Ten artykuł jest drugim z serii o błędach, pułapkach i najlepszych praktykach T-SQL. Tym razem skupiam się na klasycznych błędach związanych z podzapytaniami. W szczególności zajmuję się błędami podstawienia i trójwartościowymi problemami logicznymi. Kilka tematów, które poruszam w serii, zostało zasugerowanych przez innych MVP w dyskusji, którą odbyliśmy na ten temat. Podziękowania dla Erlanda Sommarskoga, Aarona Bertranda, Alejandro Mesy, Umachandara Jayachandrana (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man i Paul White za Wasze sugestie!
Błąd zastępowania
Aby zademonstrować klasyczny błąd podstawienia, posłużę się prostym scenariuszem klienci-zamówienia. Uruchom następujący kod, aby utworzyć funkcję pomocniczą o nazwie GetNums oraz utworzyć i wypełnić tabele Customers i Orders:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); Obecnie w tabeli Klienci znajduje się 100 klientów z kolejnymi identyfikatorami klientów w zakresie od 1 do 100. 98 z nich ma odpowiadające zamówienia w tabeli Zamówienia. Klienci o identyfikatorach 17 i 59 nie złożyli jeszcze żadnych zamówień i dlatego nie są obecni w tabeli Zamówienia.
Szukasz tylko klientów, którzy złożyli zamówienia, i próbujesz to osiągnąć za pomocą następującego zapytania (nazwij go Zapytanie 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Powinieneś odzyskać 98 klientów, ale zamiast tego otrzymujesz wszystkich 100 klientów, w tym tych z identyfikatorami 17 i 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Czy możesz dowiedzieć się, co jest nie tak?
Aby zwiększyć zamieszanie, przeanalizuj plan dla Zapytania 1, jak pokazano na rysunku 1.
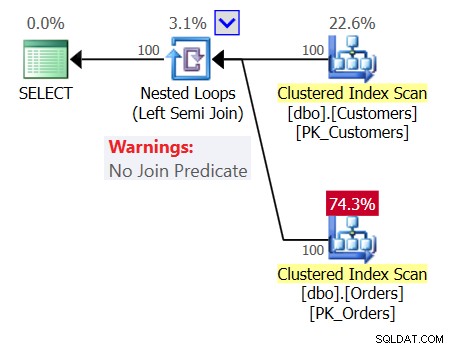 Rysunek 1:Plan dla zapytania 1
Rysunek 1:Plan dla zapytania 1
Plan zawiera operator zagnieżdżonych pętli (Left Semi Join) bez predykatu łączenia, co oznacza, że jedynym warunkiem zwrócenia klienta jest posiadanie niepustej tabeli Orders, tak jakby napisane zapytanie było następujące:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Prawdopodobnie spodziewałeś się planu podobnego do tego pokazanego na rysunku 2.
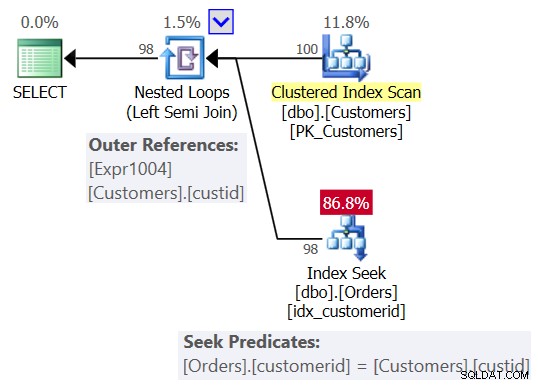 Rysunek 2:Oczekiwany plan dla zapytania 1
Rysunek 2:Oczekiwany plan dla zapytania 1
W tym planie widzisz operator zagnieżdżonych pętli (Left Semi Join), ze skanowaniem indeksu klastrowego Customers jako zewnętrznym wejściem i wyszukiwaniem w indeksie w kolumnie customerid w Orders jako wewnętrznym wejściem. Zobaczysz również odwołanie zewnętrzne (skorelowany parametr) na podstawie kolumny custid w Customers i predykatu seek Orders.customerid =Customers.custid.
Dlaczego więc otrzymujesz plan z rysunku 1, a nie z rysunku 2? Jeśli jeszcze tego nie wiesz, przyjrzyj się bliżej definicjom obu tabel — w szczególności nazwom kolumn — oraz nazwom kolumn użytym w zapytaniu. Zauważysz, że tabela Klienci zawiera identyfikatory klientów w kolumnie o nazwie custid, a tabela Zamówienia zawiera identyfikatory klientów w kolumnie o nazwie customerid. Jednak kod używa custid zarówno w zapytaniach zewnętrznych, jak i wewnętrznych. Ponieważ odwołanie do custid w wewnętrznej kwerendzie nie jest kwalifikowane, SQL Server musi rozstrzygnąć, z której tabeli pochodzi kolumna. Zgodnie ze standardem SQL, SQL Server powinien najpierw szukać kolumny w tabeli, która jest odpytywana w tym samym zakresie, ale ponieważ w Orders nie ma kolumny o nazwie custid, powinien następnie szukać jej w tabeli w zewnętrznej zakres i tym razem jest dopasowanie. Tak więc niechcący odniesienie do custid staje się pośrednio skorelowanym odniesieniem, tak jakbyś napisał następujące zapytanie:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Zakładając, że Orders nie jest puste, a zewnętrzna wartość custid nie jest NULL (nie może być w naszym przypadku, ponieważ kolumna jest zdefiniowana jako NOT NULL), zawsze otrzymasz dopasowanie, ponieważ porównujesz wartość do siebie . Tak więc Zapytanie 1 staje się odpowiednikiem:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Jeśli zewnętrzna tabela obsługiwała wartości NULL w kolumnie custid, Zapytanie 1 byłoby równoważne:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Teraz rozumiesz, dlaczego zapytanie 1 zostało zoptymalizowane z planem na rysunku 1 i dlaczego odzyskałeś wszystkich 100 klientów.
Jakiś czas temu odwiedziłem klienta, który miał podobny błąd, ale niestety z wyciągiem DELETE. Pomyśl przez chwilę, co to oznacza. Wszystkie wiersze tabeli zostały wymazane, a nie tylko te, które pierwotnie zamierzały usunąć!
Jeśli chodzi o najlepsze praktyki, które mogą pomóc w uniknięciu takich błędów, istnieją dwie główne. Po pierwsze, o ile możesz to kontrolować, upewnij się, że używasz spójnych nazw kolumn w tabelach dla atrybutów, które reprezentują to samo. Po drugie, upewnij się, że w tabeli kwalifikujesz odwołania do kolumn w podzapytaniach, w tym w zapytaniach niezależnych, gdzie nie jest to powszechna praktyka. Oczywiście możesz użyć aliasu tabeli, jeśli wolisz nie używać pełnych nazw tabel. Stosując tę praktykę do naszego zapytania, załóżmy, że w początkowej próbie użyto następującego kodu:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Tutaj nie zezwalasz na niejawne rozpoznawanie nazw kolumn, dlatego SQL Server generuje następujący błąd:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Idziesz i sprawdzasz metadane dla tabeli Zamówienia, zdajesz sobie sprawę, że użyłeś niewłaściwej nazwy kolumny i poprawiasz zapytanie (nazwij to Zapytanie 2), tak jak:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Tym razem uzyskasz właściwe wyniki z 98 klientami, z wyłączeniem klientów o identyfikatorach 17 i 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
Otrzymasz również oczekiwany plan pokazany wcześniej na rysunku 2.
Na marginesie, jasne jest, dlaczego Customers.custid jest odniesieniem zewnętrznym (parametrem skorelowanym) w operatorze zagnieżdżonych pętli (Left Semi Join) na rysunku 2. Mniej oczywiste jest to, dlaczego Expr1004 pojawia się również w planie jako odwołanie zewnętrzne. Inny SQL Server MVP, Paul White, teoretyzuje, że może to być związane z wykorzystaniem informacji z zewnętrznego liścia wejściowego, aby wskazać silnikowi pamięci masowej, aby uniknąć powielania wysiłków przez mechanizmy odczytu z wyprzedzeniem. Szczegóły znajdziesz tutaj.
Trójwartościowa usterka logiczna
Częsty błąd dotyczący podzapytań dotyczy przypadków, w których zapytanie zewnętrzne używa predykatu NOT IN, a podzapytanie może potencjalnie zwrócić wartości NULL. Załóżmy na przykład, że musisz mieć możliwość przechowywania zamówień w naszej tabeli Zamówienia z wartością NULL jako identyfikatorem klienta. Taki przypadek reprezentuje zamówienie, które nie jest powiązane z żadnym klientem; na przykład zamówienie, które kompensuje niezgodności między rzeczywistą liczbą produktów a liczbą zarejestrowaną w bazie danych.
Użyj poniższego kodu, aby odtworzyć tabelę Orders z kolumną custid zezwalającą na wartości NULL, a na razie wypełnij ją tymi samymi przykładowymi danymi, co wcześniej (z zamówieniami według identyfikatorów klientów od 1 do 100, z wyłączeniem 17 i 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Zauważ, że kiedy już przy tym jesteśmy, zastosowałem najlepszą praktykę omówioną w poprzedniej sekcji, aby używać spójnych nazw kolumn w tabelach dla tych samych atrybutów i nazwałem kolumnę w tabeli Zamówienia tak samo, jak w tabeli Klienci.
Załóżmy, że musisz napisać zapytanie zwracające klientów, którzy nie złożyli zamówień. Wymyślasz następujące uproszczone rozwiązanie, używając predykatu NOT IN (nazwij go Zapytanie 3, pierwsze wykonanie):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
To zapytanie zwraca oczekiwane wyniki z klientami 17 i 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Inwentaryzacja odbywa się w magazynie firmy i stwierdza się niezgodność między rzeczywistą ilością jakiegoś produktu a ilością zarejestrowaną w bazie danych. Tak więc dodajesz fikcyjny nakaz kompensacyjny, aby uwzględnić niezgodność. Ponieważ nie ma rzeczywistego klienta powiązanego z zamówieniem, jako identyfikatora klienta używasz wartości NULL. Uruchom następujący kod, aby dodać taki nagłówek zamówienia:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Uruchom zapytanie 3 po raz drugi:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Tym razem otrzymujesz pusty wynik:
custid companyname ------- ------------ (0 rows affected)
Najwyraźniej coś jest nie tak. Wiesz, że klienci 17 i 59 nie złożyli żadnych zamówień i rzeczywiście pojawiają się w tabeli Klienci, ale nie w tabeli Zamówienia. Jednak wynik zapytania twierdzi, że nie ma klienta, który nie złożył żadnych zamówień. Czy możesz dowiedzieć się, gdzie jest błąd i jak go naprawić?
Błąd ma oczywiście związek z NULL w tabeli Orders. W SQL NULL jest znacznikiem brakującej wartości, która może reprezentować odpowiedniego klienta. SQL nie wie, że dla nas NULL oznacza brakującego i nieodpowiedniego (nieistotnego) klienta. W przypadku wszystkich klientów w tabeli Klienci, którzy są obecni w tabeli Zamówienia, predykat IN znajduje dopasowanie dające wartość TRUE, a część NOT IN powoduje, że jest to FALSE, w związku z czym wiersz klienta jest odrzucany. Jak na razie dobrze. Ale dla klientów 17 i 59 predykat IN daje wynik UNKNOWN, ponieważ wszystkie porównania z wartościami innymi niż NULL dają FALSE, a porównanie z wartością NULL daje wynik UNKNOWN. Pamiętaj, że SQL zakłada, że NULL może reprezentować dowolnego odpowiedniego klienta, więc wartość logiczna UNKNOWN wskazuje, że nie wiadomo, czy zewnętrzny identyfikator klienta jest równy wewnętrznemu NULL identyfikatorowi klienta. FAŁSZ CZY FAŁSZ … LUB NIEZNANE jest NIEZNANE. Następnie część NOT IN zastosowana do UNKNOWN nadal daje NIEZNANE.
Mówiąc prościej po angielsku, poprosiłeś o zwrot klientów, którzy nie złożyli zamówień. Zatem naturalnie zapytanie odrzuca wszystkich klientów z tabeli Klienci, którzy są obecni w tabeli Zamówienia, ponieważ wiadomo z całą pewnością, że złożyli zamówienia. Co do reszty (w naszym przypadku 17 i 59) zapytanie odrzuca je ponieważ do SQL, tak jak nie wiadomo czy złożyli zamówienia, tak samo nie wiadomo czy nie złożyli, a filtr potrzebuje pewności (PRAWDA) w aby zwrócić wiersz. Co za marynata!
Tak więc, gdy tylko pierwszy NULL znajdzie się w tabeli Orders, od tego momentu zawsze otrzymasz pusty wynik z zapytania NOT IN. A co z przypadkami, w których w rzeczywistości nie masz w danych wartości NULL, ale kolumna zezwala na wartości NULL? Jak zauważyłeś przy pierwszym wykonaniu Zapytania 3, w takim przypadku otrzymasz poprawny wynik. Być może myślisz, że aplikacja nigdy nie wprowadzi wartości NULL do danych, więc nie masz się czym martwić. To zła praktyka z kilku powodów. Po pierwsze, jeśli kolumna jest zdefiniowana jako zezwalająca na wartości NULL, jest prawie pewna, że w końcu dotrą do niej wartości NULL, nawet jeśli nie powinny; to tylko kwestia czasu. Może to być wynikiem importowania złych danych, błędu w aplikacji i innych przyczyn. Po drugie, nawet jeśli dane nie zawierają wartości NULL, jeśli kolumna na to zezwala, optymalizator musi uwzględnić możliwość, że podczas tworzenia planu zapytania będą obecne wartości NULL, a w naszym zapytaniu NOT IN pociąga to za sobą karę wydajności . Aby to zademonstrować, rozważ plan pierwszego wykonania Zapytania 3 przed dodaniem wiersza z wartością NULL, jak pokazano na rysunku 3.
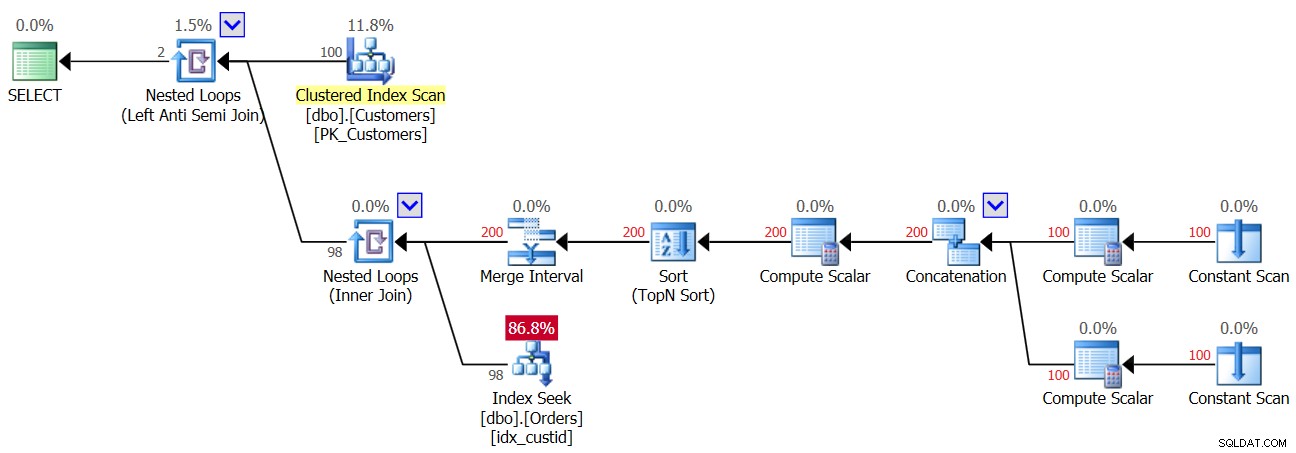 Rysunek 3:Plan pierwszego wykonania zapytania 3
Rysunek 3:Plan pierwszego wykonania zapytania 3
Górny operator zagnieżdżonych pętli obsługuje logikę Left Anti Semi Join. Zasadniczo chodzi o identyfikację niedopasowań i zwarcie wewnętrznej aktywności, gdy tylko zostanie znalezione dopasowanie. Zewnętrzna część pętli ściąga wszystkich 100 klientów z tabeli Customers, stąd wewnętrzna część pętli jest wykonywana 100 razy.
Wewnętrzna część górnej pętli wykonuje operator zagnieżdżonych pętli (Inner Join). Zewnętrzna część dolnej pętli tworzy dwa wiersze na klienta — jeden dla przypadku NULL, a drugi dla bieżącego identyfikatora klienta, w tej kolejności. Nie daj się zmylić operatorowi interwału scalania. Zwykle jest używany do łączenia nakładających się przedziałów, np. predykat taki jak col1 BETWEEN 20 AND 30 OR col1 BETWEEN 25 AND 35 jest konwertowany na col1 BETWEEN 20 AND 35. Ten pomysł można uogólnić, aby usunąć duplikaty w predykacie IN. W naszym przypadku tak naprawdę nie może być żadnych duplikatów. W uproszczeniu, jak wspomniano, pomyśl o zewnętrznej części pętli jako o tworzeniu dwóch wierszy na klienta — pierwszy dla przypadku NULL, a drugi dla bieżącego identyfikatora klienta. Następnie wewnętrzna część pętli najpierw wykonuje wyszukiwanie w indeksie idx_custid w Orders w celu wyszukania wartości NULL. Jeśli zostanie znaleziony NULL, nie aktywuje drugiego wyszukiwania bieżącego identyfikatora klienta (pamiętaj o zwarciu obsługiwanym przez górną pętlę Anti Semi Join). W takim przypadku klient zewnętrzny jest odrzucany. Ale jeśli nie zostanie znaleziony NULL, dolna pętla aktywuje drugie wyszukiwanie bieżącego identyfikatora klienta w Zamówieniach. Jeśli zostanie znaleziony, klient zewnętrzny jest odrzucany. Jeśli nie zostanie znaleziony, zwracany jest klient zewnętrzny. Oznacza to, że jeśli w Zamówieniach nie ma wartości NULL, ten plan wykonuje dwa wyszukiwania na klienta! Można to zaobserwować na planie jako liczba rzędów 200 w zewnętrznym wejściu dolnej pętli. W konsekwencji, oto statystyki I/O, które są raportowane dla pierwszego wykonania:
Table 'Orders'. Scan count 200, logical reads 603
Plan drugiego wykonania Zapytania 3, po dodaniu wiersza z NULL do tabeli Orders, pokazano na rysunku 4.
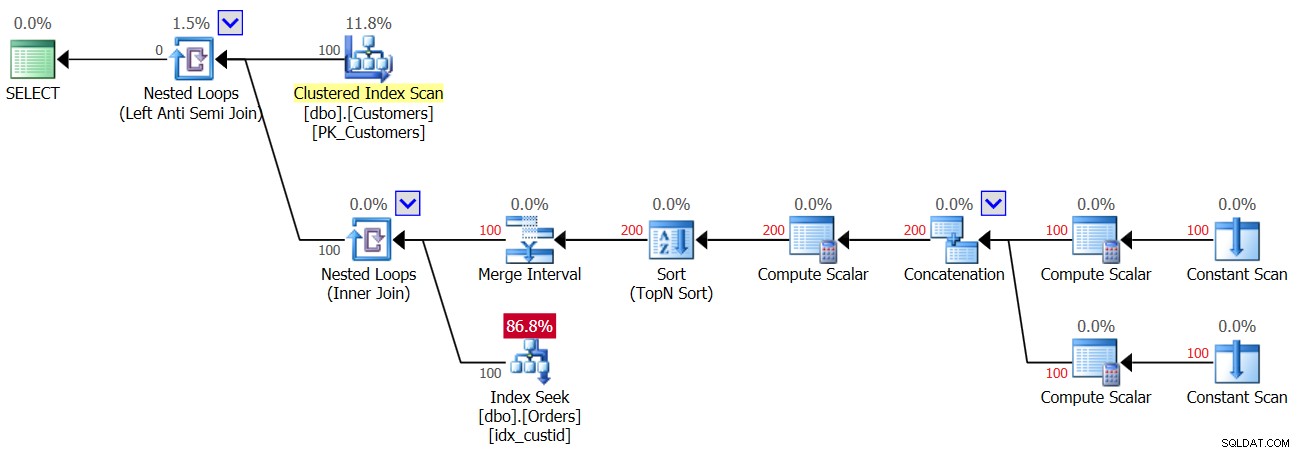 Rysunek 4:Plan drugiego wykonania zapytania 3
Rysunek 4:Plan drugiego wykonania zapytania 3
Ponieważ w tabeli występuje NULL, dla wszystkich klientów pierwsze wykonanie operatora Index Seek znajduje dopasowanie, a zatem wszyscy klienci są odrzucani. Więc tak, robimy tylko jedno wyszukiwanie na klienta, a nie dwa, więc tym razem otrzymujesz 100 wyszukiwań, a nie 200; jednak jednocześnie oznacza to, że otrzymujesz pusty wynik!
Oto statystyki I/O, które są raportowane dla drugiego wykonania:
Table 'Orders'. Scan count 100, logical reads 300
Jednym z rozwiązań tego zadania, gdy wartości NULL są możliwe wśród zwracanych wartości w podzapytaniu, jest po prostu ich odfiltrowanie, w ten sposób (nazwij to Rozwiązanie 1/Zapytanie 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Ten kod generuje oczekiwane dane wyjściowe:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Minusem tego rozwiązania jest to, że trzeba pamiętać o dodaniu filtra. Wolę rozwiązanie wykorzystujące predykat NIE ISTNIEJE, w którym podzapytanie ma wyraźną korelację porównującą identyfikator klienta zamówienia z identyfikatorem klienta, tak jak (nazwij to Rozwiązanie 2/Zapytanie 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Pamiętaj, że oparte na równości porównanie wartości NULL i czegokolwiek daje wynik UNKNOWN, a UNKNOWN jest odrzucane przez filtr WHERE. Jeśli więc w Zamówieniach istnieją wartości NULL, są one eliminowane przez wewnętrzny filtr zapytania bez konieczności dodawania wyraźnego traktowania NULL, a zatem nie musisz się martwić, czy w danych występują wartości NULL.
To zapytanie generuje oczekiwany wynik:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Plany obu rozwiązań pokazano na rysunku 5.
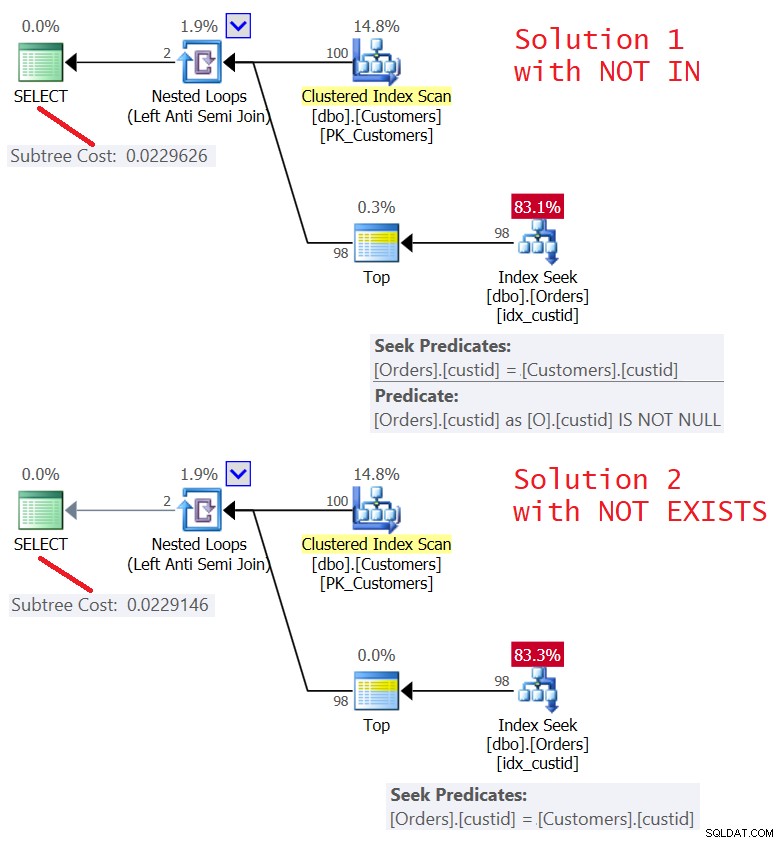 Rysunek 5:Plany dla zapytania 4 (rozwiązanie 1) i zapytania 5 (rozwiązanie 2 )
Rysunek 5:Plany dla zapytania 4 (rozwiązanie 1) i zapytania 5 (rozwiązanie 2 )
Jak widać plany są niemal identyczne. Są również dość wydajne, wykorzystując optymalizację Left Semi Join ze zwarciem. Oba przeprowadzają tylko 100 wyszukiwań w indeksie idx_custid w zamówieniach, a za pomocą operatora Top stosują zwarcie po dotknięciu jednego wiersza w liściu.
Statystyki I/O dla obu zapytań są takie same:
Table 'Orders'. Scan count 100, logical reads 348
Jedną rzeczą do rozważenia jest to, czy istnieje jakakolwiek szansa na to, że tabela zewnętrzna będzie miała wartości NULL w skorelowanej kolumnie (w naszym przypadku custid). Bardzo mało prawdopodobne, aby miało to znaczenie w scenariuszu takim jak zamówienia klientów, ale może mieć znaczenie w innych scenariuszach. Jeśli rzeczywiście tak jest, oba rozwiązania nieprawidłowo obsługują zewnętrzną wartość NULL.
Aby to zademonstrować, upuść i ponownie utwórz tabelę Klienci z wartością NULL jako jednym z identyfikatorów klientów, uruchamiając następujący kod:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); Rozwiązanie 1 nie zwróci zewnętrznej wartości NULL niezależnie od tego, czy wewnętrzna wartość NULL jest obecna, czy nie.
Rozwiązanie 2 zwróci zewnętrzną wartość NULL niezależnie od tego, czy wewnętrzna wartość NULL jest obecna, czy nie.
Jeśli chcesz obsługiwać wartości NULL, tak jak obsługujesz wartości inne niż NULL, tj. Zwróć wartość NULL, jeśli jest ona obecna w Customers, ale nie w Zamówieniach, i nie zwracaj jej, jeśli jest obecna w obu, musisz zmienić logikę rozwiązania, aby użyć odrębności porównanie oparte na porównaniu zamiast porównania opartego na równości. Można to osiągnąć, łącząc predykat EXISTS i operator zbioru EXCEPT, w ten sposób (nazwij to rozwiązanie 3/zapytanie 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Ponieważ obecnie w Kliencie i Zamówieniach znajdują się wartości NULL, to zapytanie poprawnie nie zwraca wartości NULL. Oto wynik zapytania:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Uruchom następujący kod, aby usunąć wiersz z wartością NULL z tabeli Zamówienia i ponownie uruchom Rozwiązanie 3:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Tym razem, ponieważ wartość NULL występuje w klientach, ale nie w zamówieniach, wynik zawiera wartość NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
Plan tego rozwiązania pokazano na rysunku 6:
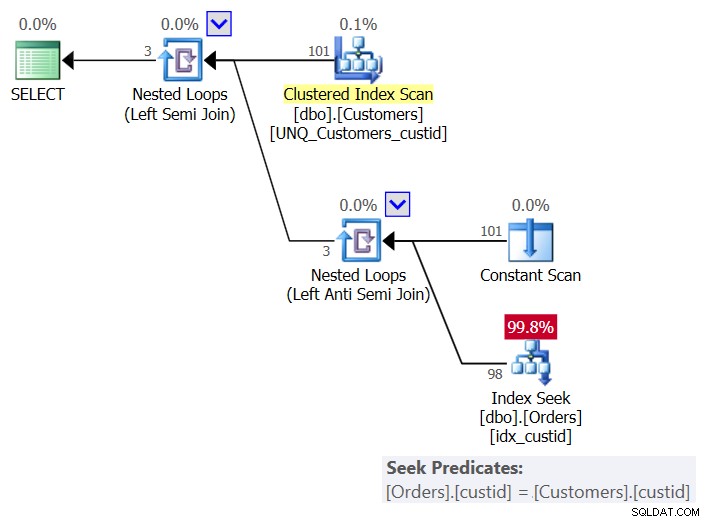 Rysunek 6:Plan dla zapytania 6 (rozwiązanie 3)
Rysunek 6:Plan dla zapytania 6 (rozwiązanie 3)
Dla każdego klienta plan używa operatora Constant Scan do utworzenia wiersza z bieżącym klientem i stosuje pojedyncze wyszukiwanie w indeksie idx_custid w Zamówieniach, aby sprawdzić, czy klient istnieje w Zamówieniach. Kończysz z jednym wyszukiwaniem na klienta. Ponieważ obecnie w tabeli mamy 101 klientów, otrzymujemy 101 wyszukiwań.
Oto statystyki we/wy dla tego zapytania:
Table 'Orders'. Scan count 101, logical reads 415
Wniosek
W tym miesiącu omówiłem błędy, pułapki i najlepsze praktyki związane z podzapytaniami. Omówiłem błędy podstawień i trójwartościowe problemy logiczne. Pamiętaj, aby używać spójnych nazw kolumn w tabelach i zawsze kwalifikować kolumny w podzapytaniach, nawet jeśli są one niezależne. Pamiętaj również, aby wymusić ograniczenie NOT NULL, gdy kolumna nie ma zezwalać na wartości NULL i zawsze brać je pod uwagę, gdy są one możliwe w danych. Upewnij się, że w przykładowych danych wstawiasz wartości NULL, gdy są one dozwolone, aby łatwiej wyłapywać błędy w kodzie podczas jego testowania. Uważaj na predykat NOT IN w połączeniu z podzapytaniami. Jeśli w wyniku wewnętrznego zapytania możliwe są wartości NULL, zwykle preferowaną alternatywą jest predykat NOT EXISTS.