Ten artykuł jest szóstą częścią serii dotyczącej wyrażeń tabelowych. W zeszłym miesiącu w części 5 omówiłem logiczne leczenie nierekurencyjnych CTE. W tym miesiącu zajmę się logicznym leczeniem rekurencyjnych CTE. Opisuję obsługę T-SQL dla rekurencyjnych CTE, a także standardowe elementy, które nie są jeszcze obsługiwane przez T-SQL. Zapewniam logicznie równoważne obejścia T-SQL dla nieobsługiwanych elementów.
Przykładowe dane
Dla przykładowych danych użyję tabeli o nazwie Pracownicy, która zawiera hierarchię pracowników. Kolumna empid reprezentuje identyfikator pracownika podwładnego (węzeł podrzędny), a kolumna mgrid reprezentuje identyfikator pracownika kierownika (węzeł nadrzędny). Użyj następującego kodu, aby utworzyć i wypełnić tabelę Pracownicy w bazie danych tempdb:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary); Zauważ, że korzeń hierarchii pracowników — dyrektor generalny — ma wartość NULL w kolumnie mgrid. Wszyscy pozostali pracownicy mają menedżera, więc ich kolumna mgrid jest ustawiona na identyfikator pracownika ich menedżera.
Rysunek 1 przedstawia graficznie hierarchię pracowników, pokazując imię i nazwisko pracownika, jego identyfikator i jego lokalizację w hierarchii.
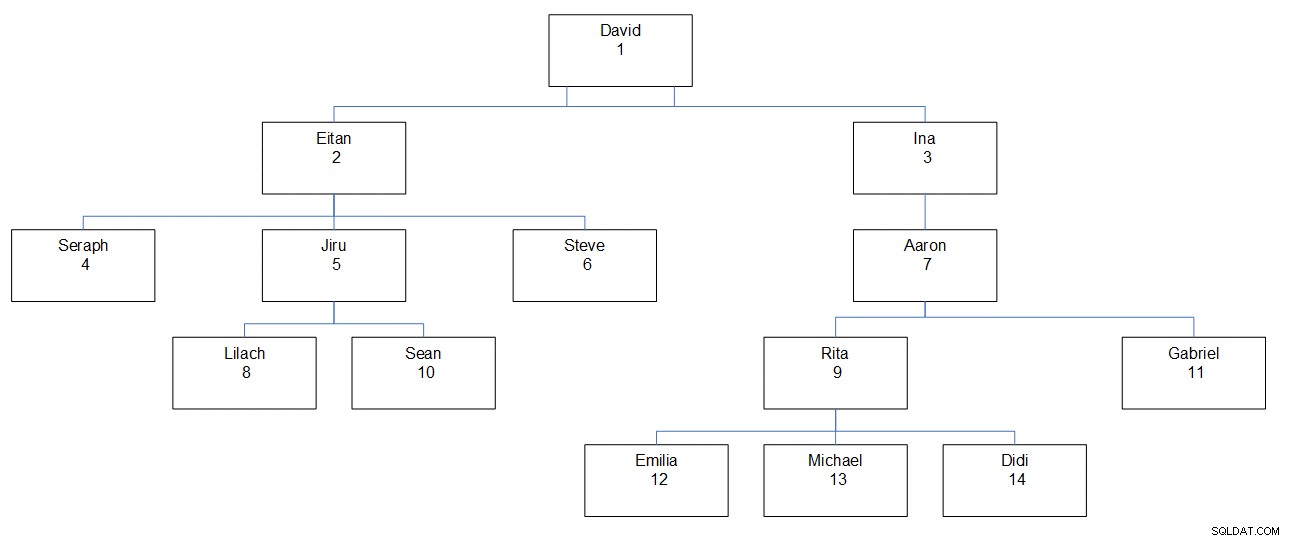 Rysunek 1:Hierarchia pracowników
Rysunek 1:Hierarchia pracowników
Rekurencyjne CTE
Rekurencyjne CTE mają wiele przypadków użycia. Klasyczna kategoria zastosowań dotyczy obsługi struktur grafowych, takich jak nasza hierarchia pracowników. Zadania związane z grafami często wymagają przemierzania ścieżek o dowolnej długości. Na przykład, biorąc pod uwagę identyfikator pracownika jakiegoś kierownika, zwróć pracownika wejściowego, a także wszystkich podwładnych pracownika wejściowego na wszystkich poziomach; tj. podwładni bezpośredni i pośredni. Jeśli masz znany mały limit liczby poziomów, które możesz potrzebować przestrzegać (stopień wykresu), możesz użyć zapytania ze sprzężeniem na poziom podwładnych. Jeśli jednak stopień wykresu jest potencjalnie wysoki, w pewnym momencie pisanie zapytania z wieloma sprzężeniami staje się niepraktyczne. Inną opcją jest użycie imperatywnego kodu iteracyjnego, ale takie rozwiązania bywają długie. W tym miejscu naprawdę błyszczą rekurencyjne CTE — umożliwiają korzystanie z deklaratywnych, zwięzłych i intuicyjnych rozwiązań.
Zacznę od podstaw rekurencyjnych CTE, zanim przejdę do bardziej interesujących rzeczy, w których omówię możliwości wyszukiwania i jazdy na rowerze.
Pamiętaj, że składnia zapytania względem CTE jest następująca:
WITHAS
(
)
Tutaj pokazuję jedno CTE zdefiniowane za pomocą klauzuli WITH, ale jak wiesz, możesz zdefiniować wiele CTE oddzielonych przecinkami.
W zwykłych, nierekurencyjnych CTE wewnętrzne wyrażenie tabelowe jest oparte na zapytaniu, które jest oceniane tylko raz. W rekurencyjnych CTE wewnętrzne wyrażenie tabeli jest zazwyczaj oparte na dwóch zapytaniach znanych jako członkowie , choć możesz mieć więcej niż dwa, aby zaspokoić niektóre specjalne potrzeby. Elementy członkowskie są zazwyczaj oddzielone operatorem UNION ALL, aby wskazać, że ich wyniki są ujednolicone.
Członek może być członkiem głównym —co oznacza, że jest oceniany tylko raz; lub może to być członek rekurencyjny — co oznacza, że jest oceniany wielokrotnie, dopóki nie zwróci pustego zestawu wyników. Oto składnia zapytania względem rekurencyjnego CTE opartego na jednym elemencie zakotwiczenia i jednym elemencie rekurencyjnym:
WITHAS
(
UNION ALL
)
To, co sprawia, że element członkowski jest rekurencyjny, to posiadanie odniesienia do nazwy CTE. To odwołanie reprezentuje zestaw wyników ostatniego wykonania. W pierwszym wykonaniu elementu rekurencyjnego odwołanie do nazwy CTE reprezentuje zestaw wyników elementu zakotwiczenia. W N-tym wykonaniu, gdzie N> 1, odwołanie do nazwy CTE reprezentuje zestaw wyników wykonania (N – 1) elementu rekurencyjnego. Jak wspomniano, gdy rekurencyjny element członkowski zwróci pusty zestaw, nie zostanie on ponownie wykonany. Odwołanie do nazwy CTE w zewnętrznym zapytaniu reprezentuje ujednolicone zestawy wyników pojedynczego wykonania elementu zakotwiczenia i wszystkich wykonań elementu rekurencyjnego.
Poniższy kod implementuje wyżej wymienione zadanie zwracania poddrzewa pracowników dla danego menedżera wejściowego, przekazując w tym przykładzie identyfikator pracownika 3 jako pracownik root:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; Zapytanie zakotwiczające jest wykonywane tylko raz, zwracając wiersz dla wejściowego pracownika root (w naszym przypadku pracownik 3).
Zapytanie rekurencyjne łączy zbiór pracowników z poprzedniego poziomu — reprezentowanych przez odwołanie do nazwy CTE, alias M dla menedżerów — z ich bezpośrednimi podwładnymi z tabeli Pracownicy, aliasem S dla podwładnych. Predykat złączenia to S.mgrid =M.empid, co oznacza, że wartość mgrid podwładnego jest równa wartości empid menedżera. Zapytanie rekurencyjne jest wykonywane cztery razy w następujący sposób:
- Zwrot podwładnych pracownika 3; wyjście:pracownik 7
- Zwrot podwładnych pracownika 7; wydajność:pracownicy 9 i 11
- Zwrot podwładnych pracowników 9 i 11; wyjście:12, 13 i 14
- Zwrot podwładnych pracowników 12, 13 i 14; wyjście:pusty zestaw; rekurencja zatrzymuje się
Odwołanie do nazwy CTE w zapytaniu zewnętrznym reprezentuje ujednolicone wyniki pojedynczego wykonania zapytania kotwiczącego (pracownik 3) z wynikami wszystkich wykonań zapytania rekurencyjnego (pracownicy 7, 9, 11, 12, 13 i 14). Ten kod generuje następujące dane wyjściowe:
empid mgrid empname ------ ------ -------- 3 1 Ina 7 3 Aaron 9 7 Rita 11 7 Gabriel 12 9 Emilia 13 9 Michael 14 9 Didi
Częstym problemem w rozwiązaniach programistycznych jest niekontrolowany kod, taki jak nieskończone pętle, zwykle spowodowane błędem. W przypadku rekurencyjnych CTE błąd może spowodować wykonanie elementu rekurencyjnego na pasie startowym. Załóżmy na przykład, że w naszym rozwiązaniu zwracania podwładnych pracownika wejściowego wystąpił błąd w predykacie sprzężenia rekurencyjnego członka. Zamiast używać ON S.mgrid =M.empid, użyłeś ON S.mgrid =S.mgrid, na przykład:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C; Biorąc pod uwagę co najmniej jednego pracownika z niepustym identyfikatorem menedżera obecnym w tabeli, wykonanie elementu rekurencyjnego będzie nadal zwracać niepusty wynik. Pamiętaj, że niejawnym warunkiem zakończenia dla rekurencyjnego elementu członkowskiego jest to, że jego wykonanie zwraca pusty zestaw wyników. Jeśli zwróci niepusty zestaw wyników, SQL Server wykona go ponownie. Zdajesz sobie sprawę, że gdyby SQL Server nie miał mechanizmu ograniczającego rekurencyjne wykonania, po prostu wykonywałby rekurencyjne elementy członkowskie w nieskończoność. Jako środek bezpieczeństwa T-SQL obsługuje opcję zapytania MAXRECURSION, która ogranicza maksymalną dozwoloną liczbę wykonań elementu rekurencyjnego. Domyślnie ten limit jest ustawiony na 100, ale można go zmienić na dowolną nieujemną wartość SMALLINT, gdzie 0 oznacza brak limitu. Ustawienie maksymalnego limitu rekurencji na wartość dodatnią N oznacza, że N + 1 próba wykonania elementu rekurencyjnego zostaje przerwana z błędem. Na przykład uruchomienie powyższego błędnego kodu w takim stanie, w jakim jest, oznacza, że polegasz na domyślnym maksymalnym limicie rekurencji wynoszącym 100, więc wykonanie 101 elementu rekurencyjnego nie powiedzie się:
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...Msg 530, Poziom 16, Stan 1, Wiersz 121
Oświadczenie zakończone. Maksymalna rekursja 100 została wyczerpana przed zakończeniem instrukcji.
Powiedzmy, że w Twojej organizacji można bezpiecznie założyć, że hierarchia pracowników nie przekroczy 6 poziomów zarządzania. Możesz zmniejszyć maksymalny limit rekurencji ze 100 do znacznie mniejszej liczby, na przykład 10, aby być po bezpiecznej stronie, na przykład:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = S.mgrid
)
SELECT empid, mgrid, empname
FROM C
OPTION (MAXRECURSION 10); Teraz, jeśli wystąpi błąd powodujący niekontrolowane wykonanie elementu rekurencyjnego, zostanie on wykryty przy 11 próbach wykonania elementu rekurencyjnego zamiast przy wykonaniu 101:
empid mgrid empname ------ ------ -------- 3 1 Ina 2 1 Eitan 3 1 Ina ...Msg 530, Poziom 16, Stan 1, Wiersz 149
Oświadczenie zostało zakończone. Maksymalna rekursja 10 została wyczerpana przed zakończeniem instrukcji.
Ważne jest, aby pamiętać, że maksymalny limit rekurencji powinien być używany głównie jako środek bezpieczeństwa w celu przerwania wykonywania błędnego kodu, który nie dał się uruchomić. Pamiętaj, że po przekroczeniu limitu wykonanie kodu jest przerywane z błędem. Nie należy używać tej opcji do ograniczania liczby poziomów do odwiedzenia w celu filtrowania. Nie chcesz, aby błąd był generowany, gdy nie ma problemu z kodem.
W celu filtrowania możesz ograniczyć liczbę poziomów, które mają być odwiedzane programowo. Definiujesz kolumnę o nazwie lvl, która śledzi numer poziomu bieżącego pracownika w porównaniu z wejściowym pracownikiem głównym. W zapytaniu zakotwiczającym ustawiasz kolumnę lvl na stałą 0. W zapytaniu rekurencyjnym ustawiasz ją na wartość lvl menedżera plus 1. Aby filtrować tyle poziomów poniżej korzenia wejściowego, co @maxlevel, dodaj predykat M.lvl <@ maxlevel do klauzuli ON zapytania rekurencyjnego. Na przykład poniższy kod zwraca pracownika 3 i dwa poziomy podwładnych pracownika 3:
DECLARE @root AS INT = 3, @maxlevel AS INT = 2;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.lvl < @maxlevel
)
SELECT empid, mgrid, empname, lvl
FROM C; To zapytanie generuje następujące dane wyjściowe:
empid mgrid empname lvl ------ ------ -------- ---- 3 1 Ina 0 7 3 Aaron 1 9 7 Rita 2 11 7 Gabriel 2
Standardowe klauzule SEARCH i CYCLE
Norma ISO/IEC SQL definiuje dwie bardzo potężne opcje dla rekurencyjnych CTE. Jedną z nich jest klauzula o nazwie SEARCH, która kontroluje rekurencyjną kolejność wyszukiwania, a druga to klauzula o nazwie CYCLE, która identyfikuje cykle w przebytych ścieżkach. Oto standardowa składnia dwóch klauzul:
7.18Funkcja
Określ generowanie informacji o kolejności i wykrywaniu cykli w wyniku rekurencyjnych wyrażeń zapytań.
Format
AS
SEARCH
GŁĘBOKOŚĆ FIRST BY
CYCLE
DEFAULT
W chwili pisania tego tekstu T-SQL nie obsługuje tych opcji, ale w poniższych linkach można znaleźć prośby o udoskonalenie funkcji z prośbą o ich włączenie do T-SQL w przyszłości i zagłosuj na nie:
- Dodaj obsługę klauzuli ISO/IEC SQL SEARCH do rekurencyjnych CTE w T-SQL
- Dodaj obsługę klauzuli CYCLE ISO/IEC SQL do rekurencyjnych CTE w T-SQL
W następnych sekcjach opiszę te dwie standardowe opcje, a także przedstawię logicznie równoważne alternatywne rozwiązania, które są obecnie dostępne w T-SQL.
klauzula WYSZUKAJ
Standardowa klauzula SEARCH definiuje rekurencyjną kolejność wyszukiwania jako BREADTH FIRST lub DEPTH FIRST przez określoną kolumnę porządkowania i tworzy nową kolumnę sekwencji z pozycjami porządkowymi odwiedzanych węzłów. Określasz SZEROKOŚĆ NAJPIERW, aby wyszukiwać najpierw na każdym poziomie (szerokość), a następnie w dół poziomów (głębokość). Określasz DEPTH FIRST, aby wyszukać najpierw w dół (głębokość), a następnie w poprzek (szerokość).
Klauzula SEARCH jest określana bezpośrednio przed zapytaniem zewnętrznym.
Zacznę od przykładu dla pierwszej kolejności wyszukiwania rekurencyjnego wszerz. Pamiętaj tylko, że ta funkcja nie jest dostępna w T-SQL, więc nie będziesz w stanie uruchomić przykładów, które używają standardowych klauzul w SQL Server lub Azure SQL Database. Poniższy kod zwraca poddrzewo pracownika 1, prosząc o pierwszą kolejność wyszukiwania szerokości według empid, tworząc kolumnę sekwencji o nazwie seqbreadth z pozycjami porządkowymi odwiedzanych węzłów:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH BREADTH FIRST BY empid SET seqbreadth
--------------------------------------------
SELECT empid, mgrid, empname, seqbreadth
FROM C
ORDER BY seqbreadth; Oto pożądane wyjście tego kodu:
empid mgrid empname seqbreadth ------ ------ -------- ----------- 1 NULL David 1 2 1 Eitan 2 3 1 Ina 3 4 2 Seraph 4 5 2 Jiru 5 6 2 Steve 6 7 3 Aaron 7 8 5 Lilach 8 9 7 Rita 9 10 5 Sean 10 11 7 Gabriel 11 12 9 Emilia 12 13 9 Michael 13 14 9 Didi 14
Nie dajcie się zmylić faktowi, że wartości seqbreadth wydają się być identyczne z wartościami empid. To tylko przypadek ze względu na sposób, w jaki ręcznie przypisałem wartości empid w utworzonych przeze mnie przykładowych danych.
Rysunek 2 przedstawia graficzną prezentację hierarchii pracowników z linią przerywaną pokazującą szerokość pierwszego rzędu, w którym przeszukiwano węzły. Wartości empid pojawiają się tuż pod nazwiskami pracowników, a przypisane wartości seqbreadth pojawiają się w lewym dolnym rogu każdego pola.
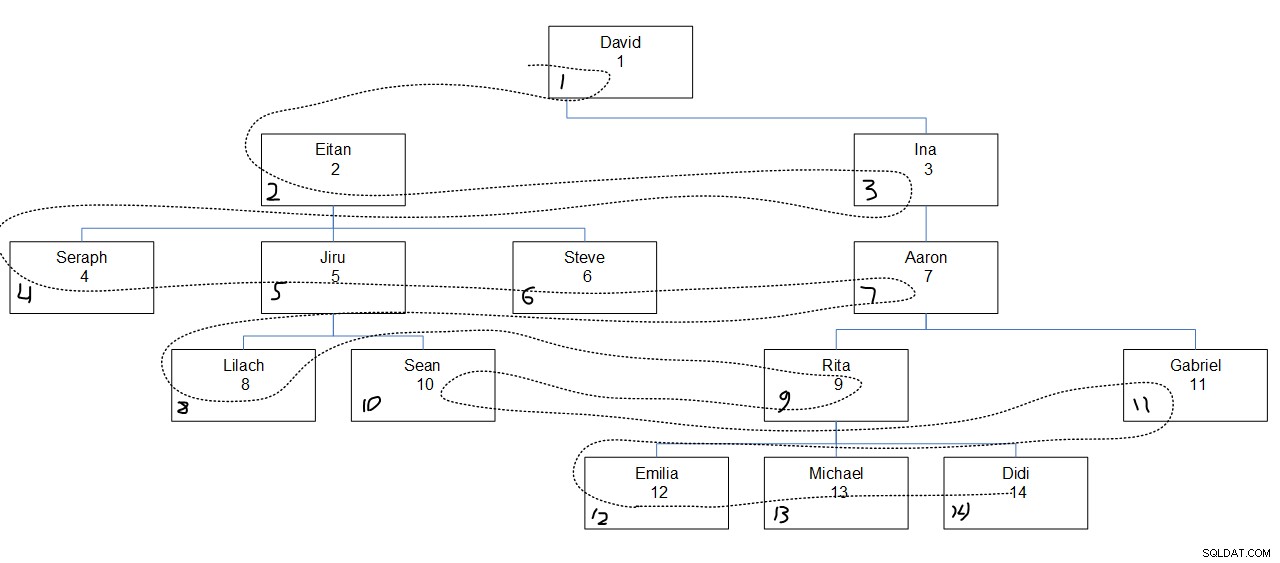 Rysunek 2:Najpierw szerokość wyszukiwania
Rysunek 2:Najpierw szerokość wyszukiwania
Co ciekawe, na każdym poziomie węzły są przeszukiwane na podstawie określonej kolejności kolumn (w naszym przypadku empid), niezależnie od powiązania rodzica węzła. Na przykład zauważ, że na czwartym poziomie Lilach jest dostępny jako pierwszy, Rita jako drugi, Sean jako trzeci, a Gabriel jako ostatni. To dlatego, że wśród wszystkich pracowników na czwartym poziomie jest to ich kolejność oparta na ich wartościach empid. To nie tak, że Lilach i Sean powinni być przeszukiwani kolejno, ponieważ są bezpośrednimi podwładnymi tego samego menedżera, Jiru.
Wymyślenie rozwiązania T-SQL, które zapewnia logiczny odpowiednik standardowej opcji SAERCH DEPTH FIRST, jest dość proste. Tworzysz kolumnę o nazwie lvl, jak pokazałem wcześniej, aby śledzić poziom węzła względem korzenia (0 dla pierwszego poziomu, 1 dla drugiego i tak dalej). Następnie obliczasz żądaną kolumnę sekwencji wyników w zewnętrznym zapytaniu za pomocą funkcji ROW_NUMBER. Jako okno zamawiania podaj najpierw lvl, a następnie żądaną kolumnę zamawiania (w naszym przypadku empid). Oto kompletny kod rozwiązania:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname, 0 AS lvl
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadth
FROM C
ORDER BY seqbreadth; Następnie przyjrzyjmy się kolejności wyszukiwania DEPTH FIRST. Zgodnie ze standardem poniższy kod powinien zwrócić poddrzewo pracownika 1, prosząc o pierwszą kolejność wyszukiwania głębokości według empid, tworząc kolumnę sekwencji o nazwie seqdepth z pozycjami porządkowymi wyszukiwanych węzłów:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SEARCH DEPTH FIRST BY empid SET seqdepth
----------------------------------------
SELECT empid, mgrid, empname, seqdepth
FROM C
ORDER BY seqdepth; Poniżej znajduje się pożądane wyjście tego kodu:
empid mgrid empname seqdepth ------ ------ -------- --------- 1 NULL David 1 2 1 Eitan 2 4 2 Seraph 3 5 2 Jiru 4 8 5 Lilach 5 10 5 Sean 6 6 2 Steve 7 3 1 Ina 8 7 3 Aaron 9 9 7 Rita 10 12 9 Emilia 11 13 9 Michael 12 14 9 Didi 13 11 7 Gabriel 14
Patrząc na pożądany wynik zapytania, prawdopodobnie trudno jest zrozumieć, dlaczego wartości sekwencji zostały przypisane w ten sposób. Rysunek 3 powinien pomóc. Ma graficzny obraz hierarchii pracowników, z linią przerywaną odzwierciedlającą kolejność pierwszego wyszukiwania głębokości, z przypisanymi wartościami sekwencji w lewym dolnym rogu każdego pola.
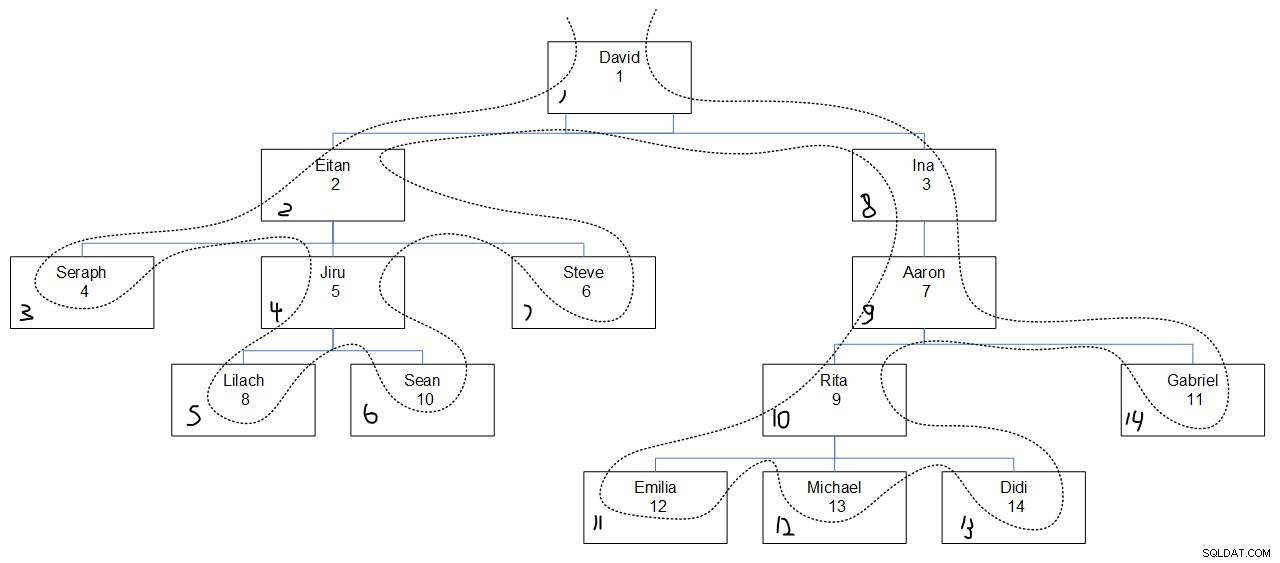 Rysunek 3:Najpierw głębokość wyszukiwania
Rysunek 3:Najpierw głębokość wyszukiwania
Wymyślenie rozwiązania T-SQL, które zapewnia logiczny odpowiednik standardowej opcji SEARCH DEPTH FIRST, jest nieco trudne, ale wykonalne. Rozwiązanie opiszę w dwóch krokach.
W kroku 1 dla każdego węzła obliczasz binarną ścieżkę sortowania, która składa się z segmentu na przodka węzła, przy czym każdy segment odzwierciedla pozycję sortowania przodka wśród jego rodzeństwa. Budujesz tę ścieżkę podobnie do sposobu, w jaki obliczasz kolumnę lvl. Oznacza to, że zacznij od pustego ciągu binarnego dla węzła głównego w zapytaniu zakotwiczającym. Następnie w zapytaniu rekurencyjnym łączysz ścieżkę rodzica z pozycją sortowania węzła wśród rodzeństwa po przekonwertowaniu go na segment binarny. Używasz funkcji ROW_NUMBER, aby obliczyć pozycję, podzieloną przez element nadrzędny (w naszym przypadku mgrid) i uporządkowaną według odpowiedniej kolumny porządkującej (w naszym przypadku empid). Konwertujesz numer wiersza na wartość binarną o wystarczającym rozmiarze w zależności od maksymalnej liczby bezpośrednich dzieci, które rodzic może mieć na wykresie. BINARY (1) obsługuje do 255 dzieci na rodzica, BINARY (2) obsługuje 65 535, BINARY (3):16 777 215, BINARY (4):4 294 967 295. W rekurencyjnym CTE odpowiednie kolumny w zakotwiczeniu i zapytaniach rekurencyjnych muszą być tego samego typu i rozmiaru , więc pamiętaj, aby przekonwertować ścieżkę sortowania na wartość binarną o tym samym rozmiarze w obu przypadkach.
Oto kod implementujący Krok 1 w naszym rozwiązaniu (zakładając, że BINARY(1) wystarcza na segment, co oznacza, że masz nie więcej niż 255 bezpośrednich podwładnych na menedżera):
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, sortpath
FROM C; Ten kod generuje następujące dane wyjściowe:
empid mgrid empname sortpath ------ ------ -------- ----------- 1 NULL David 0x 2 1 Eitan 0x01 3 1 Ina 0x02 7 3 Aaron 0x0201 9 7 Rita 0x020101 11 7 Gabriel 0x020102 12 9 Emilia 0x02010101 13 9 Michael 0x02010102 14 9 Didi 0x02010103 4 2 Seraph 0x0101 5 2 Jiru 0x0102 6 2 Steve 0x0103 8 5 Lilach 0x010201 10 5 Sean 0x010202
Zauważ, że użyłem pustego ciągu binarnego jako ścieżki sortowania węzła głównego pojedynczego poddrzewa, o które tutaj pytamy. W przypadku, gdy element zakotwiczenia może potencjalnie zwrócić wiele korzeni poddrzewa, po prostu zacznij od segmentu opartego na obliczeniach ROW_NUMBER w zapytaniu zakotwiczającym, podobnie do sposobu obliczania go w zapytaniu rekurencyjnym. W takim przypadku ścieżka sortowania będzie o jeden segment dłuższa.
To, co pozostało do zrobienia w kroku 2, to utworzenie żądanej kolumny seqdepth w wynikach, poprzez obliczenie numerów wierszy uporządkowanych według ścieżki sortowania w zewnętrznym zapytaniu, tak jak w ten sposób
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth
FROM C
ORDER BY seqdepth; To rozwiązanie jest logicznym odpowiednikiem użycia standardowej opcji SEARCH DEPTH FIRST pokazanej wcześniej wraz z żądanymi danymi wyjściowymi.
Gdy masz już kolumnę sekwencji, która odzwierciedla pierwszą kolejność wyszukiwania głębokości (w naszym przypadku seqdepth), przy odrobinie większego wysiłku możesz wygenerować bardzo ładne wizualne przedstawienie hierarchii. Potrzebna będzie również wspomniana wcześniej kolumna lvl. Zewnętrzne zapytanie można uporządkować według kolumny sekwencji. Zwracasz jakiś atrybut, którego chcesz użyć do reprezentowania węzła (powiedzmy empname w naszym przypadku), poprzedzony jakimś łańcuchem (powiedzmy ' | ') zreplikowanym razy lvl. Oto kompletny kod, aby uzyskać taki wizualny obraz:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, empname, 0 AS lvl,
CAST(0x AS VARBINARY(900)) AS sortpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.empname, M.lvl + 1 AS lvl,
CAST(M.sortpath
+ CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid)
AS BINARY(1))
AS VARBINARY(900)) AS sortpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid,
ROW_NUMBER() OVER(ORDER BY sortpath) AS seqdepth,
REPLICATE(' | ', lvl) + empname AS emp
FROM C
ORDER BY seqdepth; Ten kod generuje następujące dane wyjściowe:
empid seqdepth emp ------ --------- -------------------- 1 1 David 2 2 | Eitan 4 3 | | Seraph 5 4 | | Jiru 8 5 | | | Lilach 10 6 | | | Sean 6 7 | | Steve 3 8 | Ina 7 9 | | Aaron 9 10 | | | Rita 12 11 | | | | Emilia 13 12 | | | | Michael 14 13 | | | | Didi 11 14 | | | Gabriel
To całkiem fajne!
klauzula CYKLU
Struktury grafowe mogą mieć cykle. Te cykle mogą być ważne lub nieważne. Przykładem prawidłowych cykli jest wykres przedstawiający autostrady i drogi łączące miasta i miasteczka. Nazywa się to wykresem cyklicznym . I odwrotnie, wykres reprezentujący hierarchię pracowników, taki jak w naszym przypadku, nie powinien mieć cykli. To właśnie jest określane jako acykliczne wykres. Załóżmy jednak, że z powodu jakiejś błędnej aktualizacji, nieumyślnie kończy się cykl. Załóżmy na przykład, że przez pomyłkę aktualizujesz identyfikator dyrektora generalnego (pracownika 1) na pracownika 14, uruchamiając następujący kod:
UPDATE Employees SET mgrid = 14 WHERE empid = 1;
Masz teraz nieprawidłowy cykl w hierarchii pracowników.
Niezależnie od tego, czy cykle są prawidłowe, czy nieprawidłowe, podczas przemierzania struktury wykresu z pewnością nie chcesz wielokrotnie podążać ścieżką cykliczną. W obu przypadkach chcesz przestać podążać ścieżką po znalezieniu niepierwszego wystąpienia tego samego węzła i oznaczyć taką ścieżkę jako cykliczną.
A więc co się dzieje, gdy wysyłasz zapytanie do wykresu, który zawiera cykle przy użyciu zapytania rekurencyjnego, bez mechanizmu ich wykrywania? To zależy od implementacji. W SQL Server w pewnym momencie osiągniesz maksymalny limit rekurencji, a twoje zapytanie zostanie przerwane. Na przykład, zakładając, że uruchomiłeś powyższą aktualizację, która wprowadziła cykl, spróbuj uruchomić następujące rekurencyjne zapytanie, aby zidentyfikować poddrzewo pracownika 1:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; Ponieważ ten kod nie ustawia jawnego maksymalnego limitu rekurencji, przyjmuje się domyślny limit 100. SQL Server przerywa wykonywanie tego kodu przed zakończeniem i generuje błąd:
empid mgrid empname ------ ------ -------- 1 14 David 2 1 Eitan 3 1 Ina 7 3 Aaron 9 7 Rita 11 7 Gabriel 12 9 Emilia 13 9 Michael 14 9 Didi 1 14 David 2 1 Eitan 3 1 Ina 7 3 Aaron ...Msg 530, Poziom 16, Stan 1, Wiersz 432
Oświadczenie zostało zakończone. Maksymalna rekursja 100 została wyczerpana przed zakończeniem instrukcji.
Standard SQL definiuje klauzulę o nazwie CYCLE dla rekurencyjnych CTE, umożliwiającą radzenie sobie z cyklami na wykresie. Klauzula ta jest określana tuż przed zapytaniem zewnętrznym. Jeśli występuje również klauzula SEARCH, należy ją najpierw określić, a następnie klauzulę CYCLE. Oto składnia klauzuli CYCLE:
CYCLESET
USING
Wykrywanie cyklu odbywa się na podstawie określonej listy kolumn cykli . Na przykład w naszej hierarchii pracowników prawdopodobnie chciałbyś użyć do tego celu kolumny empid. Gdy ta sama wartość empid pojawia się po raz drugi, wykrywany jest cykl i zapytanie nie podąża dalej taką ścieżką. Określasz nową kolumnę znacznika cyklu który wskaże, czy cykl został znaleziony, czy nie, oraz własne wartości jako znacznik cyklu i znak niecykliczny wartości. Na przykład mogą to być 1 i 0 lub „Tak” i „Nie” lub dowolne inne wybrane przez Ciebie wartości. W klauzuli USING określasz nową nazwę kolumny tablicy, która będzie zawierać ścieżkę do dotychczas znalezionych węzłów.
Oto jak obsłużyć prośbę o podwładnych jakiegoś pracownika root, z możliwością wykrywania cykli w oparciu o kolumnę empid, wskazując 1 w kolumnie oznaczania cyklu, gdy cykl zostanie wykryty, a 0 w przeciwnym razie:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
CYCLE empid SET cycle TO 1 DEFAULT 0
------------------------------------
SELECT empid, mgrid, empname
FROM C; Oto pożądane wyjście tego kodu:
empid mgrid empname cycle ------ ------ -------- ------ 1 14 David 0 2 1 Eitan 0 3 1 Ina 0 7 3 Aaron 0 9 7 Rita 0 11 7 Gabriel 0 12 9 Emilia 0 13 9 Michael 0 14 9 Didi 0 1 14 David 1 4 2 Seraph 0 5 2 Jiru 0 6 2 Steve 0 8 5 Lilach 0 10 5 Sean 0
Obecnie T-SQL nie obsługuje klauzuli CYCLE, ale istnieje obejście, które zapewnia logiczny odpowiednik. Obejmuje trzy kroki. Przypomnij sobie, że wcześniej zbudowałeś binarną ścieżkę sortowania do obsługi rekurencyjnej kolejności wyszukiwania. W podobny sposób, jako pierwszy krok w rozwiązaniu, budujesz ścieżkę przodków opartą na ciągach znaków, składającą się z identyfikatorów węzłów (w naszym przypadku identyfikatorów pracowników) przodków prowadzących do bieżącego węzła, w tym do bieżącego węzła. Potrzebujesz separatorów między identyfikatorami węzłów, w tym jednego na początku i jednego na końcu.
Oto kod do zbudowania takiej ścieżki przodków:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath
FROM C; Ten kod generuje następujące dane wyjściowe, nadal realizując ścieżki cykliczne, a zatem przerywa przed zakończeniem po przekroczeniu maksymalnego limitu rekurencji:
empid mgrid empname ancpath ------ ------ -------- ------------------- 1 14 David .1. 2 1 Eitan .1.2. 3 1 Ina .1.3. 7 3 Aaron .1.3.7. 9 7 Rita .1.3.7.9. 11 7 Gabriel .1.3.7.11. 12 9 Emilia .1.3.7.9.12. 13 9 Michael .1.3.7.9.13. 14 9 Didi .1.3.7.9.14. 1 14 David .1.3.7.9.14.1. 2 1 Eitan .1.3.7.9.14.1.2. 3 1 Ina .1.3.7.9.14.1.3. 7 3 Aaron .1.3.7.9.14.1.3.7. ...Msg 530, Poziom 16, Stan 1, Wiersz 492
Oświadczenie zostało zakończone. Maksymalna rekursja 100 została wyczerpana przed zakończeniem instrukcji.
Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path '.1.3.7.9.14.1.' .
In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname, ancpath, cycle
FROM C; This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle ------ ------ -------- ------------------- ------ 1 14 David .1. 0 2 1 Eitan .1.2. 0 3 1 Ina .1.3. 0 7 3 Aaron .1.3.7. 0 9 7 Rita .1.3.7.9. 0 11 7 Gabriel .1.3.7.11. 0 12 9 Emilia .1.3.7.9.12. 0 13 9 Michael .1.3.7.9.13. 0 14 9 Didi .1.3.7.9.14. 0 1 14 David .1.3.7.9.14.1. 1 2 1 Eitan .1.3.7.9.14.1.2. 0 3 1 Ina .1.3.7.9.14.1.3. 1 7 3 Aaron .1.3.7.9.14.1.3.7. 1 ...Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.
The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT = 1;
WITH C AS
(
SELECT empid, mgrid, empname,
CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
0 AS cycle
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname,
CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath,
CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1
ELSE 0 END AS cycle
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
AND M.cycle = 0
)
SELECT empid, mgrid, empname, cycle
FROM C; This code runs to completion, and generates the following output:
empid mgrid empname cycle ------ ------ -------- ----------- 1 14 David 0 2 1 Eitan 0 3 1 Ina 0 7 3 Aaron 0 9 7 Rita 0 11 7 Gabriel 0 12 9 Emilia 0 13 9 Michael 0 14 9 Didi 0 1 14 David 1 4 2 Seraph 0 5 2 Jiru 0 6 2 Steve 0 8 5 Lilach 0 10 5 Sean 0
You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid = NULL WHERE empid = 1;
Run the recursive query and you will find that there are no cycles present.
Wniosek
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.



