[ Część 1 | Część 2 | Część 3 ]
W części 1 tej serii wypróbowałem kilka sposobów kompresji tabeli o pojemności 1 TB. Chociaż uzyskałem przyzwoite wyniki w mojej pierwszej próbie, chciałem sprawdzić, czy mogę poprawić wydajność w części 2. Nakreśliłem tam kilka rzeczy, które moim zdaniem mogą powodować problemy z wydajnością, i wyjaśniłem, jak lepiej podzielić tabelę docelową dla optymalnej kompresji magazynu kolumn. Już:
- podzielił tabelę na 8 partycji (po jednej na rdzeń);
- umieść plik danych każdej partycji we własnej grupie plików; oraz,
- ustaw kompresję archiwum na wszystkich partycjach oprócz „aktywnej”.
Nadal muszę to zrobić, aby każdy harmonogram zapisywał wyłącznie na swojej własnej partycji.
Najpierw muszę wprowadzić zmiany w utworzonej przeze mnie tabeli wsadowej. Potrzebuję kolumny do przechowywania liczby wierszy dodanych na partię (rodzaj samokontrolującego się sprawdzania poprawności) oraz czasów rozpoczęcia/zakończenia w celu pomiaru postępu.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Następnie muszę utworzyć tabelę, aby zapewnić powinowactwo — nigdy nie chcemy, aby więcej niż jeden proces działał w dowolnym harmonogramie, nawet jeśli oznaczałoby to stratę czasu na ponowną próbę logiki. Potrzebujemy więc tabeli, która będzie śledzić każdą sesję w określonym harmonogramie i zapobiegać układaniu się:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
Pomysł jest taki, że miałbym osiem instancji aplikacji (SQLQueryStress), z których każda działałaby na dedykowanym harmonogramie, obsługując tylko dane przeznaczone dla określonej partycji / grupy plików / pliku danych, ~100 milionów wierszy na raz (kliknij, aby powiększyć) :
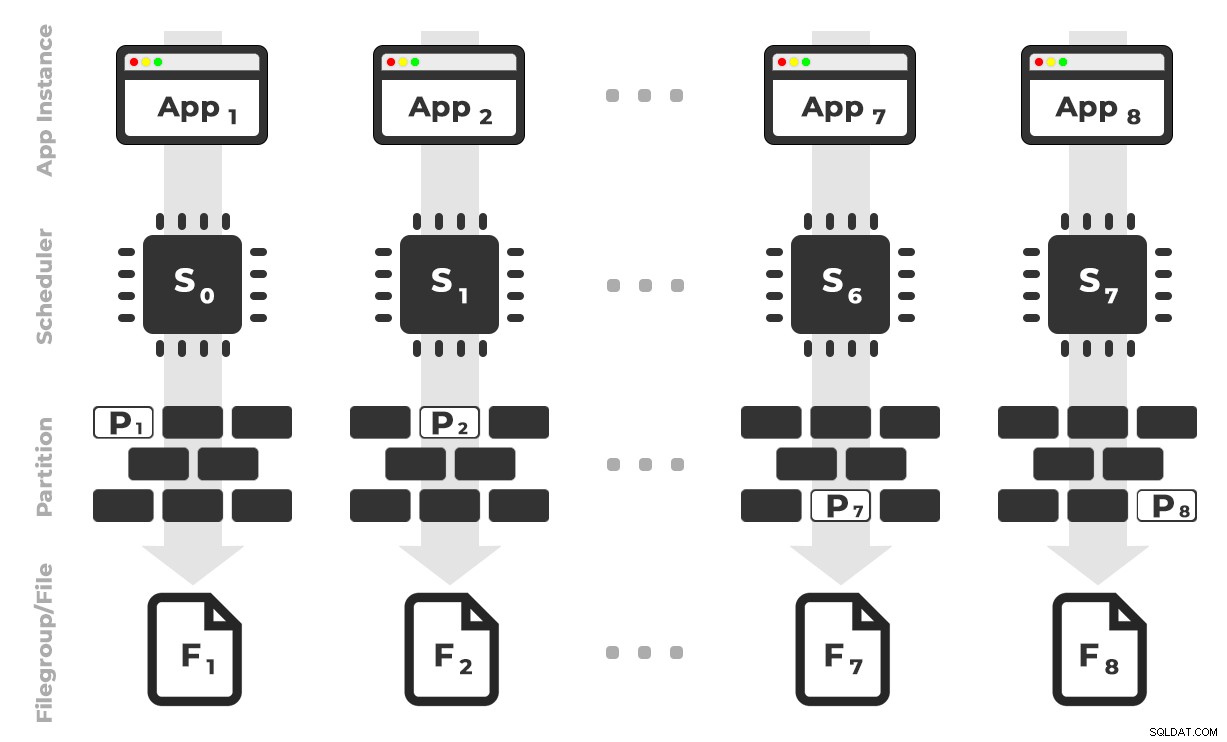 Aplikacja 1 pobiera harmonogram 0 i zapisuje na partycji 1 w grupie plików 1 i tak dalej …
Aplikacja 1 pobiera harmonogram 0 i zapisuje na partycji 1 w grupie plików 1 i tak dalej …
Następnie potrzebujemy procedury składowanej, która umożliwi każdemu wystąpieniu aplikacji zarezerwowanie czasu w jednym harmonogramie. Jak wspomniałem w poprzednim poście, nie jest to mój oryginalny pomysł (i nigdy nie znalazłbym go w tym przewodniku, gdyby nie Joe Obbish). Oto procedura, którą stworzyłem w Utility :
CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Proste, prawda? Uruchom 8 instancji SQLQueryStress i umieść tę partię w każdym:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
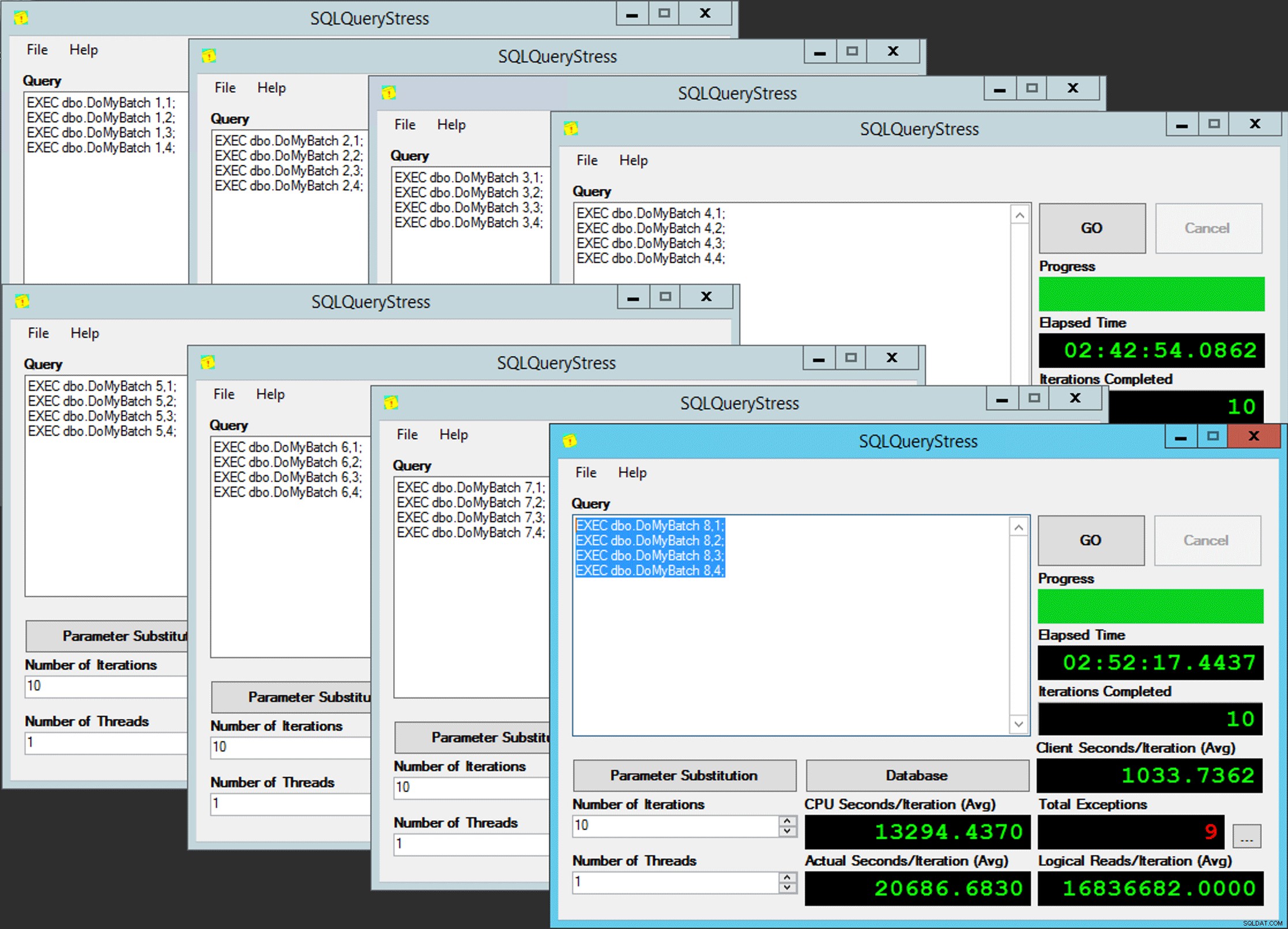 Równoległość ubogich
Równoległość ubogich
Tyle że to nie jest takie proste, ponieważ przypisanie harmonogramu jest trochę jak pudełko czekoladek. Wymagało wielu prób, aby każda instancja aplikacji działała zgodnie z oczekiwanym harmonogramem; Sprawdzę wyjątki w dowolnym wystąpieniu aplikacji i zmienię PartitionID dopasować. Dlatego użyłem więcej niż jednej iteracji (ale nadal chciałem tylko jednego wątku na instancję). Na przykład ta instancja aplikacji oczekiwała, że będzie w harmonogramie 3, ale otrzymała harmonogram 4:
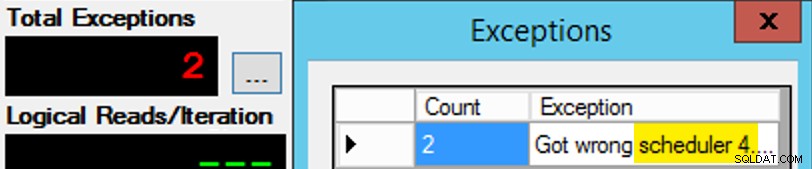 Jeśli na początku ci się nie uda…
Jeśli na początku ci się nie uda…
Zmieniłem 3 w oknie zapytania na 4 i spróbowałem ponownie. Gdybym był szybki, zadanie harmonogramu było na tyle „lepkie”, że od razu je podniosło i zaczęło ćpać. Ale nie zawsze byłam wystarczająco szybka, więc to było trochę jak walnięcie w kreta. Prawdopodobnie mogłem wymyślić lepszą procedurę ponawiania/pętli, aby praca była tutaj mniej ręczna, i skrócić opóźnienie, więc od razu wiedziałem, czy zadziałało, czy nie, ale to było wystarczająco dobre dla moich potrzeb. Spowodowało to również niezamierzone oszałamianie czasów rozpoczęcia każdego procesu, kolejna rada od pana Obbisha.
Monitorowanie
Gdy kopia stowarzyszona jest uruchomiona, mogę uzyskać wskazówkę dotyczącą aktualnego stanu za pomocą następujących dwóch zapytań:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID;
Jeśli zrobię wszystko dobrze, oba zapytania zwrócą 8 wierszy i pokażą zwiększające się odczyty logiczne i czas trwania. Typy oczekiwania zmienią się między PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD , a czasami RESERVED_MEMORY_ALLOCATION_EXT. Kiedy partia została zakończona (mógłbym je przejrzeć, odkomentowując -- AND EndTime IS NULL , potwierdzam, że RowsAdded = RowsInRange .
Po ukończeniu wszystkich 8 instancji SQLQueryStress mogłem po prostu wykonać SELECT INTO <newtable> FROM dbo.BatchQueue aby zapisać końcowe wyniki do późniejszej analizy.
Inne testy
Oprócz kopiowania danych do indeksu magazynu kolumn podzielonego na partycje w klastrze, który już istniał, przy użyciu koligacji, chciałem też wypróbować kilka innych rzeczy:
- Kopiowanie danych do nowej tabeli bez próby kontrolowania koligacji. Wyjąłem logikę powinowactwa z procedury i po prostu pozostawiłem całą sprawę „mam nadzieję, że dostaniesz właściwy harmonogram” przypadkowi. Trwało to dłużej, ponieważ układanie harmonogramu tak pojawić się. Na przykład w tym konkretnym momencie harmonogram 3 uruchamiał dwa procesy, podczas gdy harmonogram 0 był wyłączony, robiąc sobie przerwę na lunch:
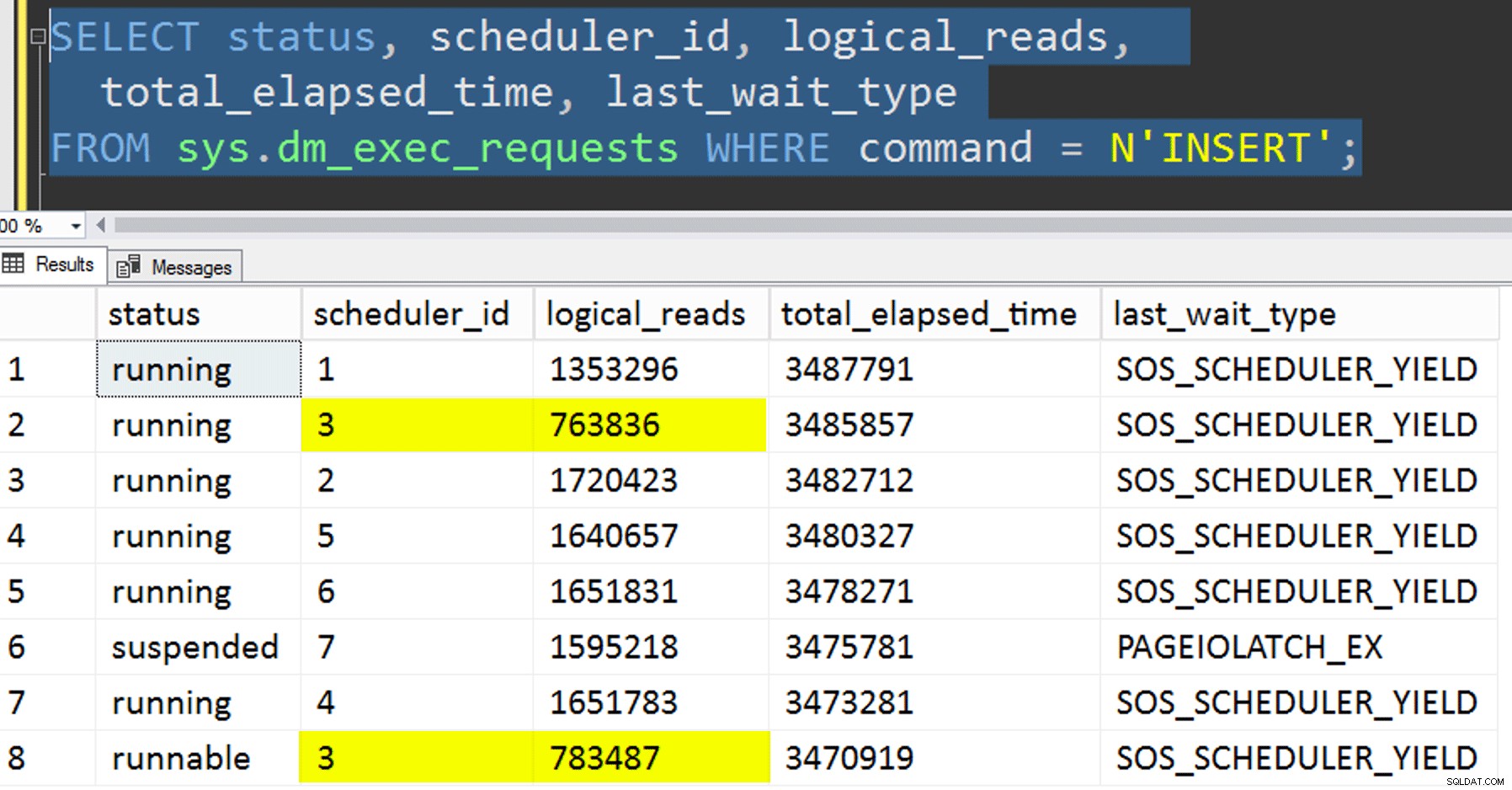 Gdzie jesteś, planista numer 0?
Gdzie jesteś, planista numer 0? - Stosowanie strony lub wiersz kompresja (zarówno online, jak i offline) do źródła przed skojarzoną kopię (offline), aby sprawdzić, czy najpierw skompresowanie danych może przyspieszyć miejsce docelowe. Zwróć uwagę, że kopię można wykonać również online, ale tak jak
intAndy'ego Mallona dobigintkonwersja, wymaga trochę gimnastyki. Zauważ, że w tym przypadku nie możemy skorzystać z koligacji procesora (chociaż moglibyśmy, gdyby tabela źródłowa była już podzielona na partycje). Byłem sprytny i wziąłem kopię zapasową oryginalnego źródła i stworzyłem procedurę przywracania bazy danych do stanu początkowego. Dużo szybciej i łatwiej niż próba ręcznego powrotu do określonego stanu.-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- I na koniec najpierw przebuduj indeks klastrowy na schemat partycji, a następnie zbuduj indeks magazynu kolumn w klastrach. Wadą tego ostatniego jest to, że w SQL Server 2017 nie można uruchomić tego w trybie online… ale będzie można to zrobić w 2019 roku.
Tutaj musimy najpierw usunąć ograniczenie PK; nie możesz użyć
Komunikat 1907, poziom 16, stan 1DROP_EXISTING, ponieważ oryginalne ograniczenie unikatowe nie może być wymuszone przez klastrowany indeks magazynu kolumn i nie można zastąpić unikatowego indeksu klastrowanego nieunikatowym indeksem klastrowanym.
Nie można odtworzyć indeksu „pk_tblOriginal”. Nowa definicja indeksu nie jest zgodna z ograniczeniem wymuszanym przez istniejący indeks.Wszystkie te szczegóły sprawiają, że jest to trzyetapowy proces, tylko drugi krok online. Pierwszy krok, który wyraźnie przetestowałem tylko
OFFLINE; który działał w ciągu trzech minut, podczas gdyONLINEZatrzymałem się po 15 minutach. Jedna z tych rzeczy, która może nie powinna być operacją rozmiaru danych w obu przypadkach, ale zostawię to na inny dzień.ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Wyniki
Czasy i współczynniki kompresji:
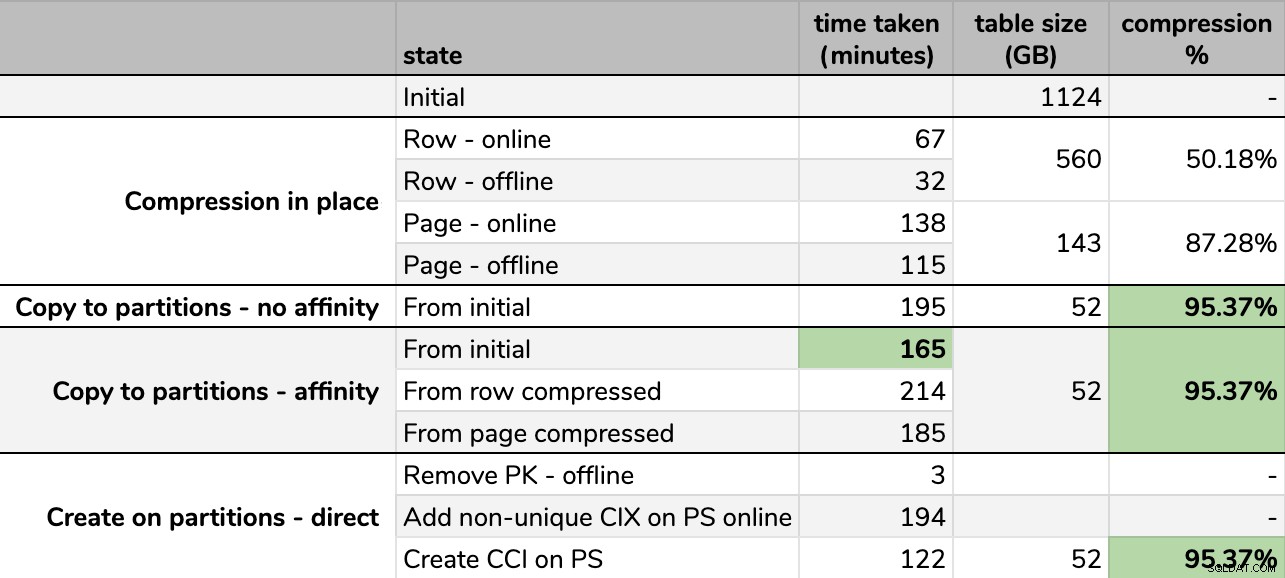 Niektóre opcje są lepsze niż inne
Niektóre opcje są lepsze niż inne
Zauważ, że zaokrągliłem do GB, ponieważ po każdym uruchomieniu byłyby niewielkie różnice w rozmiarze końcowym, nawet przy użyciu tej samej techniki. Ponadto czasy dla metod powinowactwa były oparte na średniej indywidualny harmonogram/wsadowe środowisko wykonawcze, ponieważ niektóre harmonogramy kończą pracę szybciej niż inne.
Trudno wyobrazić sobie dokładny obraz z arkusza kalkulacyjnego, jak pokazano, ponieważ niektóre zadania mają zależności, więc postaram się wyświetlić informacje na osi czasu i pokazać, jaka jest kompresja w porównaniu do czasu spędzonego:
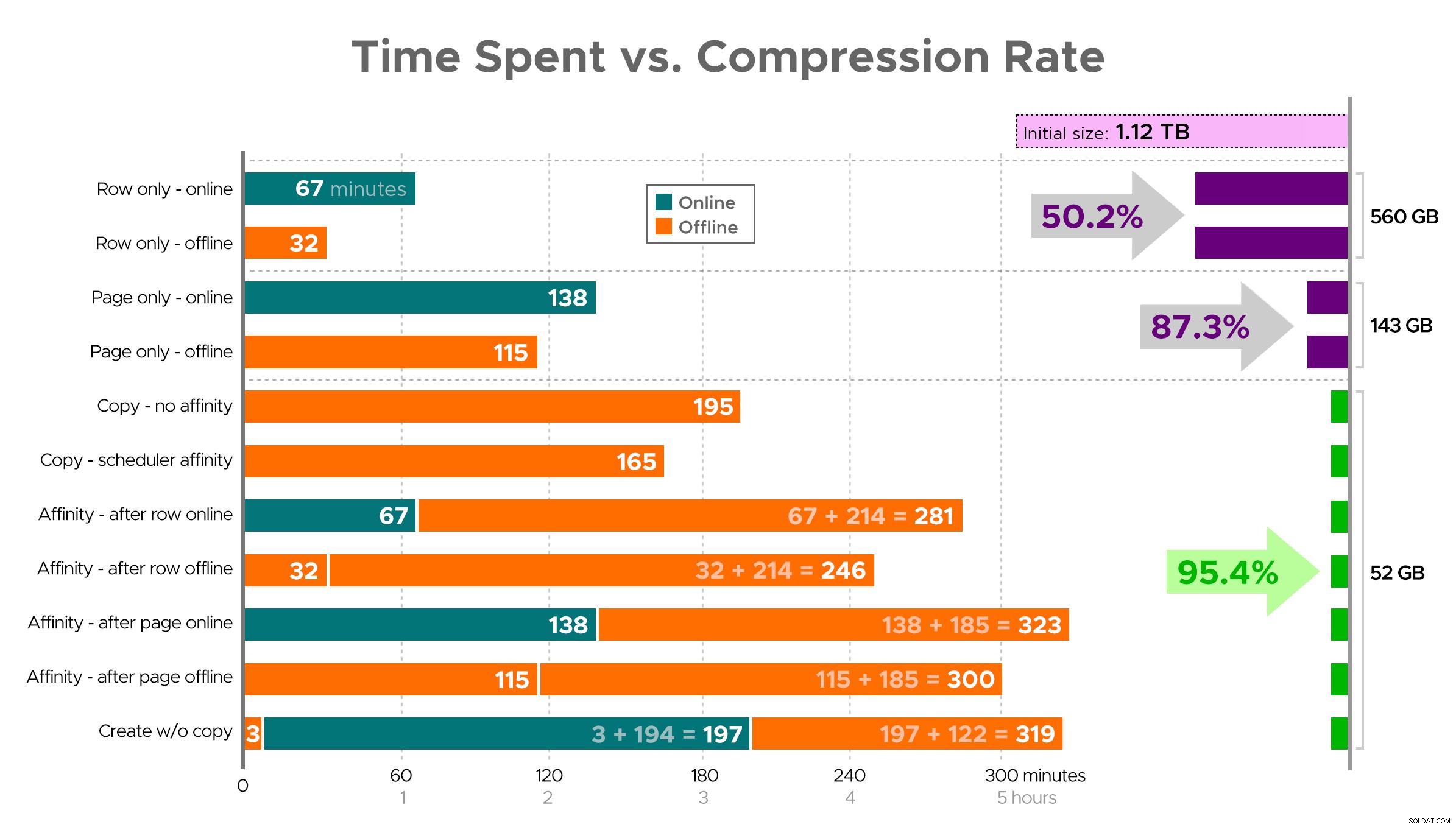 Czas spędzony (minuty) a współczynnik kompresji
Czas spędzony (minuty) a współczynnik kompresji
Kilka obserwacji z wyników, z zastrzeżeniem, że Twoje dane mogą być kompresowane w różny sposób (i że operacje online dotyczą tylko Ciebie, jeśli korzystasz z wersji Enterprise):
- Jeśli Twoim priorytetem jest zaoszczędzenie miejsca tak szybko, jak to możliwe , najlepiej jest zastosować kompresję wierszy w miejscu. Jeśli chcesz zminimalizować zakłócenia, korzystaj z Internetu; jeśli chcesz zoptymalizować prędkość, korzystaj z trybu offline.
- Jeśli chcesz zmaksymalizować kompresję bez zakłóceń , możesz zbliżyć się do 90% redukcji miejsca na dane bez żadnych zakłóceń, korzystając z kompresji stron online.
- Jeśli chcesz zmaksymalizować kompresję i zakłócenia, jest w porządku , skopiuj dane do nowej, partycjonowanej wersji tabeli z klastrowanym indeksem magazynu kolumn i użyj opisanego powyżej procesu powinowactwa, aby przeprowadzić migrację danych. (I znowu, możesz wyeliminować to zakłócenie, jeśli jesteś lepszym planistą ode mnie).
Ostatnia opcja działała najlepiej w moim scenariuszu, chociaż nadal będziemy musieli kopać opony przy obciążeniach (tak, liczba mnoga). Należy również pamiętać, że w SQL Server 2019 ta technika może nie działać tak dobrze, ale można tam tworzyć klastrowane indeksy magazynu kolumn online, więc może to nie mieć większego znaczenia.
Niektóre z tych podejść mogą być dla Ciebie mniej lub bardziej akceptowalne, ponieważ możesz preferować „pozostać dostępny” nad „jak najszybsze zakończenie” lub „minimalizować użycie dysku” nad „pozostać dostępnym” lub po prostu równoważyć wydajność odczytu i narzutu zapisu .
Jeśli chcesz uzyskać więcej informacji na temat dowolnego aspektu, po prostu zapytaj. Przyciąłem trochę tłuszczu, aby zrównoważyć szczegóły ze strawnością, a myliłem się wcześniej co do tej równowagi. Pożegnalna myśl jest taka, że jestem ciekaw, jak to jest liniowe – mamy inny stół o podobnej strukturze, który ma ponad 25 TB i jestem ciekaw, czy możemy tam wywrzeć podobny wpływ. Do tego czasu miłego kompresowania!
[ Część 1 | Część 2 | Część 3 ]