W zeszłym miesiącu omówiłem zagadkę Petera Larssona dotyczącą dopasowania podaży do popytu. Pokazałem proste rozwiązanie Petera oparte na kursorze i wyjaśniłem, że ma skalowanie liniowe. Wyzwanie, z którym ci zostawiłem, to próba wymyślenia rozwiązania zadania opartego na zestawie, i chłopcze, niech ludzie sprostają wyzwaniu! Dziękuję Luce, Kamilowi Kosno, Danielowi Brownowi, Brianowi Walkerowi, Joe Obbishowi, Rainerowi Hoffmannowi, Paulowi White'owi, Charliemu i oczywiście Peterowi Larssonowi za przesłanie swoich rozwiązań. Niektóre pomysły były genialne i wręcz oszałamiające.
W tym miesiącu zacznę badać przesłane rozwiązania, przechodząc z grubsza od tych o gorszej skuteczności do tych, które działają najlepiej. Po co w ogóle zawracać sobie głowę tymi o słabych wynikach? Ponieważ wciąż możesz się od nich wiele nauczyć; na przykład poprzez identyfikację antywzorców. Rzeczywiście, pierwsza próba rozwiązania tego wyzwania dla wielu osób, w tym dla mnie i Piotra, opiera się na koncepcji przecięcia interwałów. Zdarza się, że klasyczna, oparta na predykatach technika identyfikacji przecięcia interwałów ma słabą wydajność, ponieważ nie ma dobrego schematu indeksowania, który by ją obsługiwał. Ten artykuł jest poświęcony temu podejściu o niskiej wydajności. Mimo słabej wydajności praca nad rozwiązaniem jest ciekawym ćwiczeniem. Wymaga wyćwiczenia umiejętności modelowania problemu w sposób umożliwiający leczenie na podstawie zestawu. Interesujące jest również zidentyfikowanie przyczyny złej wydajności, co ułatwi uniknięcie antywzorca w przyszłości. Pamiętaj, że to rozwiązanie jest tylko punktem wyjścia.
DDL i mały zestaw przykładowych danych
Przypominamy, że zadanie polega na przeszukiwaniu tabeli o nazwie „Aukcje”. Użyj poniższego kodu, aby utworzyć tabelę i wypełnić ją małym zestawem przykładowych danych:
DROP TABLE IF EXISTS dbo.Auctions; CREATE TABLE dbo.Auctions( ID INT NOT NULL IDENTITY(1, 1) CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED, Kod CHAR(1) NOT NULL CONSTRAINT ck_Auctions_Code CHECK (Kod ='D' OR Kod ='S'), Ilość DECIMAL(19 , 6) OGRANICZENIE NIEZEROWE ck_Auctions_Quantity CHECK (Ilość> 0)); WŁĄCZ NR; USUŃ Z dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; WSTAW W dbo.Auctions(ID, Kod, Ilość) WARTOŚCI (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, „S”, 2.0), (4000, „S”, 2.0), (5000, „S”, 4.0), (6000, „S”, 3.0), (7000, „S”, 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Twoim zadaniem było stworzenie par, które dopasowują podaż do wpisów popytu na podstawie kolejności identyfikatorów, zapisując je do tabeli tymczasowej. Poniżej znajduje się pożądany wynik dla małego zestawu przykładowych danych:
DemandID SupplyID TradeQuantity----------- ----------- --------------1 1000 5.0000002 1000 3.0000003 2000 6.0000003 3000 2.0000005 4000 2.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.000000
W zeszłym miesiącu udostępniłem również kod, za pomocą którego można wypełnić tabelę Aukcje dużym zestawem przykładowych danych, kontrolując liczbę wpisów podaży i popytu, a także ich zakres ilościowy. Upewnij się, że używasz kodu z artykułu z zeszłego miesiąca, aby sprawdzić wydajność rozwiązań.
Modelowanie danych jako interwałów
Jednym z intrygujących pomysłów, które nadają się do obsługi rozwiązań opartych na zbiorach, jest modelowanie danych jako przedziałów. Innymi słowy, reprezentuj każdy wpis popytu i podaży jako przedział, zaczynając od bieżących całkowitych ilości tego samego rodzaju (popyt lub podaż) aż do, ale z wyłączeniem prądu, i kończąc na sumie bieżącej zawierającej prąd, oczywiście w oparciu o ID zamawianie. Na przykład, patrząc na mały zestaw danych próbki, pierwszy wpis zapotrzebowania (ID 1) dotyczy ilości 5,0, a drugi (ID 2) ilości 3,0. Pierwszy wpis zapotrzebowania może być reprezentowany przez początek przedziału:0.0, koniec:5.0, a drugi z przedziałem początek:5.0, koniec:8.0 itd.
Podobnie pierwszy wpis podaży (ID 1000) dotyczy ilości 8,0, a drugi (ID 2000) dotyczy ilości 6,0. Pierwszy wpis podaży może być reprezentowany przez początek przedziału:0.0, koniec:8.0, a drugi przez początek przedziału:8.0, koniec:14.0 itd.
Pary popyt-podaż, które musisz utworzyć, to nakładające się segmenty przecinających się odstępów między tymi dwoma rodzajami.
Jest to prawdopodobnie najlepiej zrozumiane dzięki wizualnemu przedstawieniu modelowania danych w oparciu o przedziały i pożądanego wyniku, jak pokazano na rysunku 1.
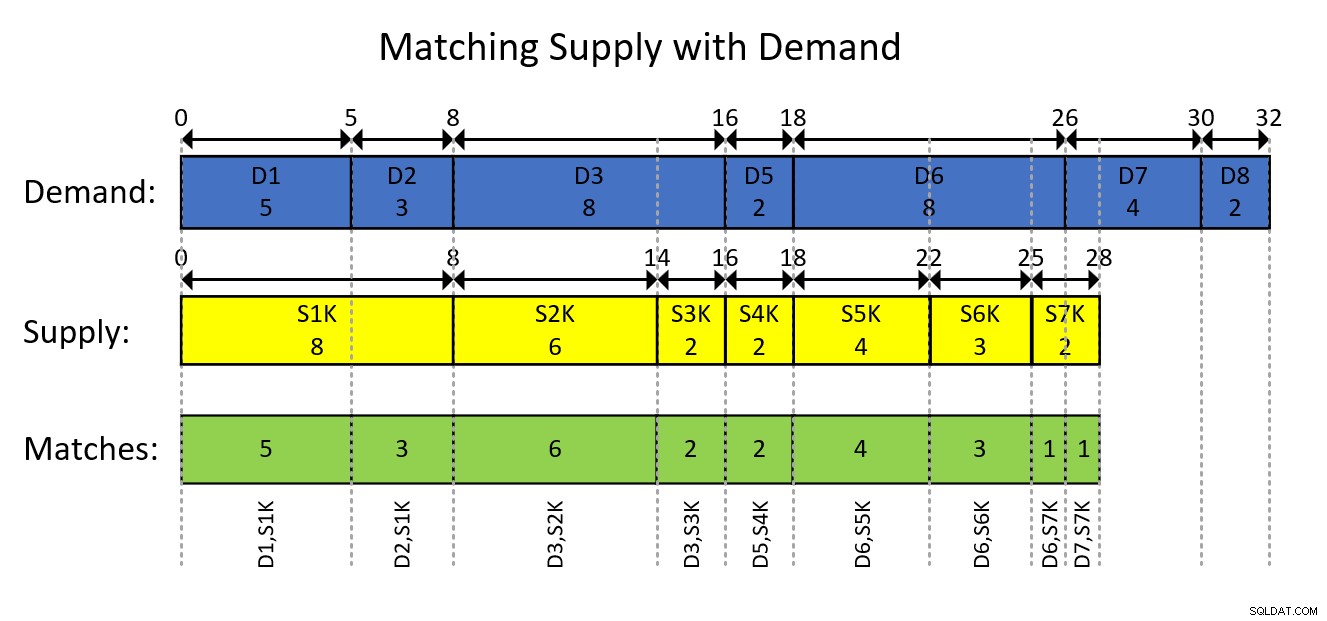 Rysunek 1:Modelowanie danych w odstępach
Rysunek 1:Modelowanie danych w odstępach
Wizualny obraz na rysunku 1 jest dość oczywisty, ale w skrócie…
Niebieskie prostokąty reprezentują wpisy popytu jako przedziały, pokazując wyłączną bieżącą ilość całkowitą jako początek przedziału i łączną bieżącą sumę jako koniec przedziału. Żółte prostokąty robią to samo dla wpisów zaopatrzenia. Następnie zauważ, jak nakładające się na siebie segmenty przecinających się przedziałów tych dwóch rodzajów, które są przedstawione za pomocą zielonych prostokątów, są parami popytu i podaży, które musisz utworzyć. Na przykład pierwsze sparowanie wyników to popyt ID 1, podaż ID 1000, ilość 5. Drugie sparowanie wyników to popyt ID 2, podaż ID 1000, ilość 3. I tak dalej.
Przecięcia interwałów przy użyciu CTE
Zanim zaczniesz pisać kod T-SQL z rozwiązaniami opartymi na idei modelowania interwałowego, powinieneś już intuicyjnie wyczuć, jakie indeksy mogą się tu przydać. Ponieważ prawdopodobnie będziesz używać funkcji okna do obliczania sum bieżących, możesz skorzystać z indeksu obejmującego z kluczem opartym na kolumnach Kod, ID i uwzględnieniu kolumny Quantity. Oto kod do utworzenia takiego indeksu:
UTWÓRZ UNIKALNY INDEKS BEZKLASTOWY idx_Code_ID_i_Quantity NA dbo.Auctions(Code, ID) INCLUDE(Ilość);
To ten sam indeks, który poleciłem dla rozwiązania opartego na kursorach, które omówiłem w zeszłym miesiącu.
Ponadto istnieje możliwość skorzystania z przetwarzania wsadowego. Możesz włączyć jego uwzględnienie bez wymagań trybu wsadowego w sklepie wierszy, np. przy użyciu SQL Server 2019 Enterprise lub nowszego, tworząc następujący fikcyjny indeks magazynu kolumn:
UTWÓRZ INDEKS KOLUMNÓW NIESKLASTOWANYCH idx_cs ON dbo.Auctions(ID) WHERE ID =-1 AND ID =-2;
Możesz teraz rozpocząć pracę nad kodem T-SQL rozwiązania.
Poniższy kod tworzy przedziały reprezentujące wpisy zapotrzebowania:
Z D0 AS-- D0 oblicza bieżące zapotrzebowanie jako EndDemand( SELECT ID, Quantity, SUM(Ilość) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand FROM dbo.Auctions WHERE Code ='D'),-- D wyodrębnia prev EndDemand jako StartDemand, wyrażając zapotrzebowanie start-end jako interwałD AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FROM D0)SELECT *FROM D;
Zapytanie definiujące CTE D0 filtruje wpisy popytu z tabeli Aukcje i oblicza bieżącą ilość całkowitą jako ogranicznik końcowy interwałów popytu. Następnie zapytanie definiujące drugi CTE o nazwie D, pyta D0 i oblicza ogranicznik początkowy interwałów zapotrzebowania, odejmując bieżącą ilość od ogranicznika końcowego.
Ten kod generuje następujące dane wyjściowe:
ID Ilość StartDemand EndDemand---- --------- ------------ ----------1 5.000000 0.000000 5.0000002 3.000000 5.000000 8.0000003 8.000000 8.000000 16.0000005 2.000000 16.000000 18.0000006 8.000000 18.000000 26.0000007 4.000000 26.000000 30.0000008 2.000000 30.000000 32.000000
Przedziały dostaw są generowane w bardzo podobny sposób, stosując tę samą logikę do wpisów podaży, używając następującego kodu:
Z S0 AS-- S0 oblicza bieżącą dostawę jako EndSupply( SELECT ID, Quantity, SUM(Ilość) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply FROM dbo.Auctions WHERE Code ='S'),-- S wyodrębnia prev EndSupply jako StartSupply, wyrażając podaż początek-koniec jako interwałS AS( SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply FROM S0)SELECT *FROM S;
Ten kod generuje następujące dane wyjściowe:
ID Ilość StartSupply EndSupply----- --------- ------------ ----------1000 8.000000 0.000000 8.0000002000 6.000000 8.000000 14.0000003000 2.000000 14.000000 16.0000004000 2.000000 16.000000 18.0000005000 4.000000 18.000000 22.0000006000 3.000000 22.000000 25.0000007000 2.000000 25.000000 27.000000
Pozostaje tylko zidentyfikować przecinające się przedziały popytu i podaży z CTE D i S oraz obliczyć nakładające się segmenty tych przecinających się przedziałów. Pamiętaj, że wyniki parowania powinny być zapisane w tabeli tymczasowej. Można to zrobić za pomocą następującego kodu:
-- Usuń tabelę tymczasową, jeśli istnieje DROP TABLE IF EXISTS #MyPairings; Z D0 AS-- D0 oblicza bieżące zapotrzebowanie jako EndDemand( SELECT ID, Quantity, SUM(Quantity) OVER(ORDER BY ID ROWERS UNBOUNDED PRECEDING) AS EndDemand FROM dbo.Auctions WHERE Code ='D'),-- D wyodrębnia prev EndDemand jako StartDemand, wyrażając zapotrzebowanie na początek i koniec jako interwałD AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FROM D0),S0 AS-- S0 oblicza bieżącą podaż jako EndSupply(SELECT ID, Quantity, SUM(Quantity) OVER (ORDER WEDŁUG WIERSZÓW ID BEZ OGRANICZEŃ POSTĘPOWANIE) AS EndSupply FROM dbo.Auctions WHERE Kod ='S'),-- S wyodrębnia prev EndSupply jako StartSupply, wyrażając dostawę początkową-końcową jako interwały AS( SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply FROM S0)-- Zapytanie zewnętrzne identyfikuje transakcje jako nakładające się segmenty przecinających się interwałów-- W przecinających się interwałach popytu i podaży wielkość transakcji wynosi wtedy -- LEAST(EndDemand, EndSupply) - GREATEST(StartDemsnad, StartSupply)SELECT D.ID AS DemandID, S.ID AS SupplyID, CASE WH PL EndDemandStartSupply WTEDY StartDemand W INNY SPOSÓB StartSupply END AS TradeQuantityDO #MyPairingsFROM D WEWNĘTRZNE POŁĄCZENIA D.StartDemand S.; Oprócz kodu, który tworzy przedziały popytu i podaży, który już widzieliście wcześniej, głównym dodatkiem jest tutaj zapytanie zewnętrzne, które identyfikuje przecinające się przedziały między D i S i oblicza nakładające się segmenty. Aby zidentyfikować przecinające się interwały, zewnętrzne zapytanie łączy D i S za pomocą następującego predykatu złączenia: D.StartDemandS.StartSupply To klasyczny predykat do identyfikacji przecięcia interwałów. Jest to również główne źródło słabej wydajności rozwiązania, co wyjaśnię pokrótce.
Zapytanie zewnętrzne oblicza również ilość handlową na liście SELECT jako:
NAJMNIEJ (EndDemand, EndSupply) - NAJWIĘKSZE (StartDemand, StartSupply)Jeśli używasz Azure SQL, możesz użyć tego wyrażenia. Jeśli używasz SQL Server 2019 lub wcześniejszego, możesz użyć następującej logicznie równoważnej alternatywy:
PRZYPADEK KIEDY EndDemandStartSupply WTEDY StartDemand W INNY SPOSÓB StartSupply KONIEC Ponieważ wymagano zapisania wyniku w tabeli tymczasowej, zewnętrzne zapytanie używa instrukcji SELECT INTO, aby to osiągnąć.
Pomysł modelowania danych jako interwałów jest wyraźnie intrygujący i elegancki. Ale co z wydajnością? Niestety to konkretne rozwiązanie ma duży problem związany ze sposobem identyfikacji przecięcia interwałów. Sprawdź plan tego rozwiązania pokazany na rysunku 2.
Rysunek 2:Plan zapytania dla skrzyżowań przy użyciu rozwiązania CTE
Zacznijmy od niedrogich części planu.
Zewnętrzne dane wejściowe sprzężenia zagnieżdżonych pętli obliczają interwały zapotrzebowania. Używa operatora Index Seek do pobierania wpisów zapotrzebowania i operatora Window Aggregate w trybie wsadowym do obliczania ogranicznika końca interwału zapotrzebowania (nazywanego w tym planie Expr1005). Ogranicznikiem początku interwału zapotrzebowania jest wtedy Expr1005 – Ilość (od D).
Na marginesie, użycie jawnego operatora sortowania przed trybem wsadowym operatora Window Aggregate może być tutaj zaskakujące, ponieważ wpisy popytu pobierane z wyszukiwania indeksu są już uporządkowane według identyfikatora, tak jak wymaga tego funkcja okna. Ma to związek z faktem, że obecnie SQL Server nie obsługuje wydajnej kombinacji równoległej operacji indeksowania z zachowaniem kolejności przed równoległym operatorem Window Aggregate w trybie wsadowym. Jeśli wymusisz plan serialu tylko w celach eksperymentalnych, zobaczysz, że operator sortowania znika. SQL Server zdecydował ogólnie, że preferowane jest tutaj użycie paralelizmu, pomimo tego, że skutkowało to dodaniem jawnego sortowania. Ale znowu, ta część planu reprezentuje niewielką część pracy w wielkim schemacie rzeczy.
Podobnie wewnętrzne dane wejściowe sprzężenia zagnieżdżonych pętli rozpoczynają się od obliczenia interwałów dostaw. Co ciekawe, SQL Server zdecydował się na użycie operatorów trybu wiersza do obsługi tej części. Z jednej strony operatory trybu wierszowego używane do obliczania sum bieżących wiążą się z większym obciążeniem niż alternatywa Window Aggregate w trybie wsadowym; z drugiej strony, SQL Server ma wydajną równoległą implementację operacji indeksowania zachowującej kolejność następującej po obliczeniach funkcji okna, unikając jawnego sortowania dla tej części. Ciekawe, że optymalizator wybrał jedną strategię dla interwałów popytu, a drugą dla interwałów podaży. W każdym razie operator Index Seek pobiera wpisy podaży, a kolejna sekwencja operatorów aż do operatora Compute Scalar oblicza ogranicznik końca interwału dostaw (nazywany w tym planie Expr1009). Ogranicznik rozpoczęcia interwału dostaw to wtedy Expr1009 – Ilość (od S).
Pomimo ilości tekstu, którego użyłem do opisania tych dwóch części, naprawdę kosztowna część pracy w planie jest następna.
Następna część musi połączyć przedziały popytu i przedziały podaży za pomocą następującego predykatu:
D.StartDemandS.StartSupply Bez indeksu pomocniczego, przy założeniu interwałów zapotrzebowania DI i interwałów dostaw SI, wymagałoby to przetwarzania wierszy DI * SI. Plan na rysunku 2 powstał po wypełnieniu tabeli Aukcje 400 000 wierszy (200 000 wpisów popytu i 200 000 wpisów podaży). Tak więc bez indeksu pomocniczego plan musiałby przetworzyć 200 000 * 200 000 =40 000 000 000 wierszy. Aby zmniejszyć ten koszt, optymalizator wybrał utworzenie indeksu tymczasowego (patrz operator Index Spool) z ogranicznikiem końca interwału dostaw (Expr1009) jako kluczem. To prawie najlepsze, co mogło zrobić. Rozwiązuje to jednak tylko część problemu. W przypadku dwóch predykatów zakresu tylko jeden może być obsługiwany przez predykat wyszukiwania indeksu. Drugi musi być obsługiwany za pomocą predykatu rezydualnego. Rzeczywiście, w planie widać, że wyszukiwanie w indeksie tymczasowym używa predykatu wyszukiwania Expr1009> Expr1005 – D.Quantity, a następnie operatora filtra obsługującego predykat rezydualny Expr1005> Expr1009 – S.Quantity.
Zakładając średnio, predykat seek izoluje połowę wierszy podaży z indeksu na wiersz popytu, całkowita liczba wierszy wyemitowanych z operatora Index Spool i przetworzonych przez operator Filter wynosi wtedy DI*SI/2. W naszym przypadku 200 000 wierszy popytu i 200 000 wierszy podaży, co przekłada się na 20 000 000 000. Rzeczywiście, wiersz przechodzący od operatora Index Spool do operatora Filter zgłasza liczbę wierszy zbliżoną do tego.
Ten plan ma skalowanie kwadratowe w porównaniu do skalowania liniowego rozwiązania opartego na kursorze z zeszłego miesiąca. Możesz zobaczyć wynik testu wydajności porównującego dwa rozwiązania na rysunku 3. Możesz wyraźnie zobaczyć ładnie ukształtowaną parabolę dla rozwiązania opartego na zestawie.
Rysunek 3:Wydajność skrzyżowań przy użyciu rozwiązania CTE w porównaniu z rozwiązaniem opartym na kursorze
Przecięcia przedziałów przy użyciu tabel tymczasowych
Możesz nieco poprawić sytuację, zastępując użycie CTE dla interwałów popytu i podaży tabelami tymczasowymi i aby uniknąć buforowania indeksu, tworząc własny indeks na tabeli tymczasowej, przechowującej interwały podaży z ogranicznikiem końcowym jako kluczem. Oto kompletny kod rozwiązania:
-- Usuń tabele tymczasowe, jeśli istnieje DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply; Z D0 AS-- D0 oblicza bieżące zapotrzebowanie jako EndDemand( SELECT ID, Quantity, SUM(Quantity) OVER(ORDER BY ID ROWERS UNBOUNDED PRECEDING) AS EndDemand FROM dbo.Auctions WHERE Code ='D'),-- D wyodrębnia prev EndDemand jako StartDemand, wyrażając zapotrzebowanie na początek i koniec jako interwałD AS( SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand FROM D0)SELECT ID, Quantity, CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand, CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemandINTO #DemandFROM D;with S0 AS-- S0 oblicza bieżącą podaż jako EndSupply( SELECT ID, Quantity, SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply FROM dbo.Auctions WHERE Kod ='S'),-- S wyodrębnia prev EndSupply jako StartSupply, wyrażając dostawę na początku-końcu jako interwały AS( SELECT ID, Quantity, EndSupply - Quantity AS StartSupply F, EndSupply S0) SELECT ID, Ilość, CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply, CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6) AS EndSupplyINTO #SupplyFROM S; UTWÓRZ UNIKALNY KLASTROWANY INDEKS idx_cl_ES_ID NA #Supply(EndSupply, ID); -- Zewnętrzne zapytanie identyfikuje transakcje jako nakładające się segmenty przecinających się interwałów -- W przecinających się interwałach popytu i podaży wielkość transakcji wynosi wtedy -- LEAST(EndDemand, EndSupply) - GREATEST(StartDemsnad, StartSupply)SELECT D.ID AS DemandID, S.ID AS SupplyID, CASE WEN EndDemandStartSupply THE StartDemand ELSE StartSupply END AS TradeQuantityINTO #MyPairingsFROM #Demand AS D INNER JOIN #Supply ASEK S.StartSupply; Plany tego rozwiązania pokazano na rysunku 4:
Rysunek 4:Plan zapytania dla skrzyżowań przy użyciu rozwiązania z tabelami temp.
Pierwsze dwa plany wykorzystują kombinację operatorów wyszukiwania indeksu + sortowania + agregacji okien w trybie wsadowym do obliczania interwałów podaży i popytu i zapisywania ich w tabelach tymczasowych. Trzeci plan obsługuje tworzenie indeksu w tabeli #Supply z ogranicznikiem EndSupply jako kluczem wiodącym.
Czwarty plan reprezentuje zdecydowanie większość pracy, z operatorem łączenia zagnieżdżonych pętli, który pasuje do każdego interwału z #Demand, przecinających się interwałów z #Supply. Zauważ, że również tutaj operator Index Seek opiera się na predykacie #Supply.EndSupply> #Demand.StartDemand jako predykacie wyszukiwania i #Demand.EndDemand> #Supply.StartSupply jako predykacie rezydualnym. Tak więc pod względem złożoności/skalowania otrzymujesz taką samą złożoność kwadratową, jak w poprzednim rozwiązaniu. Po prostu płacisz mniej za wiersz, ponieważ używasz własnego indeksu zamiast buforu indeksu używanego w poprzednim planie. Możesz zobaczyć wydajność tego rozwiązania w porównaniu z poprzednimi dwoma na rysunku 5.
Rysunek 5:Wydajność skrzyżowań przy użyciu tabel tymczasowych w porównaniu z innymi dwoma rozwiązaniami
Jak widać, rozwiązanie z tabelami tymczasowymi działa lepiej niż to z CTE, ale nadal ma skalowanie kwadratowe i bardzo źle wypada w porównaniu z kursorem.
Co dalej?
Artykuł dotyczył pierwszej próby obsługi klasycznego zadania dopasowania podaży do popytu przy użyciu rozwiązania opartego na zbiorach. Pomysł polegał na modelowaniu danych jako interwałach, dopasowaniu podaży do wpisów popytu poprzez identyfikację przecinających się interwałów podaży i popytu, a następnie obliczenie wielkości obrotu na podstawie rozmiaru nakładających się segmentów. Z pewnością intrygujący pomysł. Głównym problemem z tym jest również klasyczny problem identyfikacji przecięcia interwałów za pomocą dwóch predykatów zakresu. Nawet przy najlepszym indeksie możesz obsługiwać tylko jeden predykat zakresu za pomocą wyszukiwania indeksu; drugi predykat zakresu musi być obsługiwany przy użyciu predykatu rezydualnego. Daje to plan o kwadratowej złożoności.
Co więc możesz zrobić, aby pokonać tę przeszkodę? Istnieje kilka różnych pomysłów. Jeden genialny pomysł należy do Joe Obbish, o którym możesz przeczytać szczegółowo w jego wpisie na blogu. Inne pomysły omówię w nadchodzących artykułach z tej serii.
[ Skocz do:Oryginalne wyzwanie | Rozwiązania:Część 1 | Część 2 | Część 3 ]