Myślę, że wszyscy już znają moje opinie na temat MERGE i dlaczego trzymam się od tego z daleka. Ale oto inny (anty) wzorzec, który widzę wszędzie, gdy ludzie chcą wykonać upsert (zaktualizuj wiersz, jeśli istnieje i wstaw go, jeśli nie):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Wygląda to na całkiem logiczny przepływ, który odzwierciedla sposób, w jaki myślimy o tym w prawdziwym życiu:
- Czy istnieje już wiersz dla tego klucza?
- TAK :OK, zaktualizuj ten wiersz.
- NIE :OK, a następnie dodaj.
Ale to marnotrawstwo.
Znalezienie wiersza w celu potwierdzenia, że istnieje, tylko po to, aby znaleźć go ponownie w celu jego aktualizacji, wykonuje dwa razy więcej za nic. Nawet jeśli klucz jest indeksowany (mam nadzieję, że zawsze tak jest). Gdybym umieścił tę logikę w schemacie blokowym i powiązał na każdym kroku rodzaj operacji, która musiałaby mieć miejsce w bazie danych, otrzymałbym to:
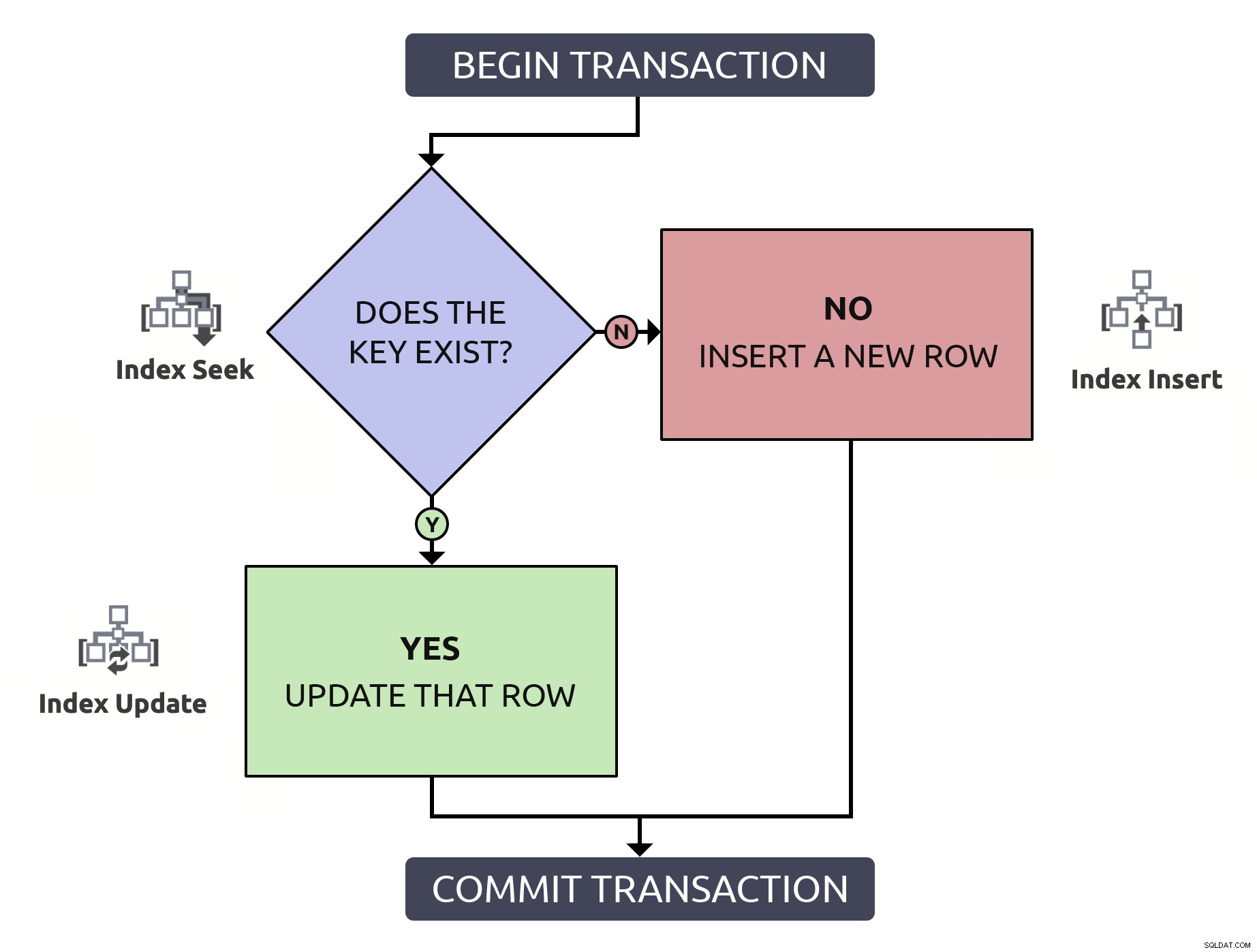 Zauważ, że wszystkie ścieżki będą wymagały dwóch operacji indeksowania.
Zauważ, że wszystkie ścieżki będą wymagały dwóch operacji indeksowania.
Co ważniejsze, pomijając wydajność, o ile nie używasz zarówno jawnej transakcji, jak i podniesiesz poziomu izolacji, wiele rzeczy może pójść nie tak, gdy wiersz jeszcze nie istnieje:
- Jeśli klucz istnieje i dwie sesje spróbują zaktualizować się jednocześnie, obie zostaną pomyślnie zaktualizowane (jeden „wygra”; „przegrany” podąży za zmianą, która się utrzyma, prowadząc do „przegranej aktualizacji”). To nie jest problem sam w sobie i tak właśnie powinniśmy oczekiwać, że system ze współbieżnością będzie działał. Paul White mówi tutaj bardziej szczegółowo o wewnętrznej mechanice, a Martin Smith mówi tutaj o kilku innych niuansach.
- Jeśli klucz nie istnieje, ale obie sesje przechodzą kontrolę istnienia w ten sam sposób, wszystko może się zdarzyć, gdy obie spróbują wstawić:
- zakleszczenie z powodu niekompatybilnych zamków;
- zgłaszaj błędy związane z naruszeniem klucza to nie powinno było się wydarzyć; lub,
- wstaw zduplikowane wartości klucza jeśli ta kolumna nie jest odpowiednio ograniczona.
Ten ostatni jest najgorszy, IMHO, ponieważ to ten, który potencjalnie uszkodzi dane . Zakleszczenia i wyjątki można łatwo poradzić sobie z takimi rzeczami, jak obsługa błędów, XACT_ABORT i ponów logikę, w zależności od tego, jak często spodziewasz się kolizji. Ale jeśli masz poczucie bezpieczeństwa, że IF EXISTS check chroni przed duplikatami (lub naruszeniami kluczy), to jest niespodzianka, która może się wydarzyć. Jeśli oczekujesz, że kolumna będzie działać jak klucz, ustaw ją jako oficjalną i dodaj ograniczenie.
„Wiele osób mówi…”
Dan Guzman mówił o warunkach wyścigu ponad dziesięć lat temu w Warunkowych warunkach wyścigu INSERT/UPDATE, a później w Warunkach wyścigu „UPSERT” z MERGE.
Michael Swart również wielokrotnie zajmował się tym tematem:
- Obalanie mitów:współbieżna aktualizacja/rozwiązania wstawiania — gdzie przyznał, że pozostawienie początkowej logiki na miejscu i tylko podniesienie poziomu izolacji zmieniło naruszenia kluczy w zakleszczenia;
- Bądź ostrożny z instrukcją scalania — gdzie sprawdził swój entuzjazm dotyczący
MERGE; i, - Czego unikać, jeśli chcesz korzystać z funkcji MERGE – gdzie po raz kolejny potwierdził, że nadal istnieje wiele ważnych powodów, aby nadal unikać
MERGE.
Upewnij się, że przeczytałeś również wszystkie komentarze do wszystkich trzech postów.
Rozwiązanie
Naprawiłem wiele impasów w mojej karierze, po prostu dostosowując się do następującego wzorca (pozbądź się nadmiarowej kontroli, zawiń sekwencję w transakcję i zabezpiecz dostęp do pierwszej tabeli odpowiednim blokowaniem):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Dlaczego potrzebujemy dwóch wskazówek? Czy to nie UPDLOCK wystarczy?
UPDLOCKsłuży do ochrony przed zakleszczeniami konwersji na wyciągu poziom (niech kolejna sesja zaczeka zamiast zachęcać ofiarę do ponownej próby).SERIALIZABLEsłuży do ochrony przed zmianami danych bazowych podczas transakcji (upewnij się, że wiersz, który nie istnieje, nadal nie istnieje).
To trochę więcej kodu, ale jest 1000% bezpieczniejsze, a nawet w najgorszym przypadku (wiersz jeszcze nie istnieje), działa tak samo jak antywzorzec. W najlepszym przypadku, jeśli aktualizujesz wiersz, który już istnieje, bardziej efektywne będzie zlokalizowanie tego wiersza tylko raz. Łącząc tę logikę z operacjami wysokiego poziomu, które musiałyby mieć miejsce w bazie danych, jest to nieco prostsze:
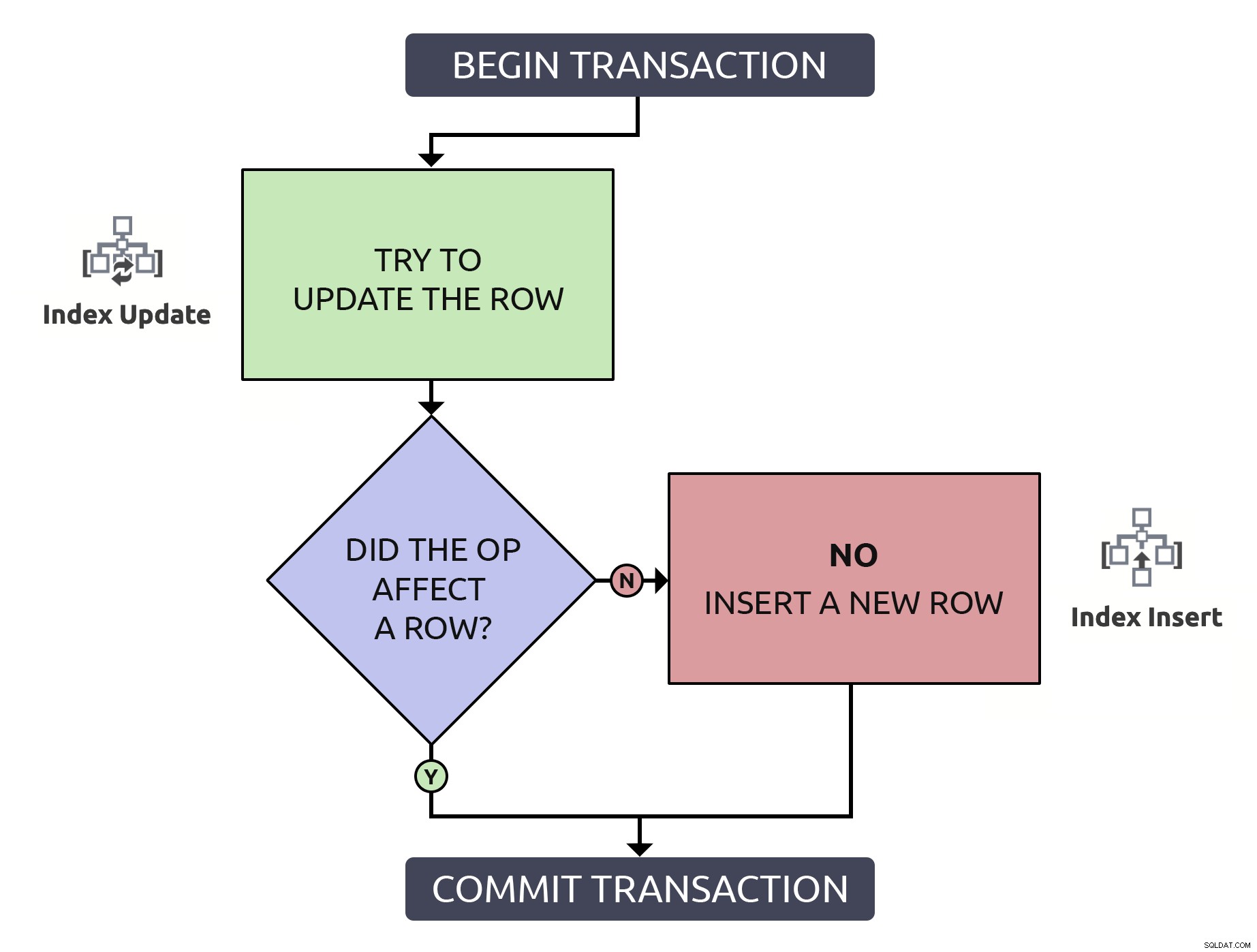 W tym przypadku jedna ścieżka wiąże się tylko z jedną operacją indeksowania.
W tym przypadku jedna ścieżka wiąże się tylko z jedną operacją indeksowania.
Ale znowu, wydajność na bok:
- Jeżeli klucz istnieje i dwie sesje próbują go zaktualizować w tym samym czasie, zarówno na zmianę, jak i pomyślnie zaktualizują wiersz , jak poprzednio.
- Jeśli klucz nie istnieje, jedna sesja „wygra” i wstawi wiersz . Drugi będzie musiał poczekać dopóki blokady nie zostaną zwolnione, aby nawet sprawdzić, czy istnieją, i być zmuszone do aktualizacji.
W obu przypadkach pisarz, który wygrał wyścig, traci swoje dane na wszystko, co „przegrany” zaktualizował po nim.
Zwróć uwagę, że ogólna przepustowość w wysoce współbieżnym systemie może cierpieć, ale jest to kompromis, na który powinieneś być gotowy. To, że otrzymujesz wiele ofiar impasu lub błędów związanych z naruszeniem klucza, ale dzieje się to szybko, nie jest dobrym wskaźnikiem wydajności. Niektórzy ludzie chcieliby, aby wszystkie blokady zostały usunięte ze wszystkich scenariuszy, ale niektóre z nich blokują, czego absolutnie potrzebujesz dla integralności danych.
A co, jeśli aktualizacja jest mniej prawdopodobna?
Oczywiste jest, że powyższe rozwiązanie optymalizuje pod kątem aktualizacji i zakłada, że klucz, do którego próbujesz pisać, będzie już istniał w tabeli tak często, jak nie. Jeśli wolisz optymalizować pod kątem wstawiania, wiedząc lub zgadując, że wstawienie będzie bardziej prawdopodobne niż aktualizacje, możesz odwrócić logikę i nadal mieć bezpieczną operację upsert:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Istnieje również podejście „po prostu zrób to”, w którym na ślepo wstawiasz i pozwalasz, aby kolizje powodowały wyjątki dla wywołującego:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
Koszt tych wyjątków często przewyższa koszt wcześniejszego sprawdzenia; musisz spróbować z mniej więcej dokładnym przypuszczeniem współczynnika trafień/chybień. Pisałem o tym tu i tutaj.
A co z przestawianiem wielu wierszy?
Powyższe dotyczy decyzji dotyczących wstawiania/aktualizacji pojedynczych wierszy, ale Justin Pealing zapytał, co zrobić, gdy przetwarzasz wiele wierszy, nie wiedząc, który z nich już istnieje?
Zakładając, że wysyłasz zestaw wierszy przy użyciu czegoś w rodzaju parametru wycenianego w tabeli, zaktualizujesz za pomocą sprzężenia, a następnie wstawisz, używając opcji NIE ISTNIEJE, ale wzorzec nadal byłby równoważny z pierwszym podejściem powyżej:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Jeśli zbierasz wiele wierszy w inny sposób niż TVP (XML, lista rozdzielana przecinkami, voodoo), umieść je najpierw w formie tabeli i dołącz do tego, co to jest. Uważaj, aby w tym scenariuszu nie optymalizować najpierw pod kątem wstawek, w przeciwnym razie niektóre wiersze zostaną zaktualizowane dwukrotnie.
Wniosek
Te wzory są lepsze od tych, które widzę zbyt często i mam nadzieję, że zaczniesz ich używać. Wskażę ten post za każdym razem, gdy znajdę IF EXISTS wzór na wolności. I, hej, kolejny krzyk do Paula White'a (sql.kiwi | @SQK_Kiwi), ponieważ jest tak doskonały w ułatwianiu zrozumienia trudnych pojęć, a co za tym idzie, wyjaśnianiu.
A jeśli uważasz, że musisz użyj MERGE , proszę nie @ mnie; albo masz dobry powód (może potrzebujesz niejasnego MERGE -tylko funkcjonalność) lub nie potraktowałeś poważnie powyższych linków.