Istnieje wiele metod sprawdzania słabo wydajnych zapytań w SQL Server, w szczególności Query Store, Extended Events i dynamiczne widoki zarządzania (DMV). Każda opcja ma zalety i wady. Zdarzenia rozszerzone dostarczają danych o wykonywaniu poszczególnych zapytań, podczas gdy magazyn zapytań i DMV agregują dane dotyczące wydajności. Aby używać Query Store i Extended Events, musisz je wcześniej skonfigurować — włączając Query Store dla swoich baz danych lub konfigurowanie sesji XE i jej uruchamianie. Dane DMV są zawsze dostępne, więc bardzo często jest to najłatwiejsza metoda szybkiego pierwszego spojrzenia na wydajność zapytań. Tutaj przydają się zapytania DMV Glenna – w swoim skrypcie ma wiele zapytań, których można użyć do znalezienia najlepszych zapytań dla instancji na podstawie procesora, logicznych operacji we/wy i czasu trwania. Ukierunkowanie na zapytania wymagające największej ilości zasobów jest często dobrym początkiem podczas rozwiązywania problemów, ale nie możemy zapomnieć o scenariuszu „śmierci przez tysiąc cięć” – zapytania lub zestawu zapytań, które są uruchamiane BARDZO często – może setki lub tysiące razy minuta. Glenn ma w swoim zestawie zapytanie, które zawiera listę najczęstszych zapytań do bazy danych na podstawie liczby wykonań, ale z mojego doświadczenia wynika, że nie daje to pełnego obrazu obciążenia pracą.
Głównym DMV używanym do przeglądania metryk wydajności zapytań jest sys.dm_exec_query_stats. Dostępne są również dodatkowe dane specyficzne dla procedur składowanych (sys.dm_exec_procedure_stats), funkcji (sys.dm_exec_function_stats) i wyzwalaczy (sys.dm_exec_trigger_stats), ale należy wziąć pod uwagę obciążenie, które nie jest wyłącznie procedurami składowanymi, funkcjami i wyzwalaczami. Rozważ mieszane obciążenie, które ma kilka zapytań ad hoc, a może jest całkowicie ad hoc.
Przykładowy scenariusz
Pożyczając i dostosowując kod z poprzedniego postu, Badając wpływ obciążenia ad hoc na wydajność, najpierw utworzymy dwie procedury składowane. Pierwsza, dbo.RandomSelects, generuje i wykonuje instrukcję ad hoc, a druga, dbo.SPRandomSelects, generuje i wykonuje sparametryzowane zapytanie.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Teraz wykonamy obie procedury składowane 1000 razy, używając tej samej metody opisanej w moim poprzednim poście z plikami .cmd wywołującymi pliki .sql z następującymi instrukcjami:
Zawartość pliku Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Zawartość pliku sparametryzowanego.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Przykładowa składnia w pliku .cmd, która wywołuje plik .sql:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Jeśli użyjemy odmiany zapytania Glenn's Top Worker Time, aby spojrzeć na najczęstsze zapytania na podstawie czasu pracy (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
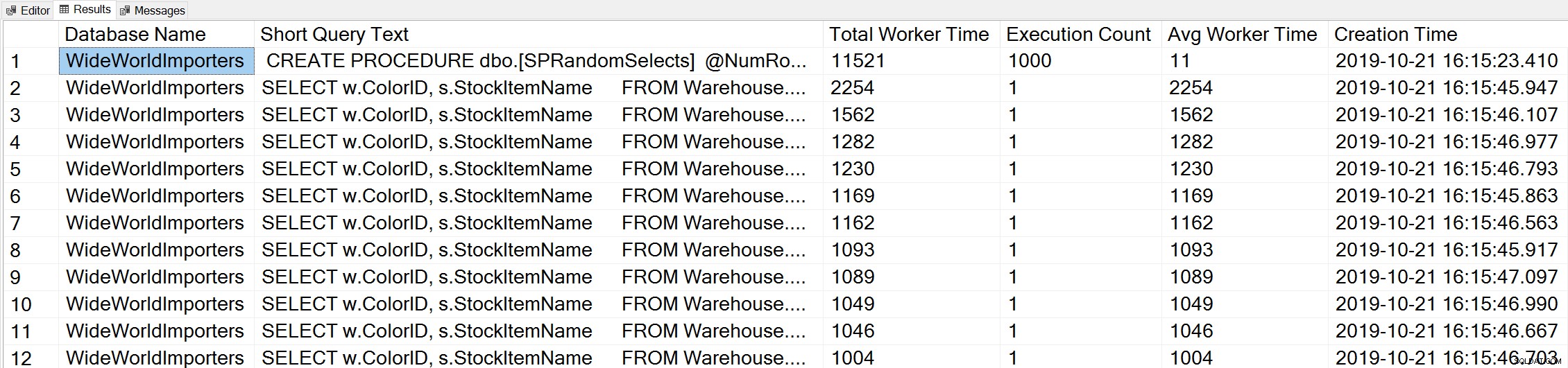
Widzimy instrukcję z naszej procedury składowanej jako zapytanie, które jest wykonywane z największą skumulowaną ilością procesora.
Jeśli uruchomimy odmianę zapytania Glenn's Query Execution Counts w bazie danych WideWorldImporters:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
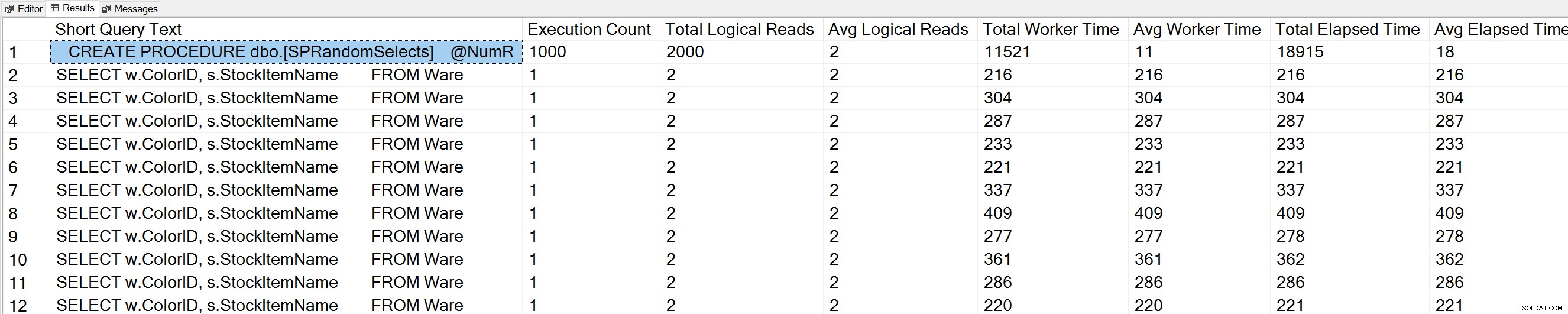
Widzimy również naszą instrukcję procedury składowanej na górze listy.
Ale zapytanie ad hoc, które wykonaliśmy, mimo że ma różne wartości literalne, było zasadniczo to samo instrukcja wykonywana wielokrotnie, jak widać patrząc na query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
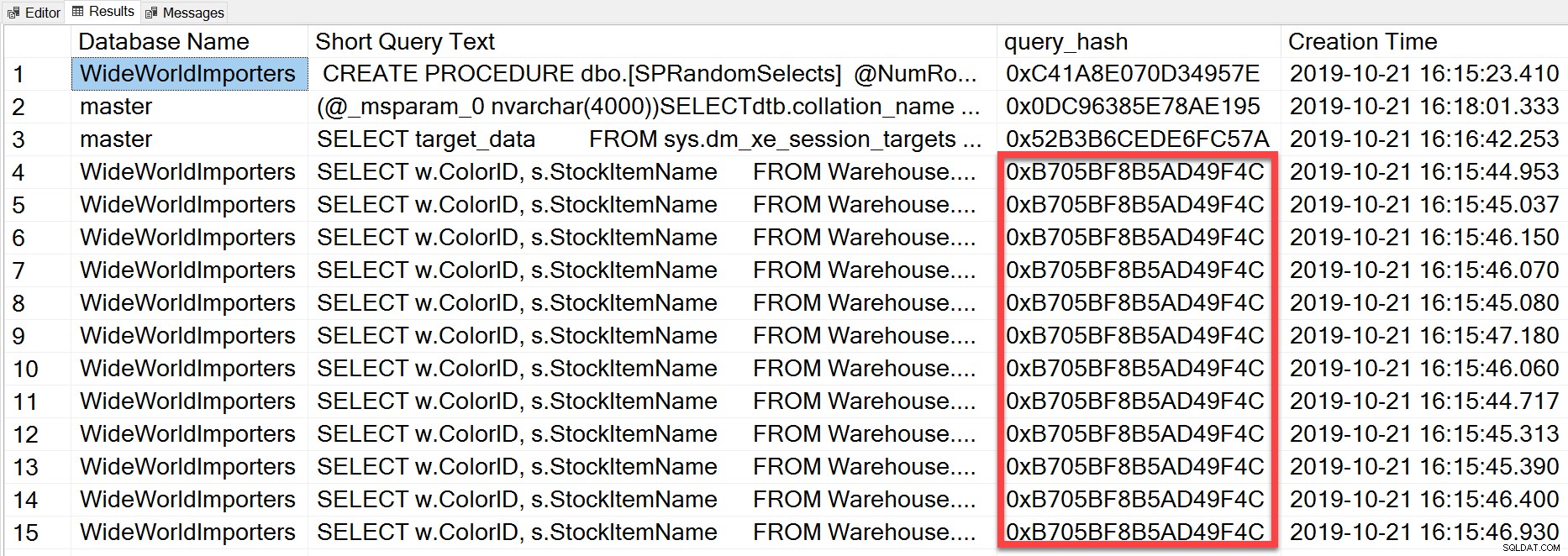
query_hash został dodany w SQL Server 2008 i jest oparty na drzewie operatorów logicznych generowanych przez Query Optimizer dla tekstu instrukcji. Zapytania, które mają podobny tekst instrukcji, które generują to samo drzewo operatorów logicznych, będą miały ten sam skrót_zapytania, nawet jeśli wartości literałów w predykacie zapytania są różne. Chociaż wartości literałów mogą być różne, obiekty i ich aliasy muszą być takie same, a także wskazówki dotyczące zapytań i potencjalnie opcje SET. Procedura składowana RandomSelects generuje zapytania z różnymi wartościami literałowymi:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Ale każde wykonanie ma dokładnie taką samą wartość dla query_hash, 0xB705BF8B5AD49F4C. Aby zrozumieć, jak często wykonywane jest zapytanie ad hoc – i te, które są takie same pod względem query_hash – musimy pogrupować według kolejności query_hash dla tej liczby, zamiast patrzeć na liczbę_wykonań w sys.dm_exec_query_stats (co często pokazuje wartość 1).
Jeśli zmienimy kontekst na bazę danych WideWorldImporters i poszukamy najczęstszych zapytań na podstawie liczby wykonań, gdzie grupujemy na query_hash, możemy teraz zobaczyć zarówno procedurę składowaną i nasze zapytanie ad hoc:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Uwaga:DMV sys.dm_exec_function_stats został dodany w SQL Server 2016. Uruchomienie tej kwerendy w SQL Server 2014 i wcześniejszych wymaga usunięcia odniesienia do tego DMV.
Te dane wyjściowe zapewniają znacznie pełniejsze zrozumienie tego, które zapytania naprawdę są wykonywane najczęściej, ponieważ agregują one na podstawie query_hash, a nie tylko patrząc na liczbę_wykonań w sys.dm_exec_query_stats, która może mieć wiele wpisów dla tego samego zapytania_hash, gdy są różne wartości literału używany. Dane wyjściowe zapytania zawierają również query_plan_hash, który może być inny dla zapytań z tym samym query_hash. Te dodatkowe informacje są przydatne podczas oceny wydajności planu dla zapytania. W powyższym przykładzie każde zapytanie ma ten sam query_plan_hash, 0x299275DD475C4B17, co pokazuje, że nawet przy różnych wartościach wejściowych Optymalizator zapytań generuje ten sam plan – jest stabilny. Gdy istnieje wiele wartości query_plan_hash dla tego samego query_hash, istnieje zmienność planu. W scenariuszu, w którym to samo zapytanie, oparte na query_hash, jest wykonywane tysiące razy, ogólne zalecenie polega na sparametryzowaniu zapytania. Jeśli możesz sprawdzić, czy nie istnieje zmienność planu, parametryzacja zapytania usuwa czas optymalizacji i kompilacji dla każdego wykonania i może zmniejszyć ogólny procesor CPU. W niektórych scenariuszach parametryzacja od pięciu do 10 zapytań ad hoc może poprawić wydajność systemu jako całości.
Podsumowanie
W każdym środowisku ważne jest, aby zrozumieć, które zapytania są najdroższe pod względem wykorzystania zasobów i jakie zapytania są wykonywane najczęściej. Ten sam zestaw zapytań może pojawić się dla obu typów analizy podczas korzystania ze skryptu DMV Glenna, co może wprowadzać w błąd. W związku z tym ważne jest, aby ustalić, czy obciążenie jest w większości proceduralne, w większości doraźne, czy mieszane. Chociaż istnieje wiele dokumentacji na temat zalet procedur składowanych, uważam, że obciążenia mieszane lub wysoce ad hoc są bardzo powszechne, szczególnie w przypadku rozwiązań korzystających z mapowań obiektowo-relacyjnych (ORM), takich jak Entity Framework, NHibernate i LINQ to SQL. Jeśli nie masz pewności co do rodzaju obciążenia serwera, uruchomienie powyższego zapytania w celu sprawdzenia najczęściej wykonywanych zapytań na podstawie query_hash jest dobrym początkiem. Gdy zaczniesz rozumieć obciążenie pracą i to, co istnieje zarówno w przypadku ciężkich trafień, jak i śmierci przez tysiące cięć zapytań, możesz przejść do prawdziwego zrozumienia wykorzystania zasobów i wpływu tych zapytań na wydajność systemu, a także ukierunkować swoje wysiłki na dostrajanie.