Ten artykuł jest piątą częścią serii o błędach, pułapkach i najlepszych praktykach T-SQL. Wcześniej zajmowałem się determinizmem, podzapytaniami, złączeniami i okienkowaniem. W tym miesiącu omówię obracanie i unpivoting. Dziękujemy Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man i Paul White za podzielenie się swoimi sugestiami!
W moich przykładach użyję przykładowej bazy danych o nazwie TSQLV5. Skrypt, który tworzy i wypełnia tę bazę danych, oraz jego diagram ER można znaleźć tutaj.
Niejawne grupowanie za pomocą PIVOT
Kiedy ludzie chcą przestawiać dane za pomocą T-SQL, używają albo standardowego rozwiązania z pogrupowanym zapytaniem i wyrażeniami CASE, albo zastrzeżonego operatora tabeli PIVOT. Główną zaletą operatora PIVOT jest to, że powoduje on skrócenie kodu. Jednak ten operator ma kilka niedociągnięć, między innymi nieodłączną pułapkę projektową, która może powodować błędy w kodzie. Tutaj opiszę pułapkę, potencjalny błąd i najlepszą praktykę, która zapobiega błędowi. Opiszę również sugestię ulepszenia składni operatora PIVOT w sposób, który pomoże uniknąć błędu.
Kiedy przestawiasz dane, rozwiązanie obejmuje trzy kroki, z trzema powiązanymi elementami:
- Grupowanie na podstawie grupowania/elementu wierszy
- Rozpiętość oparta na elemencie spread/on cols
- Agregacja na podstawie elementu agregacji/danych
Poniżej znajduje się składnia operatora PIVOT:
SELECT <select_list>
FROM <source_table>
PIVOT( <aggregate_function>(<aggregate_col>)
FOR <spread_col> IN(<target_cols>) ) AS <alias>; Projekt operatora PIVOT wymaga jawnego określenia elementów agregacji i rozprzestrzeniania, ale umożliwia programowi SQL Server niejawne określenie elementu grupowania przez eliminację. Niezależnie od tego, które kolumny pojawią się w tabeli źródłowej, która jest dostarczana jako dane wejściowe do operatora PRZESTAWNEGO, stają się one niejawnie elementem grupującym.
Załóżmy na przykład, że chcesz wysłać zapytanie do tabeli Sales.Orders w przykładowej bazie danych TSQLV5. Chcesz zwrócić identyfikatory nadawcy w wierszach, wysłane lata w kolumnach oraz liczbę zamówień na nadawcę i rok jako sumę.
Wiele osób ma trudności ze zrozumieniem składni operatora PIVOT, co często skutkuje grupowaniem danych według niepożądanych elementów. Jako przykład z naszym zadaniem załóżmy, że nie zdajesz sobie sprawy, że element grupujący jest określony niejawnie, i pojawia się następujące zapytanie:
SELECT shipperid, [2017], [2018], [2019] FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT( COUNT(shippeddate) FOR shippedyear IN([2017], [2018], [2019]) ) AS P;
W danych jest tylko trzech nadawców o identyfikatorach nadawcy 1, 2 i 3. Dlatego oczekujesz, że w wyniku pojawią się tylko trzy wiersze. Jednak rzeczywisty wynik zapytania pokazuje o wiele więcej wierszy:
shipperid 2017 2018 2019 ----------- ----------- ----------- ----------- 3 1 0 0 1 1 0 0 2 1 0 0 1 1 0 0 2 1 0 0 2 1 0 0 2 1 0 0 3 1 0 0 2 1 0 0 3 1 0 0 ... 3 0 1 0 3 0 1 0 3 0 1 0 1 0 1 0 3 0 1 0 1 0 1 0 3 0 1 0 3 0 1 0 3 0 1 0 1 0 1 0 ... 3 0 0 1 1 0 0 1 2 0 0 1 1 0 0 1 2 0 0 1 1 0 0 1 3 0 0 1 3 0 0 1 2 0 1 0 ... (830 rows affected)
Co się stało?
Możesz znaleźć wskazówkę, która pomoże ci znaleźć błąd w kodzie, patrząc na plan zapytań pokazany na rysunku 1.
 Rysunek 1:Planowanie zapytania przestawnego z grupowaniem niejawnym
Rysunek 1:Planowanie zapytania przestawnego z grupowaniem niejawnym
Nie pozwól, aby użycie operatora CROSS APPLY z klauzulą VALUES w zapytaniu zmyliło Cię. Odbywa się to po prostu w celu obliczenia kolumny wynikowej dostarczonego roku na podstawie kolumny źródłowej data dostawy i jest obsługiwane przez pierwszego operatora obliczeniowego skalarnego w planie.
Tabela wejściowa do operatora PRZESTAWNA zawiera wszystkie kolumny z tabeli Sales.Orders oraz kolumnę wynikową wysłany rok. Jak wspomniano, SQL Server określa element grupujący niejawnie przez eliminację na podstawie elementów, które nie zostały określone jako elementy agregacji (data wysyłki) i rozprzestrzeniania (rok dostawy). Być może intuicyjnie spodziewałeś się, że kolumna shipperid będzie kolumną grupującą, ponieważ pojawia się na liście SELECT, ale jak widać na planie, w praktyce dostałeś znacznie dłuższą listę kolumn, w tym orderid, który jest kluczem podstawowym w tabela źródłowa. Oznacza to, że zamiast otrzymywać wiersz na nadawcę, otrzymujesz wiersz na zamówienie. Ponieważ na liście SELECT określiłeś tylko kolumny shipperid, [2017], [2018] i [2019], reszty nie widzisz, co dodatkowo zwiększa zamieszanie. Ale reszta brała udział w dorozumianym grupowaniu.
Co mogłoby być świetne, to gdyby składnia operatora PRZESTAWNA obsługiwała klauzulę, w której można wyraźnie wskazać element grupowania/w wierszach. Coś takiego:
SELECT <select_list>
FROM <source_table>
PIVOT( <aggregate_function>(<aggregate_col>)
FOR <spread_col> IN(<target_cols>)
ON ROWS <grouping_cols> ) AS <alias>; W oparciu o tę składnię do wykonania naszego zadania użyjesz następującego kodu:
SELECT shipperid, [2017], [2018], [2019]
FROM Sales.Orders
CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear)
PIVOT( COUNT(shippeddate)
FOR shippedyear IN([2017], [2018], [2019])
ON ROWS shipperid ) AS P; Tutaj możesz znaleźć element opinii z sugestią ulepszenia składni operatora PIVOT. Aby to ulepszenie stało się nieistotną zmianą, ta klauzula może być opcjonalna, przy czym domyślnym jest istniejące zachowanie. Istnieją inne sugestie dotyczące ulepszenia składni operatora PIVOT przez uczynienie go bardziej dynamicznym i obsługę wielu agregacji.
W międzyczasie istnieje najlepsza praktyka, która może pomóc w uniknięciu błędu. Użyj wyrażenia tabelowego, takiego jak CTE lub tabela pochodna, w której rzutujesz tylko trzy elementy, które są potrzebne w operacji przestawnej, a następnie użyj wyrażenia tabelowego jako danych wejściowych do operatora PRZESTAWNA. W ten sposób w pełni kontrolujesz element grupujący. Oto ogólna składnia zgodnie z tą najlepszą praktyką:
WITH <CTE_name> AS
(
SELECT <group_cols>, <spread_col>, <aggregate_col>
FROM <source_table>
)
SELECT <select_list>
FROM <CTE_name>
PIVOT( <aggregate_function>(<aggregate_col>)
FOR <spread_col> IN(<target_cols>) ) AS <alias>; W ramach naszego zadania używasz następującego kodu:
WITH C AS
(
SELECT shipperid, YEAR(shippeddate) AS shippedyear, shippeddate
FROM Sales.Orders
)
SELECT shipperid, [2017], [2018], [2019]
FROM C
PIVOT( COUNT(shippeddate)
FOR shippedyear IN([2017], [2018], [2019]) ) AS P; Tym razem otrzymujesz tylko trzy wiersze wyników zgodnie z oczekiwaniami:
shipperid 2017 2018 2019 ----------- ----------- ----------- ----------- 3 51 125 73 1 36 130 79 2 56 143 116
Inną opcją jest użycie starego i klasycznego standardowego rozwiązania do przestawiania za pomocą zgrupowanych zapytań i wyrażeń CASE, na przykład:
SELECT shipperid, COUNT(CASE WHEN shippedyear = 2017 THEN 1 END) AS [2017], COUNT(CASE WHEN shippedyear = 2018 THEN 1 END) AS [2018], COUNT(CASE WHEN shippedyear = 2019 THEN 1 END) AS [2019] FROM Sales.Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) WHERE shippeddate IS NOT NULL GROUP BY shipperid;
Dzięki tej składni wszystkie trzy kroki obrotowe i powiązane z nimi elementy muszą być wyraźnie określone w kodzie. Jednak w przypadku dużej liczby wartości rozszerzających ta składnia jest zwykle gadatliwa. W takich przypadkach ludzie często wolą używać operatora PIVOT.
Niejawne usuwanie wartości NULL za pomocą UNPIVOT
Kolejna pozycja w tym artykule to raczej pułapka niż błąd. Ma to związek z zastrzeżonym operatorem T-SQL UNPIVOT, który pozwala przestawiać dane ze stanu kolumn do stanu wierszy.
Jako przykładowych danych użyję tabeli o nazwie CustOrders. Użyj poniższego kodu, aby utworzyć, wypełnić i przeszukać tę tabelę w celu wyświetlenia jej zawartości:
DROP TABLE IF EXISTS dbo.CustOrders;
GO
WITH C AS
(
SELECT custid, YEAR(orderdate) AS orderyearyear, val
FROM Sales.OrderValues
)
SELECT custid, [2017], [2018], [2019]
INTO dbo.CustOrders
FROM C
PIVOT( SUM(val)
FOR orderyearyear IN([2017], [2018], [2019]) ) AS P;
SELECT * FROM dbo.CustOrders; Ten kod generuje następujące dane wyjściowe:
custid 2017 2018 2019 ------- ---------- ---------- ---------- 1 NULL 2022.50 2250.50 2 88.80 799.75 514.40 3 403.20 5960.78 660.00 4 1379.00 6406.90 5604.75 5 4324.40 13849.02 6754.16 6 NULL 1079.80 2160.00 7 9986.20 7817.88 730.00 8 982.00 3026.85 224.00 9 4074.28 11208.36 6680.61 10 1832.80 7630.25 11338.56 11 479.40 3179.50 2431.00 12 NULL 238.00 1576.80 13 100.80 NULL NULL 14 1674.22 6516.40 4158.26 15 2169.00 1128.00 513.75 16 NULL 787.60 931.50 17 533.60 420.00 2809.61 18 268.80 487.00 860.10 19 950.00 4514.35 9296.69 20 15568.07 48096.27 41210.65 ...
Ta tabela zawiera łączne wartości zamówień na klienta i rok. Wartości NULL reprezentują przypadki, w których klient nie miał żadnych działań związanych z zamówieniem w roku docelowym.
Załóżmy, że chcesz przestawić dane z tabeli CustOrders, zwracając wiersz dla klienta i roku, z kolumną wyników o nazwie val zawierającą całkowitą wartość zamówienia dla bieżącego klienta i roku. Każde zadanie, które nie jest przestawne, zazwyczaj obejmuje trzy elementy:
- Nazwy istniejących kolumn źródłowych, których przestawiasz:[2017], [2018], [2019] w naszym przypadku
- Nazwa, którą przypiszesz do kolumny docelowej, która będzie zawierać nazwy kolumn źródłowych:w naszym przypadku rok zamówienia
- Nazwa przypisana do kolumny docelowej, która będzie przechowywać wartości kolumny źródłowej:w naszym przypadku val
Jeśli zdecydujesz się użyć operatora UNPIVOT do obsługi zadania cofania, najpierw poznaj powyższe trzy elementy, a następnie użyj następującej składni:
SELECT <table_cols except source_cols>, <names_col>, <values_col> FROM <source_table> UNPIVOT( <values_col> FOR <names_col> IN(<source_cols>) ) AS <alias>;
W odniesieniu do naszego zadania używasz następującego zapytania:
SELECT custid, orderyear, val FROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
To zapytanie generuje następujące dane wyjściowe:
custid orderyear val ------- ---------- ---------- 1 2018 2022.50 1 2019 2250.50 2 2017 88.80 2 2018 799.75 2 2019 514.40 3 2017 403.20 3 2018 5960.78 3 2019 660.00 4 2017 1379.00 4 2018 6406.90 4 2019 5604.75 5 2017 4324.40 5 2018 13849.02 5 2019 6754.16 6 2018 1079.80 6 2019 2160.00 7 2017 9986.20 7 2018 7817.88 7 2019 730.00 ...
Patrząc na dane źródłowe i wynik zapytania, czy zauważasz, czego brakuje?
Projekt operatora UNPIVOT obejmuje niejawną eliminację wierszy wyników, które mają wartość NULL w kolumnie wartości — w naszym przypadku val. Patrząc na plan wykonania dla tego zapytania, pokazany na Rysunku 2, możesz zobaczyć, że operator filtra usuwa wiersze z wartościami NULL w kolumnie val (Expr1007 w planie).
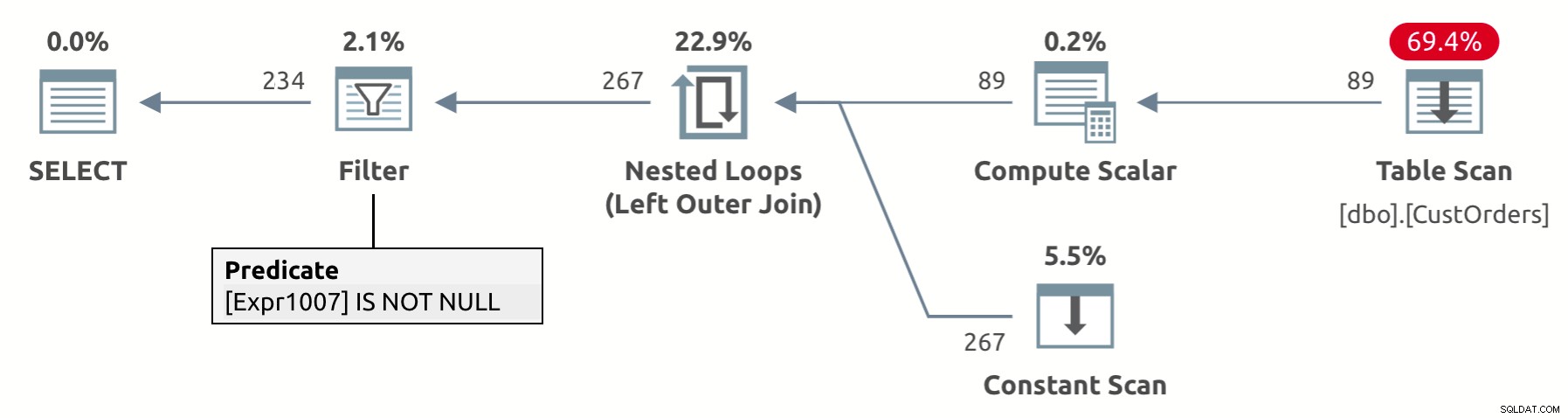 Rysunek 2:Plan dla zapytania unpivot z niejawnym usuwaniem wartości NULL
Rysunek 2:Plan dla zapytania unpivot z niejawnym usuwaniem wartości NULL
Czasami takie zachowanie jest pożądane, w takim przypadku nie musisz robić nic specjalnego. Problem polega na tym, że czasami chcesz zachować wiersze z wartościami NULL. Pułapka polega na tym, że chcesz zachować wartości NULL i nawet nie zdajesz sobie sprawy, że operator UNPIVOT jest przeznaczony do ich usuwania.
Co mogłoby być świetne, gdyby operator UNPIVOT miał opcjonalną klauzulę, która pozwalała określić, czy chcesz usunąć, czy zachować wartości NULL, przy czym ta pierwsza jest domyślna dla zgodności z poprzednimi wersjami. Oto przykład tego, jak może wyglądać ta składnia:
SELECT <table_cols except source_cols>, <names_col>, <values_col>
FROM <source_table>
UNPIVOT( <values_col> FOR <names_col> IN(<source_cols>)
[REMOVE NULLS | KEEP NULLS] ) AS <alias>; Jeśli chcesz zachować wartości NULL, na podstawie tej składni użyjesz następującego zapytania:
SELECT custid, orderyear, val FROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;
Możesz znaleźć element opinii z sugestią ulepszenia składni operatora UNPIVOT w ten sposób tutaj.
W międzyczasie, jeśli chcesz zachować wiersze z wartościami NULL, musisz wymyślić obejście. Jeśli nalegasz na używanie operatora UNPIVOT, musisz zastosować dwa kroki. W pierwszym kroku definiujesz wyrażenie tabelowe oparte na zapytaniu, które używa funkcji ISNULL lub COALESCE do zastąpienia wartości NULL we wszystkich kolumnach nieprzestawnych wartością, która normalnie nie może pojawić się w danych, np. -1 w naszym przypadku. W drugim kroku używasz funkcji NULLIF w zewnętrznym zapytaniu względem kolumny wartości, aby zastąpić -1 z powrotem wartością NULL. Oto kompletny kod rozwiązania:
WITH C AS
(
SELECT custid,
ISNULL([2017], -1.0) AS [2017],
ISNULL([2018], -1.0) AS [2018],
ISNULL([2019], -1.0) AS [2019]
FROM dbo.CustOrders
)
SELECT custid, orderyear, NULLIF(val, -1.0) AS val
FROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U; Oto wynik tego zapytania pokazujący, że wiersze z wartościami NULL w kolumnie val są zachowane:
custid orderyear val ------- ---------- ---------- 1 2017 NULL 1 2018 2022.50 1 2019 2250.50 2 2017 88.80 2 2018 799.75 2 2019 514.40 3 2017 403.20 3 2018 5960.78 3 2019 660.00 4 2017 1379.00 4 2018 6406.90 4 2019 5604.75 5 2017 4324.40 5 2018 13849.02 5 2019 6754.16 6 2017 NULL 6 2018 1079.80 6 2019 2160.00 7 2017 9986.20 7 2018 7817.88 7 2019 730.00 ...
Takie podejście jest niewygodne, zwłaszcza gdy masz dużą liczbę kolumn do odwrócenia.
Alternatywne rozwiązanie wykorzystuje kombinację operatora APPLY i klauzuli VALUES. Konstruujesz wiersz dla każdej kolumny nieprzestawnej, z jedną kolumną reprezentującą kolumnę nazw docelowych (w naszym przypadku orderyear), a drugą reprezentującą kolumnę wartości docelowych (w naszym przypadku val). Podajesz stały rok dla kolumny nazw i odpowiednią skorelowaną kolumnę źródłową dla kolumny wartości. Oto kompletny kod rozwiązania:
SELECT custid, orderyear, val
FROM dbo.CustOrders
CROSS APPLY ( VALUES(2017, [2017]),
(2018, [2018]),
(2019, [2019]) ) AS A(orderyear, val); Fajną rzeczą jest to, że jeśli nie jesteś zainteresowany usuwaniem wierszy z wartościami NULL w kolumnie val, nie musisz robić nic specjalnego. Nie ma tu niejawnego kroku, który usuwałby wiersze z wartościami NULL. Co więcej, ponieważ alias kolumny val jest tworzony jako część klauzuli FROM, jest dostępny dla klauzuli WHERE. Tak więc, jeśli jesteś zainteresowany usunięciem wartości NULL, możesz to wyraźnie określić w klauzuli WHERE, bezpośrednio wchodząc w interakcję z aliasem kolumny wartości, na przykład:
SELECT custid, orderyear, val
FROM dbo.CustOrders
CROSS APPLY ( VALUES(2017, [2017]),
(2018, [2018]),
(2019, [2019]) ) AS A(orderyear, val)
WHERE val IS NOT NULL; Chodzi o to, że ta składnia daje kontrolę nad tym, czy chcesz zachować, czy usunąć NULL. Jest bardziej elastyczny niż operator UNPIVOT w inny sposób, umożliwiając obsługę wielu nieprzestawnych miar, takich jak val i qty. W tym artykule skupiłem się jednak na pułapce związanej z wartościami NULL, więc nie wszedłem w ten aspekt.
Wniosek
Projekt operatorów PIVOT i UNPIVOT czasami prowadzi do błędów i pułapek w kodzie. Składnia operatora PIVOT nie pozwala na jednoznaczne wskazanie elementu grupującego. Jeśli nie zdajesz sobie z tego sprawy, możesz skończyć z niepożądanymi elementami grupowania. W ramach najlepszej praktyki zaleca się używanie wyrażenia tabelowego jako danych wejściowych do operatora PRZESTAWNEGO i dlatego jawnie kontroluj, co jest elementem grupującym.
Składnia operatora UNPIVOT nie pozwala na kontrolowanie, czy usunąć lub zachować wiersze z wartościami NULL w kolumnie wartości wyników. Jako obejście możesz użyć niewygodnego rozwiązania z funkcjami ISNULL i NULLIF lub rozwiązania opartego na operatorze APPLY i klauzuli VALUES.
Wspomniałem również o dwóch elementach opinii z sugestiami ulepszenia operatorów PIVOT i UNPIVOT z bardziej wyraźnymi opcjami kontrolowania zachowania operatora i jego elementów.