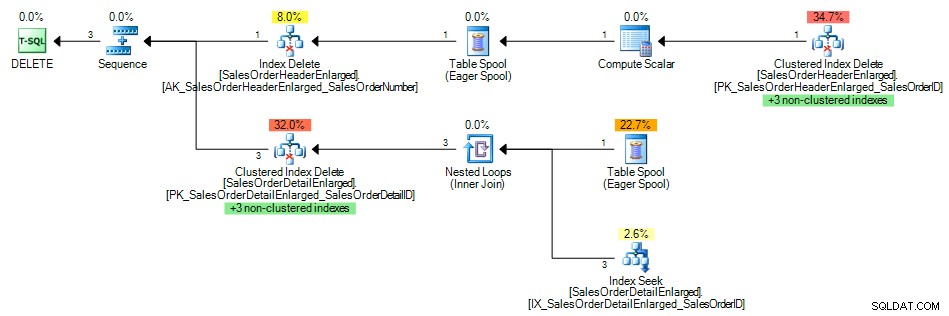
Plan zapytań z indeksem klucza obcego
Czas wykonania zapytania spadł z 1898 ms do 27 ms – redukcja o 98,58% i odczyty dla SalesOrderDetailEnlarged tabela spadła z 50647 do 48 – poprawa o 99,9%. Odkładając na bok procenty, weź pod uwagę same operacje we/wy generowane przez usunięcie. SalesOrderDetailEnlarged w tym przykładzie tabela ma tylko 500 MB, a dla systemu z 256 GB dostępnej pamięci tabela zajmująca 500 MB w buforze nie wydaje się straszną sytuacją. Ale tabela z 5 milionami wierszy jest stosunkowo niewielka; większość dużych systemów OLTP ma tabele z setkami milionów wierszy. Ponadto często zdarza się, że istnieje wiele odwołań do klucza obcego dla klucza podstawowego, gdzie usunięcie klucza podstawowego wymaga usunięcia z wielu powiązanych tabel. W takim przypadku można zobaczyć wydłużony czas trwania usuwania, co jest nie tylko problemem z wydajnością, ale także z blokowaniem, w zależności od poziomu izolacji.
Wniosek
Generalnie zaleca się utworzenie indeksu prowadzącego do kolumny (kolumn) klucza obcego, aby obsługiwać nie tylko połączenia między kluczem podstawowym i obcym, ale także aktualizacje i usunięcia. Należy zauważyć, że jest to ogólne zalecenie, ponieważ istnieją skrajne scenariusze, w których dodatkowy indeks klucza obcego nie został użyty z powodu bardzo małego rozmiaru tabeli, a dodatkowe aktualizacje indeksu faktycznie negatywnie wpłynęły na wydajność. Podobnie jak w przypadku wszelkich modyfikacji schematu, dodawanie indeksów powinno być testowane i monitorowane po wdrożeniu. Ważne jest, aby dodatkowe indeksy dawały pożądane efekty i nie wpływały negatywnie na wydajność rozwiązania. Warto również zauważyć, ile dodatkowej przestrzeni zajmują indeksy dla kluczy obcych. Należy to wziąć pod uwagę przed utworzeniem indeksów, a jeśli przynoszą one korzyści, należy wziąć pod uwagę przy planowaniu wydajności w przyszłości.