[ Część 1 | Część 2 | Część 3 ]
W duchu ostatnich tyrad Granta Fritcheya i wysiłków Erin Stellato, odkąd myślę, że zanim się poznaliśmy, chcę zająć się modą, by trąbić i promować ideę porzucania śladów na rzecz wydarzeń rozszerzonych. Gdy ktoś powie śledź , większość ludzi od razu myśli Profiler . Chociaż Profiler to szczególny koszmar, dzisiaj chciałem porozmawiać o domyślnym śledzeniu SQL Server.
W naszym środowisku jest włączony na wszystkich ponad 200 serwerach produkcyjnych i zbiera mnóstwo śmieci, których nigdy nie zbadamy. W rzeczywistości jest tak dużo śmieci, że ważne zdarzenia mogą być przydatne do rozwiązywania problemów z plikami śledzenia, zanim jeszcze nadarzy się okazja. Zacząłem więc rozważać możliwość wyłączenia go, ponieważ:
- to nie jest darmowe (narzut obserwatora na samą aktywność śledzenia, operacje we/wy związane z zapisem do plików śledzenia oraz zajmowane przez nie miejsce);
- na większości serwerów, nigdy nie jest oglądany; na innych rzadko; oraz,
- można łatwo włączyć ponownie aby uzyskać konkretne, odosobnione rozwiązywanie problemów.
Kilka innych rzeczy wpływa na wartość domyślnego śledzenia. Nie można go w żaden sposób konfigurować — nie można zmienić zbieranych zdarzeń, dodawać filtrów i kontrolować, ile plików przechowuje (5), jak duże mogą uzyskać (20 MB każdy) , lub gdzie są przechowywane (SERVERPROPERTY('ErrorLogFileName') ). Jesteśmy więc całkowicie zdani na łaskę obciążenia — na dowolnym serwerze nie możemy przewidzieć, jak daleko mogą się cofnąć dane (zdarzenia z większymi TextData na przykład wartości mogą zajmować dużo więcej miejsca i szybciej wypychać starsze zdarzenia). Czasami może cofnąć się o tydzień, innym razem może cofnąć się o kilka minut.
Analiza bieżącego stanu
Uruchomiłem poniższy kod na 224 instancjach produkcyjnych, aby zrozumieć, jaki rodzaj szumu wypełnia domyślny ślad w naszym środowisku. Jest to prawdopodobnie bardziej skomplikowane niż powinno być i nie jest nawet tak złożone, jak ostatnie zapytanie, którego użyłem, ale jest to przyzwoity punkt wyjścia do analizy podziału typów zdarzeń wysokiego poziomu, które są obecnie przechwytywane:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (Predykat EventSubClass ma na celu zapobieganie podwójnemu liczeniu zdarzeń DDL.W przypadku mapy wartości EventClass wymieniłem je w tej odpowiedzi na Stack Exchange.)
A wyniki nie są ładne (typowe wyniki z losowego serwera). Poniższe dane nie przedstawiają dokładnego wyniku tego zapytania, ale spędziłem trochę czasu, agregując wyniki w bardziej przystępny format, aby zobaczyć, ile danych było użytecznych, a ile szumu (kliknij, aby powiększyć):
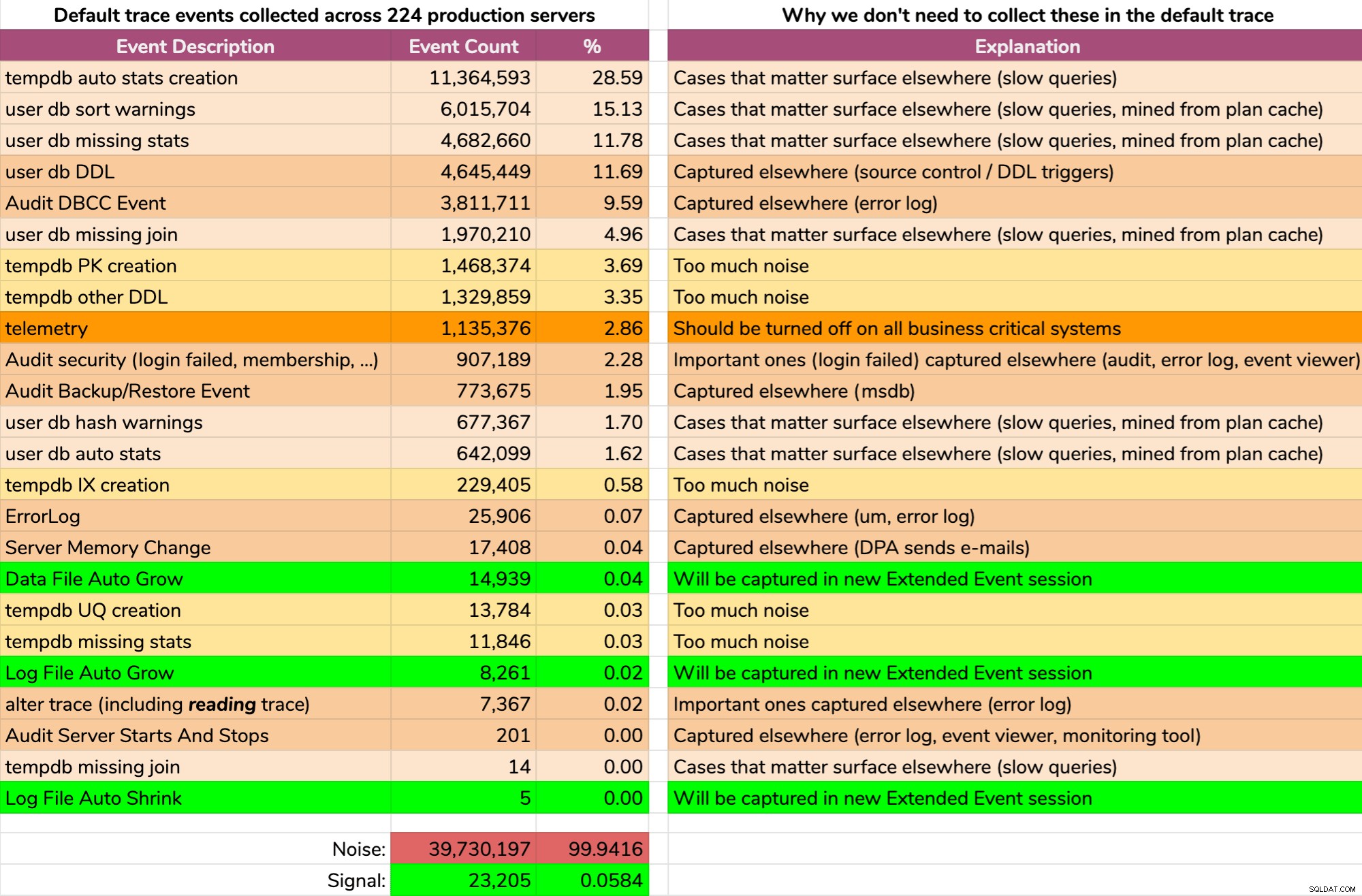
Prawie cały hałas (99,94%). Jedyną użyteczną rzeczą, jakiej kiedykolwiek potrzebowaliśmy z domyślnego śledzenia, były zdarzenia wzrostu i zmniejszania plików, ponieważ były to jedyne rzeczy, których nie przechwytywaliśmy gdzie indziej w taki czy inny sposób. Ale nawet na tym nie zawsze możemy polegać, ponieważ dane znikają tak szybko.
Inny sposób, w jaki podzieliłem dane:najstarsze zdarzenie na instancję. Niektóre instancje miały tak dużo szumu, że nie mogły utrzymać domyślnych danych śledzenia dłużej niż kilka minut! Zamazałem nazwy serwerów, ale to są prawdziwe dane (to 20 serwerów z najkrótszą historią – kliknij, aby powiększyć):
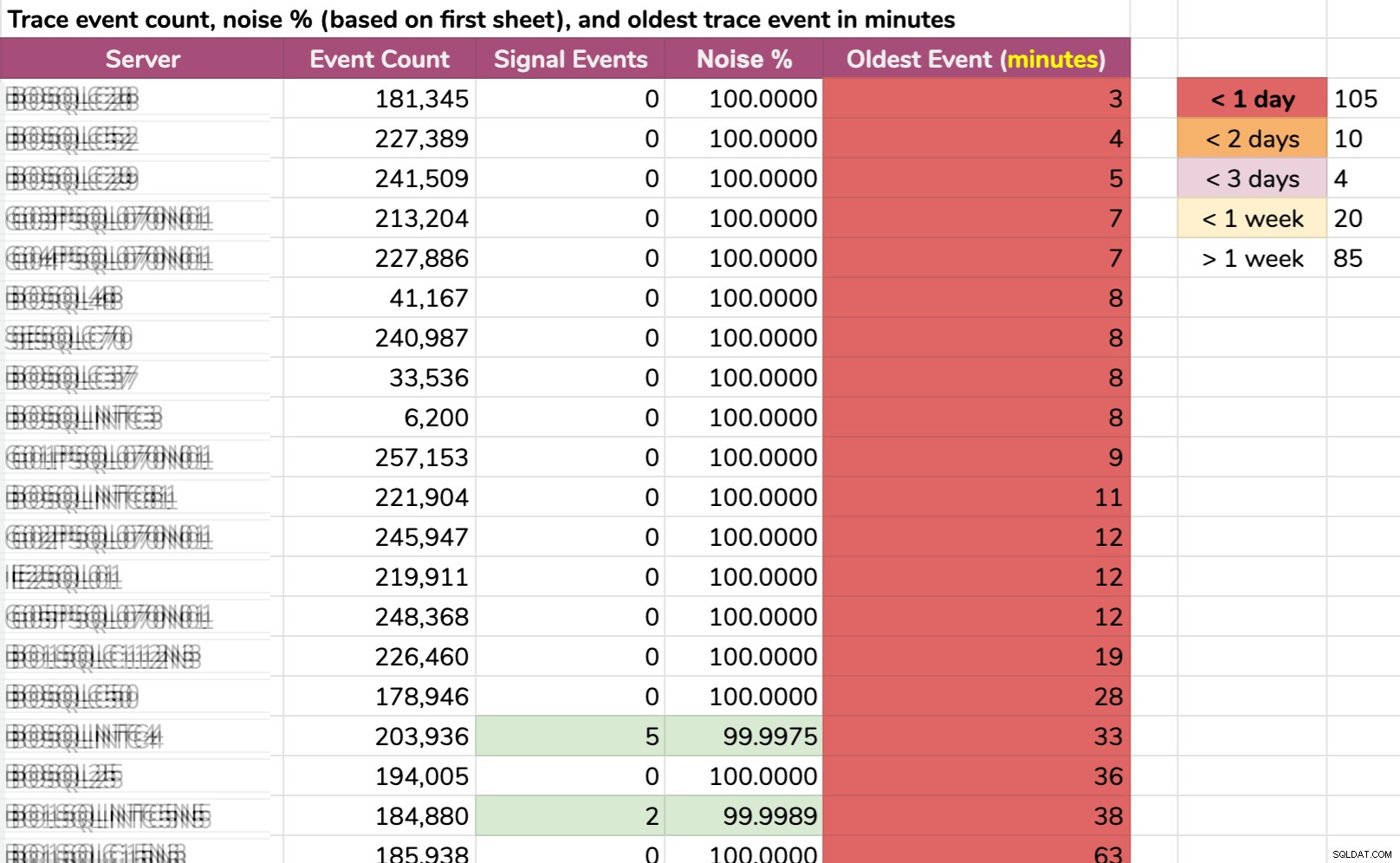
Nawet jeśli ślad zbierał tylko istotne informacje i wydarzyło się coś interesującego, musielibyśmy działać szybko, aby to złapać, w zależności od serwera. Jeśli tak się stało:
- 20 minut temu , to zniknęłoby już w 15 instancjach .
- tym razem wczoraj , zniknęłoby w 105 wystąpieniach .
- dwa dni temu , zniknęłoby w 115 wystąpieniach .
- ponad tydzień temu , zniknęłoby w 139 wystąpieniach .
Na drugim końcu też mieliśmy kilka serwerów, ale są one nieciekawe w tym kontekście; te serwery działają w ten sposób po prostu dlatego, że nie dzieje się tam nic ciekawego (np. nie są zajęte lub nie są częścią żadnego krytycznego obciążenia).
Po stronie plusów…
Badanie domyślnego śledzenia ujawniło pewne błędy konfiguracyjne na kilku naszych serwerach:
- Kilka serwerów nadal miało włączoną telemetrię . Jestem całkowicie za pomaganiem firmie Microsoft w określonych środowiskach, ale bez żadnych kosztów ogólnych w przypadku systemów o znaczeniu krytycznym dla firmy.
- Niektóre zadania synchronizacji w tle dodawały członków do ról na ślepo , w kółko, bez sprawdzania, czy byli już w tych rolach. Nie jest to szkodliwe samo w sobie, zwłaszcza, że te zdarzenia nie będą już wypełniać domyślnego śladu, ale prawdopodobnie wypełniają również audyty szumem i prawdopodobnie w tym samym schemacie występują inne ślepe operacje ponownego zastosowania.
- Ktoś włączył automatyczne zmniejszanie gdzieś (dobry żal!), więc to było coś, co chciałem wyśledzić i zapobiec ponownemu wystąpieniu (nowy XE również przechwyci te wydarzenia).
Doprowadziło to do dalszych zadań mających na celu naprawienie tych problemów i/lub dodanie warunków do istniejącej już automatyzacji. Dzięki temu możemy zapobiec nawrotom, nie polegając tylko na tym, że będziemy mieli wystarczająco dużo szczęścia, aby spotkać je w przyszłości podczas przeglądu domyślnego śledzenia, zanim zostaną wdrożone.
…ale problem pozostaje
W przeciwnym razie wszystko jest albo informacją, na której nie możemy działać, albo, jak opisano na powyższej grafice, zdarzeniami, które już przechwyciliśmy gdzie indziej. I znowu, jedynymi danymi, które mnie interesują z domyślnego śledzenia, których jeszcze nie przechwytujemy innymi sposobami, są zdarzenia związane ze wzrostem i pomniejszaniem pliku (nawet jeśli domyślny ślad przechwytuje tylko automatyczne odmiany).
Ale większym problemem nie jest tak naprawdę głośność hałasu. Poradzę sobie z dużymi, ogromnymi plikami śledzenia z dużą ilością śmieci, ponieważ klauzule WHERE zostały wymyślone właśnie w tym celu. Prawdziwym problemem jest to, że ważne wydarzenia znikały zbyt szybko.
Odpowiedź
Odpowiedź, przynajmniej w naszym scenariuszu, była prosta:wyłącz domyślne śledzenie, ponieważ nie warto go uruchamiać, jeśli nie można na nim polegać.
Ale biorąc pod uwagę ilość hałasu powyżej, co powinno go zastąpić? Cokolwiek?
Możesz potrzebować sesji zdarzeń rozszerzonych, która rejestruje wszystko przechwycony domyślny ślad. Jeśli tak, Jonathan Kehayias cię obejmuje. Dałoby to te same informacje, ale z kontrolą nad takimi rzeczami, jak przechowywanie, miejsce przechowywania danych i, gdy poczujesz się bardziej komfortowo, możliwość stopniowego usuwania niektórych głośniejszych lub mniej przydatnych zdarzeń w czasie.
Mój plan był nieco bardziej agresywny i szybko stał się „prostym” procesem wykonywania następujących czynności na wszystkich serwerach w środowisku (przez CMS):
- opracować sesję Extended Events, która przechwytuje tylko zdarzenia zmiany pliku (zarówno ręczne, jak i automatyczne)
- wyłącz domyślne śledzenie
- utwórz widok, aby ułatwić naszym zespołom korzystanie z danych docelowych
Zwróć uwagę, że nie sugeruję ślepego wyłączania domyślnego śledzenia , wyjaśniając tylko, dlaczego zdecydowałem się to zrobić w naszym środowisku. W nadchodzących postach z tej serii pokażę nową sesję Extended Events, widok, który uwidacznia podstawowe dane, kod, którego użyłem do wdrożenia tych zmian na wszystkich serwerach, oraz potencjalne skutki uboczne, o których należy pamiętać.
[ Część 1 | Część 2 | Część 3 ]