Ten artykuł jest drugim z serii o progach optymalizacji związanych z grupowaniem i agregowaniem danych. W części 1 przedstawiłem formułę inżynierii wstecznej dla kosztu operatora Stream Aggregate. Wyjaśniłem, że ten operator musi zużywać wiersze uporządkowane przez zbiór grupujący (dowolną kolejność jego elementów), a gdy dane są uzyskiwane w przedsprzedaży z indeksu, otrzymujesz skalowanie liniowe w odniesieniu do liczby wierszy i liczby grupy. Ponadto w takim przypadku nie jest potrzebne przyznanie pamięci.
W tym artykule skupię się na kosztorysowaniu i skalowaniu operacji opartej na agregacji strumienia, gdy dane nie są pozyskiwane w przedsprzedaży z indeksu, a raczej muszą być najpierw posortowane.
W moich przykładach użyję przykładowej bazy danych PerformanceV3, jak w części 1. Możesz pobrać skrypt, który tworzy i wypełnia tę bazę danych stąd. Zanim uruchomisz przykłady z tego artykułu, upewnij się, że najpierw uruchomisz następujący kod, aby usunąć kilka niepotrzebnych indeksów:
DROP INDEX idx_nc_sid_od_cid NA dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid NA dbo.Orders;
Jedyne dwa indeksy, które powinny pozostać w tej tabeli to idx_cl_od (zgrupowane z orderdate jako klucz) i PK_Orders (bez klastrów z orderid jako klucz).
Sortuj + agregacja strumienia
Celem tego artykułu jest próba ustalenia, w jaki sposób operacja agregacji strumienia skaluje się, gdy dane nie są ułożone w kolejności wstępnej przez zestaw grupowania. Ponieważ operator Stream Aggregate musi przetwarzać uporządkowane wiersze, jeśli nie są one uporządkowane w indeksie, plan musi zawierać jawny operator sortowania. Zatem koszt operacji zbiorczej, który należy wziąć pod uwagę, jest sumą kosztów operatorów Sort + Stream Aggregate.
Użyję następującego zapytania (nazwiemy je Zapytanie 1), aby zademonstrować plan obejmujący taką optymalizację:
SELECT shipperid, MAX(data zamówienia) AS maxod FROM (SELECT TOP (100) * FROM dbo.Orders) AS D GROUP BY shipperid;
Plan dla tego zapytania pokazano na rysunku 1.

Rysunek 1:Plan dla zapytania 1
Powodem, dla którego używam wyrażenia tabelowego z filtrem TOP, jest kontrolowanie dokładnej liczby (szacowanych) wierszy zaangażowanych w grupowanie i agregację. Stosowanie kontrolowanych zmian ułatwia próbę odtworzenia formuł kosztów.
Jeśli zastanawiasz się, po co filtrować tak małą liczbę wierszy w tym przykładzie, ma to związek z progami optymalizacji, które sprawiają, że ta strategia jest preferowana w stosunku do algorytmu Hash Aggregate. W części 3 opiszę kosztorysowanie i skalowanie alternatywy skrótu. W przypadkach, w których optymalizator nie wybiera samodzielnie operacji agregowania strumienia, np. gdy w grę wchodzi duża liczba wierszy, zawsze można to wymusić podając w trakcie procesu wyszukiwania podpowiedź OPTION(ORDER GROUP). Koncentrując się na wycenie planów szeregowych, możesz oczywiście dodać wskazówkę dotyczącą MAXDOP 1, aby wyeliminować równoległość.
Jak wspomniano, aby oszacować koszt i skalowanie algorytmu agregacji strumienia nieuporządkowanego w przedsprzedaży, należy wziąć pod uwagę sumę operatorów Sort + Stream Aggregate. Znasz już formułę kosztów dla operatora Stream Aggregate z Części 1:
@numrows * 0,0000006 + @numgroups * 0,0000005W naszym zapytaniu mamy 100 szacowanych wierszy wejściowych i 5 szacowanych grup wyjściowych (5 odrębnych identyfikatorów nadawcy oszacowanych na podstawie informacji o gęstości). Tak więc koszt operatora Stream Aggregate w naszym planie wynosi:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625Spróbujmy znaleźć formułę wyceny dla operatora sortowania. Pamiętaj, że skupiamy się na szacowanym koszcie i skalowaniu, ponieważ naszym ostatecznym celem jest określenie progów optymalizacji, przy których optymalizator zmienia swoje wybory z jednej strategii na inną.
Szacunkowy koszt we/wy wydaje się być stały:0,0112613. Otrzymuję ten sam koszt we/wy niezależnie od czynników, takich jak liczba wierszy, liczba kolumn sortowania, typ danych i tak dalej. Jest to prawdopodobnie spowodowane pewnymi przewidywanymi pracami we/wy.
Jeśli chodzi o koszt procesora, niestety Microsoft nie ujawnia publicznie dokładnych algorytmów, których używają do sortowania. Jednak wśród typowych algorytmów używanych do sortowania przez aparaty baz danych ogólnie są różne implementacje sortowania przez scalanie i sortowania szybkiego. Dzięki wysiłkom Paula White'a, który lubi patrzeć na ślady stosu debuggerów Windows (nie każdy z nas ma na to ochotę), mamy nieco większy wgląd w temat, opublikowany w jego serii „Internals of the Seven SQL Server Sortuje”. Zgodnie z ustaleniami Paula ogólna klasa sortowania (używana w powyższym planie) wykorzystuje sortowanie przez scalanie (najpierw wewnętrzne, a następnie przechodzące na zewnętrzne). Średnio ten algorytm wymaga n log n porównań, aby posortować n elementów. Mając to na uwadze, prawdopodobnie bezpiecznym punktem wyjścia jest założenie, że część kosztu operatora związana z procesorem opiera się na wzorze takim jak:
Koszt procesora operatora =Oczywiście może to być nadmierne uproszczenie rzeczywistej formuły kosztowej, której używa Microsoft, ale przy braku jakiejkolwiek dokumentacji w tej sprawie jest to wstępne najlepsze przypuszczenie.
Następnie można uzyskać sortowanie kosztów procesora z dwóch planów zapytań utworzonych w celu sortowania różnej liczby wierszy, powiedzmy 1000 i 2000, i na podstawie tych oraz powyższej formuły, dokonać inżynierii wstecznej kosztów porównania i kosztu uruchomienia. W tym celu nie musisz używać zapytania grupowego; wystarczy wykonać podstawowe ORDER BY. Użyję następujących dwóch zapytań (nazwiemy je Query 2 i Query 3):
SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Celem uporządkowania według wyniku obliczeń jest wymuszenie użycia operatora sortowania w planie.
Rysunek 2 przedstawia odpowiednie części dwóch planów:
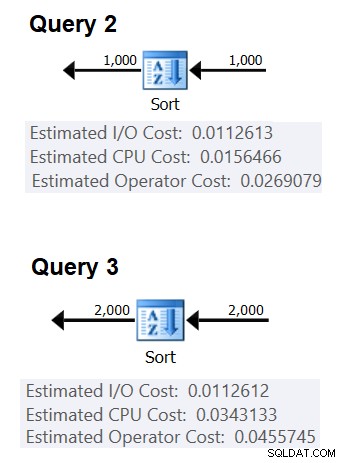
Rysunek 2:Plany dla zapytania 2 i zapytania 3
Aby spróbować wywnioskować koszt jednego porównania, użyj następującego wzoru:
koszt porównania =
((
/ (
(0,0343133 – 0,0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2,25061348918698E-06
Jeśli chodzi o koszt uruchomienia, możesz wywnioskować go na podstawie dowolnego planu, np. na podstawie planu sortującego 2000 wierszy:
koszt uruchomienia =0,0343133 – 2000*LOG(2000) * 2,25061348918698E-06 =9.99127891201865E-05
W ten sposób nasza formuła sortowania kosztu procesora staje się:
Koszt procesora operatora sortowania =9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06Korzystając z podobnych technik, przekonasz się, że takie czynniki jak średni rozmiar wiersza, liczba kolumn porządkowania i ich typy danych nie wpływają na szacowany koszt procesora sortowania. Jedynym czynnikiem, który wydaje się mieć znaczenie, jest szacunkowa liczba wierszy. Zauważ, że sortowanie będzie wymagało przyznania pamięci, a przyznanie jest proporcjonalne do liczby wierszy (nie grup) i średniego rozmiaru wiersza. Ale obecnie skupiamy się na szacowanym koszcie operatora i wydaje się, że na ten szacunek wpływa tylko szacowana liczba wierszy.
Ta formuła wydaje się przewidywać koszt procesora do progu około 5000 wierszy. Spróbuj z następującymi liczbami:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
SELECT numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS koszt predykowany FROM (VALUES(100), (200), (300), (400), (500), (1000) , (2000), (3000), (4000), (5000)) AS D(numrows);
Porównaj przewidywania formuły i szacunkowe koszty procesora, które pokazują plany dla następujących zapytań:
SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (300) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Otrzymałem następujące wyniki:
numrows współczynnik przewidywanego kosztu szacowanego kosztu ----------- --------------- -------------- --- ---- 100 0,0011363 0,0011365 1,00018 200 0,0024848 0,0024849 1.00004 300 0.0039510 0,0039511 1.00003 400 0,0054937 0,0054938 1.00002 500 0,0070933 0,0070933 1,00000 1000 0,0156466 0,0156466 1,00000 2000 0,0343133 0,0343133 1,00000 3000 0,0541576 0,0541576 0,010094 1,0945Kolumna przewidywany koszt pokazuje predykację opartą na naszej formule poddanej inżynierii wstecznej, kolumna szacowany koszt pokazuje szacowany koszt, który pojawia się w planie, a współczynnik kolumny pokazuje stosunek między tym drugim a pierwszym.
Predykcja wydaje się dość dokładna do 5000 wierszy. Jednak przy liczbach większych niż 5000 nasza formuła inżynierii wstecznej przestaje działać dobrze. Poniższe zapytanie podaje predykacje dla 6K, 7K, 10K, 20K, 100K i 200K wierszy:
SELECT numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS koszt predykowany FROM (VALUES (6000), (7000), (10000), (20000), (100000), (200000) ) AS D(liczby);Użyj następujących zapytań, aby uzyskać szacunkowe koszty procesora z planów (zwróć uwagę na wskazówkę, aby wymusić plan szeregowy, ponieważ przy większej liczbie wierszy jest bardziej prawdopodobne, że otrzymasz plan równoległy, w którym formuły wyceny są dostosowane do równoległości):
SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT id_zamówienia % 1000000000 as myorderid FROM (SELECT TOP (7000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT idzamówienia % 1000000000 as myorderid FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT idzamówienia % 1000000000 as myorderid FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT idzamówienia % 1000000000 as myorderid FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1);Otrzymałem następujące wyniki:
numrows współczynnik przewidywanego kosztu szacowanego kosztu ----------- --------------- -------------- --- --- 6000 0,117575 0,160970 1,3691 7000 0,139583 0,244848 1,7541 10000 0,207389 0,603420 2,9096 20000 0,445878 1,311710 2,9419 100000 2,591210 7,623920 2,9422 200000 5,494330 16.165700 2,9423Jak widać, poza 5000 wierszy nasza formuła staje się coraz mniej dokładna, ale co ciekawe, współczynnik dokładności stabilizuje się na około 2,94 przy około 20 000 wierszach. Oznacza to, że przy dużych liczbach nasza formuła nadal obowiązuje, tylko przy wyższym koszcie porównania, i że mniej więcej między 5 000 a 20 000 wierszy przechodzi stopniowo od niższego kosztu porównania do wyższego. Ale co może wyjaśnić różnicę między małą a dużą skalą? Dobra wiadomość jest taka, że odpowiedź nie jest tak złożona, jak pogodzenie mechaniki kwantowej i ogólnej teorii względności z teorią strun. Po prostu na mniejszą skalę Microsoft chciał uwzględnić fakt, że pamięć podręczna procesora może być używana, i do celów kosztowych zakłada stały rozmiar pamięci podręcznej.
Aby więc obliczyć koszt porównania na dużą skalę, użyj sortowania kosztów procesora z dwóch planów dla liczb powyżej 20 000. Użyję 100 000 i 200 000 wierszy (ostatnie dwa wiersze w powyższej tabeli). Oto wzór do wywnioskowania kosztu porównania:
koszt porównania =
(16.1657 – 7.62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6.62193536908588E-06Poniżej przedstawiamy wzór do wywnioskowania kosztu uruchomienia na podstawie planu dla 200 000 wierszy:
koszt uruchomienia =
16,1657 – 200000*LOG(200000) * 6,62193536908588E-06 =1,35166186417734E-04Równie dobrze może być tak, że koszt uruchomienia dla małej i dużej skali jest taki sam, a różnica, jaką otrzymaliśmy, wynika z błędów zaokrąglania. W każdym razie, przy dużej liczbie wierszy, koszt uruchomienia staje się znikomy w porównaniu z kosztem porównań.
Podsumowując, oto wzór na koszt procesora operatora sortowania dla dużych liczb (>=20000):
Koszt procesora operatora =1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06Przetestujmy dokładność formuły za pomocą 500K, 1M i 10M rzędów. Poniższy kod przedstawia predykacje naszej formuły:
SELECT numrows, 1.35166186417734E-04 + numrows * LOG(numrows) * 6.62193536908588E-06 AS koszt predykowany FROM (VALUES(500000), (1000000), (10000000)) AS D(numrows);Użyj następujących zapytań, aby uzyskać szacunkowe koszty procesora:
SELECT id zamówienia % 1000000000 as myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT idzamówienia % 1000000000 as myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT CHECKSUM(NEWID()) jako myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Zamówienia AS O1 CROSS JOIN dbo.Zamówienia AS O2) AS D ORDER BY myorderid OPTION(MAXDOP 1);Otrzymałem następujące wyniki:
numrows współczynnik przewidywanego kosztu szacowanego kosztu ----------- --------------- -------------- --- --- 500000 43,4479 43,448 1,0000 1000000 91,4856 91,486 1,0000 10000000 1067,3300 1067,340 1,0000Wygląda na to, że nasz wzór na duże liczby działa całkiem nieźle.
Łączenie wszystkiego w całość
Całkowity koszt zastosowania agregacji strumienia z jawnym sortowaniem dla małej liczby wierszy (<=5000 wierszy) wynosi:
+ + =
0,0112613
+ 9.99127891201865E-05 + @numrows * LOG(@ numrows) * 2.25061348918698E-06
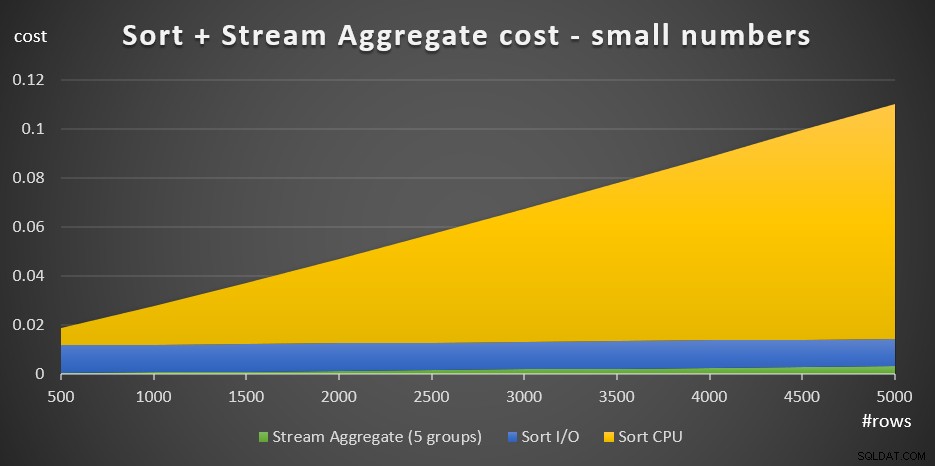
+ @numrows * 0,0000006 + @numgroups * 0,0000005Rysunek 3 przedstawia wykres warstwowy pokazujący, jak ten koszt się skaluje.
Rysunek 3:Koszt sortowania + agregacja strumienia dla małej liczby wierszeKoszt procesora sortowania stanowi największą część całkowitego zagregowanego kosztu Sort + Stream. Mimo to, przy małej liczbie wierszy, koszt Stream Aggregate i część kosztu Sort I/O nie są całkowicie pomijalne. Pod względem wizualnym możesz wyraźnie zobaczyć wszystkie trzy części wykresu.
Jeśli chodzi o dużą liczbę wierszy (>=20 000), wzór kosztów to:
0.0112613
+ 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06
+ @numrows * 0.0000006 + @numgroups * 0.0000005Nie widziałem dużej wartości w dążeniu do dokładnego sposobu, w jaki koszty porównania zmieniają się z małej na dużą.
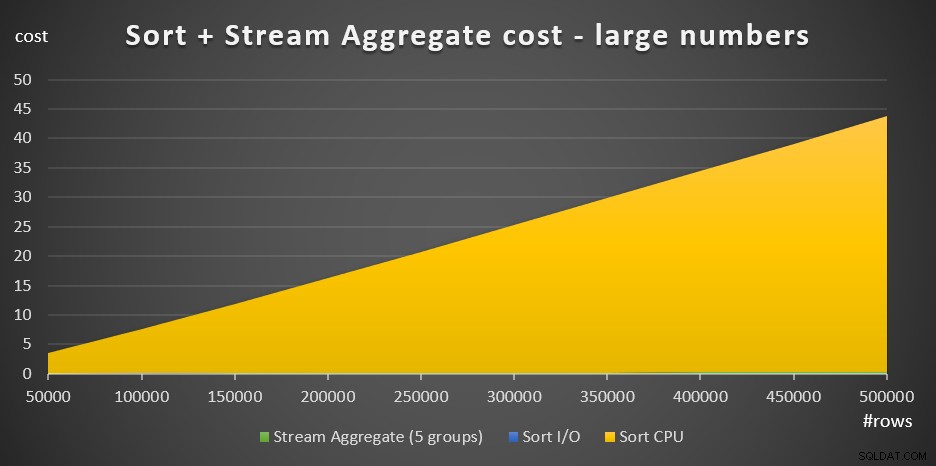
Rysunek 4 przedstawia wykres warstwowy przedstawiający skalowanie kosztów dla dużych liczb.
Rysunek 4:Koszt sortowania + agregacja strumienia dla dużej liczby wierszeW przypadku dużej liczby wierszy koszt agregacji strumienia i koszt we/wy sortowania są tak nieistotne w porównaniu z kosztem procesora sortowania, że nie są nawet widoczne gołym okiem na wykresie. Ponadto część kosztów procesora Sort przypisywana pracom startowym jest również znikoma. Dlatego jedyną istotną częścią kalkulacji kosztów jest całkowity koszt porównania:
@numrows * LOG(@numrows) *Oznacza to, że gdy trzeba ocenić skalowanie strategii Sort + Stream Aggregate, można ją uprościć do samej tylko tej dominującej części. Na przykład, jeśli chcesz ocenić, jak koszt skalowałby się ze 100 000 wierszy do 100 000 000 wierszy, możesz użyć wzoru (zauważ, że koszt porównania nie ma znaczenia):
(100000000 * LOG(100000000)*) / (100000 * LOG(100000)*) =1600Oznacza to, że gdy liczba wierszy wzrośnie ze 100 000 razy 1000 do 100 000 000, szacowany koszt wzrośnie 1600 razy.
Skalowanie od 1 000 000 do 1 000 000 000 wierszy jest obliczane jako:
(1000000000 * LOG(1000000000)) / (1000000 * LOG(1000000)) =1500Oznacza to, że gdy liczba wierszy wzrasta z 1 000 000 razy 1000, szacowany koszt wzrasta 1500 razy.
To ciekawe spostrzeżenia dotyczące sposobu skalowania strategii Sort + Stream Aggregate. Ze względu na bardzo niski koszt uruchomienia i dodatkowe skalowanie liniowe można oczekiwać, że ta strategia będzie dobrze działać z bardzo małą liczbą wierszy, ale nie tak dobrze z dużymi liczbami. Ponadto fakt, że sam operator Stream Aggregate reprezentuje tak mały ułamek kosztów w porównaniu z sytuacją, w której potrzebne jest również sortowanie, mówi, że można uzyskać znacznie lepszą wydajność, jeśli sytuacja jest taka, że można utworzyć indeks pomocniczy .
W kolejnej części serii omówię skalowanie algorytmu Hash Aggregate. Jeśli podoba Ci się to ćwiczenie polegające na próbie obliczenia formuł kosztów, sprawdź, czy możesz to rozgryźć dla tego algorytmu. Ważne jest, aby ustalić czynniki, które na to wpływają, sposób, w jaki się skaluje i warunki, w których radzi sobie lepiej niż inne algorytmy.