Gość Autor:Michael J Swart (@MJSwart)
Spędzam dużo czasu na przekładaniu wymagań oprogramowania na schematy i zapytania. Te wymagania są czasami łatwe do wdrożenia, ale często są trudne. Chcę omówić wybory dotyczące projektowania interfejsu użytkownika, które prowadzą do wzorców dostępu do danych, których implementacja przy użyciu SQL Server jest niewygodna.
Sortuj według kolumny
Sort-By-Column to tak dobrze znany wzorzec, że możemy przyjąć to za pewnik. Za każdym razem, gdy wchodzimy w interakcję z oprogramowaniem wyświetlającym tabelę, możemy oczekiwać, że kolumny będą można sortować w następujący sposób:
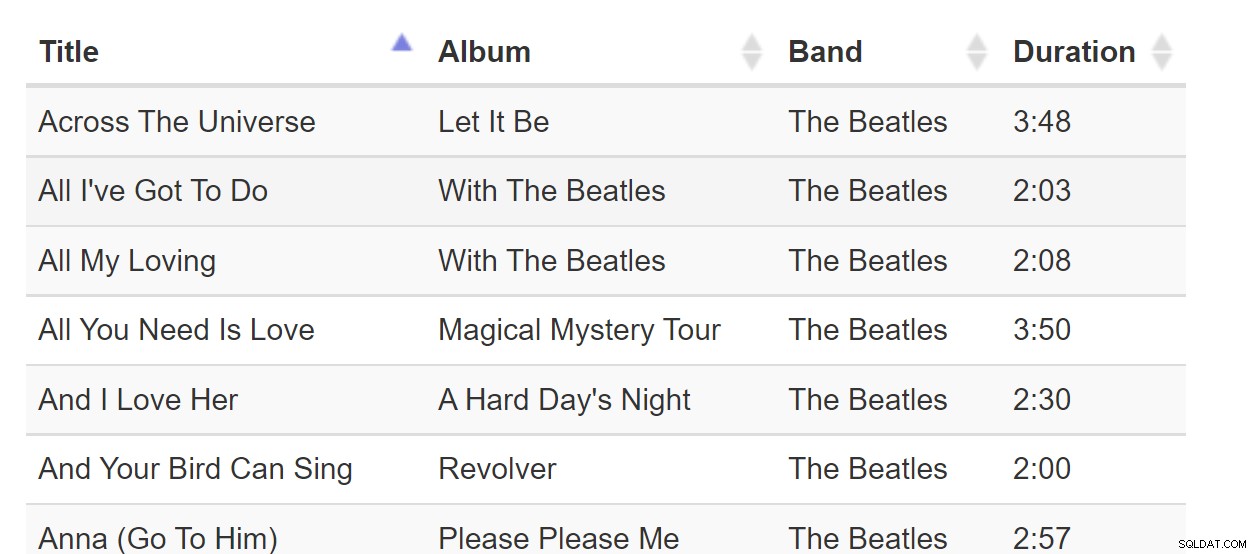
Sort-By-Colunn to świetny wzorzec, gdy wszystkie dane zmieszczą się w przeglądarce. Ale jeśli zestaw danych ma miliardy wierszy, może to być niewygodne, nawet jeśli strona internetowa wymaga tylko jednej strony danych. Rozważ poniższą tabelę piosenek:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); I rozważ te cztery zapytania posortowane według każdej kolumny:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
Nawet w przypadku tak prostego zapytania istnieją różne plany zapytań. Pierwsze dwa zapytania wykorzystują indeksy pokrywające:
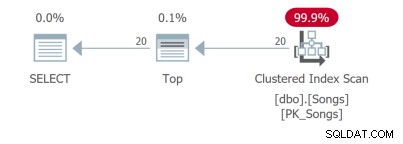
Trzecie zapytanie wymaga wyszukania klucza, co nie jest idealne:
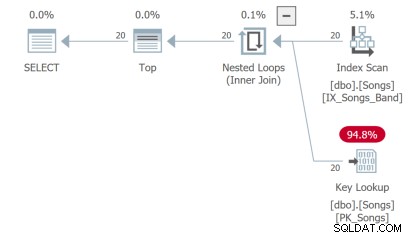
Ale najgorsze jest czwarte zapytanie, które musi przeskanować całą tabelę i wykonać sortowanie w celu zwrócenia pierwszych 20 wierszy:
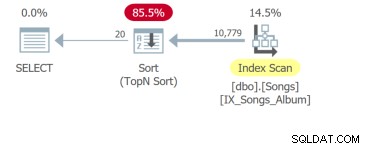
Chodzi o to, że chociaż jedyną różnicą jest klauzula ORDER BY, zapytania te należy analizować osobno. Podstawową jednostką strojenia SQL jest zapytanie. Więc jeśli pokażesz mi wymagania dotyczące interfejsu użytkownika z dziesięcioma kolumnami, które można sortować, pokażę ci dziesięć zapytań do przeanalizowania.
Kiedy to staje się niezręczne?
Funkcja Sort-By-Column to świetny wzorzec interfejsu użytkownika, ale może być niewygodna, jeśli dane pochodzą z ogromnej, rosnącej tabeli z wieloma, wieloma kolumnami. Tworzenie indeksów pokrywających w każdej kolumnie może być kuszące, ale wiąże się to z innymi kompromisami. Indeksy magazynu kolumn mogą pomóc w niektórych okolicznościach, ale wprowadza to kolejny poziom niezręczności. Nie zawsze istnieje łatwa alternatywa.
Wyniki na stronach
Korzystanie ze stronicowanych wyników to dobry sposób, aby nie przytłaczać użytkownika zbyt dużą ilością informacji naraz. To także dobry sposób, aby nie przeciążać serwerów baz danych… zwykle.
Rozważ ten projekt:

Dane w tym przykładzie wymagają zliczenia i przetworzenia całego zestawu danych w celu zgłoszenia liczby wyników. Zapytanie dla tego przykładu może mieć następującą składnię:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Jest to wygodna składnia, a zapytanie generuje tylko 25 wierszy. Ale tylko dlatego, że zestaw wyników jest mały, niekoniecznie oznacza to, że jest tani. Tak jak widzieliśmy we wzorcu Sort-By-Column, operator TOP jest tani tylko wtedy, gdy nie musi najpierw sortować dużej ilości danych.
Asynchroniczne żądania stron
Gdy użytkownik przechodzi z jednej strony wyników do następnej, powiązane żądania internetowe mogą być oddzielone sekundami lub minutami. Prowadzi to do problemów, które przypominają pułapki, które można zobaczyć podczas korzystania z NOLOCK. Na przykład:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Gdy wiersz zostanie dodany między dwoma żądaniami, użytkownik może zobaczyć ten sam wiersz dwukrotnie. A jeśli wiersz zostanie usunięty, użytkownik może go pominąć podczas poruszania się po stronach. Ten wzorzec Paged-Results jest odpowiednikiem „Daj mi wiersze 26-50”. Kiedy prawdziwe pytanie powinno brzmieć „Daj mi następne 25 rzędów”. Różnica jest subtelna.
Lepsze wzorce
W przypadku Paged-Results, „OFFSET @N ROWS” może trwać coraz dłużej wraz ze wzrostem @N. Zamiast tego rozważ przyciski Load-More lub Infinite-Scrolling. Dzięki stronicowaniu Load-More istnieje przynajmniej szansa na efektywne wykorzystanie indeksu. Zapytanie wyglądałoby mniej więcej tak:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Nadal boryka się z pewnymi pułapkami asynchronicznych żądań stron, ale z powodu zakładki użytkownik będzie mógł kontynuować od miejsca, w którym przerwał.
Wyszukiwanie tekstu do podciągu
Wyszukiwanie jest wszędzie w Internecie. Ale jakie rozwiązanie zastosować na zapleczu? Chcę ostrzec przed wyszukiwaniem podciągu za pomocą filtra LIKE SQL Server z symbolami wieloznacznymi takimi jak:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Może to prowadzić do takich dziwnych wyników:
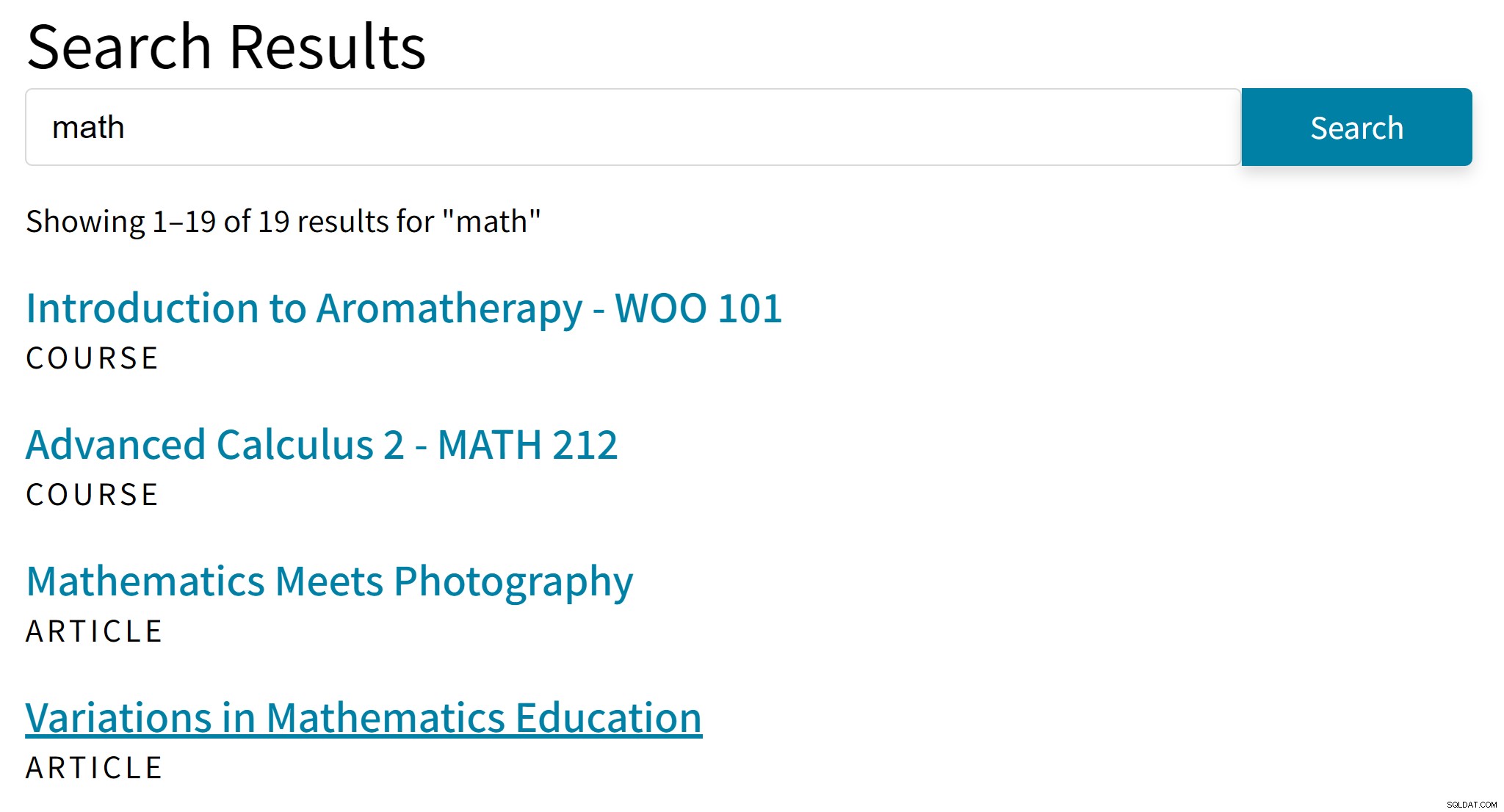
„Aromaterapia” prawdopodobnie nie jest dobrym hitem dla wyszukiwanego hasła „matematyka”. Tymczasem w wynikach wyszukiwania brakuje artykułów, które wspominają tylko o algebrze lub trygonometrii.
Efektywne korzystanie z SQL Server może być również bardzo trudne. Nie ma prostego indeksu obsługującego tego rodzaju wyszukiwanie. Paul White podał jedno trudne rozwiązanie z Trigram Wildcard String Search w SQL Server. Istnieją również trudności, które mogą wystąpić w przypadku sortowania i Unicode. Może stać się drogim rozwiązaniem dla niezbyt dobrego doświadczenia użytkownika.
Czego używać zamiast tego
Wygląda na to, że wyszukiwanie pełnotekstowe SQL Server mogłoby pomóc, ale osobiście nigdy z niego nie korzystałem. W praktyce widziałem sukces tylko w rozwiązaniach poza SQL Server (np. Elasticsearch).
Wniosek
Z mojego doświadczenia odkryłem, że projektanci oprogramowania są często bardzo otwarci na opinie, że ich projekty mogą być czasami niewygodne do wdrożenia. Kiedy tak nie jest, uznałem, że warto podkreślić pułapki, koszty i czas dostawy. Tego rodzaju informacje zwrotne są niezbędne, aby pomóc w tworzeniu możliwych do utrzymania, skalowalnych rozwiązań.
O autorze
 Michael J Swart jest pasjonatem baz danych i blogerem, który koncentruje się na tworzeniu baz danych i architekturze oprogramowania. Lubi mówić o wszystkim, co dotyczy danych, przyczyniając się do projektów społecznościowych. Michael pisze bloga jako „Zaklinacz bazy danych” na michaeljswart.com.
Michael J Swart jest pasjonatem baz danych i blogerem, który koncentruje się na tworzeniu baz danych i architekturze oprogramowania. Lubi mówić o wszystkim, co dotyczy danych, przyczyniając się do projektów społecznościowych. Michael pisze bloga jako „Zaklinacz bazy danych” na michaeljswart.com.