Wprowadzenie
Wydajne szpule to leniwe szpule dodane przez optymalizator w celu zmniejszenia szacowanego kosztu wewnętrznej strony połączeń zagnieżdżonych pętli . Występują w trzech odmianach:Lazy Table Spool , Leniwy bufor indeksu i Szpula z leniwym liczeniem wierszy . Poniżej znajduje się przykładowy kształt planu przedstawiający leniwy stół wydajnościowy:
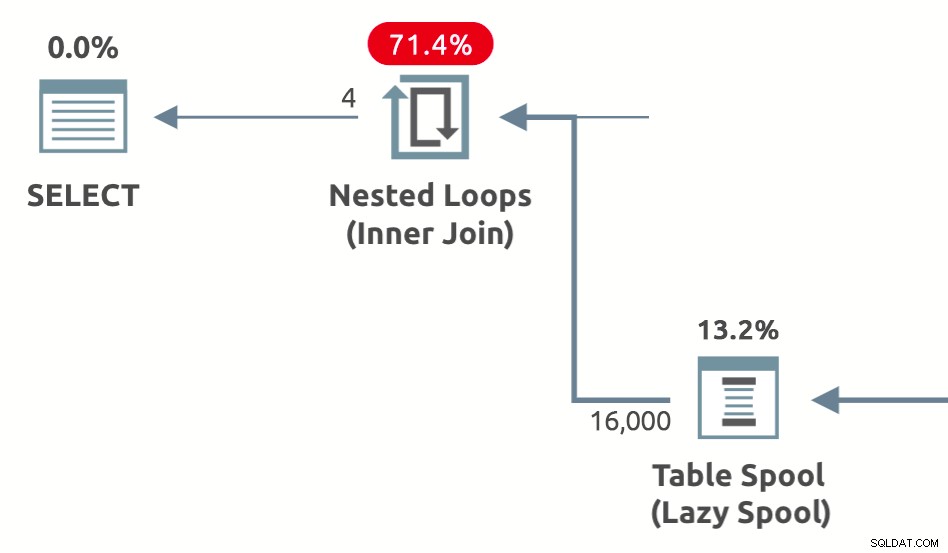
Pytania, na które chciałem odpowiedzieć w tym artykule, to dlaczego, jak i kiedy optymalizator zapytań wprowadza każdy typ buforowania wydajności.
Tuż przed rozpoczęciem chciałbym podkreślić ważną kwestię:w planach wykonania istnieją dwa różne typy sprzężeń zagnieżdżonych. Odniosę się do odmiany za pomocą odniesień zewnętrznych jako złóż wniosek i typ z predykatem złączenia na samym operatorze łączenia jako połączenia zagnieżdżonych pętli . Żeby było jasne, ta różnica dotyczy operatorów planu wykonania , a nie składnia zapytań T-SQL. Aby uzyskać więcej informacji, zobacz mój artykuł, do którego prowadzi link.
Szpule wydajności
Poniższy obrazek przedstawia szpulę wydajności Operatory planu wykonania wyświetlane w Eksploratorze planów (górny rząd) i SSMS 18.3 (dolny rząd):
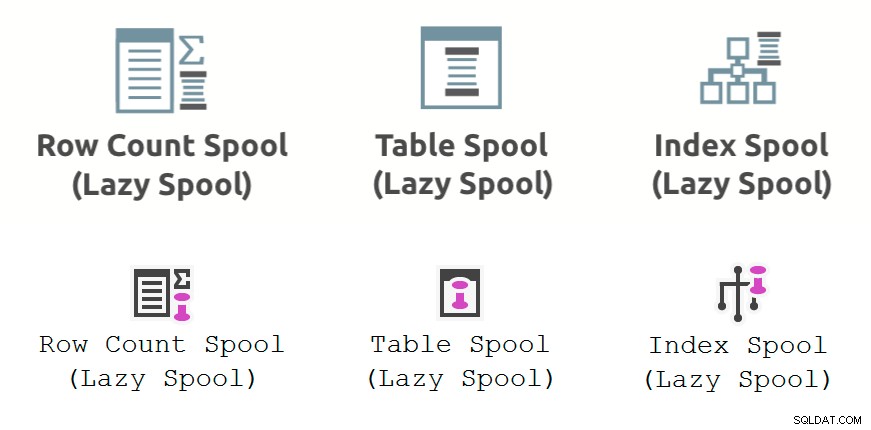
Uwagi ogólne
Wszystkie szpule wydajności są leniwi . Stół roboczy szpuli jest stopniowo zapełniany, wiersz po wierszu, gdy wiersze przepływają przez szpulę. (Z drugiej strony, gorliwe bufory zużywają wszystkie dane wejściowe z ich operatora podrzędnego przed zwróceniem jakichkolwiek wierszy do rodzica).
Szpule wydajności zawsze pojawiają się po wewnętrznej stronie (dolne wejście w graficznych planach wykonania) zagnieżdżonych pętli operatora join lub Apply. Ogólną ideą jest buforowanie i odtwarzanie wyników, zapisując powtarzające się wykonania operatorów wewnętrznych, gdy tylko jest to możliwe.
Gdy szpula jest w stanie odtworzyć wyniki z pamięci podręcznej, jest to znane jako przewijanie . Gdy spool musi wykonać swoje operatory podrzędne, aby uzyskać poprawne dane, ponownie powiąż wystąpi.
Pomocne może być wymyślenie szpuli ponownie jako brak pamięci podręcznej i przewijanie jako trafienie w pamięci podręcznej.
Szpula z leniwym stołem
Ten typ bufora wydajności może być używany zarówno z aplikacją i zagnieżdżone pętle łączą się .
Zastosuj
ponowne powiązanie (brak pamięci podręcznej) występuje, gdy odwołanie zewnętrzne zmiany wartości. Leniwa szpula stołu jest ponownie wiązana przez obcinanie jego stół roboczy i w pełni zapełnij go swoimi operatorami podrzędnymi.
przewiń (trafienie w pamięci podręcznej) występuje, gdy strona wewnętrzna wykonuje tak samo zewnętrzne wartości odniesienia jako bezpośrednio poprzedzające iteracja pętli. Przewijanie odtwarza buforowane wyniki ze stołu roboczego szpuli, oszczędzając koszt ponownego wykonania operatorów planu poniżej szpuli.
Uwaga:leniwa szpula tabeli buforuje wyniki tylko dla jednego zestawu zastosuj odniesienie zewnętrzne wartości na raz.
Połączenie zagnieżdżonych pętli
Bufor tabeli z opóźnieniem jest wypełniany raz podczas pierwszej iteracji pętli. Bufor przewija swoją zawartość dla każdej kolejnej iteracji złączenia. W przypadku złączenia zagnieżdżonych pętli wewnętrzna strona złączenia jest statycznym zestawem wierszy, ponieważ predykat złączenia znajduje się na samym złączeniu. Statyczny zestaw rzędów po wewnętrznej stronie można zatem wielokrotnie buforować i ponownie wykorzystywać za pośrednictwem szpuli. Zagnieżdżone pętle łączą się ze szpulą wydajności nigdy nie zmienia się ponownie.
Szpula z leniwym liczeniem rzędów
Szpula z liczbą wierszy to niewiele więcej niż bufora tabeli bez kolumn. Buforuje istnienie wiersza, ale nie wyświetla danych kolumn. Oprócz odnotowania jego istnienia i wzmianki, że może być wskazaniem błędu w zapytaniu źródłowym, nie będę miał więcej do powiedzenia na temat buforowania liczby wierszy.
Od tego momentu, za każdym razem, gdy zobaczysz w tekście „buforowanie tabeli”, przeczytaj go jako „buforowanie tabeli (lub liczby wierszy)”, ponieważ są one tak podobne.
Leniwa szpula indeksu
Leniwa szpula indeksu operator jest dostępny tylko z zastosowaniem .
Bufor indeksu utrzymuje tabelę roboczą, która nie jest obcinana kiedy odniesienie zewnętrzne wartości się zmieniają. Zamiast tego do istniejącej pamięci podręcznej dodawane są nowe dane, indeksowane przez zewnętrzne wartości referencyjne. Lazy index spool różni się od leniwej szpuli tabeli tym, że może odtwarzać wyniki z dowolnego poprzednia iteracja pętli, a nie tylko ostatnia.
Następny krok w zrozumieniu, kiedy bufory wydajności pojawiają się w planach wykonania, wymaga zrozumienia, jak działa optymalizator.
Tło Optymalizatora
Zapytanie źródłowe jest konwertowane na logiczną reprezentację drzewa przez analizowanie, algebraizację, uproszczenie i normalizację. Gdy powstałe drzewo nie kwalifikuje się do trywialnego planu, optymalizator oparty na kosztach szuka logicznych alternatyw, które gwarantują te same wyniki, ale przy niższym szacowanym koszcie.
Gdy optymalizator wygeneruje potencjalne alternatywy, wdraża każdą z nich przy użyciu odpowiednich operatorów fizycznych i oblicza szacunkowe koszty. Ostateczny plan wykonania jest budowany na podstawie najniższej opcji kosztowej znalezionej dla każdej grupy operatorów. Więcej szczegółów na temat tego procesu można znaleźć w mojej serii Query Optimizer Deep Dive.
Ogólne warunki niezbędne do pojawienia się buforu wydajności w ostatecznym planie optymalizatora to:
- Optymalizator musi badać logiczna alternatywa zawierająca logiczną szpulę w wygenerowanym zamienniku. Jest to bardziej skomplikowane, niż się wydaje, więc rozpakuję szczegóły w następnej głównej sekcji.
- Bufora logiczna musi być możliwa do wdrożenia jako fizyczna szpula operator w silniku wykonawczym. W przypadku nowoczesnych wersji SQL Server oznacza to zasadniczo, że wszystkie kluczowe kolumny w buforze indeksu muszą być porównywalne typ, łącznie nie więcej niż 900 bajtów*, z 64 kolumnami kluczy lub mniej.
- Najlepsze kompletny plan po optymalizacji opartej na kosztach musi zawierać jedną z alternatyw buforowania. Innymi słowy, wszelkie wybory oparte na kosztach dokonywane między opcjami szpulowania i bez szpulowania muszą wychodzić na korzyść szpuli.
* Ta wartość jest zakodowana na stałe w SQL Server i nie została zmieniona po zwiększeniu do 1700 bajtów dla nieklastrowanego klucze indeksu od SQL Server 2016 i nowsze. Dzieje się tak, ponieważ indeks buforu jest zgrupowany indeks, a nie indeks nieklastrowany.
Zasady Optymalizatora
Nie możemy określić bufora za pomocą T-SQL, więc umieszczenie go w planie wykonania oznacza, że optymalizator musi go dodać. W pierwszym kroku oznacza to, że optymalizator musi uwzględnić buforowanie logiczne w jednej z alternatyw, które wybiera do eksploracji.
Optymalizator nie stosuje w sposób wyczerpujący wszystkich znanych mu reguł logicznej równoważności do każdego drzewa zapytań. Byłoby to marnotrawstwem, biorąc pod uwagę cel optymalizatora, jakim jest szybkie stworzenie rozsądnego planu. Jest na to wiele aspektów. Po pierwsze, optymalizator działa etapami, najpierw wypróbowując tańsze i częściej stosowane reguły. Jeśli rozsądny plan zostanie znaleziony na wczesnym etapie lub zapytanie nie kwalifikuje się do późniejszych etapów, optymalizacja może zakończyć się przedwcześnie z planem o najniższym koszcie znalezionym do tej pory. Ta strategia pomaga zapobiegać spędzaniu więcej czasu na optymalizacji, niż można zaoszczędzić dzięki stopniowej poprawie kosztów.
Dopasowanie reguł
Każdy operator logiczny w drzewie zapytań jest szybko sprawdzany pod kątem dopasowania wzorca do reguł dostępnych na bieżącym etapie optymalizacji. Na przykład każda reguła będzie pasować tylko do podzbioru operatorów logicznych i może również wymagać wprowadzenia określonych właściwości, takich jak gwarantowane posortowane dane wejściowe. Reguła może odpowiadać pojedynczej operacji logicznej (pojedyncza grupa) lub wielu sąsiadujących ze sobą grupach (podsekcja planu).
Po dopasowaniu reguła kandydata jest proszona o wygenerowanie wartości obietnicy . Jest to liczba reprezentująca prawdopodobieństwo, że aktualna reguła przyniesie użyteczny wynik, biorąc pod uwagę kontekst lokalny. Na przykład reguła może generować wyższą wartość obietnicy, gdy obiekt docelowy ma wiele duplikatów na danych wejściowych, dużą szacowaną liczbę wierszy, gwarantowane posortowane dane wejściowe lub inną pożądaną właściwość.
Po zidentyfikowaniu obiecujących reguł eksploracji optymalizator sortuje je w kolejności wartości obietnicy i zaczyna prosić o wygenerowanie nowych logicznych substytutów. Każda reguła może generować jeden lub więcej substytutów, które później zostaną zaimplementowane za pomocą operatorów fizycznych. W ramach tego procesu obliczany jest szacunkowy koszt.
Chodzi o to, że ma to zastosowanie do buforowania wydajności, ponieważ logiczny kształt i właściwości planu muszą sprzyjać dopasowaniu reguł obsługujących buforowanie, a kontekst lokalny musi generować wystarczająco wysoką wartość obietnicy, aby optymalizator zdecydował się generować substytuty za pomocą reguły .
Zasady buforowania
Istnieje wiele reguł, które badają logiczne połączenia zagnieżdżonych pętli lub zastosuj alternatywy. Niektóre z tych zasad mogą generować jeden lub więcej substytutów z określonym typem szpuli wydajności. Inne reguły, które pasują do łączenia lub stosowania zagnieżdżonych pętli, nigdy nie generują alternatywy buforowania.
Na przykład reguła ApplyToNL implementuje logiczne zastosuj jako fizyczne pętle łączą się z zewnętrznymi odniesieniami. Ta reguła może generować kilka alternatyw za każdym razem, gdy działa. Oprócz operatora łączenia fizycznego, każdy substytut może zawierać leniwą kolejkę tabeli, leniwą kolejkę indeksową lub w ogóle brak buforowania. Logiczne substytuty buforowania są później indywidualnie implementowane i wyceniane jako odpowiednio wpisane fizyczne bufory, zgodnie z inną regułą o nazwie BuildSpool .
Jako drugi przykład, reguła JNtoIdxLookup implementuje sprzężenie logiczne jako fizyczne zastosowanie , z indeksem szukaj natychmiast po wewnętrznej stronie. Ta zasada nigdy generuje alternatywę z komponentem buforowym. JNtoIdxLookup jest oceniany wcześnie i zwraca wysoką wartość obietnicy, gdy pasuje, dzięki czemu proste plany wyszukiwania indeksów są szybko znajdowane.
Gdy optymalizator na wczesnym etapie znajdzie tanią alternatywę, bardziej złożone alternatywy mogą zostać agresywnie usunięte lub całkowicie pominięte. Rozumowanie jest takie, że nie ma sensu poszukiwanie opcji, które prawdopodobnie nie poprawią się w porównaniu z już znalezioną alternatywą o niskich kosztach. Podobnie, nie warto dalej badać, jeśli obecny najlepszy kompletny plan ma już wystarczająco niski całkowity koszt.
Trzeci przykład reguły:Reguła JNtoNL jest podobny do ApplyToNL , ale implementuje tylko fizyczne zagnieżdżone łączenie pętli , z leniwą szpulą stołową lub w ogóle bez szpuli. Ta zasada nigdy generuje bufor indeksu, ponieważ ten typ bufora wymaga zastosowania.
Generowanie bufora i kalkulacja kosztów
Reguła, która jest możliwa generowanie bufora logicznego niekoniecznie spowoduje to za każdym razem, gdy zostanie wywołane. Marnotrawstwem byłoby generowanie logicznych alternatyw, które nie mają prawie żadnych szans na wybranie jako najtańsze. Istnieje również koszt generowania nowych alternatyw, które z kolei mogą wytworzyć jeszcze więcej alternatyw — z których każda może wymagać wdrożenia i kosztorysowania.
Aby temu zaradzić, optymalizator implementuje wspólną logikę dla wszystkich reguł obsługujących buforowanie, aby określić, jaki typ alternatywy buforowania ma zostać wygenerowany na podstawie warunków planu lokalnego.
Łączenie zagnieżdżonych pętli
Dla połączenia zagnieżdżonych pętli , szansa na uzyskanie leniwej szpuli stołu wzrasta zgodnie z:
- Szacowana liczba wierszy na zewnętrznym wejściu złączenia.
- Szacowany koszt operatorów planu wewnętrznego.
Koszt szpuli jest spłacany przez oszczędności poczynione dzięki uniknięciu wykonywania operacji przez operatorów wewnętrznych. Oszczędności rosną wraz z większą liczbą iteracji wewnętrznych i wyższym kosztem po stronie wewnętrznej. Jest to szczególnie ważne, ponieważ model kosztów przypisuje stosunkowo niskie liczby we/wy i kosztu procesora do przewijania bufora tabeli (trafień w pamięci podręcznej). Pamiętaj, że szpula tabeli w zagnieżdżonych pętlach zawsze doświadcza tylko przewinień, ponieważ brak parametrów oznacza, że zestaw danych po wewnętrznej stronie jest statyczny.
Szpula może przechowywać dane gęściej niż operatorzy, którzy go karmią. Na przykład indeks klastrowy tabeli podstawowej może przechowywać średnio 100 wierszy na stronę. Załóżmy, że zapytanie wymaga tylko jednej wartości w kolumnie liczb całkowitych z każdego wiersza indeksu szerokiego klastrowanego. Przechowywanie tylko liczby całkowitej w tabeli roboczej buforowania oznacza, że na jednej stronie można przechowywać ponad 800 takich wierszy. Jest to ważne, ponieważ optymalizator ocenia koszt buforowania tabeli częściowo na podstawie szacunkowej liczby stron tabeli roboczej potrzebne. Inne czynniki kosztowe obejmują koszt procesora na wiersz związany z zapisywaniem i odczytywaniem bufora w szacowanej liczbie iteracji pętli.
Optymalizator jest prawdopodobnie zbyt chętny, aby dodać leniwe spools tabeli do wewnętrznej strony złączenia zagnieżdżonych pętli. Niemniej jednak decyzja optymalizatora zawsze ma sens z punktu widzenia szacowanego kosztu. Osobiście uważam łączenie zagnieżdżonych pętli za wysokie ryzyko , ponieważ mogą one szybko stać się wolne, jeśli szacowana kardynalność łączenia jest zbyt niska.
Szpula stołu może pomaga obniżyć koszty, ale nie może w pełni ukryć najgorszej wydajności łączenia naiwnych pętli zagnieżdżonych. Zwykle preferowane jest indeksowane łączenie wprowadzające, które jest bardziej odporne na błędy estymacji. Dobrym pomysłem jest również pisanie zapytań, które optymalizator może zaimplementować za pomocą skrótu lub łączenia przez scalanie, jeśli to konieczne.
Zastosuj leniwą szpulę tabeli
O złóż wniosek , szanse na uzyskanie leniwej szpuli stołu wzrost o szacowaną liczbę duplikatów połącz wartości kluczy na zewnętrznych danych wejściowych Apply. W przypadku większej liczby duplikatów istnieje statystycznie większa szansa na przewinięcie aktualnie zapisanych wyników szpuli w każdej iteracji. Zastosowanie leniwej szpuli stołowej z niższym szacowanym kosztem ma większą szansę na uwzględnienie w ostatecznym planie wykonania.
Gdy wiersze przychodzące na zewnętrzne wejście zastosowania nie mają określonej kolejności, optymalizator dokonuje oceny statystycznej na ile prawdopodobne jest, że każda iteracja spowoduje tanie przewijanie lub drogie ponowne wiązanie. Ta ocena wykorzystuje dane z etapów histogramu, jeśli są dostępne, ale nawet ten najlepszy scenariusz jest bardziej świadomym przypuszczeniem. Bez gwarancji kolejność wierszy przychodzących na zewnętrzne wejście jest nieprzewidywalna.
Te same reguły optymalizatora, które generują logiczne alternatywy buforowania, mogą również określ, że operator Apply wymaga posortowane wiersze na jego zewnętrznym wejściu. Maksymalizuje to leniwą szpulę przewijanie ponieważ gwarantuje się, że wszystkie duplikaty zostaną napotkane w bloku. Gdy gwarantowana jest kolejność sortowania zewnętrznych danych wejściowych, przez zachowaną kolejność lub jawne Sortowanie , koszt szpuli jest znacznie obniżony. Optymalizator uwzględnia wpływ kolejności sortowania na liczbę przewinięć i ponownych wiązań szpuli.
Plany z sortowaniem na zewnętrznych danych wejściowych i Lazy Table Spool na wejściu wewnętrznym są dość powszechne. Optymalizacja sortowania od strony zewnętrznej może nadal przynosić efekty przeciwne do zamierzonego. Na przykład może się to zdarzyć, gdy oszacowana kardynalność strony zewnętrznej jest tak niska, że sortowanie kończy się rozlewaniem do tempdb .
Zastosuj leniwą szpulę indeksu
O złóż wniosek , uzyskując leniwą szpulę indeksu alternatywa zależy od kształtu planu, a także od kosztów.
Optymalizator wymaga:
- Niektóre duplikaty połącz wartości na wejściu zewnętrznym.
- Równość predykat join (lub odpowiednik logiczny zrozumiały dla optymalizatora, taki jak
x <= y AND x >= y). - Gwarancja że zewnętrzne odniesienia są unikalne poniżej proponowanej leniwej szpuli indeksu.
W planach wykonania wymagana unikalność jest często zapewniana przez grupowanie agregatów według zewnętrznych odwołań lub agregat skalarny (jeden bez grupowania według). Wyjątkowość można również zapewnić na inne sposoby, na przykład przez istnienie unikalnego indeksu lub ograniczenia.
Przykład zabawki przedstawiający kształt planu znajduje się poniżej:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
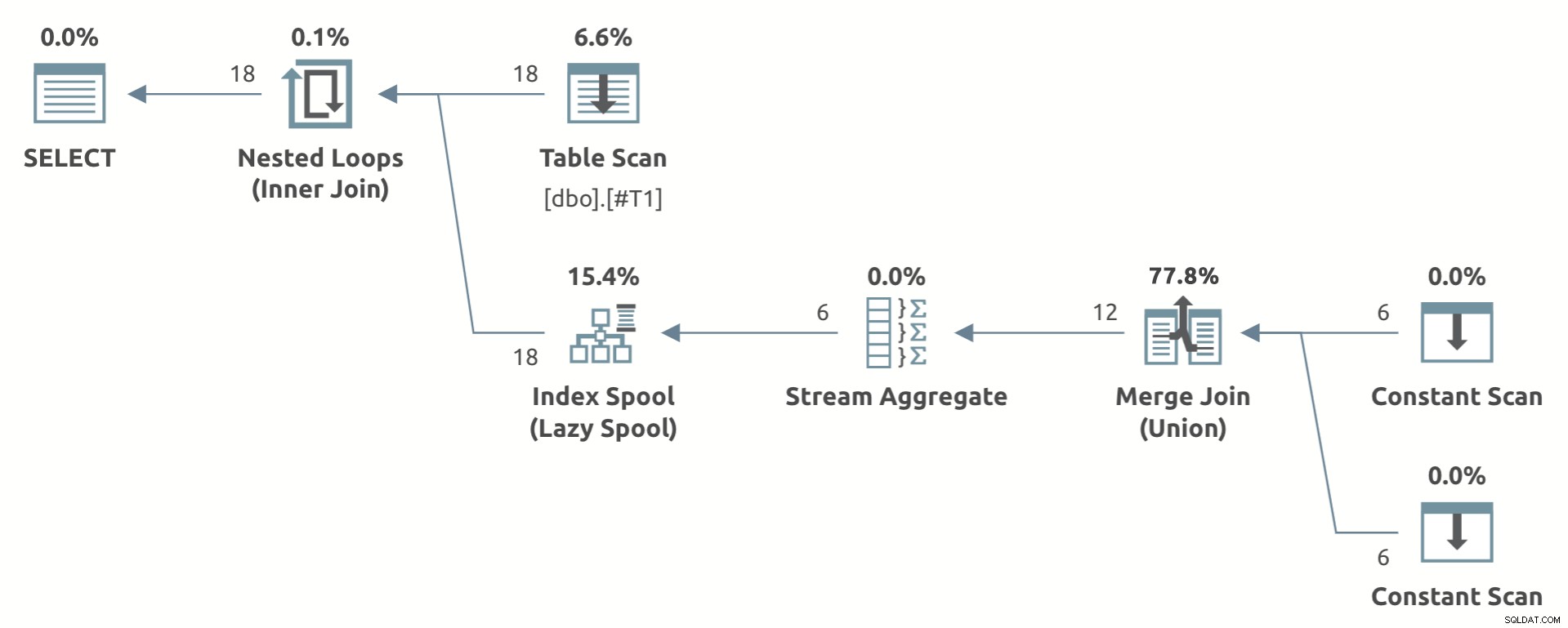
Zwróć uwagę na Agregację strumienia poniżej Lazy Index Spool .
Jeśli wymagania dotyczące kształtu planu są spełnione, optymalizator często generuje alternatywny indeks leniwy (z zastrzeżeniem wspomnianych wcześniej zastrzeżeń). To, czy ostateczny plan zawiera leniwą szpulę indeksu, czy nie, zależy od kosztów.
Buforowanie indeksu a buforowanie tabeli
Liczba szacowanych przewinięć i ponownie powiązuje dla leniwej szpuli indeksu jest tak samo jak na leniwą szpulę stołową bez posortowane zastosuj zewnętrzne dane wejściowe.
Może się to wydawać raczej niefortunnym stanem rzeczy. Główną zaletą buforowania indeksu jest to, że buforuje wszystkie poprzednio widziane wyniki. Powinno to spowodować przewijanie indeksu bardziej prawdopodobne niż w przypadku szpuli tabeli (bez sortowania na wejściu zewnętrznym) w tych samych okolicznościach. Rozumiem, że to dziwactwo istnieje, ponieważ bez niego optymalizator zdecydowanie zbyt często wybierałby szpulę indeksu.
Niezależnie od tego model kosztów dostosowuje się do powyższego w pewnym stopniu, używając różnych początkowych i kolejnych wierszy we/wy i kosztu procesora dla buforów indeksów i tabel. Efektem netto jest to, że buforowanie indeksu jest zwykle tańsze niż buforowanie tabeli bez posortowanych zewnętrznych danych wejściowych, ale pamiętaj o restrykcyjnych wymaganiach dotyczących kształtu planu, które powodują, że leniwe buforowanie indeksu stosunkowo rzadkie.
Jednak głównym konkurentem kosztowym dla indeksu leniwego buforowania jest bufor tabeli z posortowane wejście zewnętrzne. Intuicja jest dość prosta:posortowane zewnętrzne dane wejściowe oznaczają, że bufor tabeli gwarantuje sekwencyjne wyświetlanie wszystkich zduplikowanych zewnętrznych odwołań. Oznacza to, że ponownie połączy się tylko raz na odrębną wartość i przewiń dla wszystkich duplikatów. Jest to to samo, co oczekiwane zachowanie bufora indeksu (przynajmniej logicznie rzecz biorąc).
W praktyce jest bardziej prawdopodobne, że bufor indeksu będzie lepszy niż bufor tabeli zoptymalizowany pod kątem sortowania, aby uzyskać mniej zduplikowanych wartości klucza stosowania. Mniejsza liczba zduplikowanych kluczy zmniejsza przewijanie przewaga buforowania tabeli zoptymalizowanego pod kątem sortowania w porównaniu z „niefortunnymi” szacunkami buforowania indeksu odnotowanymi wcześniej.
Opcja buforowania indeksu jest również korzystna, ponieważ szacowany koszt buforowania tabeli po zewnętrznej stronie Sortuj wzrasta. Najczęściej byłoby to związane z większą liczbą (lub szerszymi) rzędami w tym punkcie planu.
Flagi i wskazówki śledzenia
-
Bufory wydajności mogą być wyłączone ze słabo udokumentowaną flagą śledzenia 8690 lub udokumentowaną wskazówkę dotyczącą zapytania
NO_PERFORMANCE_SPOOLna SQL Server 2016 lub nowszym. -
Nieudokumentowana flaga śledzenia 8691 może być używany (w systemie testowym), aby zawsze dodawać szpulę wydajności kiedy możliwe. typ leniwej szpuli, którą otrzymasz (liczba wierszy, tabela lub indeks) nie może być wymuszone; nadal zależy to od oszacowania kosztów.
-
Nieudokumentowana flaga śledzenia 2363 może być używany z nowym modelem szacowania kardynalności, aby zobaczyć pochodzenie wyraźnego oszacowania na zewnętrznych danych wejściowych do zastosowania i ogólnie oszacowaniu kardynalności.
-
Nieudokumentowana flaga śledzenia 9198 może być używany do wyłączania buforów wydajności leniwego indeksu konkretnie. Nadal możesz otrzymać leniwą szpulę z liczbą tabel lub wierszy (z optymalizacją sortowania lub bez), w zależności od kosztów.
-
Nieudokumentowana flaga śledzenia 2387 może być używany do zmniejszenia kosztu procesora odczytów wierszy z leniwej szpuli indeksu . Ta flaga wpływa na ogólne szacunki kosztów procesora w celu odczytania zakresu wierszy z b-drzewa. Ta flaga sprawia, że wybór buforu indeksu jest bardziej prawdopodobny ze względu na koszty.
Inne flagi śledzenia i metody określania, które reguły optymalizatora zostały aktywowane podczas kompilacji zapytań, można znaleźć w mojej serii Query Optimizer Deep Dive.
Końcowe myśli
Istnieje wiele wewnętrznych szczegółów, które wpływają na to, czy ostateczny plan wykonania używa buforu wydajności, czy nie. Starałem się omówić główne rozważania w tym artykule, nie zagłębiając się zbytnio w niezwykle zawiłe szczegóły formuł kosztów operatorów buforowania. Mamy nadzieję, że jest tu wystarczająco dużo ogólnych porad, które pomogą ci określić możliwe przyczyny konkretnego typu buforu wydajności w planie wykonania (lub jego braku).
Szpule wydajności często mają złą reputację, myślę, że można to uczciwie powiedzieć. Część z tego jest bez wątpienia zasłużona. Wielu z was widziało demo, w którym plan jest wykonywany szybciej bez „szpuli wydajności” niż z. W pewnym stopniu nie jest to nieoczekiwane. Istnieją przypadki brzegowe, model kosztów nie jest doskonały i bez wątpienia wersje demonstracyjne często zawierają plany ze słabymi szacunkami kardynalności lub innymi problemami ograniczającymi optymalizację.
To powiedziawszy, czasami chciałbym, aby SQL Server dostarczał jakiegoś rodzaju ostrzeżenia lub innej informacji zwrotnej, gdy ucieka się do dodawania leniwego buforu tabeli do sprzężenia zagnieżdżonych pętli (lub zastosowania bez używanego pomocniczego indeksu po stronie wewnętrznej). Jak wspomniano w głównym tekście, są to sytuacje, które najczęściej mi się źle układają, kiedy oszacowania kardynalności okazują się strasznie niskie.
Być może pewnego dnia optymalizator zapytań uwzględni pewną koncepcję ryzyka, aby zaplanować wybory lub zapewni bardziej „adaptacyjne” możliwości. W międzyczasie opłaca się obsługiwać sprzężenia zagnieżdżonych pętli za pomocą przydatnych indeksów i unikać pisania zapytań, które można zaimplementować tylko przy użyciu zagnieżdżonych pętli, jeśli to możliwe. Generalizuję oczywiście, ale optymalizator radzi sobie lepiej, gdy ma więcej opcji, rozsądny schemat, dobre metadane i łatwe w zarządzaniu instrukcje T-SQL. Tak jak ja, myślę o tym.
Inne artykuły ze szpuli
Bufory niewydajne są używane w SQL Server do wielu celów, w tym:
- Ochrona Halloween
- Niektóre funkcje okna trybu wiersza
- Obliczanie wielu agregatów
- Optymalizacja stwierdzeń, które zmieniają dane



