Ten artykuł jest czwartym z serii o progach optymalizacji. Seria obejmuje grupowanie i agregowanie danych, wyjaśniając różne algorytmy, z których może korzystać program SQL Server, oraz model wyceny, który pomaga wybrać między algorytmami. W tym artykule skupiam się na rozważaniach dotyczących równoległości. Omówię różne strategie paralelizmu, z których może korzystać SQL Server, progi wyboru między planem szeregowym a równoległym oraz logikę kosztów stosowaną przez SQL Server przy użyciu koncepcji zwanej stopień równoległości dla wyceny (DOP do wyceny).
W moich przykładach będę nadal używać tabeli dbo.Orders w przykładowej bazie danych PerformanceV3. Przed uruchomieniem przykładów z tego artykułu uruchom następujący kod, aby usunąć kilka niepotrzebnych indeksów:
DROP INDEX, JEŚLI ISTNIEJE idx_nc_sid_od_cid NA dbo.Orders; DROP INDEX, JEŚLI ISTNIEJE idx_unc_od_oid_i_cid_eid NA dbo.Orders;
Jedyne dwa indeksy, które powinny pozostać w tej tabeli, to idx_cl_od (z klastrem z orderdate jako kluczem) i PK_Orders (bez klastra z orderid jako kluczem).
Strategie równoległości
Oprócz konieczności wyboru między różnymi strategiami grupowania i agregacji (zamówione w przedsprzedaży Stream Aggregate, Sort + Stream Aggregate, Hash Aggregate), SQL Server musi również wybrać, czy wybrać plan szeregowy, czy równoległy. W rzeczywistości może wybierać między wieloma różnymi strategiami równoległości. SQL Server wykorzystuje logikę kosztów, która skutkuje progami optymalizacji, które w różnych warunkach powodują, że jedna strategia jest preferowana względem innych. W poprzednich częściach serii szczegółowo omówiliśmy już logikę kosztów, której SQL Server używa w planach szeregowych. W tej sekcji przedstawię kilka strategii paralelizmu, które SQL Server może wykorzystać do obsługi grupowania i agregacji. Na początku nie będę zagłębiać się w szczegóły logiki kosztorysowej, a jedynie opiszę dostępne opcje. W dalszej części artykułu wyjaśnię, jak działają formuły wyceny, oraz wyjaśnię ważny czynnik w tych formułach zwany DOP do wyceny.
Jak się później dowiesz, SQL Server uwzględnia liczbę logicznych procesorów w maszynie w swoich formułach kalkulacji kosztów dla planów równoległych. W moich przykładach, o ile nie powiem inaczej, zakładam, że system docelowy ma 8 logicznych procesorów. Jeśli chcesz wypróbować podane przeze mnie przykłady, aby uzyskać takie same plany i wartości kosztów jak ja, musisz uruchomić kod również na maszynie z 8 logicznymi procesorami. Jeśli Twoja maszyna ma inną liczbę procesorów, możesz emulować maszynę z 8 procesorami — do celów związanych z kosztami — na przykład:
DBCC OPTIMIZER_WHATIF (procesory, 8);
Mimo że to narzędzie nie jest oficjalnie udokumentowane i obsługiwane, jest całkiem wygodne do celów badawczych i edukacyjnych.
Tabela Orders w naszej przykładowej bazie danych zawiera 1 000 000 wierszy z identyfikatorami zamówień z zakresu od 1 do 1 000 000. Aby zademonstrować trzy różne strategie równoległości grupowania i agregacji, przefiltruję zamówienia, których identyfikator zamówienia jest większy lub równy 300001 (700 000 dopasowań) i pogrupuję dane na trzy różne sposoby (według custid [2 000 grup przed filtrowaniem], według empid [500 grup] i według dostawcy [5 grup]) i oblicz liczbę zamówień na grupę.
Użyj następującego kodu, aby utworzyć indeksy do obsługi zgrupowanych zapytań:
UTWÓRZ INDEKS idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);CREATE INDEX idx_oid_i_sid ON dbo.Orders(orderid) INCLUDE(shipperid);CREATE INDEX idx_oid_i_cLUDE IN(dboorder);Następujące zapytania implementują wyżej wymienione filtrowanie i grupowanie:
-- Zapytanie 1:Serial SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY custidOPTION(MAXDOP 1); -- Zapytanie 2:Równoległe, a nie lokalne/globalne SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY custid; -- Zapytanie 3:Lokalny równoległy Globalny równoległy SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY empid; -- Zapytanie 4:Lokalny równoległy globalny serial szeregowy SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY shipperid;Zauważ, że Query 1 i Query 2 są takie same (oba są grupowane według custid), tylko pierwsze wymusza plan szeregowy, a drugie otrzymuje plan równoległy na maszynie z 8 procesorami. Używam tych dwóch przykładów do porównania strategii szeregowej i równoległej dla tego samego zapytania.
Rysunek 1 przedstawia szacunkowe plany dla wszystkich czterech zapytań:
Rysunek 1:Strategie równoległości
Na razie nie przejmuj się wartościami kosztów pokazanymi na rysunku i wzmianką o określeniu DOP dla wyceny. Zajmę się nimi później. Najpierw skup się na zrozumieniu strategii i różnic między nimi.
Strategia zastosowana w planie szeregowym dla zapytania 1 powinna być ci znana z poprzednich części serii. Plan filtruje odpowiednie zlecenia za pomocą wyszukiwania w utworzonym wcześniej indeksie pokrycia. Następnie, przy szacowanej liczbie wierszy do zgrupowania i zagregowania, optymalizator preferuje strategię Hash Aggregate od strategii Sort + Stream Aggregate.
Plan dla zapytania 2 wykorzystuje prostą strategię równoległości, która wykorzystuje tylko jeden operator agregacji. Równoległy operator Index Seek dystrybuuje pakiety wierszy do różnych wątków w sposób okrężny. Każdy pakiet wierszy może zawierać wiele różnych identyfikatorów klientów. Aby pojedynczy operator agregujący mógł obliczyć poprawne końcowe liczby grup, wszystkie wiersze należące do tej samej grupy muszą być obsługiwane przez ten sam wątek. Z tego powodu operator wymiany Parallelism (Repartition Streams) jest używany do ponownego podziału strumieni według zbioru grupującego (custid). Wreszcie, operator wymiany równoległości (Gather Streams) służy do zbierania strumieni z wielu wątków w pojedynczy strumień wierszy wyników.
Plany dla Query 3 i Query 4 wykorzystują bardziej złożoną strategię równoległości. Plany zaczynają się podobnie do planu dla zapytania 2, w którym równoległy operator wyszukiwania indeksu dystrybuuje pakiety wierszy do różnych wątków. Następnie praca agregacji jest wykonywana w dwóch krokach:jeden operator agregacji lokalnie grupuje i agreguje wiersze bieżącego wątku (zwróć uwagę na element wynikowy częściowyagg1004), a drugi operator agregacji globalnie grupuje i agreguje wyniki agregacji lokalnych (zwróć uwagę na element globalagg1005 wynik członkowski). Każdy z dwóch kroków agregacji — lokalny i globalny — może wykorzystywać dowolny z algorytmów agregacji, które opisałem wcześniej w tej serii. Oba plany dla zapytania 3 i zapytania 4 rozpoczynają się od lokalnego zagregowania skrótu i kontynuują z globalnym zagregowaniem sortowania + strumienia. Różnica między nimi polega na tym, że pierwsza z nich wykorzystuje równoległość w obu krokach (stąd wymiana strumieni Repartycji jest używana między nimi a wymianą Gather Streams po agregacie globalnym), a druga obsługuje agregację lokalną w strefie równoległej i globalną agregować w strefie szeregowej (stąd między nimi używana jest wymiana Gather Streams).
Prowadząc badania dotyczące ogólnej optymalizacji zapytań, a konkretnie równoległości, dobrze jest zapoznać się z narzędziami, które umożliwiają kontrolowanie różnych aspektów optymalizacji, aby zobaczyć ich efekty. Wiesz już, jak wymusić plan szeregowy (ze wskazówką MAXDOP 1) i jak emulować środowisko, które ze względów kosztowych ma określoną liczbę logicznych procesorów (DBCC OPTIMIZER_WHATIF, z opcją procesorów). Innym przydatnym narzędziem jest wskazówka zapytania ENABLE_PARALLEL_PLAN_PREFERENCE (wprowadzona w SQL Server 2016 SP1 CU2), która maksymalizuje równoległość. Mam na myśli to, że jeśli dla zapytania jest obsługiwany plan równoległy, paralelizm będzie preferowany we wszystkich częściach planu, które mogą być obsługiwane równolegle, tak jakby był bezpłatny. Na przykład na rysunku 1 można zauważyć, że domyślnie plan dla zapytania 4 obsługuje agregację lokalną w strefie szeregowej i agregację globalną w strefie równoległej. Oto to samo zapytanie, tylko tym razem z zastosowaną wskazówką dotyczącą zapytania ENABLE_PARALLEL_PLAN_PREFERENCE (nazwiemy je Zapytanie 5):
SELECT identyfikator wysyłki, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=300001GROUP BY shipperidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Plan dla zapytania 5 pokazano na rysunku 2:
Rysunek 2:Maksymalizacja równoległości
Zauważ, że tym razem zarówno lokalne, jak i globalne agregaty są obsługiwane w równoległych strefach.
Wybór planu szeregowego/równoległego
Przypomnijmy, że podczas optymalizacji zapytań SQL Server tworzy wiele planów kandydujących i wybiera ten o najniższym koszcie spośród wygenerowanych. Termin koszt jest trochę myląca, ponieważ według szacunków plan kandydata o najniższym koszcie ma być planem o najkrótszym czasie działania, a nie tym, w którym wykorzystano najmniej zasobów. Na przykład, między planem kandydującym szeregowym a planem równoległym utworzonym dla tego samego zapytania, plan równoległy prawdopodobnie zużyje więcej zasobów, ponieważ musi używać operatorów wymiany, które synchronizują wątki (dystrybucja, podział i gromadzenie strumieni). Jednak aby plan równoległy wymagał mniej czasu na ukończenie działania niż plan szeregowy, oszczędności uzyskane dzięki pracy z wieloma wątkami muszą przewyższać dodatkową pracę wykonaną przez operatorów giełdy. Musi to być odzwierciedlone w formułach kosztów używanych przez SQL Server, gdy w grę wchodzi równoległość. Nie jest to proste zadanie do dokładnego wykonania!
Oprócz tego, że koszt planu równoległego musi być niższy niż koszt planu szeregowego, aby był preferowany, koszt alternatywnego planu szeregowego musi być większy lub równy prógowi kosztów dla równoległości . Jest to opcja konfiguracji serwera ustawiona domyślnie na 5, która zapobiega obsłudze zapytań o dość niskim koszcie z równoległością. Chodzi o to, że system z dużą liczbą małych zapytań ogólnie skorzystałby bardziej na korzystaniu z planów szeregowych, zamiast marnować dużo zasobów na synchronizację wątków. Nadal możesz mieć wiele zapytań z planami szeregowymi wykonywanymi w tym samym czasie, efektywnie wykorzystując wieloprocesorowe zasoby maszyny. W rzeczywistości wielu specjalistów SQL Server lubi zwiększać próg kosztów dla równoległości z domyślnej wartości 5 do wyższej wartości. System uruchamiający jednocześnie dość małą liczbę dużych zapytań zyskałby znacznie więcej na korzystaniu z planów równoległych.
Podsumowując, aby program SQL Server preferował plan równoległy względem alternatywy szeregowej, koszt planu szeregowego musi być co najmniej progiem kosztu równoległości, a koszt planu równoległego musi być niższy niż koszt planu szeregowego (co oznacza, że potencjalnie krótszy czas pracy).
Zanim przejdę do szczegółów rzeczywistych formuł kosztów, zilustruję przykładami różne scenariusze, w których dokonuje się wyboru między planem szeregowym a równoległym. Upewnij się, że twój system zakłada 8 logicznych procesorów, aby uzyskać koszty zapytań podobne do moich, jeśli chcesz wypróbować przykłady.
Rozważ następujące zapytania (nazwiemy je Zapytanie 6 i Zapytanie 7):
-- Zapytanie 6:Serial SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=400001GROUP BY empid; -- Zapytanie 7:Wymuszony równoległy SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=400001GROUP BY empidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Plany dla tych zapytań pokazano na rysunku 3.
Rysunek 3:Koszt seryjny
W tym przypadku [wymuszony] koszt planu równoległego jest niższy niż koszt planu szeregowego; jednak koszt planu szeregowego jest niższy niż domyślny próg kosztów dla równoległości równy 5, dlatego SQL Server domyślnie wybrał plan szeregowy.
Rozważ następujące zapytania (nazwiemy je Zapytanie 8 i Zapytanie 9):
-- Zapytanie 8:Równoległy SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY empid; -- Zapytanie 9:Wymuszony szeregowy SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY empidOPTION(MAXDOP 1);Plany dla tych zapytań pokazano na rysunku 4.
Rysunek 4:Koszt seryjny>=próg kosztowy dla równoległości, koszt równoległy
W tym przypadku [wymuszony] koszt planu szeregowego jest większy lub równy progowi kosztów dla równoległości, a koszt planu równoległego jest niższy niż koszt planu szeregowego, dlatego SQL Server domyślnie wybrał plan równoległy.
Rozważ następujące zapytania (nazwiemy je Zapytanie 10 i Zapytanie 11):
-- Zapytanie 10:Serial SELECT *FROM dbo.OrdersWHERE id zamówienia>=100000; -- Zapytanie 11:Wymuszone równoległe SELECT *FROM dbo.OrdersWHERE id zamówienia>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Plany dla tych zapytań są pokazane na rysunku 5.
Rysunek 5:Koszt seryjny>=próg kosztowy dla równoległości, koszt równoległy>=koszt seryjny
W tym przypadku koszt planu szeregowego jest większy lub równy progowi kosztów równoległości; jednak koszt planu szeregowego jest niższy niż [wymuszony] koszt planu równoległego, dlatego SQL Server domyślnie wybrał plan szeregowy.
Jest jeszcze jedna rzecz, którą musisz wiedzieć o próbie maksymalizacji równoległości za pomocą wskazówki ENABLE_PARALLEL_PLAN_PREFERENCE. Aby SQL Server mógł nawet korzystać z planu równoległego, musi istnieć jakiś element umożliwiający równoległość, taki jak predykat rezydualny, sortowanie, agregacja i tak dalej. Plan, który stosuje tylko skanowanie indeksu lub wyszukiwanie indeksu bez predykatu rezydualnego i bez żadnego innego aktywatora równoległości, będzie przetwarzany z planem szeregowym. Rozważ następujące zapytania jako przykład (nazwiemy je Zapytanie 12 i Zapytanie 13):
-- Zapytanie 12 SELECT *FROM dbo.OrdersOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); -- Zapytanie 13 SELECT *FROM dbo.OrdersWHERE id zamówienia>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Plany dla tych zapytań pokazano na rysunku 6.
Rysunek 6:Włącznik równoległości
Zapytanie 12 otrzymuje plan szeregowy pomimo podpowiedzi, ponieważ nie ma aktywatora równoległości. Zapytanie 13 otrzymuje plan równoległy, ponieważ w grę wchodzi predykat rezydualny.
Obliczanie i testowanie DOP pod kątem kosztów
Firma Microsoft musiała skalibrować formuły wyceny, próbując uzyskać niższy koszt planu równoległego niż koszt planu szeregowego, co odzwierciedla krótszy czas wykonywania i na odwrót. Jednym z potencjalnych pomysłów było podzielenie kosztu procesora operatora szeregowego przez liczbę logicznych procesorów w maszynie, aby uzyskać koszt procesora operatora równoległego. Logiczna liczba procesorów w maszynie jest głównym czynnikiem określającym stopień równoległości zapytania, czyli w skrócie DOP (liczba wątków, które mogą być używane w strefie równoległej w planie). Uproszczone myślenie jest takie, że jeśli operator potrzebuje T jednostek czasu do ukończenia podczas korzystania z jednego wątku, a stopień równoległości zapytania wynosi D, zajęłoby operatorowi czas T/D podczas korzystania z wątków D. W praktyce sprawy nie są takie proste. Na przykład zwykle masz wiele zapytań uruchomionych jednocześnie, a nie tylko jedno, w którym to przypadku pojedyncze zapytanie nie uzyska wszystkich zasobów procesora komputera. Tak więc Microsoft wpadł na pomysł stopień równoległości w kosztorysowaniu (w skrócie DOP dla wyceny). Ta miara jest zwykle mniejsza niż liczba logicznych procesorów w maszynie i jest czynnikiem, przez który koszt procesora operatora szeregowego jest dzielony przez, aby obliczyć koszt procesora operatora równoległego.
Zwykle DOP do kalkulacji kosztów jest obliczany jako liczba logicznych procesorów podzielona przez 2 przy użyciu dzielenia liczb całkowitych. Są jednak wyjątki. Gdy liczba procesorów wynosi 2 lub 3, DOP do obliczania kosztów jest ustawiany na 2. Przy 4 lub więcej procesorach DOP do obliczania kosztów jest ustawiany na #CPUs / 2, ponownie przy użyciu dzielenia liczb całkowitych. To do pewnego maksimum, które zależy od ilości pamięci dostępnej dla maszyny. W maszynie z maksymalnie 4096 MB pamięci maksymalny DOP dla kalkulacji kosztów wynosi 8; przy ponad 4096 MB, maksymalny DOP do wyceny wynosi 32.
Aby przetestować tę logikę, wiesz już, jak emulować żądaną liczbę logicznych procesorów za pomocą DBCC OPTIMIZER_WHATIF, z opcją procesorów, na przykład:
DBCC OPTIMIZER_WHATIF (procesory, 8);Używając tego samego polecenia z opcją MemoryMBs, możesz emulować żądaną ilość pamięci w MB, na przykład:
DBCC OPTIMIZER_WHATIF (MemoryMBs, 16384);Użyj następującego kodu, aby sprawdzić istniejący stan emulowanych opcji:
DBCC TRACEON(3604); DBCC OPTIMIZER_WHATIF (stan); DBCC TRACEOFF(3604);Użyj następującego kodu, aby zresetować wszystkie opcje:
DBCC OPTIMIZER_WHATIF (ResetAll);Oto zapytanie T-SQL, którego możesz użyć do obliczenia DOP do kosztorysowania na podstawie wejściowej liczby procesorów logicznych i ilości pamięci:
DECLARE @NumCPUs AS INT =8, @MemoryMBs AS INT =16384; SELECT CASE WHEN @NumCPUs =1 THEN 1 WHEN @NumCPUs <=3 THEN 2 WHEN @NumCPUs>=4 THEN (SELECT MIN(n) FROM ( VALUES(@NumCPUs / 2), (MaxDOP4C ) ) AS D2(n)) END AS DOP4CFROM ( VALUES ( PRZYPADEK GDY @MemoryMBs <=4096 THEN 8 ELSE 32 END ) ) AS D1(MaxDOP4C);Z określonymi wartościami wejściowymi to zapytanie zwraca 4.
Tabela 1 zawiera szczegóły DOP dotyczące kosztów, które otrzymujesz na podstawie logicznej liczby procesorów i ilości pamięci w twoim komputerze.
| #CPU | DOP dla kosztów, gdy MB pamięci <=4096 | DOP dla kosztów, gdy MB pamięci> 4096 |
|---|---|---|
| 1 | 1 | 1 |
| 2-5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8-9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14-15 | 7 | 7 |
| 16-17 | 8 | 8 |
| 18-19 | 8 | 9 |
| 20-21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24-25 | 8 | 12 |
| 26-27 | 8 | 13 |
| 28-29 | 8 | 14 |
| 30-31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36-37 | 8 | 18 |
| 38-39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46-47 | 8 | 23 |
| 48-49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58-59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| >=64 | 8 | 32 |
Tabela 1:DOP do wyceny
Jako przykład wróćmy do Zapytania 1 i Zapytania 2 pokazanych wcześniej:
-- Zapytanie 1:Wymuszone seryjne SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY custidOPTION(MAXDOP 1); -- Zapytanie 2:Naturalnie równolegle SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY custid;
Plany dla tych zapytań pokazano na rysunku 7.
 Rysunek 7:DOP dla kosztowanie
Rysunek 7:DOP dla kosztowanie
Zapytanie 1 wymusza plan szeregowy, podczas gdy Zapytanie 2 otrzymuje plan równoległy w moim środowisku (emulując 8 logicznych procesorów i 16 384 MB pamięci). Oznacza to, że DOP do kalkulacji kosztów w moim środowisku wynosi 4. Jak wspomniano, koszt procesora operatora równoległego jest obliczany jako koszt procesora operatora szeregowego podzielony przez DOP do kalkulacji kosztów. Widać, że tak właśnie jest w naszym planie równoległym z operatorami Index Seek i Hash Aggregate, które działają równolegle.
Jeśli chodzi o koszty operatorów giełd, składają się one z kosztu uruchomienia i pewnego stałego kosztu na wiersz, który można łatwo odtworzyć.
Zauważ, że w prostej strategii grupowania i agregacji równoległej, której użyto tutaj, oszacowania liczności w planach szeregowym i równoległym są takie same. Dzieje się tak, ponieważ zatrudniony jest tylko jeden operator kruszywa. Później zobaczysz, że sytuacja wygląda inaczej, gdy używasz strategii lokalnej/globalnej.
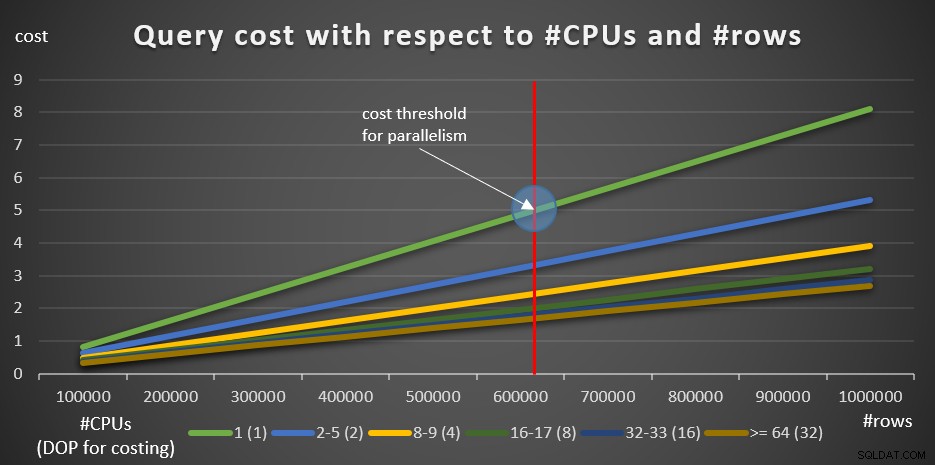
Poniższe zapytania pomagają zilustrować wpływ liczby logicznych procesorów i liczby zaangażowanych wierszy na koszt zapytania (10 zapytań, z przyrostami o 100 tys. wierszy):
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=900001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=800001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=700001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=600001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=500001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=400001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=300001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=200001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=100001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=000001GROUP BY empid;
Rysunek 8 przedstawia wyniki.
Rysunek 8:Koszt zapytania w odniesieniu do #CPU i #rows
Zielona linia przedstawia koszty różnych zapytań (z różną liczbą wierszy) przy użyciu planu szeregowego. Pozostałe wiersze przedstawiają koszty planów równoległych z różną liczbą procesorów logicznych oraz odpowiadający im DOP do wyceny. Czerwona linia reprezentuje punkt, w którym koszt zapytania szeregowego wynosi 5 — domyślny próg kosztu dla ustawienia równoległości. Na lewo od tego punktu (mniej wierszy do grupowania i agregowania) zwykle optymalizator nie bierze pod uwagę planu równoległego. Aby móc badać koszty planów równoległych poniżej progu kosztów równoległości, możesz zrobić jedną z dwóch rzeczy. Jedną z opcji jest użycie wskazówki dotyczącej zapytania ENABLE_PARALLEL_PLAN_PREFERENCE, ale jako przypomnienie, ta opcja maksymalizuje równoległość, a nie tylko ją wymusza. Jeśli nie jest to pożądany efekt, możesz po prostu wyłączyć próg kosztów dla równoległości, na przykład:
EXEC sp_configure 'pokaż opcje zaawansowane', 1; PONOWNA KONFIGURACJA; EXEC sp_configure 'próg kosztów dla równoległości', 0; EXEC sp_configure 'pokaż opcje zaawansowane', 0; PONOWNIE KONFIGURUJ;
Oczywiście nie jest to sprytne posunięcie w systemie produkcyjnym, ale doskonale przydatne do celów badawczych. Właśnie to zrobiłem, aby uzyskać informacje do wykresu na rysunku 8.
Zaczynając od 100 tys. wierszy i dodając 100 tys. przyrostów, wszystkie wykresy wydają się sugerować, że próg kosztowy dla równoległości nie był czynnikiem, plan równoległy zawsze byłby preferowany. Tak właśnie jest w przypadku naszych zapytań i liczby zaangażowanych wierszy. Wypróbuj jednak mniejszą liczbę wierszy, zaczynając od 10 KB i zwiększając ją o 10 KB, korzystając z następujących pięciu zapytań (ponownie, na razie wyłącz próg kosztów dla równoległości):
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=990001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=980001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=970001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE identyfikator zamówienia>=960001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=950001GROUP BY empid;
Rysunek 9 pokazuje koszty zapytań zarówno w planach szeregowych, jak i równoległych (emulacja 4 procesorów, DOP dla kosztorysowania 2).
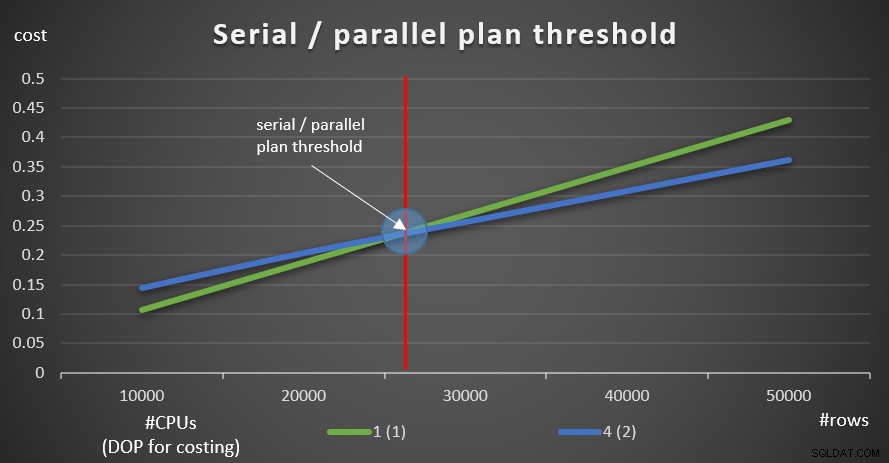 Rysunek 9:Serial / próg planu równoległego
Rysunek 9:Serial / próg planu równoległego
Jak widać, istnieje próg optymalizacji, do którego preferowany jest plan szeregowy, a powyżej którego preferowany jest plan równoległy. Jak wspomniano, w normalnym systemie, w którym próg kosztów dla równoległości jest ustawiony na wartość domyślną 5 lub wyższą, próg efektywny jest i tak wyższy niż na tym wykresie.
Wcześniej wspomniałem, że gdy SQL Server wybierze prostą strategię równoległości grupowania i agregacji, oszacowania kardynalności planów szeregowego i równoległego są takie same. Pytanie brzmi, w jaki sposób SQL Server obsługuje oszacowania kardynalności dla lokalnej/globalnej strategii równoległości.
Aby to zrozumieć, użyję Zapytania 3 i Zapytania 4 z naszych wcześniejszych przykładów:
-- Zapytanie 3:Lokalny równoległy globalny równoległy SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY empid; -- Zapytanie 4:Lokalny równoległy globalny serial szeregowy SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE id zamówienia>=300001GROUP BY shipperid;
W systemie z 8 logicznymi procesorami i efektywnym DOP dla wartości kosztowej 4, otrzymałem plany pokazane na rysunku 10.
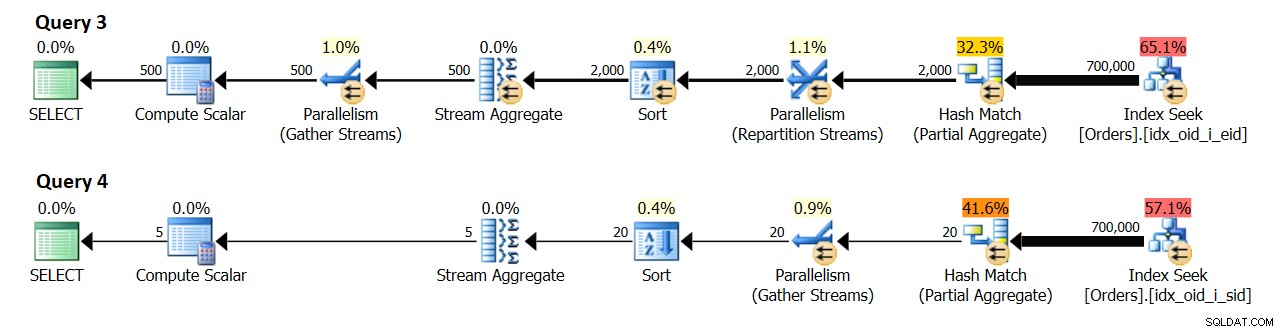 Rysunek 10:Oszacowanie liczebności
Rysunek 10:Oszacowanie liczebności
Zapytanie 3 grupuje zamówienia według empid. Oczekuje się ostatecznie 500 różnych grup pracowników.
Zapytanie 4 grupuje zamówienia według dostawcy. Oczekuje się ostatecznie 5 różnych grup nadawców.
Co ciekawe, wydaje się, że oszacowanie kardynalności dla liczby grup utworzonych przez agregację lokalną wynosi {liczba odrębnych grup oczekiwanych przez każdy wątek} * {DOP dla kosztorysowania}. W praktyce zdajesz sobie sprawę, że liczba ta będzie zwykle dwa razy większa, ponieważ liczy się DOP do wykonania (czyli po prostu DOP), który opiera się głównie na liczbie procesorów logicznych. Ta część jest nieco trudna do emulowania w celach badawczych, ponieważ polecenie DBCC OPTIMIZER_WHATIF z opcją CPUs wpływa na obliczanie DOP do wyceny, ale DOP do wykonania nie będzie większy niż rzeczywista liczba procesorów logicznych, które widzi Twoja instancja SQL Server. Ta liczba jest zasadniczo oparta na liczbie programów planujących, od których zaczyna się program SQL Server. możesz kontrolować liczbę programów planujących, które SQL Server zaczyna od użycia parametru startowego -P{ #schedulers }, ale jest to nieco bardziej agresywne narzędzie badawcze w porównaniu z opcją sesji.
W każdym razie, bez emulowania żadnych zasobów, moja maszyna testowa ma 4 logiczne procesory, w wyniku czego DOP oznacza koszt 2, a DOP — wykonanie 4. W moim środowisku agregacja lokalna w planie dla zapytania 3 pokazuje oszacowanie 1000 grup wyników (500 x 2), a rzeczywista 2000 (500 x 4). Podobnie agregacja lokalna w planie dla Zapytania 4 pokazuje oszacowanie 10 grup wyników (5 x 2) i 20 (5 x 4).
Po zakończeniu eksperymentów uruchom następujący kod w celu oczyszczenia:
-- Ustaw próg kosztu równoległości na domyślny EXEC sp_configure 'pokaż opcje zaawansowane', 1; PONOWNA KONFIGURACJA; EXEC sp_configure 'próg kosztów dla równoległości', 5; EXEC sp_configure 'pokaż opcje zaawansowane', 0; RECONFIGURE; GO -- Zresetuj opcje OPTIMIZER_WHATIF DBCC OPTIMIZER_WHATIF (ResetAll); -- Upuść indeksy DROP INDEX idx_oid_i_sid NA dbo.Orders;DROP INDEX idx_oid_i_eid NA dbo.Orders;DROP INDEX idx_oid_i_cid NA dbo.Orders;
Wniosek
W tym artykule opisałem kilka strategii paralelizmu, które SQL Server wykorzystuje do obsługi grupowania i agregacji. Ważną koncepcją do zrozumienia w optymalizacji zapytań z planami równoległymi jest stopień równoległości (DOP) dla kosztów. Pokazałem kilka progów optymalizacji, w tym próg między planami szeregowymi i równoległymi oraz ustawienie progu kosztowego dla równoległości. Większość pojęć, które tu opisałem, nie jest unikalna dla grupowania i agregacji, a raczej ma zastosowanie do rozważań dotyczących planów równoległych w SQL Server w ogóle. W przyszłym miesiącu będę kontynuować serię, omawiając optymalizację z przepisywaniem zapytań.