W Stack Overflow mamy kilka tabel korzystających z klastrowych indeksów magazynu kolumn, które działają świetnie w przypadku większości naszego obciążenia. Ale ostatnio natknęliśmy się na sytuację, w której „perfekcyjne burze” — wiele procesów, które próbują usunąć z tego samego CCI — przeciążyłyby procesor, ponieważ wszystkie działały równolegle i walczyły o dokończenie operacji. Oto jak to wyglądało w SolarWinds SQL Sentry:
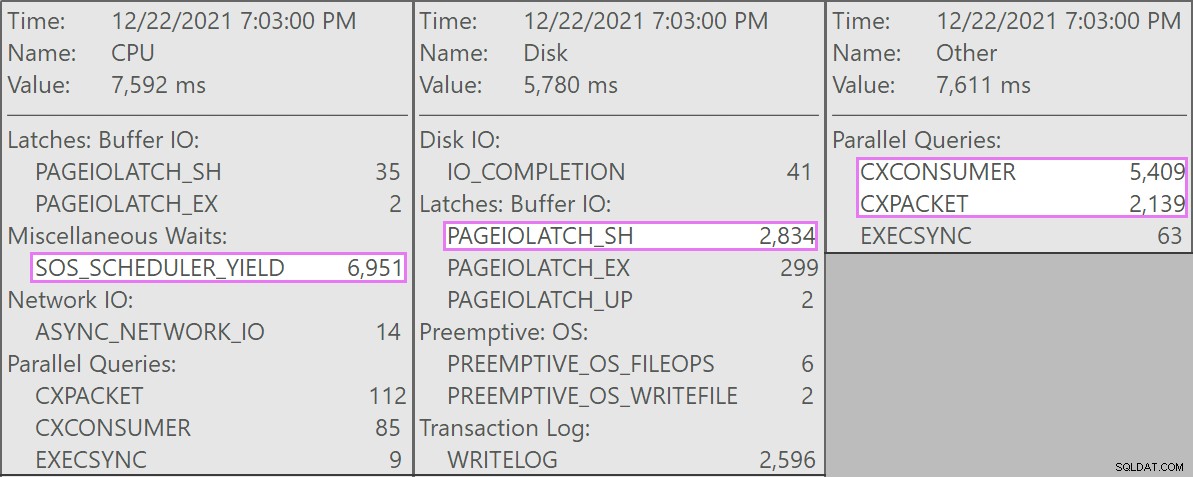
A oto interesujące oczekiwania związane z tymi zapytaniami:
Wszystkie konkurujące zapytania miały następującą formę:
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
Plan wyglądał tak:

A ostrzeżenie na skanie poinformowało nas o dość ekstremalnych szczątkowych I/O:

Tabela ma 1,9 miliarda wierszy, ale ma tylko 32 GB (dziękujemy, pamięć kolumnowa!). Mimo to każde usuwanie pojedynczych wierszy zajęłoby od 10 do 15 sekund, przy czym większość tego czasu poświęcono na SOS_SCHEDULER_YIELD .
Na szczęście, ponieważ w tym scenariuszu operacja usuwania może być asynchroniczna, byliśmy w stanie rozwiązać problem za pomocą dwóch zmian (choć tutaj rażąco upraszczam):
- Ograniczyliśmy
MAXDOPna poziomie bazy danych, więc te usunięcia nie mogą przebiegać tak równolegle - Poprawiliśmy serializację procesów pochodzących z aplikacji (w zasadzie kolejkowaliśmy usunięcia przez jednego dyspozytora)
Jako DBA możemy łatwo kontrolować MAXDOP , chyba że zostanie zastąpione na poziomie zapytania (kolejna królicza nora na kolejny dzień). Niekoniecznie możemy kontrolować aplikację w takim zakresie, zwłaszcza jeśli jest ona dystrybuowana lub nie nasza. Jak możemy serializować zapisy w tym przypadku bez drastycznej zmiany logiki aplikacji?
Próbna konfiguracja
Nie zamierzam tworzyć lokalnie dwumiliardowej tabeli — nie mówiąc już o dokładnej tabeli — ale możemy przybliżyć coś na mniejszą skalę i spróbować odtworzyć ten sam problem.
Załóżmy, że to jest SuggestedEdits stół (w rzeczywistości tak nie jest). Ale jest to łatwy przykład do użycia, ponieważ możemy pobrać schemat z Eksploratora danych Stack Exchange. Używając tego jako podstawy, możemy utworzyć równoważną tabelę (z kilkoma drobnymi zmianami, aby ułatwić wypełnianie) i rzucić na nią klastrowany indeks magazynu kolumn:
CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
Aby wypełnić go 100 milionami wierszy, możemy skrzyżować złącze sys.all_objects i sys.all_columns pięć razy (w moim systemie za każdym razem wygeneruje to 2,68 miliona wierszy, ale YMMV):
-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5
Następnie możemy sprawdzić spację:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
To tylko 1,3 GB, ale to powinno wystarczyć:

Naśladowanie usuwania naszego klastrowanego magazynu kolumn
Oto proste zapytanie z grubsza pasujące do tego, co nasza aplikacja robi z tabelą:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
Plan nie jest jednak idealnie dopasowany:
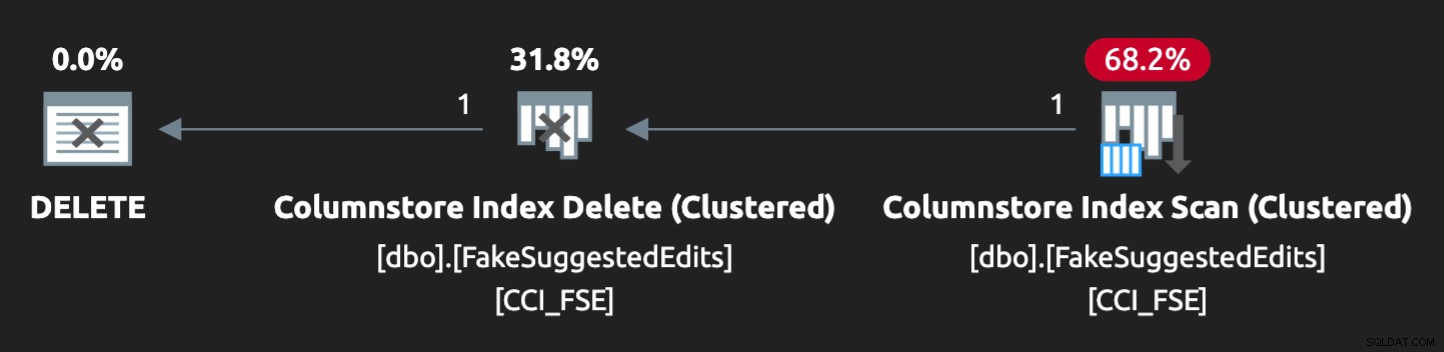
Aby zmusić go do równoległego działania i wygenerowania podobnej rywalizacji na moim skromnym laptopie, musiałem trochę zmusić optymalizator do tej wskazówki:
OPTION (QUERYTRACEON 8649);
Teraz wygląda dobrze:

Odtworzenie problemu
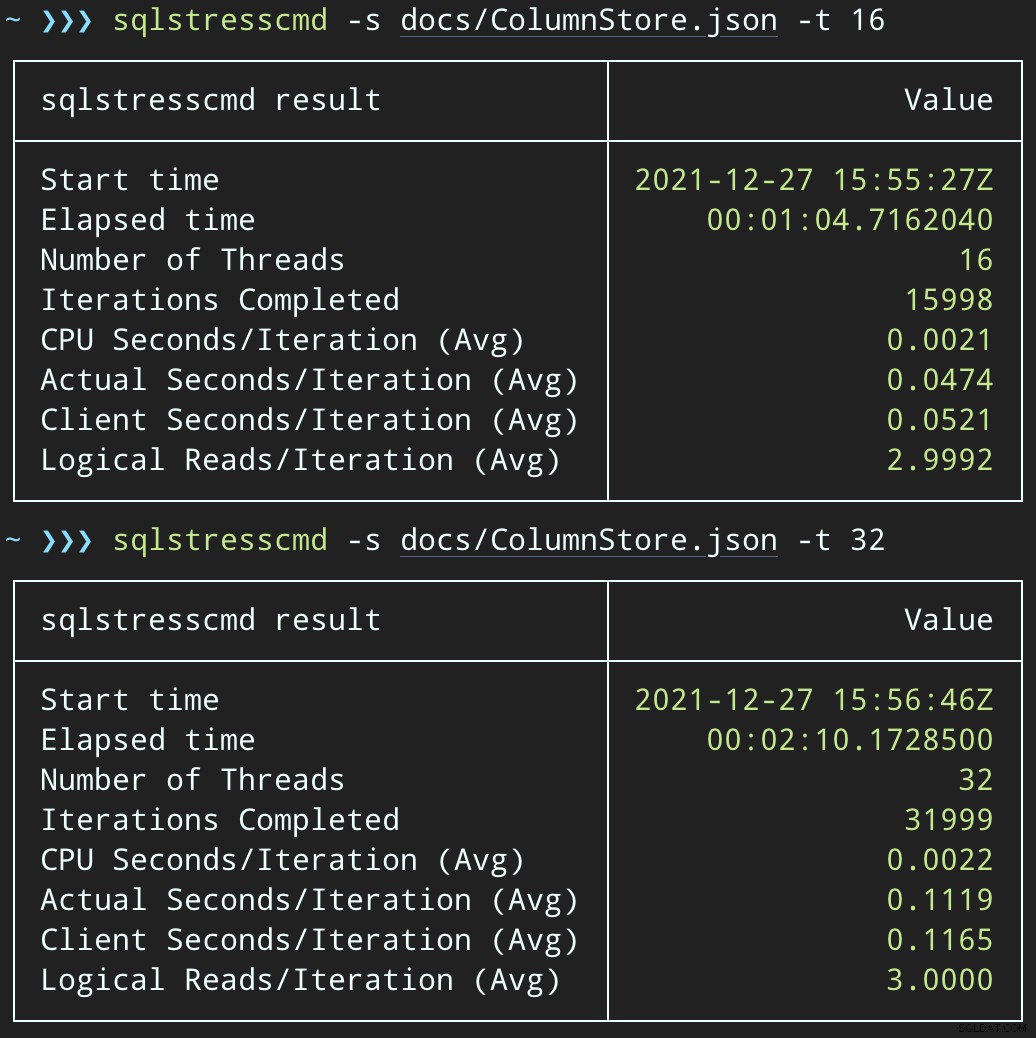
Następnie możemy stworzyć gwałtowny wzrost jednoczesnej aktywności usuwania za pomocą SqlStressCmd, aby usunąć 1000 losowych wierszy przy użyciu 16 i 32 wątków:
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
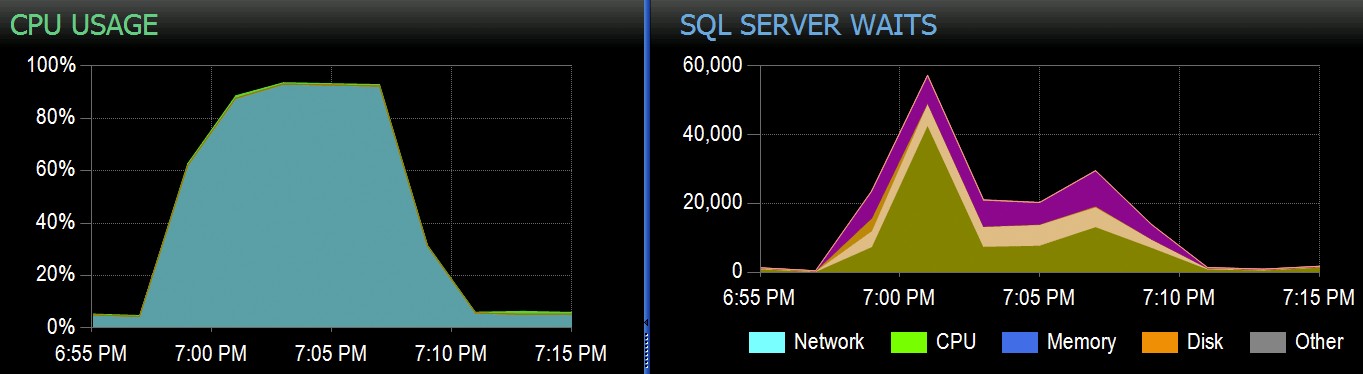
Możemy zaobserwować obciążenie procesora:
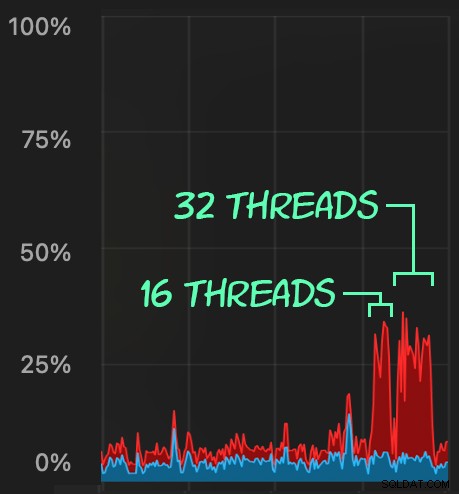
Obciążenie procesora trwa odpowiednio przez około 64 i 130 sekund:
Uwaga:dane wyjściowe z SQLQueryStress są czasami nieco nieaktualne w iteracjach, ale potwierdziłem, że praca, o którą prosisz, została wykonana precyzyjnie.
Potencjalne obejście:kolejka usuwania
Początkowo myślałem o wprowadzeniu do bazy danych tabeli kolejek, której moglibyśmy użyć do odciążenia czynności usuwania:
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
Wszystko, czego potrzebujemy, to wyzwalacz INSTEAD OF, aby przechwycić te nieuczciwe usunięcia pochodzące z aplikacji i umieścić je w kolejce do przetwarzania w tle. Niestety, nie można utworzyć wyzwalacza w tabeli z klastrowanym indeksem magazynu kolumn:
Komunikat 35358, poziom 16, stan 1CREATE TRIGGER w tabeli „dbo.FakeSuggestedEdits” nie powiódł się, ponieważ nie można utworzyć wyzwalacza w tabeli z klastrowanym indeksem magazynu kolumn. Rozważ wymuszenie logiki wyzwalacza w inny sposób lub jeśli musisz użyć wyzwalacza, zamiast tego użyj stosu lub indeksu B-drzewa.
Będziemy potrzebować minimalnej zmiany w kodzie aplikacji, tak aby wywołała ona procedurę składowaną do obsługi usuwania:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
To nie jest stan stały; to tylko po to, aby zachować to samo zachowanie, zmieniając tylko jedną rzecz w aplikacji. Po zmianie aplikacji i pomyślnym wywołaniu tej procedury składowanej zamiast wysyłania zapytań usuwania ad hoc, procedura składowana może ulec zmianie:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; END
Testowanie wpływu kolejki
Teraz, jeśli zmienimy SqlQueryStress na wywołanie procedury składowanej:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
I prześlij podobne partie (umieszczając 16 tys. lub 32 tys. wierszy w kolejce):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
Wpływ procesora jest nieco wyższy:
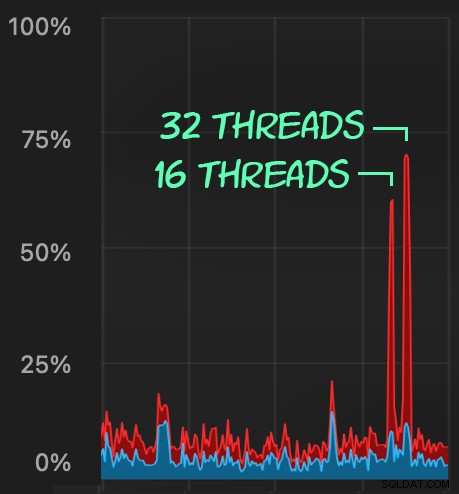
Jednak zadania kończą się znacznie szybciej — odpowiednio 16 i 23 sekundy:
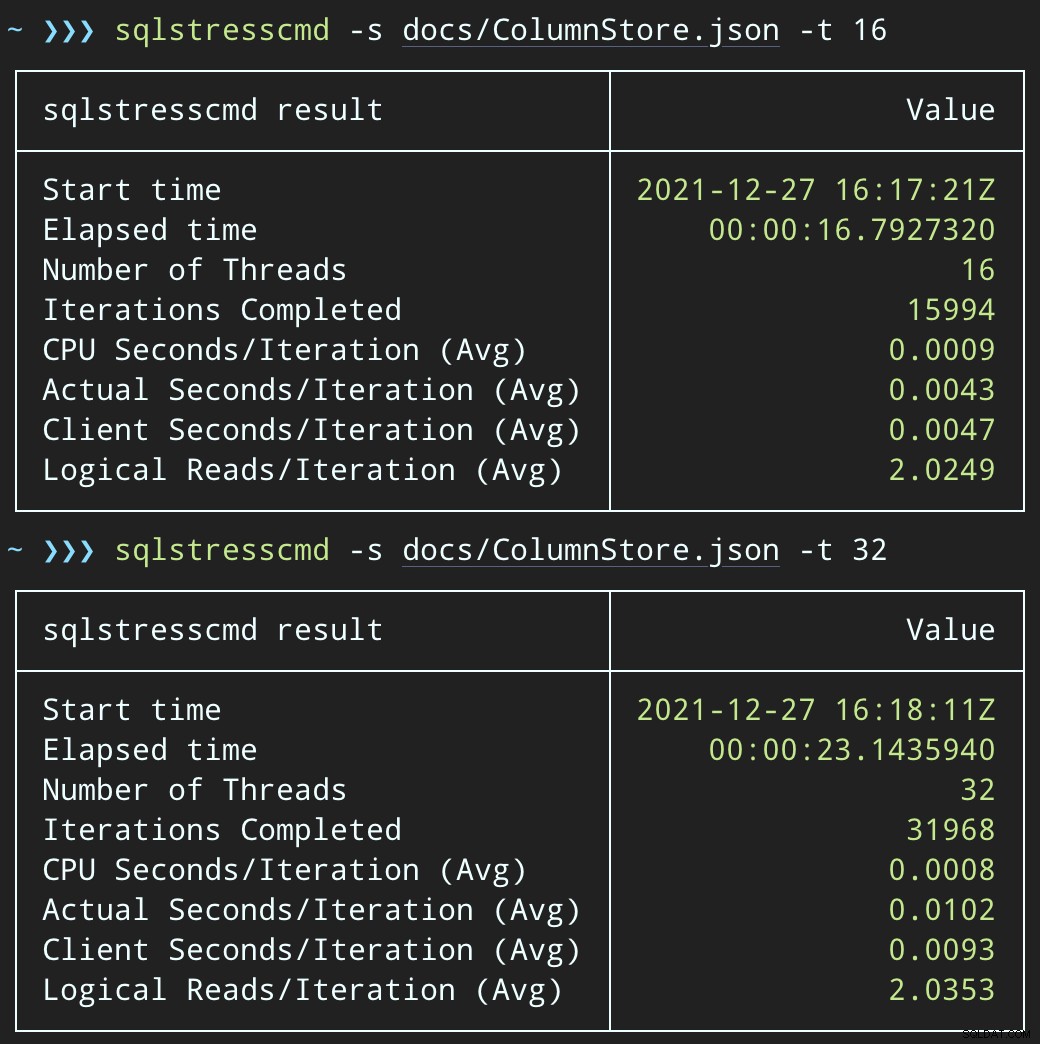
Jest to znaczne zmniejszenie bólu odczuwanego przez aplikacje, gdy wchodzą w okresy wysokiej współbieżności.
Nadal musimy wykonać usuwanie, chociaż
Nadal musimy przetwarzać te usunięcia w tle, ale teraz możemy wprowadzić grupowanie i mieć pełną kontrolę nad szybkością i wszelkimi opóźnieniami, które chcemy wprowadzić między operacjami. Oto bardzo podstawowa struktura procedury składowanej do przetwarzania kolejki (co prawda bez pełnej kontroli transakcji, obsługi błędów lub czyszczenia tabeli kolejki):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
END Teraz usuwanie wierszy potrwa dłużej — średnia dla 10 000 wierszy to 223 sekundy, z czego ~100 to celowe opóźnienie. Ale żaden użytkownik nie czeka, więc kogo to obchodzi? Profil procesora jest prawie zerowy, a aplikacja może kontynuować dodawanie elementów w kolejce tak bardzo współbieżnie, jak chce, z prawie zerowym konfliktem z zadaniem w tle. Podczas przetwarzania 10 000 wierszy dodałem kolejne 16 tys. wierszy do kolejki i używało tego samego procesora co poprzednio — trwało to tylko o sekundę dłużej niż wtedy, gdy zadanie nie było uruchomione:
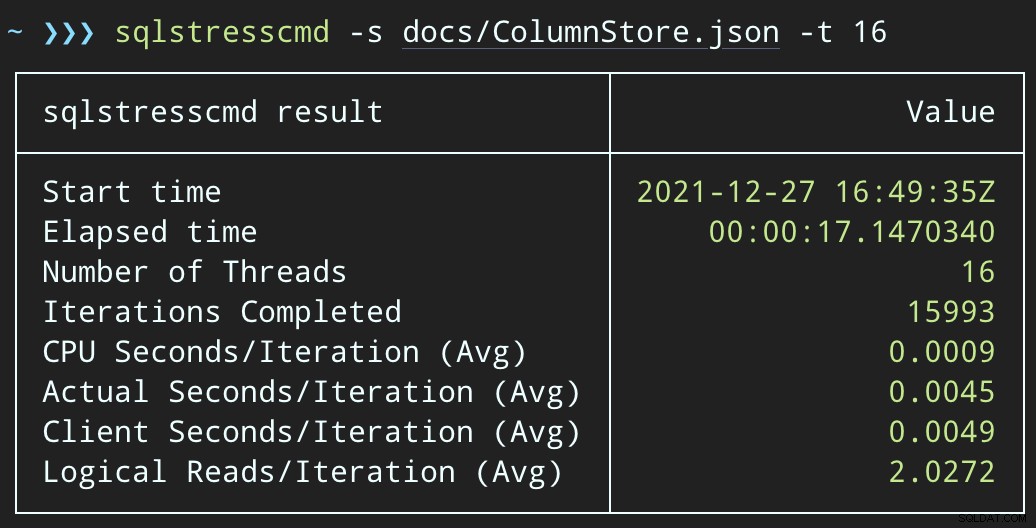
Plan wygląda teraz tak, ze znacznie lepszymi szacunkowymi/rzeczywistymi wierszami:
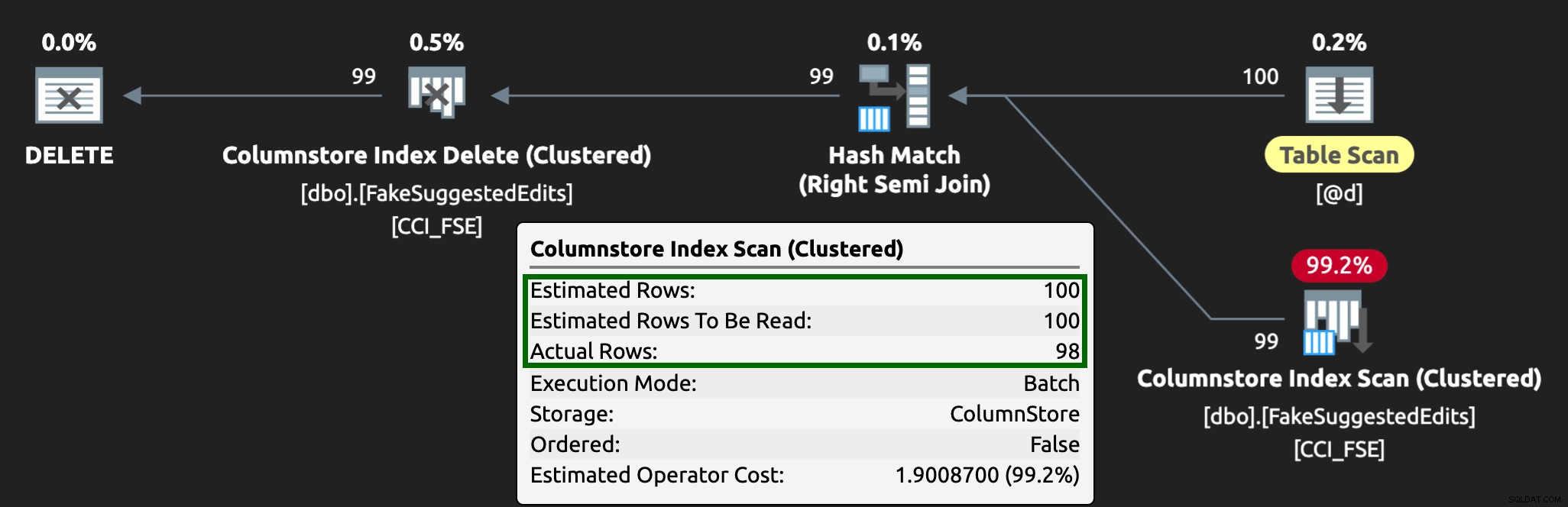
Widzę, że takie podejście do tabeli kolejek jest skutecznym sposobem radzenia sobie z wysoką współbieżnością DML, ale wymaga przynajmniej odrobiny elastyczności w przypadku aplikacji przesyłających DML — jest to jeden z powodów, dla których naprawdę lubię, gdy aplikacje wywołują procedury składowane, ponieważ daj nam znacznie większą kontrolę bliżej danych.
Inne opcje
Jeśli nie masz możliwości zmiany zapytań dotyczących usuwania pochodzących z aplikacji — lub jeśli nie możesz odroczyć usuwania do procesu w tle — możesz rozważyć inne opcje, aby zmniejszyć wpływ usuwania:
- Indeks nieklastrowy w kolumnach predykatów do obsługi wyszukiwania punktów (możemy to zrobić w izolacji bez zmiany aplikacji)
- Korzystanie tylko z miękkiego usuwania (nadal wymaga zmian w aplikacji)
Ciekawe będzie sprawdzenie, czy te opcje oferują podobne korzyści, ale zachowam je na przyszły wpis.