Jest to trzecia część serii poświęconej rozwiązaniom wyzwania generatora szeregów liczbowych. W części 1 omówiłem rozwiązania, które generują wiersze w locie. W części 2 omówiłem rozwiązania, które odpytują fizyczną tabelę podstawową, którą wstępnie wypełniasz wierszami. W tym miesiącu skoncentruję się na fascynującej technice, którą można wykorzystać do sprostania naszemu wyzwaniu, ale która ma również ciekawe zastosowania znacznie wykraczające poza to. Nie znam oficjalnej nazwy tej techniki, ale jest ona nieco podobna w koncepcji do eliminacji partycji poziomej, więc będę się do niej nieformalnie nazywać eliminacją jednostek poziomych technika. Technika ta może przynieść interesujące pozytywne korzyści w zakresie wydajności, ale istnieją również zastrzeżenia, o których należy pamiętać, ponieważ w pewnych warunkach może to spowodować obniżenie wydajności.
Jeszcze raz dziękujemy Alanowi Bursteinowi, Joe Obbishowi, Adamowi Machanicowi, Christopherowi Fordowi, Jeffowi Modenowi, Charliemu, NoamGrowi, Kamilowi Kosno, Dave'owi Masonowi, Johnowi Nelsonowi #2, Edowi Wagnerowi, Michaelowi Burbea i Paulowi White'owi za podzielenie się swoimi pomysłami i komentarzami.
Przeprowadzę testy w tempdb, włączając statystyki czasu:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME ON;
Wcześniejsze pomysły
Technika eliminowania jednostek poziomych może być używana jako alternatywa dla logiki eliminowania kolumn lub eliminacji jednostek pionowych technikę, na której polegałem w kilku rozwiązaniach, które omówiłem wcześniej. Możesz przeczytać o podstawach logiki eliminacji kolumn za pomocą wyrażeń tabelowych w Podstawy wyrażeń tabelowych, Część 3 – Tabele pochodne, zagadnienia dotyczące optymalizacji w sekcji „Rzutowanie kolumn i słowo na SELECT *”.
Podstawową ideą techniki eliminacji jednostek w pionie jest to, że jeśli masz zagnieżdżone wyrażenie tabelowe, które zwraca kolumny x i y, a twoje zewnętrzne zapytanie odwołuje się tylko do kolumny x, proces kompilacji zapytania eliminuje y z początkowego drzewa zapytań, a zatem z planu nie musi tego oceniać. Ma to kilka pozytywnych implikacji związanych z optymalizacją, takich jak uzyskanie pokrycia indeksu za pomocą samego x, a jeśli y jest wynikiem obliczeń, w ogóle nie trzeba oceniać podstawowego wyrażenia y. Ten pomysł leżał u podstaw rozwiązania Alana Bursteina. Opierałem się również na kilku innych rozwiązaniach, które omówiłem, takich jak funkcja dbo.GetNumsAlanCharlieItzikBatch (z części 1), funkcje dbo.GetNumsJohn2DaveObbishAlanCharlieItzik i dbo.GetNumsJohn2DaveObbishAlan2 z części 2, i inne. Jako przykład użyję dbo.GetNumsAlanCharlieItzikBatch jako podstawowego rozwiązania z logiką eliminacji wertykalnej.
Przypominamy, że to rozwiązanie używa sprzężenia z fikcyjną tabelą, która ma indeks magazynu kolumn, aby uzyskać przetwarzanie wsadowe. Oto kod do utworzenia fikcyjnej tabeli:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
A oto kod z definicją funkcji dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Użyłem następującego kodu do przetestowania wydajności funkcji ze 100 mln wierszy, zwracając obliczoną kolumnę wyników n (manipulacja wynikiem funkcji ROW_NUMBER), uporządkowaną według n:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Oto statystyki czasu, które otrzymałem podczas tego testu:
Czas procesora =9328 ms, upływ czasu =9330 ms.Użyłem następującego kodu do przetestowania wydajności funkcji ze 100 mln wierszy, zwracając kolumnę rn (bezpośrednią, niezmodyfikowaną, wynik funkcji ROW_NUMBER), uporządkowaną według rn:
DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY rn OPTION(MAXDOP 1);
Oto statystyki czasu, które otrzymałem podczas tego testu:
Czas procesora =7296 ms, upływ czasu =7291 ms.Przyjrzyjmy się ważnym pomysłom zawartym w tym rozwiązaniu.
Opierając się na logice eliminacji kolumn, alan wpadł na pomysł, aby zwrócić nie tylko jedną kolumnę z serią liczb, ale trzy:
- Kolumna rn reprezentuje niezmodyfikowany wynik funkcji ROW_NUMBER, która zaczyna się od 1. Jest tania w obliczeniach. Jest to zachowanie porządku zarówno wtedy, gdy podajesz stałe, jak i niestałe (zmienne, kolumny) jako dane wejściowe funkcji. Oznacza to, że gdy twoje zewnętrzne zapytanie używa ORDER BY rn, nie otrzymasz w planie operatora sortowania.
- Kolumna n reprezentuje obliczenia oparte na @low, stałej i numerze wiersza (wynik funkcji ROW_NUMBER). Jest to zachowanie kolejności względem rownum, gdy podajesz stałe jako dane wejściowe do funkcji. Dzieje się tak dzięki spostrzeżeniom Charliego dotyczącym ciągłego składania (szczegóły w części 1). Jednak nie jest to zachowanie kolejności, gdy podajesz niestałe jako dane wejściowe, ponieważ nie otrzymujesz stałego składania. Pokażę to później w sekcji o zastrzeżeniach.
- Kolumna op reprezentuje n w odwrotnej kolejności. Jest to wynik obliczeń, a nie zachowanie porządku.
Opierając się na logice eliminacji kolumn, jeśli chcesz zwrócić serię liczb zaczynającą się od 1, zapytaj o kolumnę rn, co jest tańsze niż zapytanie n. Jeśli potrzebujesz serii liczb zaczynającej się od wartości innej niż 1, wpisz zapytanie n i pokryj dodatkowy koszt. Jeśli potrzebujesz wyniku uporządkowanego według kolumny liczbowej, ze stałymi jako danymi wejściowymi, możesz użyć ORDER BY rn lub ORDER BY n. Ale z niestałymi jako danymi wejściowymi, chcesz upewnić się, że używasz ORDER BY rn. Dobrym pomysłem może być po prostu zawsze trzymać się używania ORDER BY rn, gdy chcesz, aby zamówiony wynik był bezpieczny.
Idea eliminacji jednostek poziomych jest podobna do idei eliminacji jednostek pionowych, tylko dotyczy zestawów wierszy zamiast zestawów kolumn. W rzeczywistości Joe Obbish oparł się na tym pomyśle w swojej funkcji dbo.GetNumsObbish (z części 2), a my pójdziemy o krok dalej. W swoim rozwiązaniu Joe ujednolicił wiele zapytań reprezentujących rozłączne podzakresy liczb, używając filtra w klauzuli WHERE każdego zapytania w celu zdefiniowania zastosowania podzakresu. Kiedy wywołujesz funkcję i przekazujesz stałe dane wejściowe reprezentujące ograniczniki pożądanego zakresu, SQL Server eliminuje nieodpowiednie zapytania w czasie kompilacji, więc plan nawet ich nie odzwierciedla.
Eliminacja jednostek poziomych, czas kompilacji a czas wykonywania
Być może dobrym pomysłem byłoby rozpoczęcie od zademonstrowania koncepcji poziomej eliminacji jednostek w bardziej ogólnym przypadku, a także omówienie ważnego rozróżnienia między eliminacją w czasie kompilacji a eliminacją w czasie wykonywania. Następnie możemy omówić, jak zastosować ten pomysł do naszego wyzwania dotyczącego serii liczb.
W moim przykładzie użyję trzech tabel o nazwach dbo.T1, dbo.T2 i dbo.T3. Użyj następującego kodu DDL i DML, aby utworzyć i wypełnić te tabele:
DROP TABLE IF EXISTS dbo.T1, dbo.T2, dbo.T3; GO CREATE TABLE dbo.T1(col1 INT); INSERT INTO dbo.T1(col1) VALUES(1); CREATE TABLE dbo.T2(col1 INT); INSERT INTO dbo.T2(col1) VALUES(2); CREATE TABLE dbo.T3(col1 INT); INSERT INTO dbo.T3(col1) VALUES(3);
Załóżmy, że chcesz zaimplementować wbudowany TVF o nazwie dbo.OneTable, który akceptuje jedną z trzech powyższych nazw tabel jako dane wejściowe i zwraca dane z żądanej tabeli. W oparciu o koncepcję eliminacji jednostek poziomych, możesz zaimplementować tę funkcję w następujący sposób:
CREATE OR ALTER FUNCTION dbo.OneTable(@WhichTable AS NVARCHAR(257)) RETURNS TABLE AS RETURN SELECT col1 FROM dbo.T1 WHERE @WhichTable = N'dbo.T1' UNION ALL SELECT col1 FROM dbo.T2 WHERE @WhichTable = N'dbo.T2' UNION ALL SELECT col1 FROM dbo.T3 WHERE @WhichTable = N'dbo.T3'; GO
Pamiętaj, że wbudowany TVF stosuje osadzanie parametrów. Oznacza to, że gdy jako dane wejściowe przekażesz stałą, taką jak N'dbo.T2', proces wstawiania zastępuje wszystkie odwołania do @WhichTable stałą przed optymalizacją . Proces eliminacji może następnie usunąć odniesienia do T1 i T3 z początkowego drzewa zapytań, dzięki czemu optymalizacja zapytań skutkuje planem, który odwołuje się tylko do T2. Przetestujmy ten pomysł za pomocą następującego zapytania:
SELECT * FROM dbo.OneTable(N'dbo.T2');
Plan dla tego zapytania pokazano na rysunku 1.
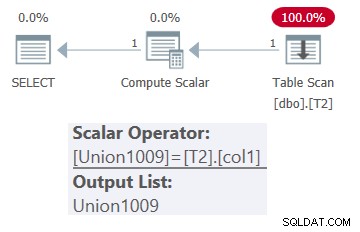 Rysunek 1:Plan dla dbo.OneTable ze stałymi danymi wejściowymi
Rysunek 1:Plan dla dbo.OneTable ze stałymi danymi wejściowymi
Jak widać, w planie pojawia się tylko tabela T2.
Sprawy są nieco trudniejsze, gdy jako dane wejściowe przekazujesz niestałą. Może tak być w przypadku używania zmiennej, parametru procedury lub przekazywania kolumny przez APPLY. Wartość wejściowa jest albo nieznana w czasie kompilacji, albo należy wziąć pod uwagę potencjał ponownego wykorzystania sparametryzowanego planu.
Optymalizator nie może wyeliminować żadnej tabeli z planu, ale wciąż ma pewną sztuczkę. Może używać operatorów filtrów startowych nad poddrzewami, które uzyskują dostęp do tabel, i wykonywać tylko odpowiednie poddrzewo w oparciu o wartość środowiska uruchomieniowego @WhichTable. Użyj następującego kodu, aby przetestować tę strategię:
DECLARE @T AS NVARCHAR(257) = N'dbo.T2'; SELECT * FROM dbo.OneTable(@T);
Plan tego wykonania pokazano na rysunku 2:
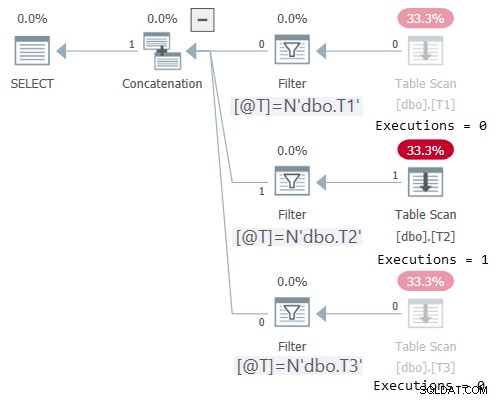 Rysunek 2:Plan dla dbo.OneTable z niestałymi danymi wejściowymi
Rysunek 2:Plan dla dbo.OneTable z niestałymi danymi wejściowymi
Eksplorator planu sprawia, że jest cudownie oczywiste, aby zobaczyć, że tylko odpowiednie poddrzewo zostało wykonane (Wykonania =1) i wyszarza poddrzewa, które nie zostały wykonane (Wykonania =0). Ponadto STATISTICS IO pokazuje informacje o I/O tylko dla tabeli, do której uzyskano dostęp:
Tabela „T2”. Liczba skanów 1, odczyty logiczne 1, odczyty fizyczne 0, odczyty serwera strony 0, odczyty z wyprzedzeniem 0, odczyty z wyprzedzeniem serwera strony 0, odczyty logiczne lobu 0, odczyty fizyczne lobu 0, odczyty serwera strony lobu 0, odczyty naprzód odczytuje 0, serwer stron lob odczyt z wyprzedzeniem odczytuje 0.Stosowanie logiki eliminacji jednostek poziomych do wyzwania serii liczb
Jak wspomniano, możesz zastosować koncepcję poziomej eliminacji jednostek, modyfikując dowolne z wcześniejszych rozwiązań, które obecnie używają pionowej logiki eliminacji. Użyję funkcji dbo.GetNumsAlanCharlieItzikBatch jako punktu wyjścia dla mojego przykładu.
Przypomnijmy, że Joe Obbish użył poziomej eliminacji jednostek, aby wyodrębnić odpowiednie rozłączne podzakresy szeregu liczb. Użyjemy tej koncepcji do poziomego oddzielenia tańszych obliczeń (rn), gdzie @low =1 od droższych obliczeń (n), gdzie @low <> 1.
Skoro już przy tym jesteśmy, możemy poeksperymentować, dodając pomysł Jeffa Modena do jego funkcji fnTally, w której używa on wiersza wartowniczego o wartości 0 dla przypadków, w których zakres zaczyna się od @low =0.
Mamy więc cztery jednostki poziome:
- Wiersz wartownika z 0, gdzie @low =0, z n =0
- TOP (@high) wierszy, gdzie @low =0, z tanim n =rownum, a op =@high – rownum
- TOP (@high) wierszy, gdzie @low =1, przy tanim n =numer rzędu, a op =@high + 1 – numer rzędu
- TOP(@high – @low + 1) wiersze, gdzie @low <> 0 AND @low <> 1, z droższym n =@low – 1 + numer wiersza, a op =@high + 1 – numer wiersza
To rozwiązanie łączy idee Alana, Charliego, Joe, Jeffa i mnie, więc nazwiemy wersję funkcji dbo.GetNumsAlanCharlieJoeJeffItzikBatch w trybie wsadowym.
Po pierwsze, pamiętaj, aby upewnić się, że nadal masz pustą tabelę dbo.BatchMe, aby uzyskać przetwarzanie wsadowe w naszym rozwiązaniu, lub użyj następującego kodu, jeśli nie:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Oto kod z definicją funkcji dbo.GetNumsAlanCharlieJoeJeffItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeJeffItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT @low AS n, @high AS op WHERE @low = 0 AND @high > @low
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 0
ORDER BY rownum
UNION ALL
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 0 AND @low <> 1
ORDER BY rownum;
GO Ważne:koncepcja eliminacji jednostek poziomych jest bez wątpienia bardziej skomplikowana do wdrożenia niż pionowa, więc po co zawracać sobie głowę? Ponieważ zdejmuje z użytkownika odpowiedzialność za wybór właściwej kolumny. Użytkownik musi się tylko martwić o wysyłanie zapytań do kolumny o nazwie n, w przeciwieństwie do pamiętania o użyciu rn, gdy zakres zaczyna się od 1, a n w przeciwnym razie.
Zacznijmy od przetestowania rozwiązania ze stałymi wejściami 1 i 100 000 000, prosząc o uporządkowanie wyniku:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Plan tego wykonania pokazano na rysunku 3.
 Rysunek 3:Plan dla dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Rysunek 3:Plan dla dbo.GetNumsAlanCharlieJoeJeffItzikBatch(1, 100M)
Zauważ, że jedyna zwracana kolumna jest oparta na bezpośrednim, niezmodyfikowanym wyrażeniu ROW_NUMBER (Expr1313). Zauważ też, że nie ma potrzeby sortowania w planie.
Otrzymałem następujące statystyki czasu dla tego wykonania:
Czas procesora =7359 ms, upływ czasu =7354 ms.Środowisko wykonawcze odpowiednio odzwierciedla fakt, że plan używa trybu wsadowego, niezmodyfikowanego wyrażenia ROW_NUMBER i braku sortowania.
Następnie przetestuj funkcję ze stałym zakresem od 0 do 99 999 999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Plan tego wykonania pokazano na rysunku 4.
 Rysunek 4:Plan dla dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Rysunek 4:Plan dla dbo.GetNumsAlanCharlieJoeJeffItzikBatch(0, 99999999)
Plan używa operatora łączenia łączenia (konkatenacji), aby scalić wiersz wartownika z wartością 0 i resztą. Mimo że druga część jest tak samo wydajna jak poprzednio, logika łączenia pobiera dość duże żniwo, wynoszące około 26% w czasie wykonywania, co skutkuje następującymi statystykami czasowymi:
Czas procesora =9265 ms, upływ czasu =9298 ms.Przetestujmy funkcję ze stałym zakresem od 2 do 100 000 001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Plan tego wykonania pokazano na rysunku 5.
 Rysunek 5:Plan dla dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Rysunek 5:Plan dla dbo.GetNumsAlanCharlieJoeJeffItzikBatch(2, 100000001)
Tym razem nie ma kosztownej logiki łączenia, ponieważ część wiersza wartownika jest nieistotna. Zauważ jednak, że zwrócona kolumna jest zmanipulowanym wyrażeniem @low – 1 + rownum, które po osadzeniu/umieszczeniu parametrów i stałym złożeniu stało się 1 + rownum.
Oto statystyki czasu, które otrzymałem dla tego wykonania:
Czas procesora =9000 ms, upływ czasu =9015 ms.Zgodnie z oczekiwaniami nie jest to tak szybkie, jak w przypadku zakresu zaczynającego się od 1, ale co ciekawe, szybsze niż w przypadku zakresu zaczynającego się od 0.
Usuwanie wiersza wartowniczego 0
Biorąc pod uwagę, że technika z wierszem wartowniczym o wartości 0 wydaje się być wolniejsza niż zastosowanie manipulacji do wartości rownum, sensowne jest po prostu jej unikanie. To prowadzi nas do uproszczonego rozwiązania opartego na eliminacjach poziomych, które łączy pomysły Alana, Charliego, Joe i mnie. Wywołam funkcję z tym rozwiązaniem dbo.GetNumsAlanCharlieJoeItzikBatch. Oto definicja funkcji:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low = 1
ORDER BY rownum
UNION ALL
SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
WHERE @low <> 1
ORDER BY rownum;
GO Przetestujmy to w zakresie od 1 do 100M:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Zgodnie z oczekiwaniami plan jest taki sam, jak ten pokazany wcześniej na rysunku 3.
W związku z tym otrzymałem następujące statystyki czasu:
Czas procesora =7219 ms, upływ czasu =7243 ms.Przetestuj to w zakresie od 0 do 99 999 999:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(0, 99999999) ORDER BY n OPTION(MAXDOP 1);
Tym razem otrzymujesz taki sam plan, jak ten pokazany wcześniej na rysunku 5, a nie na rysunku 4.
Oto statystyki czasu, które otrzymałem dla tej egzekucji:
Czas procesora =9313 ms, upływ czasu =9334 ms.Przetestuj go z zakresem od 2 do 100 000 001:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(2, 100000001) ORDER BY n OPTION(MAXDOP 1);
Ponownie otrzymujesz taki sam plan, jak ten pokazany wcześniej na rysunku 5.
Otrzymałem następujące statystyki czasu dla tego wykonania:
Czas procesora =9125 ms, upływ czasu =9148 ms.Ostrzeżenia dotyczące niestałych danych wejściowych
Zarówno w przypadku pionowych, jak i poziomych technik eliminacji jednostek wszystko działa idealnie, o ile jako dane wejściowe przekazujesz stałe. Musisz jednak zdawać sobie sprawę z ostrzeżeń, które mogą skutkować spadkiem wydajności, gdy przekazujesz niestałe dane wejściowe. Technika pionowej eliminacji jednostek ma mniej problemów, a problemy, które istnieją, są łatwiejsze do rozwiązania, więc zacznijmy od tego.
Pamiętaj, że w tym artykule użyliśmy funkcji dbo.GetNumsAlanCharlieItzikBatch jako naszego przykładu, która opiera się na koncepcji pionowej eliminacji jednostek. Przeprowadźmy serię testów z niestałymi danymi wejściowymi, takimi jak zmienne.
Jako pierwszy test zwrócimy rn i poprosimy o dane uporządkowane przez rn:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = rn FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Pamiętaj, że rn reprezentuje niezmanipulowane wyrażenie ROW_NUMBER, więc fakt, że używamy niestałych danych wejściowych, nie ma w tym przypadku specjalnego znaczenia. Nie ma potrzeby wyraźnego sortowania w planie.
Otrzymałem następujące statystyki czasu dla tej egzekucji:
Czas procesora =7390 ms, upływ czasu =7386 ms.Te liczby reprezentują idealny przypadek.
W następnym teście uporządkuj wiersze wyników według n:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Plan tego wykonania pokazano na rysunku 6.
 Rysunek 6:Plan dla dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) zamawiania przez n
Rysunek 6:Plan dla dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) zamawiania przez n
Widzisz problem? Po wstawieniu @low zostało zastąpione przez @mylow, a nie przez wartość w @mylow, która wynosi 1. W konsekwencji nie miało miejsca ciągłe składanie, a zatem n nie jest zachowaniem kolejności względem rownum. Doprowadziło to do wyraźnego sortowania w planie.
Oto statystyki czasu, które otrzymałem dla tego wykonania:
Czas procesora =25141 ms, upływ czasu =25628 ms.Czas wykonania prawie potroił się w porównaniu do sytuacji, w której jawne sortowanie nie było potrzebne.
Prostym obejściem tego problemu jest użycie oryginalnego pomysłu Alana Bursteina, aby zawsze porządkować według rn, gdy potrzebujesz uporządkowanego wyniku, zarówno podczas zwracania rn, jak i zwracania n, na przykład:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(@mylow, @myhigh) ORDER BY rn OPTION(MAXDOP 1);
Tym razem w planie nie ma wyraźnego sortowania.
Otrzymałem następujące statystyki czasu dla tego wykonania:
Czas procesora =9156 ms, upływ czasu =9184 ms.Liczby odpowiednio odzwierciedlają fakt, że zwracasz zmanipulowane wyrażenie, ale nie powoduje to wyraźnego sortowania.
W przypadku rozwiązań opartych na technice poziomej eliminacji jednostek, takich jak nasza funkcja dbo.GetNumsAlanCharlieJoeItzikBatch, sytuacja jest bardziej skomplikowana w przypadku korzystania z niestałych danych wejściowych.
Najpierw przetestujmy funkcję z bardzo małym zakresem 10 liczb:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Plan tego wykonania pokazano na rysunku 7.
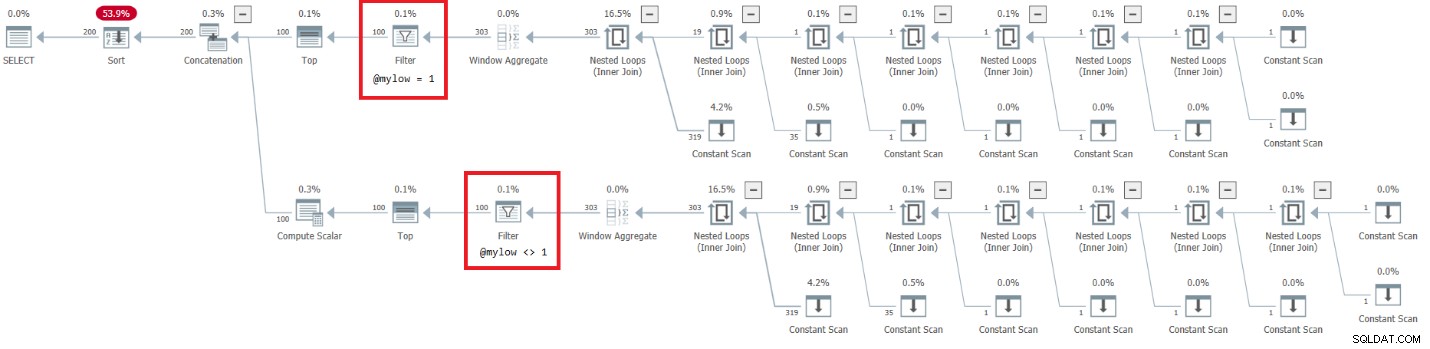 Rysunek 7:Plan dla dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Rysunek 7:Plan dla dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Ten plan ma bardzo niepokojącą stronę. Zauważ, że operatory filtrów pojawiają się poniżej Najlepsi operatorzy! W każdym wywołaniu funkcji z niestałymi danymi wejściowymi naturalnie jedna z gałęzi poniżej operatora Concatenation zawsze będzie miała fałszywy warunek filtrowania. Jednak oba operatory Top proszą o niezerową liczbę wierszy. Tak więc operator Top nad operatorem z warunkiem fałszywego filtru zapyta o wiersze i nigdy nie zostanie spełniony, ponieważ operator filtru będzie odrzucał wszystkie wiersze, które otrzyma z węzła podrzędnego. Praca w poddrzewie poniżej operatora filtru będzie musiała dobiegać do końca. W naszym przypadku oznacza to, że poddrzewo przejdzie przez pracę generowania wierszy 4B, które operator filtru odrzuci. Zastanawiasz się, dlaczego operator filtra zawraca sobie głowę żądaniem wierszy ze swojego węzła podrzędnego, ale wydaje się, że tak to obecnie działa. Trudno to zobaczyć na planie statycznym. Łatwiej jest to zobaczyć na żywo, na przykład dzięki opcji wykonywania zapytań na żywo w SentryOne Plan Explorer, jak pokazano na rysunku 8. Wypróbuj.
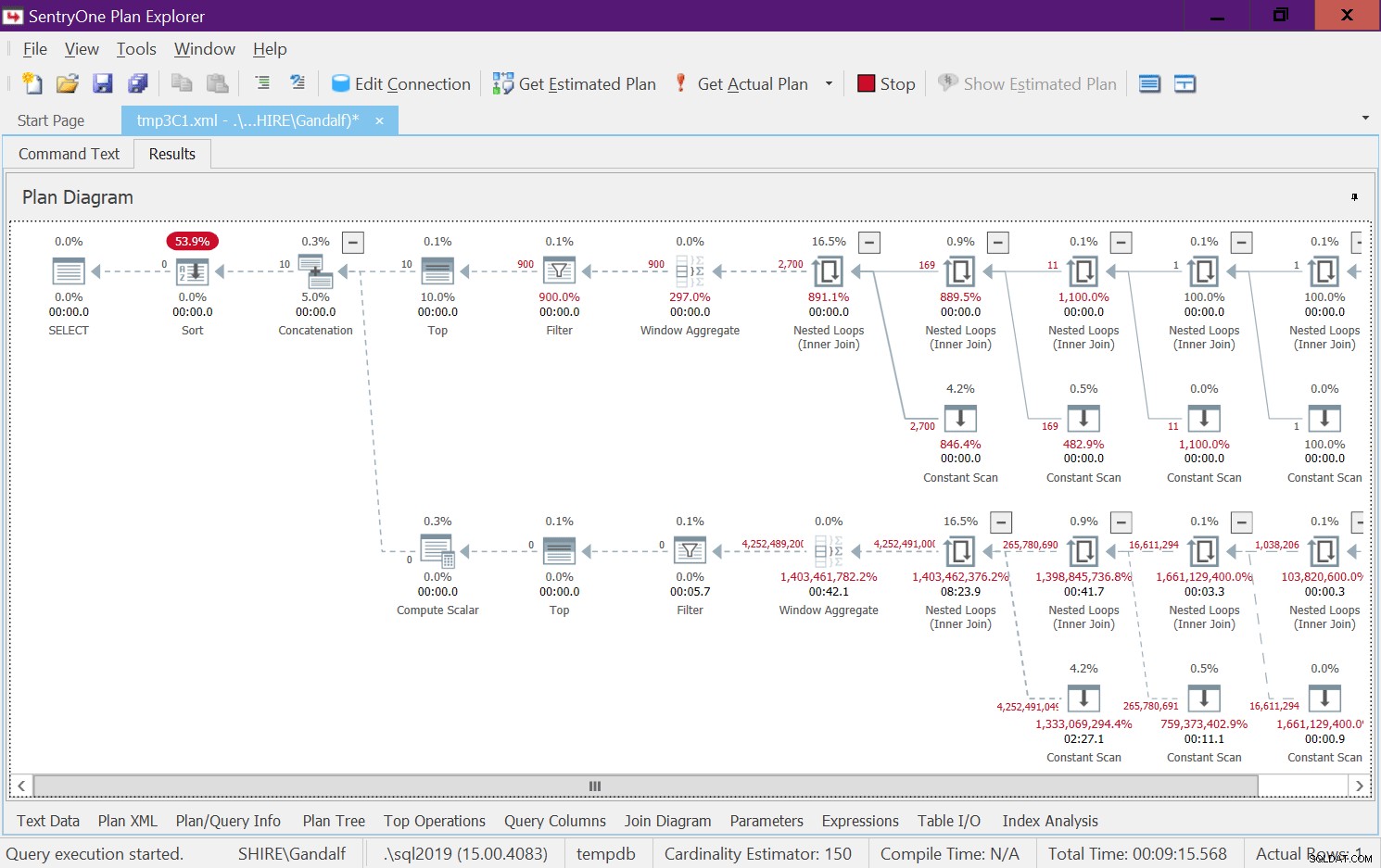 Rysunek 8:Statystyki zapytań na żywo dla dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Rysunek 8:Statystyki zapytań na żywo dla dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Ukończenie tego testu na moim komputerze zajęło 9:15 minut i pamiętaj, że żądanie dotyczyło zwrócenia zakresu 10 liczb.
Zastanówmy się, czy istnieje sposób na uniknięcie aktywacji nieistotnego poddrzewa w całości. Aby to osiągnąć, chciałbyś, aby operatory filtrów startowych pojawiały się powyżej najlepszych operatorów zamiast pod nimi. Jeśli czytasz Podstawy wyrażeń tabelowych, Część 4 — Tabele pochodne, rozważania dotyczące optymalizacji, ciąg dalszy, wiesz, że filtr TOP zapobiega rozgnieżdżaniu wyrażeń tabelowych. Wszystko, co musisz zrobić, to umieścić zapytanie TOP w tabeli pochodnej i zastosować filtr w zapytaniu zewnętrznym względem tabeli pochodnej.
Oto nasza zmodyfikowana funkcja implementująca tę sztuczkę:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieJoeItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT *
FROM ( SELECT TOP(@high)
rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D1
WHERE @low = 1
UNION ALL
SELECT *
FROM ( SELECT TOP(@high - @low + 1)
@low - 1 + rownum AS n,
@high + 1 - rownum AS op
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum ) AS D2
WHERE @low <> 1;
GO Zgodnie z oczekiwaniami, egzekucje ze stałymi zachowują się i działają tak samo, jak bez sztuczki.
Jeśli chodzi o wejścia niestałe, teraz przy małych zakresach jest bardzo szybki. Oto test z zakresem 10 liczb:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 10; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Plan tego wykonania pokazano na rysunku 9.
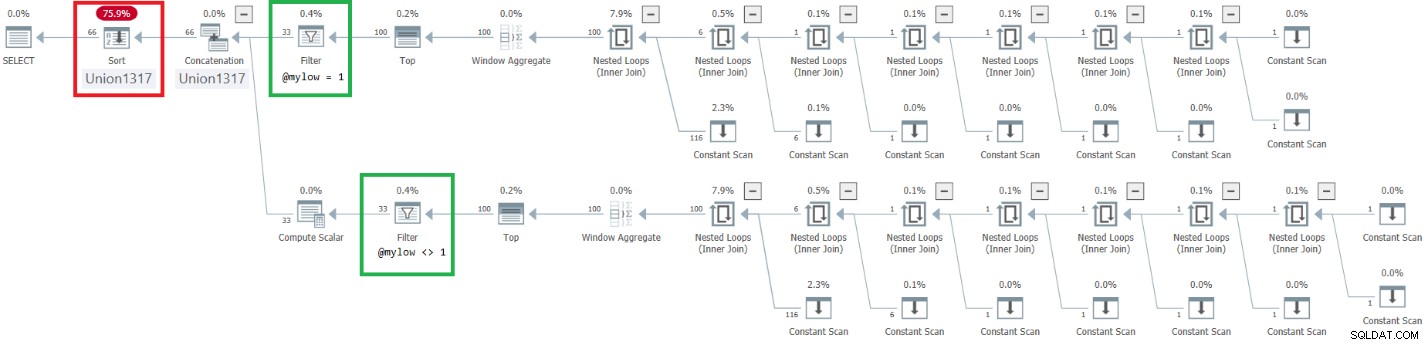 Rysunek 9:Plan ulepszonego dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Rysunek 9:Plan ulepszonego dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh)
Zauważ, że osiągnięto pożądany efekt umieszczenia operatorów filtra nad operatorami Top. Jednak kolumna porządkowania n jest traktowana jako wynik manipulacji, a zatem nie jest uważana za kolumnę zachowującą kolejność względem rownum. W związku z tym w planie jest wyraźne sortowanie.
Przetestuj funkcję z dużym zakresem 100M liczb:
DECLARE @mylow AS BIGINT = 1, @myhigh AS BIGINT = 100000000; DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieJoeItzikBatch(@mylow, @myhigh) ORDER BY n OPTION(MAXDOP 1);
Otrzymałem następujące statystyki czasu:
Czas procesora =29907 ms, upływ czasu =29909 ms.Co za porażka; to było prawie idealne!
Podsumowanie wyników i statystyki
Rysunek 10 zawiera podsumowanie statystyk czasu dla różnych rozwiązań.
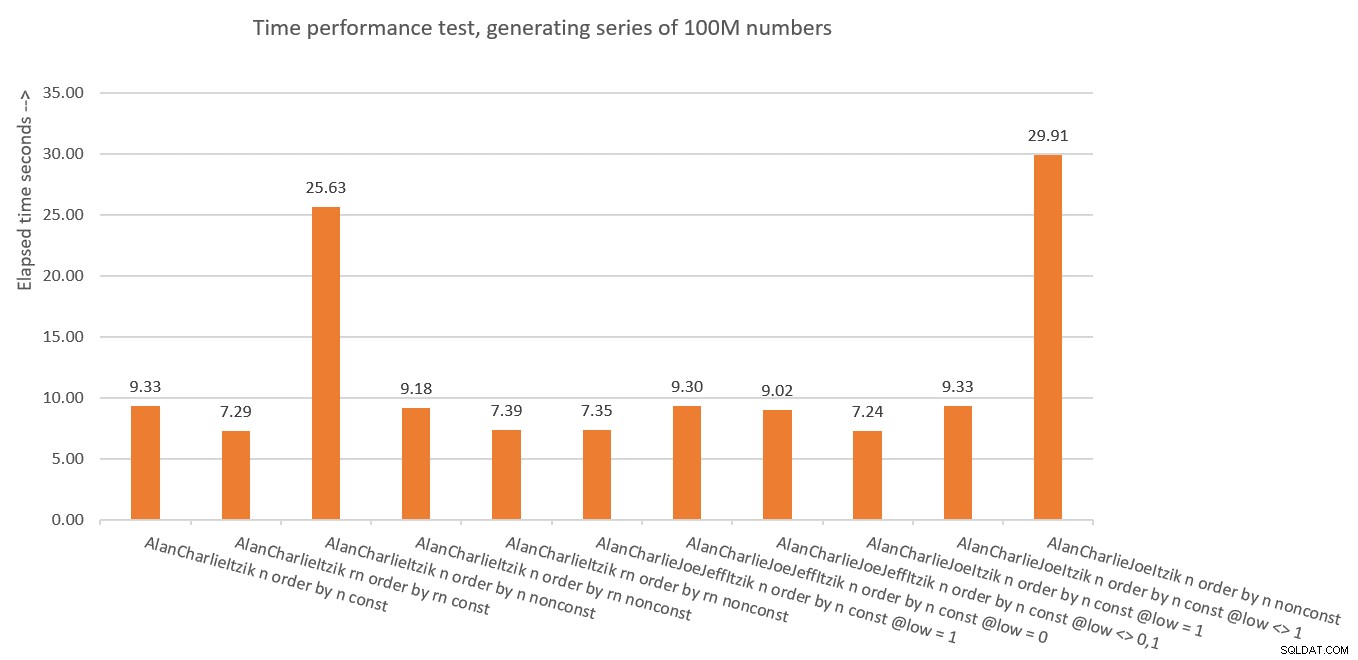 Rysunek 10:Podsumowanie wydajności czasowej rozwiązań
Rysunek 10:Podsumowanie wydajności czasowej rozwiązań
Więc czego nauczyliśmy się z tego wszystkiego? Chyba nie zrobię tego ponownie! Żartuję. Dowiedzieliśmy się, że bezpieczniej jest używać koncepcji eliminacji pionowej, takiej jak w dbo.GetNumsAlanCharlieItzikBatch, która ujawnia zarówno niezmanipulowany wynik ROW_NUMBER (rn), jak i zmanipulowany (n). Tylko upewnij się, że kiedy potrzebujesz zwrócić zamówiony wynik, zawsze porządkuj według rn, niezależnie od tego, czy zwracasz rn, czy n.
Jeśli masz absolutną pewność, że Twoje rozwiązanie zawsze będzie używane ze stałymi jako danymi wejściowymi, możesz użyć koncepcji eliminacji jednostek poziomych. Spowoduje to bardziej intuicyjne rozwiązanie dla użytkownika, ponieważ będzie on wchodzić w interakcję z jedną kolumną dla rosnących wartości. Nadal sugerowałbym użycie sztuczki z tabelami pochodnymi, aby zapobiec rozgnieżdżaniu i umieścić operatory filtra nad operatorami Top, jeśli funkcja jest kiedykolwiek używana z niestałymi danymi wejściowymi, tak dla pewności.
Jeszcze nie skończyliśmy. W przyszłym miesiącu będę kontynuować odkrywanie dodatkowych rozwiązań.