Wprowadzenie
W SQL Server 2012 agregacja zgrupowana (wektorowa) mogła korzystać z równoległego wykonywania w trybie wsadowym, ale tylko dla częściowej (na wątek) agregacji. Powiązana globalna agregacja zawsze działała w trybie wiersza, po Strumieniach podziału wymiana.
SQL Server 2014 dodał możliwość wykonywania równoległej agregacji grupowej w trybie wsadowym w ramach jednej agregacji Hash Match operator. Wyeliminowało to niepotrzebne przetwarzanie w trybie wiersza i wyeliminowało potrzebę wymiany.
SQL Server 2016 wprowadził szeregowe przetwarzanie w trybie wsadowym i agregację pushdown . Gdy przesuwanie się powiedzie, agregacja jest wykonywana w ramach skanowania kolumn samego operatora, prawdopodobnie działającego bezpośrednio na skompresowanych danych i korzystającego z instrukcji procesora SIMD.
Poprawa wydajności możliwa dzięki zagregowanemu pushdownowi może być bardzo znacząca. Dokumentacja wymienia niektóre warunki wymagane do osiągnięcia pushdown, ale są przypadki, w których braku „lokalnie agregowanych wierszy” nie można w pełni wyjaśnić na podstawie samych tych szczegółów.
W tym artykule omówiono dodatkowe czynniki, które wpływają na agregację przesuwania w dół dla GROUP BY tylko zapytania . Agregacja skalarna w dół (agregacja bez GROUP BY klauzula), filter pushdown i wyrażenie pushdown mogą zostać omówione w przyszłym poście.
Przechowywanie kolumn
Pierwszą rzeczą do powiedzenia jest to, że agregacja przesuwania w dół dotyczy tylko danych skompresowanych, więc wiersze w magazynie delta nie kwalifikują się. Poza tym pushdown może zależeć od rodzaju użytej kompresji. Aby to zrozumieć, należy najpierw sprawdzić, jak działa magazyn kolumn na wysokim poziomie:
skompresowana grupa wierszy zawiera segment kolumny dla każdej kolumny. Nieprzetworzone wartości kolumn są zakodowane w 4-bajtowej lub 8-bajtowej liczbie całkowitej przy użyciu wartości lub słownik kodowanie.
Kodowanie wartości może zmniejszyć liczbę bitów wymaganych do przechowywania, tłumacząc surowe wartości za pomocą modyfikatora przesunięcia bazowego i wielkości. Na przykład wartości {1100, 1200, 1300} mogą być przechowywane jako (0, 1, 2) przez najpierw przeskalowanie o współczynnik 0,01, aby uzyskać {11, 12, 13}, a następnie zmianę bazy na 11, aby uzyskać {0, 1, 2}.
Kodowanie słownika jest używany, gdy istnieją zduplikowane wartości. Może być używany z danymi nienumerycznymi. Każda unikatowa wartość jest przechowywana w słowniku i ma przypisany identyfikator w postaci liczby całkowitej. Dane segmentu odwołują się następnie do numerów identyfikacyjnych w słowniku zamiast do oryginalnych wartości.
Po zakodowaniu dane segmentu mogą być dodatkowo skompresowane przy użyciu kodowania długości przebiegu (RLE) i pakowania bitów:
RLE zastępuje powtarzające się elementy danymi i liczbę powtórzeń, na przykład {1, 1, 1, 1, 1, 2, 2, 2} można zastąpić {5×1, 3×2}. Oszczędność miejsca RLE wzrasta wraz z długością powtarzających się przebiegów. Krótkie serie mogą przynieść efekt przeciwny do zamierzonego.
Pakowanie bitów przechowuje binarną formę danych w tak wąskim, wspólnym oknie, jak to tylko możliwe. Na przykład liczby {7, 9, 15} są przechowywane w postaci binarnych (jednobajtowych dla spacji) liczb całkowitych jako {00000111, 00001001, 00001111}. Pakowanie tych bitów w ustalone czterobitowe okno daje strumień {011110011111}. Wiedząc, że istnieje stały rozmiar okna, nie ma potrzeby stosowania ogranicznika.
Kodowanie i kompresja to oddzielne kroki, więc RLE i bit-packing są stosowane do wyniku kodowania wartości lub kodowania słownikowego surowych danych. Ponadto dane w tym samym segmencie kolumny mogą mieć mieszankę kompresji RLE i bit-packing. Skompresowane dane RLE nazywają się czystymi , a spakowane bitami skompresowane dane są nazywane nieczystymi . Segment kolumny może zawierać zarówno dane czyste, jak i nieczyste.
Oszczędność miejsca, którą można osiągnąć dzięki kodowaniu i kompresji, może zależeć od zamówienia. Wszystkie segmenty kolumn w grupie wierszy muszą być niejawnie posortowane w ten sam sposób, aby SQL Server mógł wydajnie zrekonstruować pełne wiersze z segmentów kolumn. Wiedząc, że wiersz 123 jest przechowywany na tej samej pozycji (123) w każdym segmencie kolumny oznacza, że numer wiersza nie musi być przechowywany.
Jedną wadą tego rozwiązania jest to, że powszechna kolejność sortowania należy wybrać dla wszystkich segmentów kolumn w grupie wierszy. Określona kolejność może bardzo dobrze pasować do jednej kolumny, ale tracić znaczące możliwości w innych kolumnach. Najwyraźniej dotyczy to kompresji RLE. SQL Server wykorzystuje technologię Vertipaq do określenia dobrego sposobu sortowania kolumn w każdej grupie wierszy, aby uzyskać dobry ogólny wynik kompresji.
SQL Server obecnie używa tylko RLE w segmencie kolumny, gdy jest co najmniej 64 ciągłe powtarzające się wartości. Pozostałe wartości w segmencie są upakowane bitami. Jak wspomniano, to, czy powtarzające się wartości pojawiają się jako ciągłe w segmencie kolumny, zależy od kolejności wybranej dla grupy wierszy.
SQL Server obsługuje wyspecjalizowaną kartę SIMD rozpakowywanie bitów dla szerokości bitów od 1 do 10 włącznie, 12 i 21 bitów. SQL Server może również używać standardowych rozmiarów liczb całkowitych, np. 16, 32 i 64 bity z pakietem bitowym. Te liczby zostały wybrane, ponieważ ładnie pasują w jednostce 64-bitowej. Na przykład jedna jednostka może pomieścić trzy podjednostki 21-bitowe lub 5 podjednostek 12-bitowych. SQL Server nie przekroczyć granicę 64-bitową podczas pakowania bitów.
SIMD używa rejestrów 256-bitowych, gdy procesor obsługuje instrukcje AVX2, oraz rejestrów 128-bitowych, gdy dostępne są instrukcje SSE4.2. W przeciwnym razie można użyć rozpakowywania bez karty SIM.
Zgrupowane zagregowane warunki pushdown
Większość planów z agregatem Hash Match operator bezpośrednio nad skanowaniem kolumn operator potencjalnie zakwalifikuje się do grupowego zagregowania pushdown, z zastrzeżeniem ogólnych warunków podanych w dokumentacji.
Czasami można również dodać dodatkowe filtry i wyrażenia, nie uniemożliwiając grupowego agregacji pushdown. Ogólna zasada jest taka, że filtr lub wyrażenie musi być również w stanie przesunąć w dół (chociaż zgodne wyrażenia mogą nadal pojawiać się w oddzielnym Scalar obliczeniowym ). Jak wspomniano we wstępie, aspekty te mogą być szczegółowo omówione w osobnych artykułach.
Obecnie w planach wykonania nie ma nic, co wskazywałoby, czy określony agregat został uznany za ogólnie zgodny ze zgrupowanym zagregowanym pushdownem lub nie. Mimo to, gdy plan ogólnie się kwalifikuje dla zgrupowanego agregowanego pushdown, dostępne są zarówno ścieżki kodu pushdown (szybkie), jak i niespychające (wolne).
Każda partia danych wyjściowych skanowania (do 900 wierszy) podejmuje decyzję w czasie wykonywania między szybką i wolną ścieżką kodu. Ta elastyczność pozwala jak największej liczbie partii skorzystać z pushdown. W najgorszym przypadku żadne partie nie będą korzystać z szybkiej ścieżki w czasie wykonywania, pomimo planu „ogólnie zgodnego”.
Plan wykonania pokazuje wynik szybkiego przetwarzania pushdown jako „wiersze agregowane lokalnie” bez odpowiedniego wyniku w wierszu ze skanowania. Partie o wolnej ścieżce pojawiają się jak zwykle jako wiersze wyjściowe ze skanowania magazynu kolumn, a agregacja jest wykonywana przez oddzielny operator zamiast podczas skanowania.
Pojedyncza zgrupowana kombinacja agregacji i skanowania może wysłać niektóre partie na szybką ścieżkę, a niektóre na powolną ścieżkę, więc jest całkowicie możliwe, aby zobaczyć niektóre, ale nie wszystkie, wiersze zagregowane lokalnie. Po pomyślnym przejściu grupowania agregacji każda partia wyjściowa ze skanowania zawiera klucze grupowania i częściową agregację reprezentującą wiersze, które przyczyniają się.
Szczegółowe kontrole
Istnieje kilka testów środowiska wykonawczego, które pozwalają określić, czy można użyć przetwarzania pushdown. Wśród słabo udokumentowanych kontroli są:
- Nie może być możliwości zagregowania przepełnienia .
- Wszelkie nieczyste (pakowane bitami) klucze grupujące musi być nie szerszy niż 10 bitów . Czyste (zakodowane w RLE) klucze grupujące są traktowane jako mające nieczystą szerokość równą zero, więc zazwyczaj stwarzają niewiele przeszkód.
- Przetwarzanie pushdown musi nadal być uważane za wartościowe , używając „miar korzyści” aktualizowanych na końcu każdej partii wyjściowej.
Możliwość zagregowanego przepełnienia jest oceniany zachowawczo dla każdej partii w oparciu o typ agregatu, typ danych wynikowych, bieżące wartości częściowej agregacji oraz informacje o danych wejściowych. Na przykład SQL Server zna minimalne i maksymalne wartości z metadanych segmentu, które są widoczne w DMV sys.column_store_segments . Tam, gdzie istnieje ryzyko przepełnienia, partia użyje przetwarzania wolnej ścieżki. Jest to głównie ryzyko dla SUM agregat.
Ograniczenie nieczystej szerokości klucza grupowania warto podkreślić. Dotyczy to tylko kolumn w GROUP BY klauzule faktycznie wykorzystywane w planie wykonawczym jako podstawa grupowania. Te zestawy nie zawsze są dokładnie takie same, ponieważ optymalizator może swobodnie usuwać nadmiarowe kolumny grupujące lub w inny sposób przepisywać agregacje, o ile ostateczne wyniki zapytania są zgodne z oryginalną specyfikacją zapytania. W przypadku rozbieżności znaczenie mają kolumny grupujące pokazane w planie wykonania.
Większą trudnością jest wiedza, czy któraś z kolumn grupujących jest przechowywana przy użyciu pakowania bitów, a jeśli tak, to jaka szerokość została użyta. Przydałoby się również wiedzieć, ile wartości zostało zakodowanych przy użyciu RLE. Te informacje mogą znajdować się w column_store_segments DMV, ale dzisiaj tak nie jest. O ile mi wiadomo, nie ma obecnie udokumentowanego sposobu na uzyskanie informacji o pakowaniu bitów i RLE z metadanych. To pozostawia nam szukanie nieudokumentowanych alternatyw.
Znajdowanie informacji o RLE i pakietach bitowych
Nieudokumentowany DBCC CSINDEX może udzielić nam potrzebnych informacji. Aby to polecenie generowało dane wyjściowe na karcie wiadomości SSMS, musi być włączona flaga śledzenia 3604. Biorąc pod uwagę informacje o interesującym nas segmencie kolumny, to polecenie zwraca:
- Atrybuty segmentu (podobne do
column_store_segments) - Informacje RLE
- Zakładki do danych RLE
- Informacje o pakietach bitowych
Ponieważ nie jest to udokumentowane, istnieje kilka dziwactw (takich jak konieczność dodania jednego do identyfikatorów kolumn dla klastrowanego magazynu kolumn, ale nie nieklastrowanego magazynu kolumn), a nawet kilka drobnych błędów. Nie należy go używać na niczym innym niż osobisty system testowy. Mamy nadzieję, że pewnego dnia zostanie udostępniona obsługiwana metoda dostępu do tych danych.
Przykłady
Najlepszy sposób na pokazanie DBCC CSINDEX i pokazać punkty poczynione do tej pory w tym tekście, to praca na kilku przykładach. Poniższe skrypty zakładają, że istnieje tabela o nazwie dbo.Numbers w aktualnej bazie danych zawierającej liczby całkowite od 1 do co najmniej 16 384. Oto skrypt do stworzenia mojej standardowej wersji tej tabeli z dziesięcioma milionami liczb całkowitych:
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
Wszystkie przykłady używają tej samej podstawowej tabeli testowej:Pierwsza kolumna c1 zawiera unikalny numer dla każdego wiersza. Druga kolumna c2 zawiera wiele duplikatów dla każdej z niewielkiej liczby odrębnych wartości.
Klastrowany indeks magazynu kolumn jest tworzony po wypełnieniu danych, dzięki czemu wszystkie dane testowe trafiają do jednej skompresowanej grupy wierszy (bez magazynu delta). Jest zbudowany zastępując indeks klastrowy b-drzewa w kolumnie c2 aby zachęcić algorytm VertiPaq do wczesnego rozważenia przydatności sortowania w tej kolumnie. To jest podstawowa konfiguracja testu:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
Dwie zmienne dotyczą liczby różnych wartości do wstawienia w kolumnie c2 i liczbę duplikatów dla każdej z tych wartości.
Zapytanie testowe to bardzo proste zgrupowane COUNT_BIG agregacja przy użyciu kolumny c2 jako klucz:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
Informacje o indeksie magazynu kolumn będą wyświetlane przy użyciu DBCC CSINDEX po każdym wykonaniu zapytania testowego:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); Testy zostały przeprowadzone na najnowszej wydanej wersji SQL Server dostępnej w momencie pisania:Microsoft SQL Server 2017 RTM-CU13-OD kompilacja 14.0.3049 Wersja programistyczna (64-bitowa) w systemie Windows 10 Pro. Wszystko powinno działać dobrze również w najnowszej wersji SQL Server 2016.
Test 1:Pushdown, 9-bitowe nieczyste klawisze
Ten test używa skryptu wypełniania danych testowych dokładnie tak, jak napisano powyżej, tworząc tabelę z 32 256 wierszami. Kolumna c1 zawiera liczby od 1 do 32 256.
Kolumna c2 zawiera 512 odrębnych wartości od 0 do 511 włącznie. Każda wartość w c2 jest duplikowany 63 razy , ale nie pojawiają się jako ciągłe bloki podczas przeglądania w c1 zamówienie; powtarzają się 63 razy przez wartości od 0 do 511.
Biorąc pod uwagę powyższą dyskusję, oczekujemy, że SQL Server będzie przechowywać c2 dane kolumny za pomocą:
- Kodowanie słownika ponieważ istnieje znaczna liczba zduplikowanych wartości.
- Brak RLE . Liczba duplikatów (63) na wartość nie osiąga progu 64 wymaganego dla RLE.
- Rozmiar opakowania bitów 9 . 512 odrębnych wpisów w słowniku zmieści się dokładnie w 9 bitach (2^9 =512). Każda jednostka 64-bitowa będzie zawierać do siedmiu podjednostek 9-bitowych.
Wszystko to zostało potwierdzone jako poprawne za pomocą DBCC CSINDEX zapytanie:
Atrybuty segmentu sekcja wyniku pokazuje kodowanie słownika (wpisz 2; wartości dla encodingType są zgodne z dokumentacją w sys.column_store_segments ).
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 Liczba wierszy =32256
Sekcja RLE pokazuje brak danych RLE , tylko wskaźnik do regionu upakowanego bitami i pusty wpis dla wartości zero:
Nagłówek RLE:
Typ płata =3 Liczba tablicy RLE (w jednostkach natywnych) =2
Rozmiar wpisu tablicy RLE =8
Dane RLE:
Indeks =0 Tablica Bitpack Indeks =0 Liczba =32256
Indeks =1 Wartość =0 Liczba =0
Nagłówek danych Bitpack sekcja pokazuje rozmiar pakietu bitów 9 i 4608 użytych jednostek bitpack:
Nagłówek danych pakietu bitowego:
Rozmiar wpisu pakietu bitowego =9 Liczba jednostek pakietu bitowego =4608 Pakiet bitów MinId =3
Bitpack DataSize =36864
Dane pakietu bitowego sekcja pokazuje wartości przechowywane w pierwszych dwóch jednostkach bitpack zgodnie z żądaniem dwóch ostatnich parametrów w DBCC CSINDEX Komenda. Przypomnijmy, że każda jednostka 64-bitowa może pomieścić 7 podjednostek (ponumerowanych od 0 do 6) po 9 bitów każda (7 x 9 =63 bity). Łącznie 4608 jednostek mieści 4608 * 7 =32 256 rzędów:
Jednostka 0 Podjednostka 0 =383
Jednostka 0 Podjednostka 1 =255
Jednostka 0 Podjednostka 2 =127
Jednostka 0 Podjednostka 3 =510
Jednostka 0 Podjednostka 4 =381
Jednostka 0 Podjednostka 5 =253
Jednostka 0 Podjednostka 6 =125
Jednostka 1 Podjednostka 0 =508
Jednostka 1 Podjednostka 1 =379
Jednostka 1 Podjednostka 2 =251
Jednostka 1 Podjednostka 3 =123
Jednostka 1 Podjednostka 4 =506
Jednostka 1 podjednostka 5 =377
Jednostka 1 podjednostka 6 =249
Ponieważ klucze grupujące używają pakowania bitów o rozmiarze mniejszym lub równym 10 , spodziewamy się zgrupowanego zagregowanego przesuwania w dół do pracy tutaj. Rzeczywiście, plan wykonania pokazuje, że wszystkie wiersze zostały zagregowane lokalnie podczas Skanowania indeksu kolumnowego operator:

Plik XML planu zawiera ActualLocallyAggregatedRows="32256" w informacjach o środowisku wykonawczym dla skanowania indeksu.
Test 2:Brak naciskania, 12-bitowe nieczyste klucze
Ten test zmienia @values parametr na 1025, zachowując @dupes w wieku 63 lat. Daje to tabelę 64 575 wierszy z 1025 odrębnymi wartościami w kolumnie c2 biegnie od 0 do 1024 włącznie. Każda wartość w c2 jest duplikowany 63 razy .
SQL Server przechowuje c2 dane kolumny za pomocą:
- Kodowanie słownika ponieważ istnieje znaczna liczba zduplikowanych wartości.
- Brak RLE . Liczba duplikatów (63) na wartość nie osiąga progu 64 wymaganego dla RLE.
- Napakowane bitami w rozmiarze 12 . 1025 odrębnych wpisów słownikowych nie mieści się w 10 bitach (2^10 =1024). Zmieściłyby się w 11 bitach, ale SQL Server nie obsługuje tego rozmiaru pakietu bitowego, jak wspomniano wcześniej. Następny najmniejszy rozmiar to 12 bitów. Używając jednostek 64-bitowych z twardymi obramowaniami do pakowania bitów, nie więcej podjednostek 11-bitowych nie zmieściłoby się w 64 bitach niż podjednostki 12-bitowe. Tak czy inaczej, 5 podjednostek zmieści się w jednostce 64-bitowej.
DBCC CSINDEX dane wyjściowe potwierdzają powyższą analizę:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 Liczba wierszy =64575
Nagłówek RLE:
Typ płata =3 Liczba tablicy RLE (w jednostkach natywnych) =2
Rozmiar wpisu tablicy RLE =8
Dane RLE:
Indeks =0 Bitpack Array Indeks =0 Liczba =64575
Indeks =1 Wartość =0 Liczba =0
Nagłówek danych pakietu bitowego:
Rozmiar wpisu Bitpack =12 Liczba jednostek Bitpack =12915 Bitpack MinId =3
Bitpack DataSize =103320
Dane pakietu Bitpack:
Jednostka 0 Podjednostka 0 =767
Jednostka 0 Podjednostka 1 =510
Jednostka 0 Podjednostka 2 =254
Jednostka 0 Podjednostka 3 =1021
Jednostka 0 Podjednostka 4 =765
Jednostka 1 Jednostka podrzędna 0 =507
Jednostka 1 Jednostka podrzędna 1 =250
Jednostka 1 Jednostka podrzędna 2 =1019
Jednostka 1 Jednostka podrzędna 3 =761
Jednostka 1 Jednostka podrzędna 4 =505
Od nieczystego klawisze grupujące mają rozmiar ponad 10 , spodziewamy się zgrupowanego zagregowanego przesuwania w dół nie pracować tutaj. Potwierdza to plan wykonania pokazujący zero wierszy agregowanych lokalnie w Skanowaniu indeksu kolumn operator:
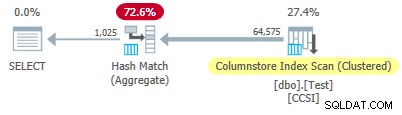
Wszystkie 64 575 wierszy jest emitowanych (w partiach) przez Skanowanie indeksu kolumn i agregowane w trybie wsadowym przez Hash Match Aggregate operator. ActualLocallyAggregatedRows brakuje atrybutu w informacjach o czasie wykonywania planu XML dla skanowania indeksu.
Test 3:Pushdown, czyste klawisze
Ten test zmienia @dupes parametr od 63 do 64, aby umożliwić RLE. @values parametr zostaje zmieniony na 16 384 (maksymalna całkowita liczba wierszy, która nadal mieści się w pojedynczej grupie wierszy). Dokładna liczba wybrana dla @values nie jest ważne — chodzi o wygenerowanie 64 duplikatów każdej unikalnej wartości, aby można było użyć RLE.
SQL Server przechowuje c2 dane kolumny za pomocą:
- Kodowanie słownika ze względu na zduplikowane wartości.
- RLE. Używane dla każdej odrębnej wartości, ponieważ każda spełnia próg 64.
- Brak danych paczkowanych bitami . Gdyby istniał, użyłby rozmiaru 16. Rozmiar 12 nie jest wystarczająco duży (2^12 =4096 różnych wartości), a rozmiar 21 byłby marnotrawstwem. 16 384 różne wartości zmieściłyby się w 14 bitach, ale tak jak poprzednio, nie więcej z nich zmieści się w jednostce 64-bitowej niż w podjednostkach 16-bitowych.
DBCC CSINDEX dane wyjściowe potwierdzają powyższe (tylko kilka wpisów RLE i zakładek pokazanych ze względu na spację):
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 Liczba wierszy =1048576
Nagłówek RLE:
Typ płata =3 Liczba tablicy RLE (w jednostkach natywnych) =16385
Rozmiar wpisu tablicy RLE =8
Dane RLE:
Indeks =0 Wartość =3 Liczba =64
Indeks =1 Wartość =1538 Liczba =64
Indeks =2 Wartość =3072 Liczba =64
Indeks =3 Wartość =4608 Liczba =64
Indeks =4 Wartość =6142 Liczba =64
…
Indeks =16381 Wartość =8954 Liczba =64
Indeks =16382 Wartość =10489 Liczba =64
Indeks =16383 Wartość =12025 Liczba =64
Indeks =16384 Wartość =0 Liczba =0
Nagłówek zakładki:
Liczba zakładek =65 Odległość zakładek =16384 Rozmiar zakładek =520
Dane zakładek:
Pozycja =0 Indeks =64
Pozycja =512 Indeks =16448
Pozycja =1024 Indeks =32832
…
Pozycja =31744 Indeks =1015872
Pozycja =32256 Indeks =1032256
Pozycja =32768 Indeks =1048577
Nagłówek danych pakietu bitowego:
Rozmiar wpisu Bitpack =16 Liczba jednostek Bitpack =0 Bitpack MinId =3
Bitpack DataSize =0
Ponieważ klucze grupujące są czyste (używany jest RLE), zgrupowane zagregowane przesuwanie w dół oczekuje się tutaj. Plan wykonania potwierdza to, pokazując wszystkie wiersze zagregowane lokalnie w Skanowaniu indeksu kolumn operator:
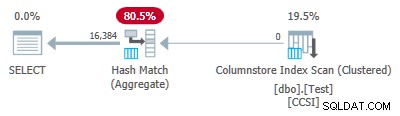
Plik XML planu zawiera ActualLocallyAggregatedRows="1048576" w informacjach o środowisku wykonawczym dla skanowania indeksu.
Test 4:10-bitowe nieczyste klucze
Ten test ustawia @values do 1024 i @dupes do 63, co daje tabelę 64 512 wierszy z 1024 różnymi wartościami w kolumnie c2 z wartościami od 0 do 1023 włącznie. Każda wartość w c2 jest duplikowany 63 razy .
Co najważniejsze , indeks klastrowy b-drzewa jest teraz tworzony w kolumnie c1 zamiast kolumny c2 . Klastrowany magazyn kolumn nadal zastępuje indeks klastrowany b-drzewa. To jest zmieniona część skryptu:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQL Server przechowuje c2 dane kolumny za pomocą:
- Kodowanie słownika z powodu duplikatów.
- Brak RLE . Liczba duplikatów (63) na wartość nie osiąga progu 64 wymaganego dla RLE.
- Pakowanie bitów w rozmiarze 10 . 1024 odrębnych wpisów w słowniku mieści się dokładnie w 10 bitach (2^10 =1024). Sześć podjednostek po 10 bitów każda może być przechowywanych w każdej jednostce 64-bitowej.
DBCC CSINDEX wyjście to:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 Liczba wierszy =64512
Nagłówek RLE:
Typ płata =3 Liczba tablicy RLE (w jednostkach natywnych) =2
Rozmiar wpisu tablicy RLE =8
Dane RLE:
Indeks =0 Bitpack Array Indeks =0 Liczba =64512
Indeks =1 Wartość =0 Liczba =0
Nagłówek danych pakietu bitowego:
Rozmiar wpisu pakietu bitowego =10 Liczba jednostek pakietu bitowego =10752 Pakiet bitów MinId =3
Rozmiar danych pakietu bitowego =86016
Dane pakietu bitowego:
Jednostka 0 Podjednostka 0 =766
Jednostka 0 Podjednostka 1 =509
Jednostka 0 Podjednostka 2 =254
Jednostka 0 Podjednostka 3 =1020
Jednostka 0 Podjednostka 4 =764
Jednostka 0 Podjednostka 5 =506
Jednostka 1 Podjednostka 0 =250
Jednostka 1 Podjednostka 1 =1018
Jednostka 1 Podjednostka 2 =760
Jednostka 1 Podjednostka 3 =504
Jednostka 1 Podjednostka 4 =247
Jednostka 1 Podjednostka 5 =1014
Od nieczystego klucze grupujące mają rozmiar mniejszy lub równy 10, spodziewalibyśmy się grupowanego agregowanego pushdown do pracy tutaj. Ale nie tak się dzieje . Plan wykonania pokazuje, że 54 612 z 64 512 wierszy zostało zagregowanych w Hash Match Aggregate operator:
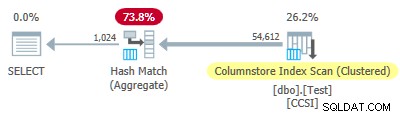
Plik XML planu zawiera ActualLocallyAggregatedRows="9900" w informacjach o środowisku wykonawczym dla skanowania indeksu. Oznacza to zgrupowane zagregowane przesuwanie w dół został użyty w 9900 rzędach, ale nie został użyty w pozostałych 54 612!
Mechanizm sprzężenia zwrotnego
SQL Server został uruchomiony przy użyciu grupowanego agregującego pushdown dla tego wykonania, ponieważ nieczyste klucze grupujące spełniają kryteria 10 bitów lub mniej. Trwało to łącznie 11 partii (każda po 900 rzędów =łącznie 9900 rzędów). W tym momencie mechanizm sprzężenia zwrotnego mierzący skuteczność zgrupowanego zagregowanego przesuwania w dół zdecydował, że to nie działa, i wyłączył go . Pozostałe partie zostały przetworzone z wyłączonym przesuwaniem w dół.
Informacje zwrotne zasadniczo porównują liczbę wierszy zagregowanych z liczbą utworzonych grup. Rozpoczyna się od wartości 100 i jest regulowana na końcu każdej partii wyjściowej pushdown. Jeśli wartość spadnie do 10 lub mniej, przesuwanie w dół jest wyłączone dla bieżącej operacji grupowania.
„Miara korzyści w dół” jest zmniejszana mniej więcej w zależności od tego, jak źle idzie wysiłek agregacji w dół. Jeśli w partii wyjściowej jest średnio mniej niż 8 wierszy na klucz grupowania, bieżąca wartość korzyści zostanie zmniejszona o 22%. Jeśli jest ich więcej niż 8, ale mniej niż 16, wskaźnik zmniejsza się o 11%.
Z drugiej strony, jeśli sytuacja się poprawi i 16 lub więcej wierszy na klucz grupowania zostanie później napotkanych dla wyjściowej partii, metryka zostanie zresetowana do 100 i będzie nadal dostosowywana, gdy skanowanie jest tworzone przez częściowe zagregowane partie.
Dane w tym teście zostały przedstawione w szczególnie nieprzydatnej kolejności do przesuwania ze względu na oryginalny indeks klastrowy b-drzewa w kolumnie c1 . Przedstawione w ten sposób wartości w kolumnie c2 zaczynają się od 0 i zwiększaj o 1, aż osiągną 1023, a następnie rozpoczynają cykl od nowa. 1023 różne wartości są więcej niż wystarczające, aby zapewnić, że każda 900-wierszowa partia wyjściowa zawiera tylko jeden częściowo zagregowany wiersz dla każdego klucza. To nie jest szczęśliwy stan.
Gdyby było 64 duplikatów na wartość zamiast 63, SQL Server rozważyłby sortowanie według c2 podczas budowania indeksu magazynu kolumn, co spowodowało kompresję RLE. W obecnej sytuacji 22% kary nalicza się po każdej partii. Zaczynając od 100 i używając tej samej arytmetyki zaokrąglania w górę, sekwencja wartości metryki wygląda następująco:
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
Jedenasta partia zmniejsza metrykę do 10 lub mniej, a przesuwanie w dół jest wyłączone. 11 partii po 900 wierszy stanowi 9900 wierszy agregowanych lokalnie pokazanych w planie wykonania.
Odmiana z 900 odrębnymi wartościami
To samo zachowanie można zaobserwować w teście 4 z zaledwie 901 odrębnymi wartościami, zakładając, że wiersze są prezentowane w tej samej nieprzydatnej kolejności.
Zmiana @values parametr na 900 przy zachowaniu wszystkich pozostałych parametrów ma dramatyczny wpływ na plan wykonania:
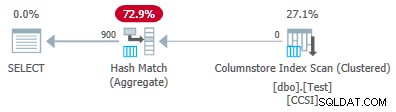
Teraz wszystkie 900 grup jest agregowanych podczas skanowania! Właściwości planu XML pokazują ActualLocallyAggregatedRows="56700" . Dzieje się tak, ponieważ zgrupowane agregowane pushdown utrzymuje 900 kluczy grupowania i częściowych agregacji w jednej partii. Nigdy nie napotyka nowej wartości klucza spoza partii, więc nie ma powodu, aby rozpocząć nową partię danych wyjściowych.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Uwaga: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.