Jest to ostatnia część pięcioczęściowej serii, w której szczegółowo opisano sposób, w jaki rozpoczynają się równoległe plany SQL Server w trybie rzędowym. Część 1 zainicjowała kontekst wykonania zero dla zadania nadrzędnego, a część 2 utworzyła drzewo skanowania zapytań. Część 3 rozpoczęła skanowanie zapytania, wykonała wczesną fazę przetwarzania i rozpoczął pierwsze dodatkowe zadania równoległe w gałęzi C. W części 4 opisano synchronizację wymiany i uruchomienie równoległych gałęzi C i D.
Rozpoczęcie zadań równoległych gałęzi B
Przypomnienie o gałęziach w tym równoległym planie (kliknij, aby powiększyć):
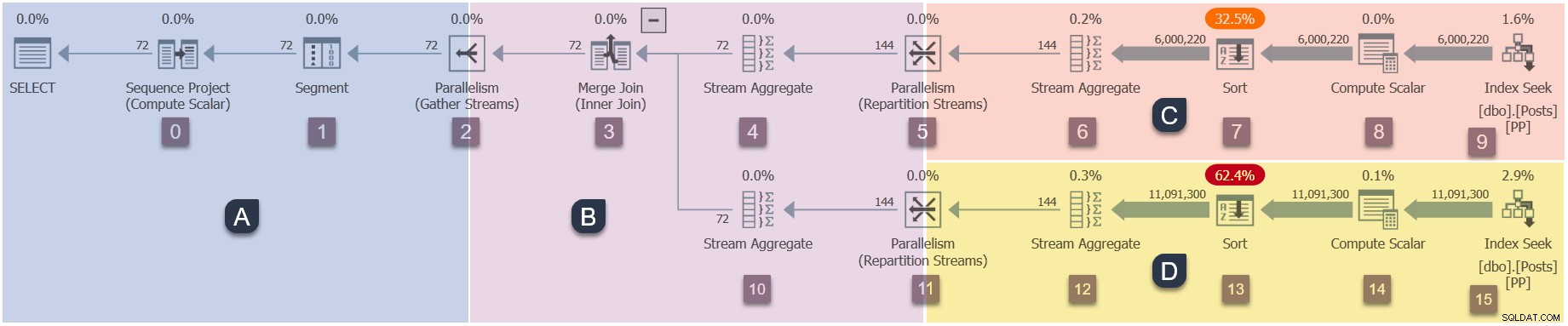
To jest czwarty etap sekwencji wykonywania:
- Oddział A (zadanie nadrzędne).
- Gałąź C (dodatkowe zadania równoległe).
- Gałąź D (dodatkowe zadania równoległe).
- Oddział B (dodatkowe zadania równoległe).
Jedyny wątek aktywny w tej chwili (nie zawieszony w CXPACKET ) jest zadaniem nadrzędnym , który znajduje się po stronie konsumenta wymiany strumieni podziału w węźle 11 w Oddziale B:
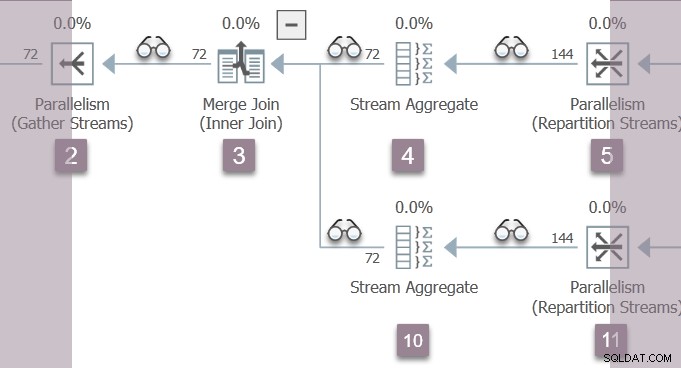
Zadanie nadrzędne powraca teraz z zagnieżdżonych wczesnych faz wywołań, ustawiając czasy, które upłynął i czas procesora w profilerach, jak to się dzieje. Czasy pierwszej i ostatniej aktywności nie aktualizowane podczas przetwarzania we wczesnej fazie. Pamiętaj, że te liczby są rejestrowane względem kontekstu wykonania zero — zadania równoległe gałęzi B jeszcze nie istnieją.
Zadanie nadrzędne wznosi się drzewo od węzła 11, przez agregację strumieni w węźle 10 i połączenie scalające w węźle 3, z powrotem do wymiany strumieni zbierania w węźle 2.
Przetwarzanie wczesnej fazy jest teraz zakończone .
Z oryginalnymi EarlyPhases zadzwoń w węźle 2 zbierz strumienie wymiana w końcu zakończone, zadanie nadrzędne powraca do otwierania tej wymiany (możesz prawie pamiętać to wezwanie z początku tej serii). Metoda otwarta w węźle 2 wywołuje teraz CQScanExchangeNew::StartAllProducers utworzyć równoległe zadania dla Oddziału B.
Zadanie nadrzędne teraz czeka na CXPACKET u konsumentu strona węzła 2 zbierz strumienie Wymieniać się. To oczekiwanie będzie trwało, aż nowo utworzone zadania gałęzi B zakończą swoje zagnieżdżone Open dzwoni i wrócił do pełnego otwarcia strony producenta wymiany strumieni zbierania.
Zadania równoległe gałęzi B otwarte
Dwa nowe równoległe zadania w gałęzi B zaczynają się u producenta strona węzła 2 zbierz strumienie Wymieniać się. Zgodnie ze zwykłym iteracyjnym modelem wykonywania w trybie wiersza wywołują:
CQScanXProducerNew::Open(węzeł 2 strona producenta otwarta).CQScanProfileNew::Open(profil dla węzła 3).CQScanMergeJoinNew::Open(węzeł 3 scalający dołączenie).CQScanProfileNew::Open(profil dla węzła 4).CQScanStreamAggregateNew::Open(agregacja strumienia węzła 4).CQScanProfileNew::Open(profil dla węzła 5).CQScanExchangeNew::Open(wymiana strumieni wymiany).
Zadania równoległe podążają za zewnętrznymi (górnymi) danymi wejściowymi do łączenia przez scalanie, tak jak miało to miejsce we wczesnej fazie przetwarzania.
Zakończenie wymiany
Gdy zadania oddziału B dotrą do konsumenta strona wymiany strumieni repartycji w węźle 5, każde zadanie:
- Rejestry z portem wymiany (
CXPort). - Tworzy rury (
CXPipe), które łączą to zadanie z jednym lub większą liczbą zadań po stronie producenta (w zależności od rodzaju wymiany). Bieżąca wymiana to strumienie podziału, więc każde zadanie konsumenckie ma dwa potoki (w DOP 2). Każdy konsument może otrzymać wiersze od jednego z dwóch producentów. - Dodaje
CXPipeMergescalić rzędy z wielu rur (ponieważ jest to wymiana zachowująca porządek). - Tworzy pakiety wierszy (mylnie nazwany
CXPacket) używany do kontroli przepływu i do buforowania rzędów w rurach wymiany. Są one przydzielane z wcześniej przyznanej pamięci zapytań.
Gdy oba zadania równoległe po stronie konsumenta zakończą tę pracę, wymiana węzła 5 jest gotowa do pracy. Dwóch konsumentów (w gałęzi B) i dwóch producentów (w gałęzi C) otworzyli port wymiany, więc węzeł 5 CXPACKET czeka na koniec .
Punkt kontrolny
W obecnym stanie rzeczy:
- Zadanie nadrzędne w Oddziale A czeka na
CXPACKETpo stronie konsumenta węzła 2 gromadzą wymianę strumieni. To oczekiwanie będzie trwało, aż obaj producenci węzła 2 wrócą i otworzą giełdę. - Dwa równoległe zadania w Oddziale B można uruchamiać . Właśnie otworzyli stronę konsumenta wymiany strumieni repartycji w węźle 5.
- Dwa równoległe zadania w Oddziale C zostały właśnie wydane z ich
CXPACKETczekaj i teraz można uruchomić . Dwie agregacje strumieni w węźle 6 (jeden na zadanie równoległe) mogą rozpocząć agregację wierszy z dwóch sortowań w węźle 7. Przypomnijmy, że indeks szuka w węźle 9 zamkniętym jakiś czas temu, gdy sortowania zakończyły fazę wejściową. - Dwa równoległe zadania w Oddziale D czekają na
CXPACKETpo stronie producenta wymiany strumieni partycji w węźle 11. Czekają na otwarcie strony odbiorczej węzła 11 przez dwa równoległe zadania w gałęzi B. Wyszukiwanie indeksu zostało zamknięte, a sorty są gotowe do przejścia do ich faza wyjściowa.
Wiele aktywnych oddziałów
Po raz pierwszy mamy aktywnych wiele gałęzi (B i C) w tym samym czasie, co może być trudne do omówienia. Na szczęście projekt zapytania demonstracyjnego jest taki, że agregacja strumienia w gałęzi C wygeneruje tylko kilka wierszy. Mała liczba wąskich wierszy wyjściowych z łatwością zmieści się w buforach pakietu wierszy w węźle 5 wymiana strumieni repartycyjnych. Zadania gałęzi C mogą zatem kontynuować swoją pracę (i ostatecznie zamknąć) bez czekania, aż strumienie partycjonowania węzła 5 po stronie konsumenta pobiorą jakiekolwiek wiersze.
Dogodnie oznacza to, że możemy pozwolić dwóm równoległym zadaniom z gałęzi C działać w tle, nie martwiąc się o nie. Musimy tylko zająć się tym, co robią dwa równoległe zadania Gałęzi B.
Otwarcie oddziału B zakończone
Przypomnienie Oddziału B:
Dwaj pracownicy równolegli w gałęzi B wracają ze swojego Open połączenia w węźle 5 wymieniają strumienie repartycji. To przenosi je z powrotem przez agregację strumienia w węźle 4 do połączenia scalającego w węźle 3.
Ponieważ wznosimy się drzewo w Open metody, profilery powyżej węzła 5 i węzła 4 rejestrują ostatnią aktywność czas, a także gromadzone czasy, które upłynął i czas pracy procesora (na zadanie). Nie wykonujemy teraz wczesnych faz zadania nadrzędnego, więc nie ma to wpływu na liczby zarejestrowane dla kontekstu wykonania zerowego.
Przy łączeniu scalającym dwa równoległe zadania gałęzi B zaczynają opadać wewnętrzne (dolne) dane wejściowe, przenosząc je przez agregat strumieni w węźle 10 (i kilka profilerów) do strony konsumenta wymiany strumieni podziału w węźle 11.
Oddział D wznawia wykonywanie
Powtórzenie zdarzeń gałęzi C w węźle 5 występuje teraz w strumieniach podziału węzła 11. Strona konsumencka centrali 11 jest zakończona i otwarta. Dwóch producentów z Oddziału D kończy swój CXPACKET czeka, stając się możliwym do uruchomienia ponownie. Pozwolimy, aby zadania gałęzi D działały w tle, umieszczając ich wyniki w buforach wymiany.
Jest teraz sześć równoległych zadań (po dwa w gałęziach B, C i D) wspólnie dzielą czas na dwa harmonogramy przypisane do dodatkowych równoległych zadań w tym zapytaniu.
Otwarcie oddziału A zakończone
Dwa równoległe zadania w gałęzi B wracają z ich Open wywołania w węźle 11 wymieniają strumienie repartycji, powyżej agregacji strumienia węzła 10, przez połączenie scalające w węźle 3 i z powrotem do strony producenta zbieraj strumienie w węźle 2. Profiler ostatni aktywny a skumulowane czasy, które upłynął i czas pracy procesora są aktualizowane, gdy wspinamy się w górę drzewa w zagnieżdżonym Open metody.
U producenta po stronie wymiany strumieni zbierania, dwa równoległe zadania gałęzi B synchronizują się otwierając port wymiany, a następnie czekają na CXPACKET aby otworzyć się po stronie konsumenta.
Zadanie nadrzędne oczekiwanie po stronie konsumenta strumieni zbierania jest teraz udostępnione z jego CXPACKET czekać, co pozwala na całkowite otwarcie portu wymiany po stronie konsumenta. To z kolei zwalnia producentów z ich (krótkiego) CXPACKET czekać. Strumienie zbierania węzła 2 zostały teraz otwarte przez wszystkich właścicieli.
Kończenie skanowania zapytań
Zadanie nadrzędne teraz podnosi drzewo skanowania zapytań z wymiany strumieni zbierania, wracając z Open połączenia na giełdzie, segment i projekt sekwencyjny operatorów w Oddziale A.
To kończy otwarcie drzewo skanowania zapytań, zainicjowane przez wywołanie CQueryScan::StartupQuery . Wszystkie gałęzie planu równoległego rozpoczęły wykonywanie.
Powracające wiersze
Plan wykonania jest gotowy do rozpoczęcia zwracania wierszy w odpowiedzi na polecenie GetRow połączenia w głównym drzewa skanowania zapytań, zainicjowane przez wywołanie CQueryScan::GetRow . Nie będę wdawać się w szczegóły, ponieważ wykracza to ściśle poza zakres artykułu o tym, jak równoległe plany startują .
Jednak krótka sekwencja to:
- Zadanie nadrzędne wywołuje
GetRoww projekcie sekwencji, który wywołujeGetRoww segmencie, który wywołujeGetRowna konsumencie strona wymiany strumieni zbierania. - Jeśli na giełdzie nie ma jeszcze żadnych wierszy, zadanie nadrzędne czeka na
CXCONSUMER. - Tymczasem, niezależnie działające równoległe zadania gałęzi B rekurencyjnie wywołują
GetRowzaczynając od producenta strona wymiany strumieni zbierania. - Wiersze są dostarczane do gałęzi B przez strony konsumentów wymiany strumieni podziału w węzłach 5 i 12.
- Oddziały C i D nadal przetwarzają wiersze ze swoich sortowań przez odpowiednie agregaty strumieni. Zadania gałęzi B mogą wymagać czekania na
CXCONSUMERw strumieniach repartycji węzły 5 i 12, aby cały pakiet wierszy stał się dostępny. - Wiersze wyłaniające się z zagnieżdżonego
GetRowpołączenia w gałęzi B są składane w pakiety wierszy u producenta strona wymiany strumieni zbierania. CXCONSUMERzadania nadrzędnego czekanie po stronie konsumenta strumieni zbierania kończy się, gdy pakiet staje się dostępny.- Wiersz na raz jest następnie przetwarzany przez operatorów nadrzędnych w gałęzi A, a na koniec do klienta.
- W końcu wiersze się kończą i zagnieżdżone
Closepołączenie spływa w dół drzewa, między giełdami, a równoległe wykonywanie dobiega końca.
Podsumowanie i uwagi końcowe
Najpierw podsumowanie sekwencji wykonania tego konkretnego równoległego planu wykonania:
- Zadanie nadrzędne otwiera oddział A . Wczesna faza przetwarzanie rozpoczyna się od wymiany strumieni zbierania.
- Wywołania we wczesnej fazie zadania nadrzędnego schodzą z drzewa skanowania do wyszukiwania indeksu w węźle 9, a następnie wznoszą się z powrotem do wymiany partycjonującej w węźle 5.
- Zadanie nadrzędne rozpoczyna równoległe zadania dla Oddziału C , a następnie czeka, aż wczytają wszystkie dostępne wiersze do blokujących operatorów sortowania w węźle 7.
- Wywołania we wczesnej fazie wznoszą się do złączenia scalającego, a następnie schodzą wewnętrzne dane wejściowe do wymiany w węźle 11.
- Zadania dla Oddziału D są uruchamiane tak samo jak w przypadku gałęzi C, podczas gdy zadanie nadrzędne czeka w węźle 11.
- Wywołania we wczesnej fazie powracają z węzła 11 aż do strumieni zbierania. Kończy się wczesna faza tutaj.
- Zadanie nadrzędne tworzy równoległe zadania dla Oddziału B i czeka na zakończenie otwierania gałęzi B.
- Zadania gałęzi B docierają do strumieni repartycji węzła 5, synchronizują, kończą wymianę i zwalniają zadania gałęzi C, aby rozpocząć agregowanie wierszy z sortowań.
- Kiedy zadania gałęzi B dotrą do strumieni repartycji węzła 12, synchronizują się, kończą wymianę i zwalniają zadania gałęzi D, aby rozpocząć agregowanie wierszy z sortowania.
- Zadania gałęzi B powracają do wymiany strumieni zbierania i synchronizują się, zwalniając zadanie nadrzędne z oczekiwania. Zadanie nadrzędne jest teraz gotowe do rozpoczęcia procesu zwracania wierszy do klienta.
Możesz obejrzeć wykonanie tego planu w Sentry One Plan Explorer. Pamiętaj, aby włączyć opcję „Z profilem zapytania na żywo” w kolekcji Rzeczywisty plan. Zaletą wykonywania zapytania bezpośrednio w Eksploratorze planów jest to, że będziesz mógł przechodzić przez wiele przechwytów we własnym tempie, a nawet przewijać do tyłu. Wyświetli również graficzne podsumowanie we/wy, procesora i oczekiwania zsynchronizowane z danymi profilowania zapytań na żywo.
Dodatkowe uwagi
Rosnące drzewo skanowania zapytań we wczesnej fazie przetwarzania ustawia pierwszy i ostatni czas aktywności w każdym iteratorze profilowania dla zadania nadrzędnego, ale nie kumuluje czasu, który upłynął lub czasu procesora. Wznoszenie drzewa podczas Open i GetRow wywołuje równoległe zestawy zadań ostatniego czasu aktywności i akumuluje czas, który upłynął oraz czas procesora w każdym iteratorze profilowania na zadanie.
Przetwarzanie we wczesnej fazie jest specyficzne dla planów równoległych w trybie wiersza. Konieczne jest upewnienie się, że wymiany są inicjowane we właściwej kolejności, a wszystkie równoległe maszyny działają poprawnie.
Zadanie nadrzędne nie zawsze wykonuje całość przetwarzania we wczesnej fazie. Wczesne fazy zaczynają się od wymiany korzenia, ale sposób, w jaki te wywołania poruszają się po drzewie, zależy od napotkanych iteratorów. Wybrałem połączenie scalające do tego demo, ponieważ wymaga ono przetwarzania we wczesnej fazie dla obu danych wejściowych.
Wczesne fazy w (na przykład) równoległym łączeniu mieszającym propagują tylko dane wejściowe kompilacji. Kiedy skrót mieszający przechodzi w fazę sondowania, otwiera się iteratory na tym wejściu, w tym wszelkie wymiany. Rozpoczyna się kolejna runda przetwarzania we wczesnej fazie, obsługiwana przez (dokładnie) jedno z równoległych zadań, pełniące rolę zadania nadrzędnego.
Gdy przetwarzanie we wczesnej fazie napotka gałąź równoległą zawierającą iterator blokujący, uruchamia dodatkowe zadania równoległe dla tej gałęzi i czeka, aż producenci zakończą fazę otwierania. Ta gałąź może również mieć gałęzie podrzędne, które są obsługiwane w ten sam sposób, rekurencyjnie.
Niektóre gałęzie w planie równoległym w trybie wiersza mogą być wymagane do uruchomienia w jednym wątku (np. ze względu na globalną agregację lub szczyt). Te „strefy szeregowe” działają również na dodatkowym „równoległym” zadaniu, z tą różnicą, że istnieje tylko jedno zadanie, kontekst wykonania i pracownik dla tej gałęzi. Przetwarzanie we wczesnej fazie działa tak samo, niezależnie od liczby zadań przypisanych do oddziału. Na przykład „strefa szeregowa” raportuje czasy zadania nadrzędnego (lub zadania równoległego pełniącego tę rolę), a także pojedynczego zadania dodatkowego. Przejawia się to w planie pokazu jako dane dla „wątku 0” (wczesne fazy) oraz „wątku 1” (dodatkowe zadanie).
Zamykanie myśli
Wszystko to z pewnością stanowi dodatkową warstwę złożoności. Zwrot z tej inwestycji to wykorzystanie zasobów środowiska wykonawczego (głównie wątków i pamięci), skrócone czasy oczekiwania na synchronizację, zwiększona przepustowość, potencjalnie dokładne metryki wydajności i zminimalizowane prawdopodobieństwo wystąpienia równoległych zakleszczeń wewnątrz zapytań.
Chociaż równoległość w trybie wiersza została w dużej mierze przyćmiona przez bardziej nowoczesny silnik wykonywania równoległego w trybie wsadowym, projekt trybu wiersza nadal ma w sobie pewne piękno. Większość iteratorów udaje, że nadal działa w planie szeregowym, z prawie całą synchronizacją, kontrolą przepływu i planowaniem obsługiwaną przez giełdy. Staranność i uwaga widoczne w szczegółach implementacji, takich jak przetwarzanie we wczesnej fazie, umożliwia pomyślne wykonanie nawet największych planów równoległych bez poświęcania zbyt wiele uwagi projektantowi zapytań nad praktycznymi trudnościami.