Jako konsultant pracujący z SQL Server, wiele razy jestem proszony o przyjrzenie się serwerowi, który wydaje się mieć problemy z wydajnością. Podczas wykonywania triage na serwerze zadaję pewne pytania, takie jak:jakie jest twoje normalne wykorzystanie procesora, jakie są twoje średnie opóźnienia dysku, jakie jest twoje normalne wykorzystanie pamięci i tak dalej. Odpowiedź zwykle brzmi:„nie wiemy” lub „nie przechwytujemy tych informacji regularnie”. Brak aktualnego stanu wyjściowego sprawia, że bardzo trudno jest stwierdzić, jak wygląda nieprawidłowe zachowanie. Jeśli nie wiesz, co to jest normalne zachowanie, skąd możesz mieć pewność, że jest lepiej, czy gorzej? Często używam wyrażeń „jeśli tego nie monitorujesz, nie możesz tego zmierzyć” i „jeśli tego nie mierzysz, nie możesz tym zarządzać”.
Z perspektywy monitorowania organizacje powinny co najmniej monitorować pod kątem nieudanych zadań, takich jak tworzenie kopii zapasowych, konserwacja indeksów, DBCC CHECKDB i inne ważne zadania. Łatwo jest skonfigurować powiadomienia o niepowodzeniach; jednak potrzebny jest również proces, aby upewnić się, że zadania działają zgodnie z oczekiwaniami. Widziałem prace, które się zawieszają i nigdy nie są kończone. Powiadomienie o niepowodzeniu nie wywoła alarmu, ponieważ zadanie nigdy się nie powiedzie lub nie powiedzie się.
Na podstawie bazowej wydajności należy uchwycić kilka kluczowych wskaźników. Stworzyłem proces, którego używam z klientami, który regularnie przechwytuje kluczowe metryki i przechowuje te wartości w bazie danych użytkowników. Mój proces jest prosty:dedykowana baza danych z procedurami składowanymi, które wykorzystują popularne skrypty, które wstawiają zestawy wyników do tabel. Mam zadania SQL Agent do uruchamiania procedur składowanych w regularnych odstępach czasu oraz skrypt czyszczący do usuwania danych starszych niż X dni. Metryki, które zawsze przechwytuję, obejmują:
Oczekiwana długość życia strony :PLE jest prawdopodobnie jednym z najlepszych sposobów oceny, czy twój system jest pod presją pamięci wewnętrznej. Większość systemów ma wartości PLE, które zmieniają się podczas normalnego obciążenia. Lubię trendować te wartości, aby wiedzieć, jakie są wartości minimalne, średnie i maksymalne. Lubię próbować zrozumieć, co spowodowało spadek PLE w określonych porach dnia, aby sprawdzić, czy te procesy można dostroić. Wiele razy ktoś skanuje tabelę i opróżnia pulę buforów. Pomocna może być umiejętność prawidłowego indeksowania tych zapytań. Upewnij się tylko, że monitorujesz właściwy licznik PLE – zobacz tutaj .
Wykorzystanie procesora :Posiadanie linii bazowej wykorzystania procesora pozwala wiedzieć, czy system jest nagle obciążony procesorem. Często, gdy użytkownik skarży się na problemy z wydajnością, zauważy, że procesor wygląda na wysoki. Na przykład, jeśli CPU oscyluje wokół 80%, mogą uznać to za niepokojące, jednak jeśli CPU również wynosiło 80% w tym samym czasie w poprzednich tygodniach, kiedy nie zgłaszano żadnych problemów, prawdopodobieństwo, że przyczyną problemu jest CPU, jest bardzo niskie. Procesor Trending służy nie tylko do przechwytywania, gdy procesor gwałtownie wzrasta i pozostaje na niezmiennie wysokiej wartości. Mam wiele historii o tym, jak zostałem doprowadzony do mostu konferencyjnego o stopniu poważności, ponieważ wystąpił problem z aplikacją. Jako DBA nosiłem kapelusz „Default Blame Acceptor”. Kiedy zespół aplikacji powiedział, że wystąpił problem z bazą danych, do mnie należało udowodnienie, że tak nie jest, serwer bazy danych był winny, dopóki nie udowodniono jego niewinności. Doskonale pamiętam incydent, w którym zespół aplikacji był przekonany, że serwer bazy danych ma problemy, ponieważ użytkownicy nie mogą się połączyć. Przeczytali w Internecie, że SQL Server może cierpieć z powodu głodu w puli wątków, jeśli odmawia połączenia. Wskoczyłem na serwer i zacząłem przyglądać się zasobom oraz tym, jakie procesy są aktualnie uruchomione. W ciągu kilku minut zgłosiłem, że serwer, o którym mowa, był bardzo znudzony. W oparciu o nasze podstawowe dane, procesor zwykle wynosił 60% i był bezczynny około 20%, oczekiwany czas życia strony był zauważalnie wyższy niż normalnie, nie wystąpiło żadne blokowanie ani blokowanie, operacje we/wy wyglądały świetnie, żadnych błędów w logach oraz liczba sesji wynosiła około 1/3 ich normalnej liczby. Następnie dodałem komentarz:„Wygląda na to, że użytkownicy nawet nie docierają do serwera bazy danych”. To zwróciło uwagę użytkowników sieci i zdali sobie sprawę, że zmiana, którą wprowadzili w systemie równoważenia obciążenia, nie działała prawidłowo i ustalili, że ponad 50% połączeń było nieprawidłowo trasowanych i nie docierało do serwera bazy danych. Gdybym nie wiedział, jaki jest poziom odniesienia, osiągnięcie rozwiązania zajęłoby nam dużo więcej czasu.
Dysk we/wy :Przechwytywanie metryk dysku jest bardzo ważne. DMV sys.dm_io_virtual_file_stats kumuluje się od ostatniego ponownego uruchomienia serwera. Przechwycenie opóźnień we/wy w określonym przedziale czasu da ci linię bazową tego, co jest normalne w tym czasie. Poleganie na wartości skumulowanej może dać wypaczone dane z działań po godzinach pracy lub długich okresów bezczynności systemu. Paul omówił to tu .
Rozmiary plików bazy danych :Posiadanie spisu baz danych, który obejmuje rozmiar pliku, używany rozmiar, wolne miejsce i nie tylko, może pomóc w prognozowaniu wzrostu bazy danych. Często jestem proszony o prognozę, ile pamięci będzie potrzebne dla serwera bazy danych w nadchodzącym roku. Nie znając tygodniowego lub miesięcznego trendu wzrostowego, nie mam możliwości inteligentnego wymyślenia liczby. Gdy zacznę śledzić te wartości, mogę odpowiednio je trendować. Oprócz trendów mogłem również dowiedzieć się, kiedy nastąpił nieoczekiwany wzrost bazy danych. Kiedy widzę nieoczekiwany wzrost i badam, zwykle okazuje się, że ktoś albo zduplikował tabelę, aby przeprowadzić pewne testy (tak, w produkcji!) albo wykonał inny jednorazowy proces. Śledzenie tego typu danych i możliwość reagowania w przypadku wystąpienia anomalii pomaga pokazać, że jesteś proaktywny i czuwasz nad swoimi systemami.
Statystyki oczekiwania :Monitorowanie statystyk oczekiwania może pomóc w ustaleniu przyczyny niektórych problemów z wydajnością. Wielu nowych administratorów baz danych jest zaniepokojonych, gdy po raz pierwszy zaczynają badać statystyki oczekiwania i nie zdają sobie sprawy, że oczekiwania zawsze występują, a tak właśnie działa system planowania SQL Server. Istnieje również wiele wyczekiwań, które można uznać za łagodne lub w większości nieszkodliwe. Paul Randal wyklucza te w większości nieszkodliwe oczekiwanie w swoim popularnym skrypcie ze statystykami oczekiwania. Paul zbudował także ogromną bibliotekę różnych rodzajów czekania i klasy zatrzaskowe z opisami i innymi informacjami na temat rozwiązywania problemów z oczekiwaniami i zatrzaskami.
Udokumentowałem mój proces zbierania danych, a kod można znaleźć na moim blogu . W zależności od sytuacji i rodzajów problemów, z którymi może borykać się klient, mogę również chcieć uchwycić dodatkowe metryki. Glenn Berry napisał na blogu o procesie, który zebrał, który rejestruje średnią liczbę zadań, średnią liczbę zadań, które można uruchomić, średnią liczbę oczekujących operacji we/wy, wykorzystanie procesora przez proces SQL Server i średnią długość życia strony we wszystkich węzłach NUMA. Szybkie wyszukiwanie w Internecie ujawni kilka innych procesów gromadzenia danych, które ludzie udostępnili, nawet Zespół SQL Server Tiger ma proces, który wykorzystuje T-SQL i PowerShell.
Korzystanie z niestandardowej bazy danych i budowanie własnego pakietu do gromadzenia danych jest prawidłowym rozwiązaniem do przechwytywania punktu odniesienia, ale większość z nas nie zajmuje się tworzeniem pełnych rozwiązań do monitorowania SQL Server. Jest dużo więcej rzeczy, które byłyby pomocne w przechwytywaniu, takich jak długo działające zapytania, najczęstsze zapytania i procedury składowane oparte na pamięci, we/wy i procesorze, zakleszczenia, fragmentacja indeksów, transakcje na sekundę i wiele innych. W tym celu zawsze polecam klientom zakup narzędzia monitorującego innej firmy. Dostawcy ci specjalizują się w nadążaniu za najnowszymi trendami i funkcjami SQL Server, dzięki czemu możesz skupić swój czas na upewnieniu się, że SQL Server jest tak stabilny i szybki, jak to tylko możliwe.
Rozwiązania takie jak SQL Sentry (dla SQL Server) i DB Sentry (dla Azure SQL Database) przechwytuje wszystkie te metryki i umożliwia łatwe tworzenie różnych planów bazowych. Możesz mieć normalną linię bazową, koniec miesiąca, koniec kwartału i inne. Następnie możesz zastosować linię bazową i zobaczyć wizualnie, jak rzeczy się różnią. Co ważniejsze, możesz skonfigurować dowolną liczbę alertów dla różnych warunków i otrzymywać powiadomienia, gdy metryki przekroczą Twoje progi.
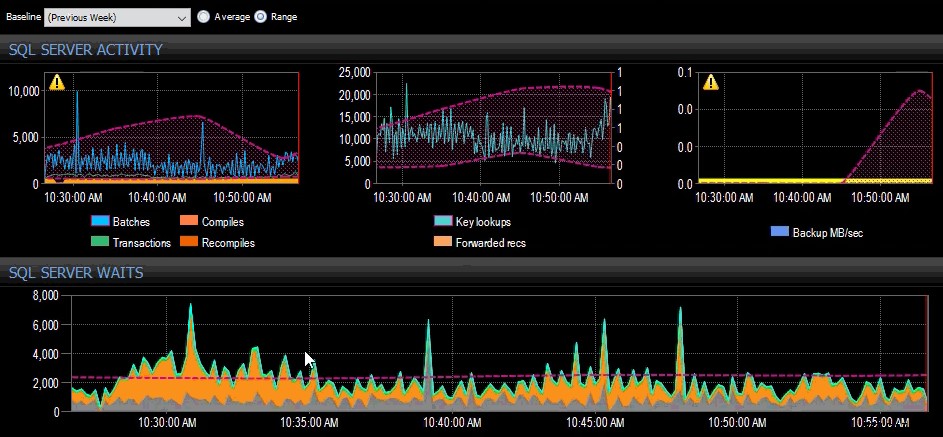 Wzorzec bazowy z zeszłego tygodnia zastosowany do kilku wskaźników SQL Server na pulpicie nawigacyjnym SQL Sentry.
Wzorzec bazowy z zeszłego tygodnia zastosowany do kilku wskaźników SQL Server na pulpicie nawigacyjnym SQL Sentry.
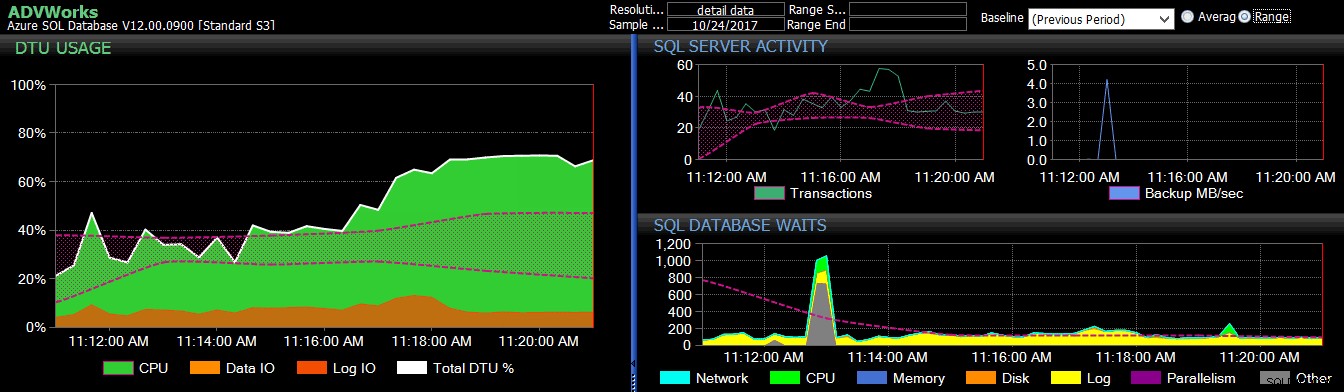 Para bazowa poprzedniego okresu została zastosowana do kilku metryk usługi Azure SQL Database na pulpicie nawigacyjnym DB Sentry.
Para bazowa poprzedniego okresu została zastosowana do kilku metryk usługi Azure SQL Database na pulpicie nawigacyjnym DB Sentry.
Aby uzyskać więcej informacji na temat linii bazowych w SentryOne, zobacz te posty na blogu zespołu lub ten 2-minutowy wtorkowy film . Chcesz pobrać wersję próbną? Ciebie też tam mają .