Ten artykuł jest trzecią częścią serii poświęconej złożoności NULL. W części 1 omówiłem znaczenie znacznika NULL i jego zachowanie w porównaniach. W części 2 opisałem NULL niespójności w traktowaniu różnych elementów językowych. W tym miesiącu opiszę zaawansowane standardowe funkcje obsługi NULL, które nie zostały jeszcze wprowadzone do T-SQL, oraz obejścia, których obecnie używają ludzie.
Będę nadal używał przykładowej bazy danych TSQLV5, tak jak w zeszłym miesiącu w niektórych moich przykładach. Skrypt, który tworzy i wypełnia tę bazę danych, oraz jego diagram ER można znaleźć tutaj.
DISTINCT predykat
W części 1 serii wyjaśniłem, w jaki sposób wartości NULL zachowują się w porównaniach i jak zawiłości wokół trójwartościowej logiki predykatów stosowanej przez SQL i T-SQL. Rozważ następujący predykat:
X =YJeśli którykolwiek predykand ma wartość NULL — również gdy oba mają wartość NULL — wynikiem tego predykatu jest wartość logiczna UNKNOWN. Z wyjątkiem operatorów IS NULL i IS NOT NULL, to samo dotyczy wszystkich innych operatorów, w tym innych niż (<>):
X <> YCzęsto w praktyce chcesz, aby wartości NULL zachowywały się jak wartości inne niż NULL dla celów porównawczych. Dzieje się tak zwłaszcza wtedy, gdy używasz ich do reprezentowania braku, ale nie ma zastosowania wartości. Norma ma rozwiązanie tej potrzeby w postaci funkcji zwanej predykatem DISTINCT, która ma następującą postać:
Zamiast używać semantyki równości lub nierówności, ten predykat używa semantyki opartej na odrębności podczas porównywania predykandów. Jako alternatywę dla operatora równości (=) możesz użyć następującego formularza, aby uzyskać TRUE, gdy dwa predykandy są takie same, w tym gdy oba są wartościami NULL, i FALSE, gdy nie są, w tym gdy jeden jest NULL i inne nie:
X NIE RÓŻNI SIĘ OD YJako alternatywa dla innego niż operator (<>), użyjesz następującej formy, aby uzyskać TRUE, gdy dwa predykandy są różne, w tym gdy jeden jest NULL, a drugi nie, oraz FALSE, gdy są takie same, w tym gdy oba mają wartość NULL:
X RÓŻNI SIĘ OD YZastosujmy predykat DISTINCT do przykładów, których użyliśmy w części 1 serii. Przypomnij sobie, że musiałeś napisać zapytanie, które podało parametr wejściowy @dt, zwraca zamówienia, które zostały wysłane w dniu wejścia, jeśli nie jest NULL, lub w ogóle nie zostały wysłane, jeśli dane wejściowe mają wartość NULL. Zgodnie ze standardem do zaspokojenia tej potrzeby użyjesz następującego kodu z predykatem DISTINCT:
SELECT identyfikator zamówienia, datawysyłkiFROM Sprzedaż.ZamówieniaWHERE datawysyłki NIE JEST ODRÓŻNIONA OD @dt;
Na razie przypomnij sobie z Części 1, że możesz użyć kombinacji predykatu EXISTS i operatora INTERSECT jako obejścia SARGable w T-SQL, na przykład:
SELECT identyfikator zamówienia, data wysyłkiFROM Sales.OrdersWHERE EXISTS (SELECT data wysyłki INTERSECT SELECT @dt);
Aby zwrócić zamówienia, które zostały wysłane w innym dniu niż data wejściowa @dt, należy użyć następującego zapytania:
SELECT identyfikator zamówienia, datawysyłkiFROM Sprzedaż.ZamówieniaWHERE datawysyłki JEST RÓŻNA OD @dt;
Obejście, które działa w T-SQL, wykorzystuje kombinację predykatu EXISTS i operatora EXCEPT, na przykład:
SELECT identyfikator zamówienia, data wysyłkiFROM Sales.OrdersWHERE EXISTS (SELECT data wysyłki EXCEPT SELECT @dt);
W części 1 omówiłem również scenariusze, w których trzeba łączyć tabele i stosować semantykę opartą na odrębności w predykacie złączenia. W moich przykładach użyłem tabel nazwanych T1 i T2, z NULLable łączonymi kolumnami nazwanymi k1, k2 i k3 po obu stronach. Zgodnie ze standardem do obsługi takiego sprzężenia użyjesz następującego kodu:
WYBIERZ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1INNER DOŁĄCZ dbo.T2 ON T1.k1 NIE RÓŻNI SIĘ OD T2.k1 I T1.k2 NIE RÓŻNI SIĘ OD T2 .k2 I T1.k3 NIE RÓŻNI SIĘ OD T2.k3;
Na razie, podobnie jak w poprzednich zadaniach filtrowania, możesz użyć kombinacji predykatu EXISTS i operatora INTERSECT w klauzuli ON złączenia, aby emulować odrębny predykat w T-SQL, na przykład:
WYBIERZ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1INNER JOIN dbo.T2 ON EXISTS(WYBIERZ T1.k1, T1.k2, T1.k3 PRZECIĘCIE WYBIERZ T2.k1 , T2.k2, T2.k3);
W przypadku użycia w filtrze ten formularz jest zgodny z SARG, a gdy jest używany w złączeniach, może potencjalnie polegać na kolejności indeksowania.
Jeśli chcesz zobaczyć predykat DISTINCT dodany do T-SQL, możesz na niego zagłosować tutaj.
Jeśli po przeczytaniu tej sekcji nadal czujesz się trochę nieswojo z predykatem DISTINCT, nie jesteś sam. Być może ten predykat jest znacznie lepszy niż jakiekolwiek istniejące obejście, które mamy obecnie w T-SQL, ale jest nieco rozwlekłe i nieco mylące. Używa formy negatywnej, aby zastosować to, co w naszym umyśle jest pozytywnym porównaniem i na odwrót. Cóż, nikt nie powiedział, że wszystkie standardowe sugestie są idealne. Jak zauważył Charlie w jednym ze swoich komentarzy do Części 1, lepiej działałby następujący uproszczony formularz:
Jest zwięzły i znacznie bardziej intuicyjny. Zamiast X NIE ODRÓŻNIA SIĘ OD Y, użyjesz:
X JEST YI zamiast X IS DISTINCT FROM Y, użyjesz:
X NIE JEST YTen proponowany operator jest w rzeczywistości zgodny z już istniejącymi operatorami IS NULL i IS NOT NULL.
W przypadku naszego zadania zapytania, aby zwrócić zamówienia, które zostały wysłane w dacie wejściowej (lub nie zostały wysłane, jeśli dane wejściowe mają wartość NULL), należy użyć następującego kodu:
SELECT identyfikator zamówienia, data wysyłkiFROM Sales.OrdersWHERE data wysyłki IS @dt;
Aby zwrócić zamówienia, które zostały wysłane w dniu innym niż data wejściowa, użyj następującego kodu:
SELECT identyfikator zamówienia, datawysyłkiFROM Sprzedaż.ZamówieniaWHERE datawysyłki NIE JEST @dt;
Jeśli Microsoft kiedykolwiek zdecyduje się na dodanie odrębnego predykatu, byłoby dobrze, gdyby wspierał zarówno standardową pełną formę, jak i tę niestandardową, ale bardziej zwięzłą i bardziej intuicyjną formę. Co ciekawe, procesor zapytań SQL Server obsługuje już wewnętrzny operator porównania IS, który wykorzystuje tę samą semantykę, co opisany tutaj pożądany operator IS. Szczegóły dotyczące tego operatora można znaleźć w artykule Paula White'a Plany nieudokumentowanych zapytań:Porównania równości (wyszukaj „IS zamiast EQ”). To, czego brakuje, to ujawnienie go na zewnątrz jako część T-SQL.
Klauzula traktowania NULL (IGNORE NULLS | RESPECT NULLS)
Podczas korzystania z funkcji okna przesunięcia LAG, LEAD, FIRST_VALUE i LAST_VALUE, czasami trzeba kontrolować zachowanie leczenia NULL. Domyślnie te funkcje zwracają wynik żądanego wyrażenia na żądanej pozycji, niezależnie od tego, czy wynikiem wyrażenia jest rzeczywista wartość, czy NULL. Jednak czasami chcesz kontynuować ruch w odpowiednim kierunku (wstecz dla LAG i LAST_VALUE, naprzód dla LEAD i FIRST_VALUE) i zwrócić pierwszą wartość inną niż NULL, jeśli jest obecna, lub NULL w przeciwnym razie. Standard zapewnia kontrolę nad tym zachowaniem za pomocą klauzuli traktowania NULL o następującej składni:
offset_function(Domyślnym ustawieniem w przypadku, gdy klauzula leczenia NULL nie jest określona, jest opcja RESPECT NULLS, co oznacza, że zwraca wszystko, co jest obecne w żądanej pozycji, nawet jeśli NULL. Niestety ta klauzula nie jest jeszcze dostępna w T-SQL. Podam przykłady standardowej składni przy użyciu funkcji LAG i FIRST_VALUE, a także obejść, które działają w T-SQL. Możesz użyć podobnych technik, jeśli potrzebujesz takiej funkcjonalności z LEAD i LAST_VALUE.
Jako przykładowych danych użyję tabeli o nazwie T4, którą tworzysz i wypełniasz za pomocą następującego kodu:
DROP TABLE IF EXISTS dbo.T4;GO CREATE TABLE dbo.T4( id INT NOT NULL OGRANICZENIE PK_T4 PRIMARY KEY, col1 INT NULL); INSERT INTO dbo.T4(id, col1) VALUES( 2, NULL),( 3, 10),( 5, -1),( 7, NULL),(11, NULL),(13, -12),( 17, NULL), (19, NULL), (23, 1759);
Istnieje typowe zadanie polegające na zwróceniu ostatniego odpowiedniego wartość. NULL w col1 oznacza brak zmiany wartości, podczas gdy wartość różna od NULL wskazuje nową odpowiednią wartość. Musisz zwrócić ostatnią wartość kol1 inną niż NULL na podstawie kolejności identyfikatorów. Używając standardowej klauzuli o traktowaniu NULL, poradzisz sobie z tym zadaniem w następujący sposób:
SELECT id, col1,COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastvalFROM dbo.T4;
Oto oczekiwany wynik tego zapytania:
id col1 lastval----------- ----------- -----------2 NULL NULL3 10 105 -1 -17 NULL - 111 NULL -113 -12 -1217 NULL -1219 NULL -1223 1759 1759
W T-SQL istnieje obejście, ale obejmuje ono dwie warstwy funkcji okna i wyrażenie tabelowe.
W pierwszym kroku używasz funkcji okna MAX, aby obliczyć kolumnę o nazwie grp przechowującą do tej pory maksymalną wartość identyfikatora, gdy col1 nie jest NULL, na przykład:
SELECT id, col1,MAX(CASE, GDY col1 NIE JEST NULL THEN id END) OVER (KOLEJNOŚĆ WEDŁUG WIERSZY ID, NIEOGRANICZONE POSTĘPOWANIE) AS grpFROM dbo.T4;
Ten kod generuje następujące dane wyjściowe:
id col1 grp----------- ----------- -----------2 NULL NULL3 10 35 -1 57 NULL 511 NULL 513 -12 1317 NULL 1319 NULL 1323 1759 23
Jak widać, unikalna wartość grp jest tworzona za każdym razem, gdy następuje zmiana wartości col1.
W drugim kroku definiujesz CTE na podstawie zapytania z kroku pierwszego. Następnie w zewnętrznym zapytaniu zwracasz maksymalną dotychczasową wartość col1 w obrębie każdej partycji zdefiniowanej przez grp. To ostatnia wartość col1 różna od NULL. Oto kompletny kod rozwiązania:
with C AS(SELECT id, col1, MAX(CASE, GDY col1 IS NOT NULL THEN id END) OVER(ORDER BY id ROWERS UNBOUNDED PRECEDING) AS grpFROM dbo.T4)SELECT id, col1,MAX(col1) OVER( PARTYCJA BY grp ZAMÓWIENIE BY id WIERSZE BEZ OGRANICZENIA POSTĘPOWANIE) AS lastvalFROM C;
Oczywiście, to o wiele więcej kodu i pracy w porównaniu ze zwykłym powiedzeniem IGNORE_NULLS.
Inną powszechną potrzebą jest zwrócenie pierwszej odpowiedniej wartości. W naszym przypadku załóżmy, że musisz zwrócić pierwszą jak dotąd niezerową wartość col1 na podstawie kolejności identyfikatorów. Używając standardowej klauzuli traktowania NULL, obsłużysz zadanie za pomocą funkcji FIRST_VALUE i opcji IGNORE NULLS, na przykład:
SELECT id, col1,FIRST_VALUE(col1) IGNORE NULLS OVER(ORDER BY id ROWS UNBOUNDED PRECEDING) AS firstvalFROM dbo.T4;
Oto oczekiwany wynik tego zapytania:
id col1 firstval----------- ----------- -----------2 NULL NULL3 10 105 -1 107 NULL 1011 NULL 1013 -12 1017 NULL 1019 NULL 1023 1759 10
Obejście w T-SQL wykorzystuje technikę podobną do tej stosowanej dla ostatniej wartości innej niż NULL, tylko zamiast podejścia podwójnego MAX, używasz funkcji FIRST_VALUE na górze funkcji MIN.
W pierwszym kroku używasz funkcji okna MIN, aby obliczyć kolumnę o nazwie grp przechowującą dotychczas minimalną wartość identyfikatora, gdy col1 nie ma wartości NULL, na przykład:
SELECT id, col1,MIN(CASE, GDY col1 NIE JEST NULL THEN id END) OVER (KOLEJNOŚĆ WEDŁUG WIERSZY ID, NIEOGRANICZONE POSTĘPOWANIE) AS grpFROM dbo.T4;
Ten kod generuje następujące dane wyjściowe:
id col1 grp----------- ----------- -----------2 NULL NULL3 10 35 -1 37 NULL 311 NULL 313 -12 317 NULL 319 NULL 323 1759 3
Jeśli istnieją jakiekolwiek NULL przed pierwszą odpowiednią wartością, otrzymujesz dwie grupy — pierwsza z NULL jako wartością grp i druga z pierwszym identyfikatorem innym niż NULL jako wartością grp.
W drugim kroku umieszczasz kod pierwszego kroku w wyrażeniu tabelowym. Następnie w zapytaniu zewnętrznym używasz funkcji FIRST_VALUE, podzielonej na partycje przez grp, aby zebrać pierwszą odpowiednią wartość (inną niż NULL), jeśli jest obecna, i NULL w przeciwnym razie, na przykład:
WITH C AS(SELECT id, col1, MIN(CASE, GDY col1 NOT NULL THEN id END) OVER(ORDER BY id ROWS UNBOUNDED PRECEDING) AS grpFROM dbo.T4)SELECT id, col1,FIRST_VALUE(col1) OVER( PARTYCJA BY grp ZAMÓWIENIE BY id WIERSZE BEZ OGRANICZEŃ POSTĘPOWANIE) AS firstvalFROM C;
Ponownie, to dużo kodu i pracy w porównaniu do zwykłego korzystania z opcji IGNORE_NULLS.
Jeśli uważasz, że ta funkcja może być dla Ciebie przydatna, możesz głosować za włączeniem jej do T-SQL tutaj.
ZAMÓW WEDŁUG NULLS PIERWSZY | NULL OSTATNIE
Kiedy zamawiasz dane, czy to do celów prezentacji, okienkowania, filtrowania TOP/OFFSET-FETCH, czy w jakimkolwiek innym celu, pojawia się pytanie, jak powinny zachowywać się wartości NULL w tym kontekście? Standard SQL mówi, że wartości NULL powinny być sortowane razem przed lub po wartościach innych niż NULL i pozostawiają to implementacji, aby określić jeden lub drugi sposób. Jednak niezależnie od tego, co wybierze sprzedawca, musi to być spójne. W języku T-SQL wartości NULL są porządkowane jako pierwsze (przed wartościami innymi niż NULL) podczas korzystania z kolejności rosnącej. Rozważ następujące zapytanie jako przykład:
SELECT id zamówienia, data wysyłkiFROM Sprzedaż.ZamówieniaORDER BY datawysyłki, id zamówienia;
To zapytanie generuje następujące dane wyjściowe:
Dane wyjściowe pokazują, że niewysłane zamówienia, które mają NULL datę wysłania, są złożone przed zamówieniami wysłanymi, które mają istniejącą odpowiednią datę wysłania.
Ale co, jeśli potrzebujesz wartości NULL, aby zamówić jako ostatni podczas korzystania z kolejności rosnącej? Norma ISO/IEC SQL obsługuje klauzulę, którą stosuje się do wyrażenia porządkującego kontrolującego, czy wartości NULL są uporządkowane jako pierwsze czy ostatnie. Składnia tej klauzuli to:
Aby sprostać naszym potrzebom, zwracając zamówienia posortowane według dat wysyłki, rosnąco, ale z niewysłanymi zamówieniami zwróconymi jako ostatni, a następnie według ich identyfikatorów zamówień jako rozstrzygający, użyjesz następującego kodu:
SELECT identyfikator zamówienia, data wysyłkiFROM Sprzedaż.ZamówieniaORDER BY data wysyłki NULLS LAST, identyfikator zamówienia;
Niestety, ta klauzula porządkowania NULLS nie jest dostępna w T-SQL.
Powszechnym obejściem używanym przez ludzi w T-SQL jest poprzedzenie wyrażenia porządkującego wyrażeniem CASE, które zwraca stałą z niższą wartością porządkowania dla wartości innych niż NULL niż dla wartości NULL (nazwiemy to rozwiązanie Zapytanie 1):
WYBIERZ id.zamówienia, datawysyłkiFROM Sprzedaż.ZamówieniaPORZĄDKOWANIE WEDŁUG PRZYPADKU KIEDY datawysyłki NIE JEST NULL, TO 0 ELSE 1 END, datawysyłki, id zamówienia;
To zapytanie generuje żądane dane wyjściowe z wartościami NULL wyświetlanymi na końcu:
Istnieje indeks pokrycia zdefiniowany w tabeli Sales.Orders, z kolumną shippingdate jako kluczem. Jednak podobnie jak kolumna z manipulowanym filtrowaniem zapobiega SARGability filtra i możliwości zastosowania indeksu wyszukiwania, manipulowana kolumna porządkowania uniemożliwia poleganie na kolejności indeksów w celu obsługi klauzuli ORDER BY zapytania. Dlatego SQL Server generuje plan dla Zapytania 1 z jawnym operatorem sortowania, jak pokazano na rysunku 1.
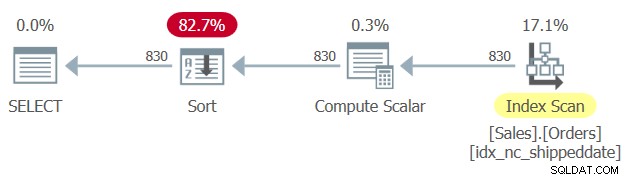 Rysunek 1:Plan dla zapytania 1
Rysunek 1:Plan dla zapytania 1
Czasami rozmiar danych nie jest tak duży, aby jawne sortowanie stanowiło problem. Ale czasami tak jest. Przy jawnym sortowaniu skalowalność zapytania staje się bardzo liniowa (płacisz więcej za wiersz, im więcej masz wierszy), a czas odpowiedzi (czas potrzebny do zwrócenia pierwszego wiersza) jest opóźniony.
Istnieje sztuczka, której możesz użyć, aby uniknąć jawnego sortowania w takim przypadku, dzięki rozwiązaniu, które jest zoptymalizowane za pomocą operatora łączenia łączenia z zachowaniem kolejności. Możesz znaleźć szczegółowe omówienie tej techniki stosowanej w różnych scenariuszach w SQL Server:Unikanie sortowania z konkatenacją łączenia łączenia. Pierwszy krok w rozwiązaniu ujednolica wyniki dwóch zapytań:jedno zapytanie zwracające wiersze, w których kolumna porządkowania nie ma wartości NULL, z kolumną wynikową (nazwiemy ją sortcol) opartą na stałej z pewną wartością porządkowania, powiedzmy 0, oraz inne zapytanie zwracające wiersze z wartościami NULL, z sortcol ustawioną na stałą o wyższej wartości porządkowania niż w pierwszym zapytaniu, powiedzmy 1. W drugim kroku definiujesz wyrażenie tabelowe na podstawie kodu z pierwszego kroku, a następnie w zewnętrznym zapytaniu uporządkuj wiersze z wyrażenia tabeli najpierw według sortcol, a następnie według pozostałych elementów porządkujących. Oto kompletny kod rozwiązania implementujący tę technikę (nazwiemy to rozwiązanie Zapytanie 2):
WITH C AS(SELECT idzam;
Plan dla tego zapytania pokazano na rysunku 2.
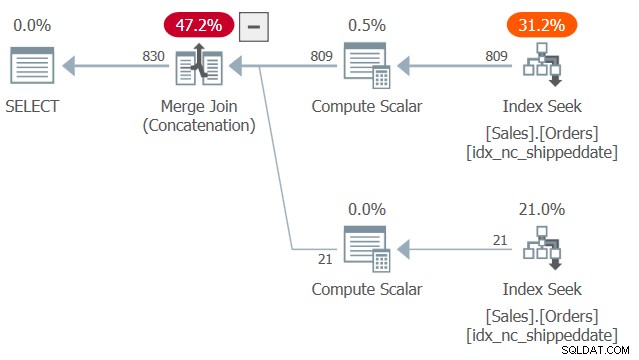 Rysunek 2:Plan dla zapytania 2
Rysunek 2:Plan dla zapytania 2
Zwróć uwagę na dwa wyszukiwania i uporządkowane skany zakresów w indeksie obejmującym idx_nc_shippeddate — jedno pobiera wiersze, w których sentdateis nie ma wartości NULL, a drugie pobiera wiersze, w których senddate ma wartość NULL. Następnie, podobnie jak algorytm Merge Join działa w łączeniu, algorytm Merge Join (Konkatenacja) ujednolica wiersze z dwóch uporządkowanych stron w sposób podobny do zamka błyskawicznego i zachowuje kolejność przetwarzania w celu obsługi potrzeb porządkowania prezentacji zapytania. Nie twierdzę, że ta technika jest zawsze szybsza niż bardziej typowe rozwiązanie z wyrażeniem CASE, które wykorzystuje jawne sortowanie. Jednak pierwsza ma skalowanie liniowe, a druga ma skalowanie n log n. Tak więc pierwsza będzie lepiej radzić sobie z dużą liczbą wierszy, a druga z małą liczbą.
Oczywiście dobrze jest mieć rozwiązanie dla tej powszechnej potrzeby, ale byłoby znacznie lepiej, gdyby T-SQL dodał w przyszłości obsługę standardowej klauzuli porządkowania NULL.
Wniosek
Standard ISO/IEC SQL ma sporo funkcji obsługi NULL, które nie zostały jeszcze wprowadzone do T-SQL. W tym artykule omówiłem niektóre z nich:predykat DISTINCT, klauzulę traktowania NULL i kontrolowanie, czy wartości NULL są uporządkowane jako pierwsze czy ostatnie. Przedstawiłem również obejścia tych funkcji, które są obsługiwane w T-SQL, ale są one oczywiście kłopotliwe. W przyszłym miesiącu kontynuuję dyskusję, omawiając standardowe ograniczenie niepowtarzalności, czym różni się ono od implementacji T-SQL i obejść, które można zaimplementować w T-SQL.



