Czy kiedykolwiek skontaktowałeś się z firmą Microsoft lub partnerem firmy Microsoft i rozmawiałeś z nimi o kosztach przejścia do chmury? Jeśli tak, być może słyszałeś o kalkulatorze jednostek DTU usługi Azure SQL Database, a także o tym, jak został on poddany inżynierii wstecznej przez Andy'ego Mallona. Kalkulator jednostek DTU to bezpłatne narzędzie, za pomocą którego można przesyłać metryki wydajności z serwera i używać danych do określania odpowiedniej warstwy usług w przypadku migracji tego serwera do bazy danych SQL Azure (lub do puli elastycznej bazy danych SQL).
Aby to zrobić, musisz zaplanować lub ręcznie uruchomić skrypt (wiersz poleceń lub Powershell, dostępny do pobrania na stronie kalkulatora DTU) w okresie typowego obciążenia produkcyjnego.
Jeśli próbujesz analizować duże środowisko lub chcesz analizować dane z określonych punktów w czasie, może to stać się uciążliwe. W wielu przypadkach wielu administratorów baz danych ma pewien rodzaj narzędzia do monitorowania, które już rejestruje dla nich dane dotyczące wydajności. W wielu przypadkach prawdopodobnie już przechwytuje potrzebne metryki lub można je łatwo skonfigurować do przechwytywania potrzebnych danych. Dzisiaj przyjrzymy się, jak wykorzystać SentryOne, abyśmy mogli dostarczyć odpowiednie dane do kalkulatora DTU.
Na początek spójrzmy na informacje pobierane przez narzędzie wiersza poleceń i skrypt PowerShell dostępne na stronie kalkulatora DTU; przechwytuje 4 liczniki monitorowania wydajności:
- Procesor – % czasu procesora
- Dysk logiczny — odczyty dysku/s
- Dysk logiczny — zapisy na dysku/s
- Baza danych – opróżnione bajty dziennika/s
Pierwszym krokiem jest określenie, czy te metryki zostały już przechwycone w ramach zbierania danych w SQL Sentry. Aby dowiedzieć się więcej, sugeruję przeczytanie tego wpisu na blogu autorstwa Jasona Halla, w którym opowiada on o tym, jak ułożone są dane i jak można je przeszukiwać. Nie będę tutaj omawiał każdego kroku, ale zachęcam do przeczytania i dodania zakładek do całej serii blogów.
Kiedy przejrzałem bazę danych SentryOne, odkryłem, że 3 z 4 liczników były już domyślnie przechwytywane. Brakowało tylko [Database – Log Bytes Flushed/sec] , więc musiałem móc to włączyć. Był inny post na blogu autorstwa Justina Randalla, który wyjaśnia, jak to zrobić.
W skrócie, możesz wysłać zapytanie do [PerformanceAnalysisCounter] tabela.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Zauważysz, że domyślnie [PerformanceAnalysisSampleIntervalID] jest ustawiony na 0 – oznacza to, że jest wyłączony. Aby to włączyć, musisz uruchomić następujące polecenie. Po prostu pobierz identyfikator z zapytania SELECT, które właśnie uruchomiłeś i użyj go w tej aktualizacji:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
Po uruchomieniu aktualizacji konieczne będzie ponowne uruchomienie usług monitorowania SentryOne odpowiednich dla tego celu, aby można było zebrać nowe dane licznika.
Zauważ, że ustawiłem [PerformanceAnalysisSampleIntervalID] do 1, aby dane były przechwytywane co 10 sekund, jednak można je przechwytywać rzadziej, aby zminimalizować rozmiar zebranych danych kosztem mniejszej dokładności. Zobacz [PerformanceAnalysisSampleInterval] tabela z listą wartości, których możesz użyć.
Nie oczekuj natychmiastowego napływu danych do tabel; zajmie to trochę czasu, zanim przejdzie przez system. Możesz sprawdzić populację za pomocą następującego zapytania:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
Po potwierdzeniu, że dane są wyświetlane, powinieneś mieć dane dla każdej metryki wymaganej przez kalkulator DTU, chociaż możesz poczekać, aż uzyskasz reprezentatywną próbkę z pełnego obciążenia lub cyklu biznesowego.
Jeśli przeczytasz wpis na blogu Jasona, zobaczysz, że dane są przechowywane w różnych tabelach zbiorczych, a każda z tych tabel zbiorczych ma różne współczynniki przechowywania. Wiele z nich jest niższych niż to, czego bym chciał, gdybym analizował obciążenia przez pewien czas. Chociaż można je zmienić, może to nie być najmądrzejszy sposób. Ponieważ to, co ci pokazuję, nie jest obsługiwane, możesz chcieć uniknąć zbytniego majstrowania przy ustawieniach SentryOne, ponieważ może to mieć negatywny wpływ na wydajność, rozwój lub jedno i drugie.
Aby to zrekompensować, stworzyłem skrypt, który pozwala mi wyodrębnić dane potrzebne do różnych tabel zbiorczych i przechowywać te dane we własnej lokalizacji, abym mógł kontrolować własne przechowywanie i nie zakłócać działania SentryOne.
TABELA:dbo.AzureDatabaseDTUData
Utworzyłem tabelę o nazwie [AzureDatabaseDTUData] i zapisał go w bazie danych SentryOne. Utworzona przeze mnie procedura automatycznie wygeneruje tę tabelę, jeśli nie istnieje, więc nie ma potrzeby robienia tego ręcznie, chyba że chcesz dostosować miejsce jej przechowywania. Możesz przechowywać to w osobnej bazie danych, jeśli chcesz, wystarczy edytować skrypt, aby to zrobić. Tabela wygląda tak:
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Procedura:dbo.Custom_CollectDTUDataForDevice
Jest to procedura składowana, której można użyć do jednoczesnego pobrania wszystkich danych specyficznych dla jednostki DTU (pod warunkiem, że licznik bajtów dziennika był zbierany przez wystarczającą ilość czasu) lub zaplanować okresowe dodawanie do zebranych danych do jesteś gotowy, aby przesłać dane wyjściowe do kalkulatora DTU. Podobnie jak w powyższej tabeli, procedura jest tworzona w bazie danych SentryOne, ale możesz ją łatwo utworzyć w innym miejscu, po prostu dodaj trzy- lub czteroczęściowe nazwy do odniesień do obiektów. Interfejs procedury wygląda następująco:
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Uwaga :Cała procedura jest trochę długa, więc jest dołączona do tego posta (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Istnieje kilka parametrów, których możesz użyć. Każdy ma wartość domyślną, więc nie musisz ich określać, jeśli zgadzasz się z wartościami domyślnymi.
- @Identyfikator urządzenia – Pozwala to określić, czy chcesz zbierać dane dla konkretnego serwera SQL, czy dla wszystkiego. Wartość domyślna to -1, co oznacza skopiowanie wszystkich obserwowanych serwerów SQL. Jeśli chcesz wyeksportować informacje tylko dla określonej instancji, znajdź
DeviceIDodpowiadający hostowi w[dbo].[Device]tabeli i przekaż tę wartość. Możesz przekazać tylko jeden@DeviceIDna raz, więc jeśli chcesz przejść przez zestaw serwerów, możesz wywołać procedurę wiele razy lub możesz zmodyfikować procedurę, aby obsługiwała zestaw urządzeń. - @DaysToPurge – To reprezentuje wiek, w którym chcesz usunąć dane. Wartość domyślna to 14 dni, co oznacza, że będziesz pobierać dane nie starsze niż 14 dni, a wszelkie dane starsze niż 14 dni w Twojej tabeli niestandardowej zostaną usunięte.
Pozostałe cztery parametry są dostępne w celu zabezpieczenia na przyszłość, na wypadek gdyby wyliczenia SentryOne dla identyfikatorów liczników kiedykolwiek się zmieniły.
Kilka uwag na temat scenariusza:
- Gdy dane są pobierane, pobiera maksymalną wartość z przyciętej minuty i eksportuje ją. Oznacza to, że na minutę przypada jedna wartość na metrykę, ale jest to maksymalna przechwycona wartość. Jest to ważne ze względu na sposób, w jaki dane muszą być prezentowane kalkulatorowi DTU.
- Przy pierwszym uruchomieniu eksportu może to potrwać trochę dłużej. Dzieje się tak, ponieważ pobiera wszystkie dane, które może na podstawie wartości parametrów. Po każdym kolejnym uruchomieniu jedyne wyodrębnione dane to to, co jest nowe od ostatniego uruchomienia, więc powinno być znacznie szybsze.
- Będziesz musiał zaplanować tę procedurę, aby działała zgodnie z harmonogramem, który wyprzedza proces oczyszczania SentryOne. To, co zrobiłem, to właśnie utworzyłem zadanie agenta SQL do uruchamiania co noc, które zbiera wszystkie nowe dane od poprzedniej nocy.
- Ponieważ proces czyszczenia w SentryOne może się różnić w zależności od metryki, możesz skończyć z wierszami w kopii, które nie zawierają wszystkich 4 liczników przez określony czas. Możesz chcieć rozpocząć analizę danych dopiero od momentu rozpoczęcia procesu ekstrakcji.
- Użyłem bloku kodu z istniejących procedur SentryOne, aby określić tabelę zbiorczą dla każdego licznika. Mogłem na stałe zakodować bieżące nazwy tabel, jednak używając metody SentryOne, powinna ona być kompatybilna w przód z wszelkimi zmianami we wbudowanych procesach rollup.
Gdy Twoje dane zostaną przeniesione do samodzielnej tabeli, możesz użyć zapytania PIVOT, aby przekształcić je w formę oczekiwaną przez kalkulator DTU.
Procedura:dbo.Custom_ExportDataForDTUCalculator
Stworzyłem kolejną procedurę wyodrębniania danych do formatu CSV. Dołączony jest również kod tej procedury (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Istnieją trzy parametry:
- @Identyfikator urządzenia – Smallint odpowiadający jednemu z urządzeń, które zbierasz i które chcesz przesłać do kalkulatora.
- @BeginTime – Datetime reprezentujący czas rozpoczęcia w czasie lokalnym; na przykład
'2018-12-04 05:47:00.000'. Procedura zostanie przetłumaczona na UTC. Jeśli zostanie pominięty, pobierze od najwcześniejszej wartości w tabeli. - @EndTime – Datetime reprezentujący czas zakończenia, ponownie w czasie lokalnym; na przykład
'2018-12-06 12:54:00.000'. Jeśli zostanie pominięty, zbierze do ostatniej wartości w tabeli.
Przykładowe wykonanie, aby pobrać wszystkie dane zebrane dla SQLInstanceA między 4 grudnia o 5:47 a 6 grudnia o 12:54.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Dane będą musiały zostać wyeksportowane do pliku CSV. Nie martw się o same dane; Upewniłem się, że wyprowadzam wyniki, aby w pliku csv nie było żadnych informacji identyfikujących serwer, tylko daty i dane.
Jeśli uruchomisz zapytanie w programie SSMS, możesz kliknąć prawym przyciskiem myszy i wyeksportować wyniki; jednak masz tutaj ograniczone możliwości i będziesz musiał manipulować danymi wyjściowymi, aby uzyskać format oczekiwany przez kalkulator DTU. (Spróbuj i daj mi znać, jeśli znajdziesz sposób, aby to zrobić.)
Polecam po prostu użyć kreatora eksportu wypiekanego w SSMS. Kliknij prawym przyciskiem myszy bazę danych i przejdź do Zadania -> Eksportuj dane. Jako źródło danych użyj „SQL Server Native Client” i skieruj go na swoją bazę danych SentryOne (lub gdziekolwiek masz przechowywaną kopię danych). Jako miejsce docelowe wybierz „Miejsce docelowe pliku płaskiego”. Przejdź do lokalizacji, nadaj plikowi nazwę i zapisz plik jako CSV.
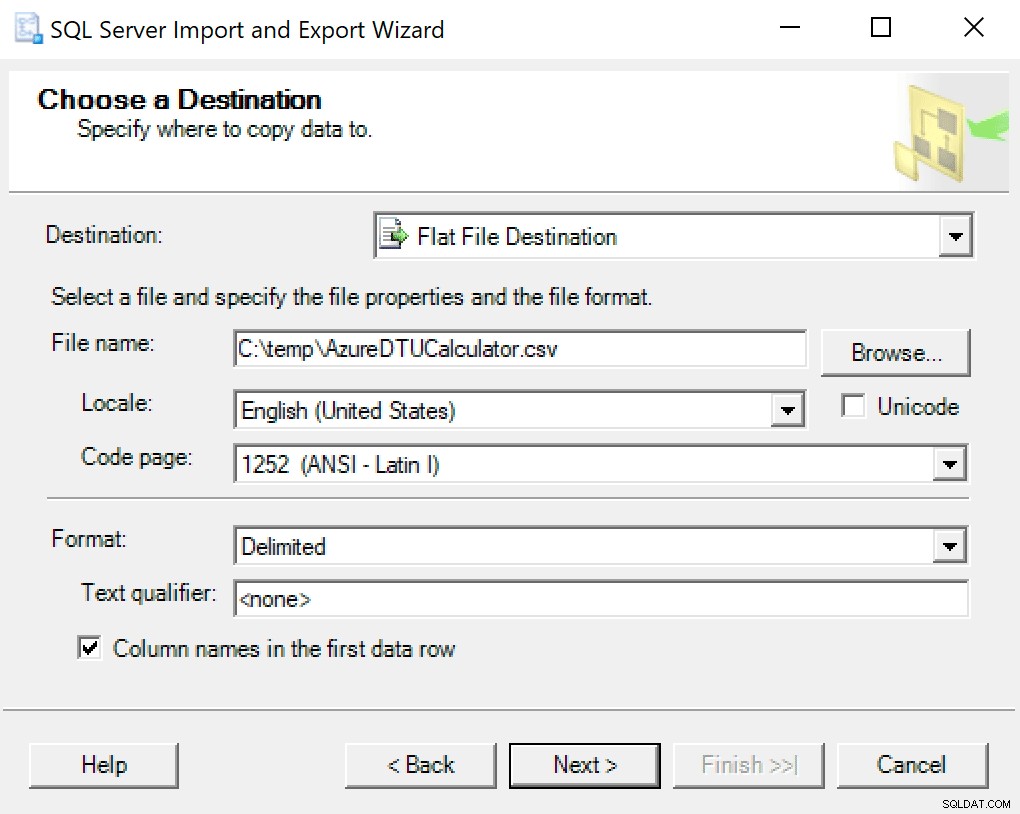
Uważaj, aby pozostawić stronę kodową w spokoju; niektóre mogą zwracać błędy. Wiem, że 1252 działa dobrze. Pozostałe wartości pozostaw domyślnie.
Na następnym ekranie wybierz opcję Napisz zapytanie, aby określić dane do przesłania .
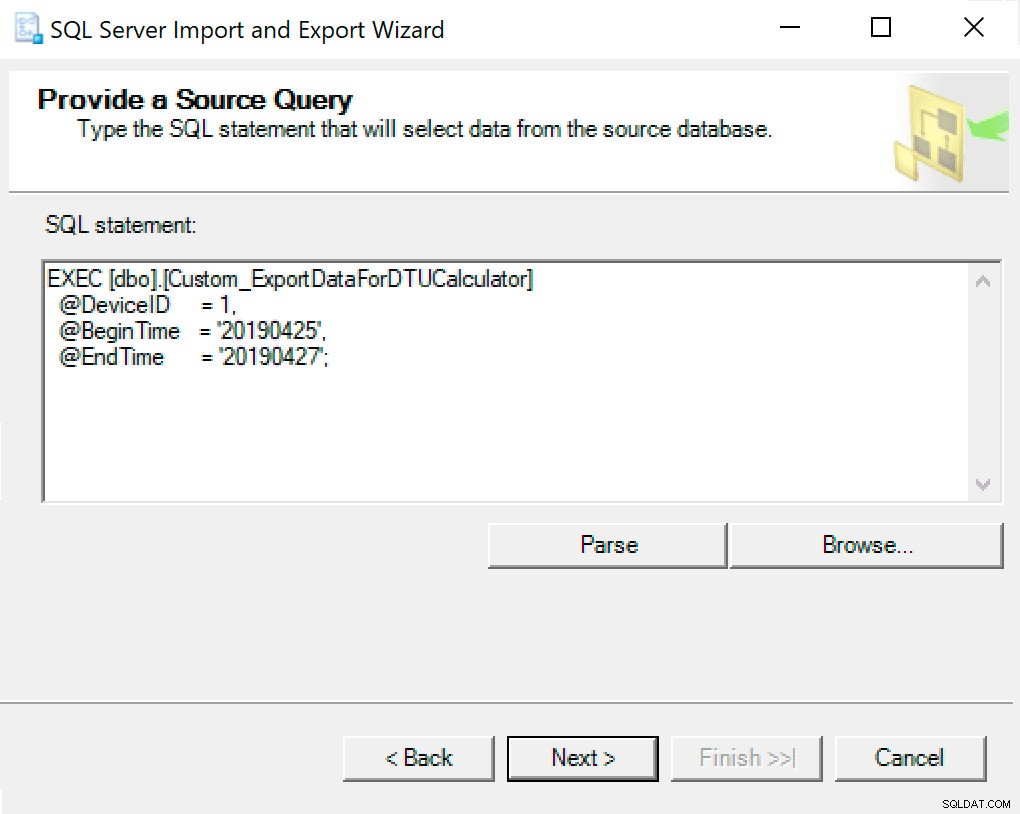
W następnym oknie skopiuj wywołanie procedury z ustawionymi w nim parametrami. Uderz dalej.
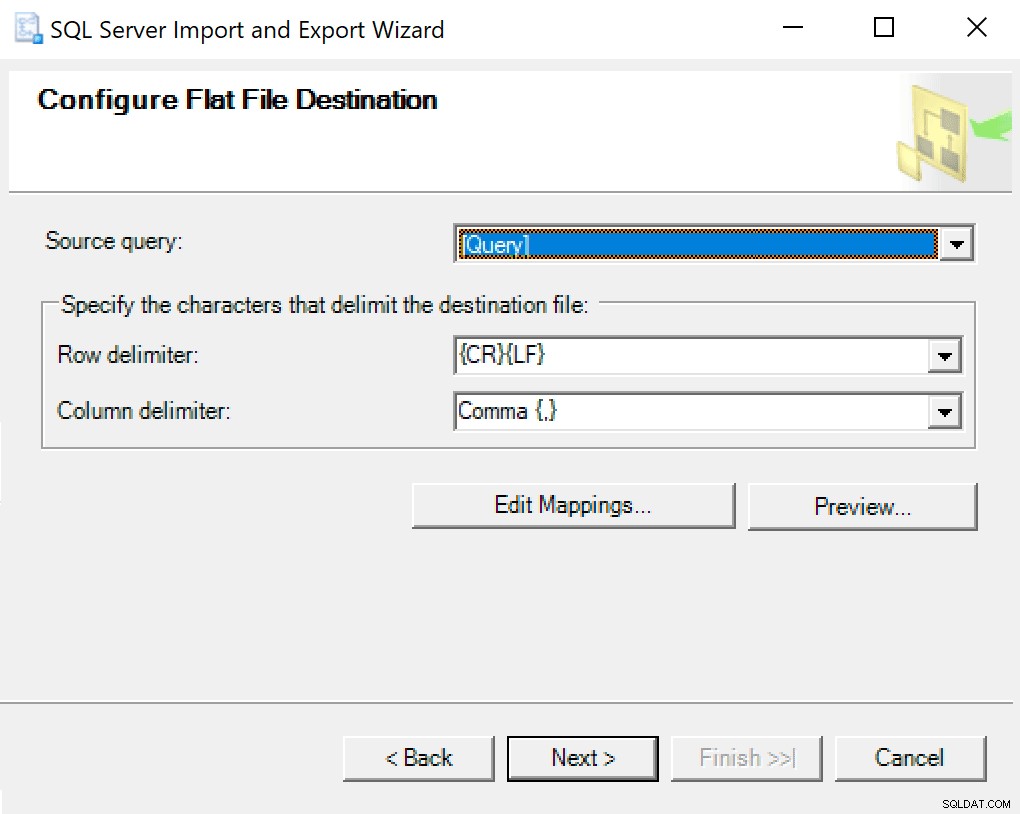
Kiedy dojdziesz do Konfiguruj miejsce docelowe pliku płaskiego, pozostawiam te opcje jako domyślne. Oto zrzut ekranu na wypadek, gdyby Twój był inny:
Uderz dalej i uruchom natychmiast. Zostanie utworzony plik, którego użyjesz w ostatnim kroku.
UWAGA :Możesz utworzyć pakiet SSIS do użycia w tym celu, a następnie przekazać wartości parametrów do pakietu SSIS, jeśli zamierzasz to robić często. Dzięki temu nie będziesz musiał przechodzić przez kreatora za każdym razem.
Przejdź do lokalizacji, w której zapisałeś plik i sprawdź, czy tam jest. Po otwarciu powinien wyglądać mniej więcej tak:
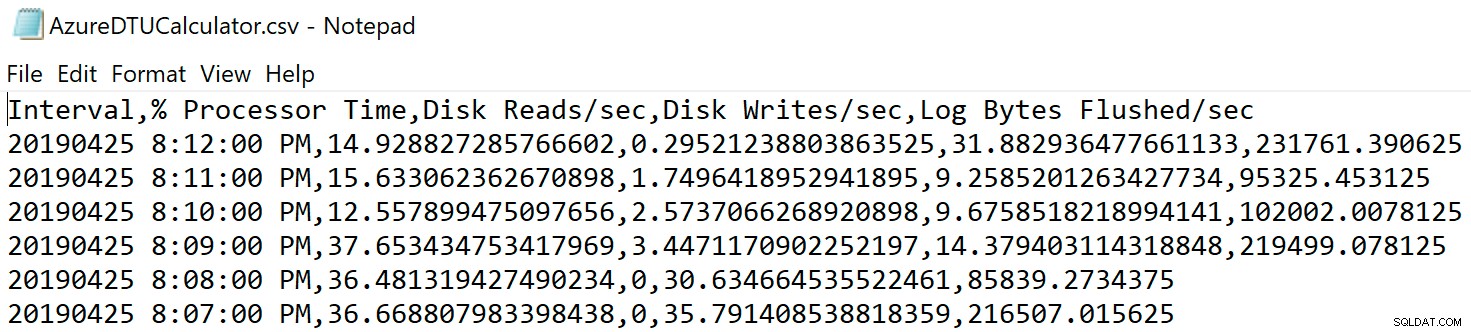
Otwórz witrynę internetową kalkulatora DTU i przewiń w dół do części „Prześlij plik CSV i oblicz”. Wprowadź liczbę rdzeni serwera, prześlij plik CSV i kliknij Oblicz. Otrzymasz taki zestaw wyników (kliknij dowolny obraz, aby powiększyć):
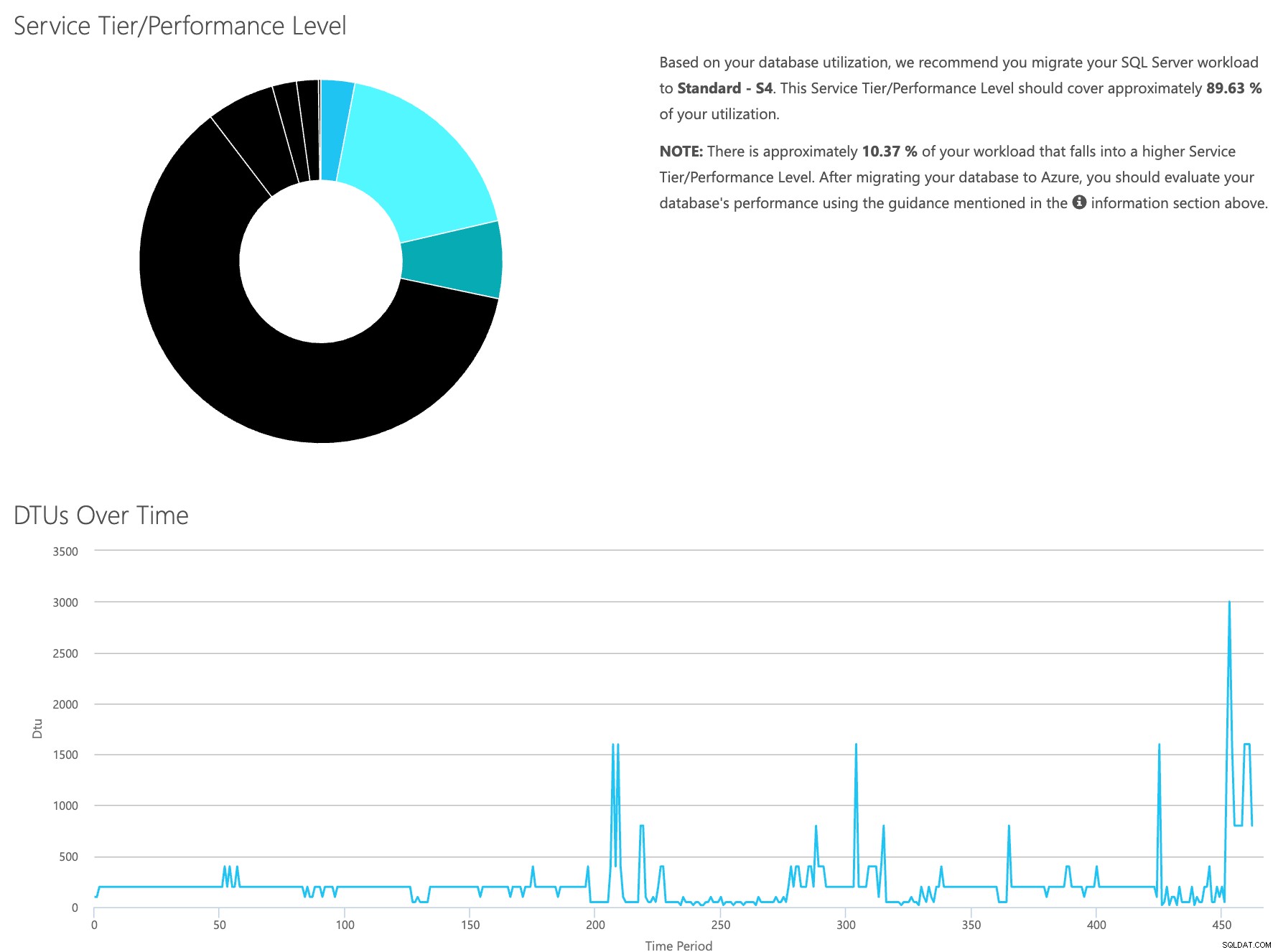
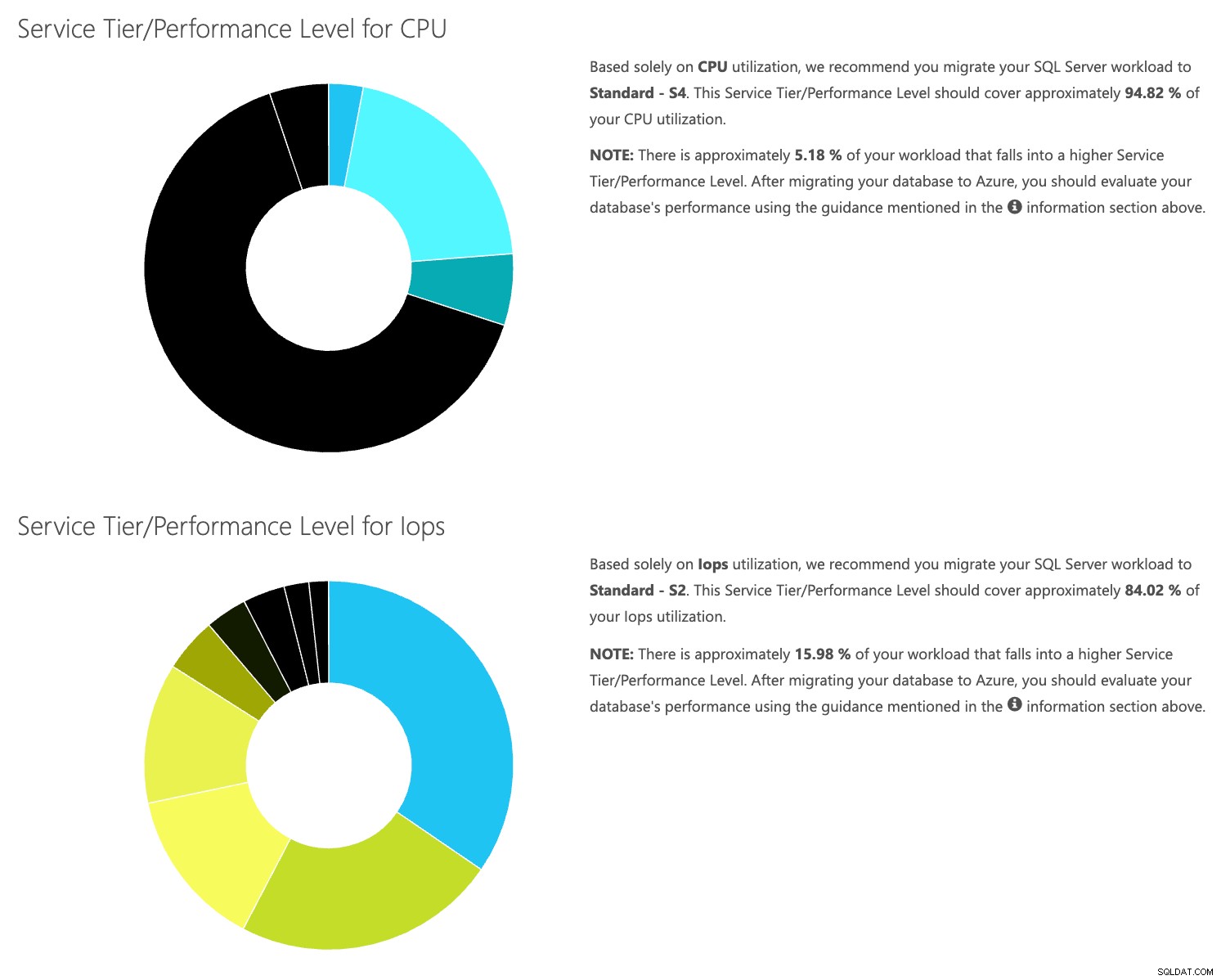
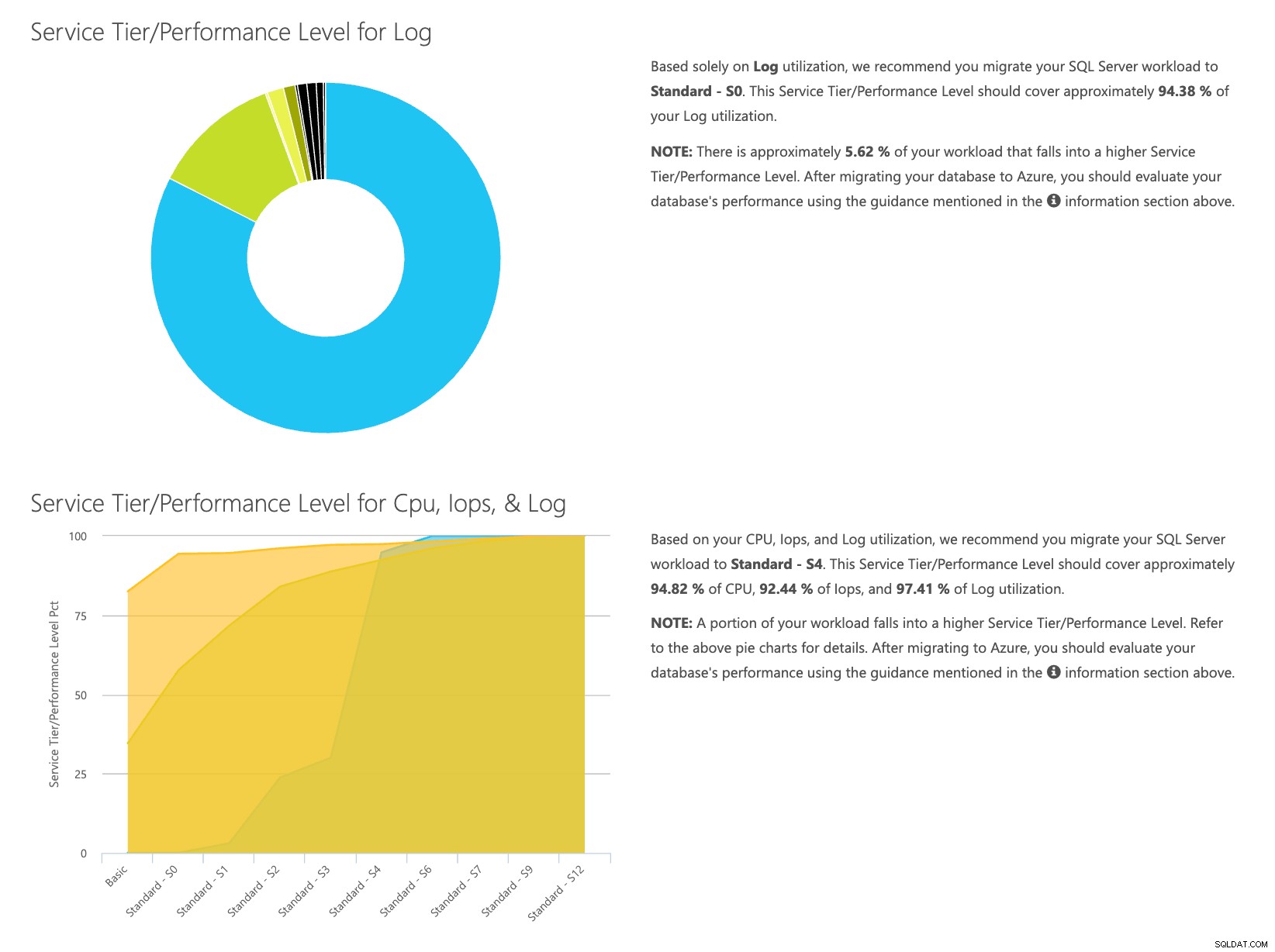
Ponieważ dane są przechowywane oddzielnie, możesz analizować obciążenia w różnym czasie i możesz to zrobić bez konieczności ręcznego uruchamiania\schedule polecenia \skryptu narzędzia\powershell dla dowolnego serwera, którego monitorujesz już za pomocą SentryOne.
Aby krótko podsumować kroki, oto, co należy zrobić:
- Włącz licznik [Baza danych – opróżnione dzienniki bajtów/s] i sprawdź, czy dane są zbierane
- Skopiuj dane z tabel SentryOne do swojej własnej tabeli (i zaplanuj to tam, gdzie to konieczne).
- Eksportuj dane z nowej tabeli w odpowiednim formacie dla kalkulatora DTU
- Prześlij plik CSV do kalkulatora DTU
W przypadku każdego serwera/instancji, które rozważasz migrację do chmury, i które obecnie monitorujesz za pomocą SQL Sentry, jest to stosunkowo bezbolesny sposób na oszacowanie zarówno rodzaju potrzebnej warstwy usług, jak i kosztu. Jednak nadal będziesz musiał to monitorować, gdy już tam będzie; w tym celu sprawdź SentryOne DB Sentry.
O autorze
 Dustin Dorsey jest obecnie inżynierem ds. zarządzania bazami danych w LifePoint Health, w którym kieruje zespołem odpowiedzialnym za zarządzanie i inżynierię rozwiązań w technologiach baz danych dla 90 szpitali. Od 2008 roku pracuje i wspiera SQL Server głównie w służbie zdrowia w zakresie administracji, architektury, rozwoju i BI. Pasjonuje go znajdowanie sposobów na rozwiązywanie problemów nękających codzienność DBA i uwielbia dzielić się tym z innymi. Można go spotkać przemawiającego na wydarzeniach społeczności SQL, a także blogującego na DustinDorsey.com.
Dustin Dorsey jest obecnie inżynierem ds. zarządzania bazami danych w LifePoint Health, w którym kieruje zespołem odpowiedzialnym za zarządzanie i inżynierię rozwiązań w technologiach baz danych dla 90 szpitali. Od 2008 roku pracuje i wspiera SQL Server głównie w służbie zdrowia w zakresie administracji, architektury, rozwoju i BI. Pasjonuje go znajdowanie sposobów na rozwiązywanie problemów nękających codzienność DBA i uwielbia dzielić się tym z innymi. Można go spotkać przemawiającego na wydarzeniach społeczności SQL, a także blogującego na DustinDorsey.com.