Podsłuchiwanie parametrów
Parametryzacja zapytań promuje ponowne wykorzystanie buforowanych planów wykonania, unikając w ten sposób niepotrzebnych kompilacji i zmniejszając liczbę zapytań ad hoc w pamięci podręcznej planów.
To wszystko są dobre rzeczy, pod warunkiem parametryzowane zapytanie naprawdę powinno używać tego samego buforowanego planu wykonania dla różnych wartości parametrów. Plan wykonania, który jest wydajny dla jednej wartości parametru, może nie być dobrym wyborem dla innych możliwych wartości parametrów.
Gdy włączone jest podsłuchiwanie parametrów (domyślnie), SQL Server wybiera plan wykonania na podstawie określonych wartości parametrów, które istnieją w czasie kompilacji. Niejawnym założeniem jest to, że sparametryzowane instrukcje są najczęściej wykonywane z najczęstszymi wartościami parametrów. Brzmi to wystarczająco rozsądnie (nawet oczywiste) i rzeczywiście często działa dobrze.
Problem może wystąpić, gdy nastąpi automatyczna ponowna kompilacja buforowanego planu. Ponowna kompilacja może zostać wywołana z różnych powodów, na przykład z powodu porzucenia indeksu używanego przez plan z pamięci podręcznej (poprawność ponownej kompilacji) lub z powodu zmiany informacji statystycznych (optymalność przekompilować).
Bez względu na dokładną przyczynę rekompilacji planu, istnieje szansa, że nietypowy wartość jest przekazywana jako parametr w momencie generowania nowego planu. Może to skutkować nowym planem w pamięci podręcznej (w oparciu o wyszukaną nietypową wartość parametru), który nie jest dobry dla większości wykonań, do których zostanie ponownie użyty.
Nie jest łatwo przewidzieć, kiedy dany plan wykonania zostanie ponownie skompilowany (na przykład dlatego, że statystyki zmieniły się wystarczająco), co powoduje sytuację, w której dobrej jakości plan wielokrotnego użytku może zostać nagle zastąpiony zupełnie innym planem zoptymalizowanym pod kątem nietypowych wartości parametrów.
Jeden z takich scenariuszy ma miejsce, gdy nietypowa wartość jest wysoce selektywna, co skutkuje planem zoptymalizowanym dla małej liczby wierszy. Takie plany często wykorzystują wykonywanie jednowątkowe, łączenie zagnieżdżonych pętli i wyszukiwania. Poważne problemy z wydajnością mogą pojawić się, gdy ten plan zostanie ponownie użyty dla różnych wartości parametrów, które generują znacznie większą liczbę wierszy.
Wyłączanie podsłuchiwania parametrów
Podsłuchiwanie parametrów można wyłączyć za pomocą udokumentowanej flagi śledzenia 4136. Flaga śledzenia jest również obsługiwana dla na zapytanie użyj za pomocą QUERYTRACEON wskazówka zapytania. Oba mają zastosowanie począwszy od SQL Server 2005 Service Pack 4 (i nieco wcześniej, jeśli zastosujesz aktualizacje zbiorcze do Service Pack 3).
Począwszy od SQL Server 2016, podsłuchiwanie parametrów można również wyłączyć na poziomie bazy danych , używając PARAMETER_SNIFFING argument ALTER DATABASE SCOPED CONFIGURATION .
Gdy wąchanie parametrów jest wyłączone, SQL Server używa średniej dystrybucji statystyki, aby wybrać plan wykonania.
Brzmi to również jak rozsądne podejście (i może pomóc uniknąć sytuacji, w której plan jest zoptymalizowany pod kątem niezwykle selektywnej wartości parametru), ale nie jest to również idealna strategia:plan zoptymalizowany pod kątem „średniej” wartości może się okazać poważnie nieoptymalne dla powszechnie spotykanych wartości parametrów.
Rozważ plan wykonania, który zawiera operatory zużywające pamięć, takie jak sortowanie i skróty. Ponieważ pamięć jest zarezerwowana przed rozpoczęciem wykonywania zapytania, sparametryzowany plan oparty na średnich wartościach dystrybucji może rozlać się do tempdb dla wspólnych wartości parametrów, które dają więcej danych niż oczekiwał optymalizator.
Rezerwacje pamięci zwykle nie mogą rosnąć podczas wykonywania zapytania, niezależnie od tego, ile wolnej pamięci może mieć serwer. Niektóre aplikacje czerpią korzyści z wyłączenia podsłuchiwania parametrów (na przykład zobacz ten post w archiwum autorstwa zespołu ds. wydajności Dynamics AX).
W przypadku większości obciążeń całkowite wyłączenie wykrywania parametrów jest niewłaściwym rozwiązaniem , a może nawet katastrofą. Wąchanie parametrów to optymalizacja heurystyczna:przez większość czasu działa lepiej niż używanie średnich wartości w większości systemów.
Wskazówki dotyczące zapytań
SQL Server zapewnia szereg wskazówek dotyczących zapytań i innych opcji umożliwiających dostrojenie zachowania podsłuchu parametrów:
OPTIMIZE FOR (@parameter = value)wskazówka zapytania tworzy plan wielokrotnego użytku na podstawie określonej wartości.OPTIMIZE FOR (@parameter UNKNOWN)używa średnich statystyk rozkładu dla określonego parametru.OPTIMIZE FOR UNKNOWNużywa rozkładu średniego dla wszystkich parametrów (ten sam efekt, co flaga śledzenia 4136).WITH RECOMPILEopcja procedury składowanej kompiluje nowy plan procedury dla każdego wykonania.OPTION (RECOMPILE)wskazówka zapytania kompiluje nowy plan dla indywidualnej instrukcji.
Stara technika „ukrywania parametrów” (przypisywanie parametrów procedury do zmiennych lokalnych i odwoływanie się do zmiennych) ma taki sam efekt, jak określenie OPTIMIZE FOR UNKNOWN . Może być przydatny w instancjach starszych niż SQL Server 2008 (OPTIMIZE FOR wskazówka była nowa na rok 2008).
Można by argumentować, że każda Sparametryzowaną instrukcję należy sprawdzić pod kątem wrażliwości na wartości parametrów i pozostawić w spokoju (jeśli domyślne zachowanie działa dobrze) lub wyraźnie wskazać przy użyciu jednej z powyższych opcji.
W praktyce rzadko się to robi, częściowo dlatego, że wykonanie kompleksowej analizy dla wszystkich możliwych wartości parametrów może być czasochłonne i wymaga dość zaawansowanych umiejętności.
Najczęściej taka analiza nie jest przeprowadzana, a problemy z wrażliwością parametrów są rozwiązywane jako i kiedy występują w produkcji.
Ten brak wcześniejszej analizy jest prawdopodobnie jednym z głównych powodów, dla których wąchanie parametrów ma złą reputację. Opłaca się być świadomym potencjalnych problemów i przeprowadzić przynajmniej szybką analizę instrukcji, które mogą powodować problemy z wydajnością przy ponownej kompilacji z nietypową wartością parametru.
Co to jest parametr?
Niektórzy powiedzieliby, że SELECT instrukcja odwołująca się do zmiennej lokalnej to „sparametryzowana instrukcja” w pewnym sensie, ale to nie jest definicja, której używa SQL Server.
Rozsądną wskazówkę, że instrukcja wykorzystuje parametry, można znaleźć, patrząc na właściwości planu (zobacz Parametry w Eksploratorze planów Sentry One. Lub kliknij węzeł główny planu zapytania w SSMS, otwórz Właściwości i rozwiń Listę parametrów węzeł):
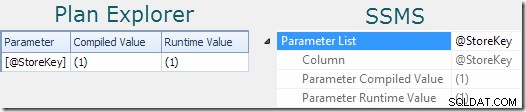
„Skompilowana wartość” pokazuje sniffowaną wartość parametru użytego do kompilacji buforowanego planu. „Wartość czasu działania” pokazuje wartość parametru konkretnego wykonania uchwyconego w planie.
Każda z tych właściwości może być pusta lub może jej brakować w różnych okolicznościach. Jeśli zapytanie nie jest sparametryzowane, po prostu brakuje wszystkich właściwości.
Tylko dlatego, że w SQL Server nic nie jest proste, zdarzają się sytuacje, w których można wypełnić listę parametrów, ale instrukcja nadal nie jest sparametryzowana. Może się to zdarzyć, gdy SQL Server podejmie próbę prostej parametryzacji (omówione później), ale uzna, że próba jest „niebezpieczna”. W takim przypadku znaczniki parametrów będą obecne, ale plan wykonania nie jest w rzeczywistości sparametryzowany.
Podsłuchiwanie nie służy tylko procedurom przechowywanym
Wąchanie parametrów występuje również, gdy partia jest jawnie sparametryzowana do ponownego użycia przy użyciu sp_executesql .
Na przykład:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'K%';
Optymalizator wybiera plan wykonania na podstawie sniffowanej wartości @NameLike parametr. Szacuje się, że wartość parametru „K%” pasuje do bardzo niewielu wierszy w Product tabeli, więc optymalizator wybiera zagnieżdżoną pętlę sprzężenia i strategię wyszukiwania kluczy:
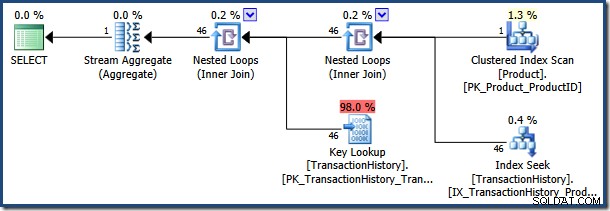

Ponowne wykonanie instrukcji z wartością parametru „[H-R]%” (co będzie pasować do znacznie większej liczby wierszy) powoduje ponowne wykorzystanie buforowanego sparametryzowanego planu:
EXECUTE sys.sp_executesql
N'
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
',
N'@NameLike nvarchar(50)',
@NameLike = N'[H-R]%';
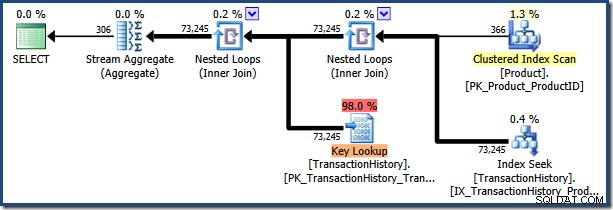

AdventureWorks przykładowa baza danych jest zbyt mała, aby spowodować katastrofę wydajności, ale ten plan z pewnością nie jest optymalny dla wartości drugiego parametru.
Możemy zobaczyć plan, który wybrałby optymalizator, czyszcząc pamięć podręczną planów i ponownie wykonując drugie zapytanie:
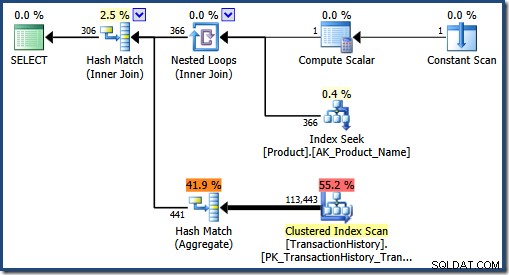

W przypadku oczekiwanej większej liczby dopasowań optymalizator określa, że sprzężenie haszujące i agregacja haszowania są lepszymi strategiami.
Funkcje T-SQL
Wąchanie parametrów występuje również w przypadku funkcji T-SQL, chociaż sposób generowania planów wykonania może utrudnić zauważenie tego.
Istnieją dobre powody, aby ogólnie unikać skalarnych i wieloinstancyjnych funkcji T-SQL, więc tylko do celów edukacyjnych, oto wersja naszego zapytania testowego T-SQL z wieloinstancyjnymi funkcjami z wartościami tabelarycznymi:
CREATE FUNCTION dbo.F
(@NameLike nvarchar(50))
RETURNS @Result TABLE
(
ProductID integer NOT NULL PRIMARY KEY,
Name nvarchar(50) NOT NULL,
TotalQty integer NOT NULL
)
WITH SCHEMABINDING
AS
BEGIN
INSERT @Result
SELECT
P.ProductID,
P.Name,
TotalQty = SUM(TH.Quantity)
FROM Production.Product AS P
JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID
WHERE
P.Name LIKE @NameLike
GROUP BY
P.ProductID,
P.Name;
RETURN;
END; Poniższe zapytanie używa funkcji do wyświetlania informacji o nazwach produktów zaczynających się od „K”:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; Podglądanie parametrów za pomocą wbudowanej funkcji jest trudniejsze, ponieważ SQL Server nie zwraca oddzielnego planu zapytania po wykonaniu (rzeczywistego) dla każdego wywołania funkcji. Funkcja może być wywoływana wiele razy w ramach jednej instrukcji, a użytkownicy nie byliby pod wrażeniem, gdyby SSMS próbował wyświetlić milion planów wywołań funkcji dla pojedynczego zapytania.
W wyniku tej decyzji projektowej rzeczywisty plan zwrócony przez SQL Server dla naszego zapytania testowego nie jest zbyt pomocny:
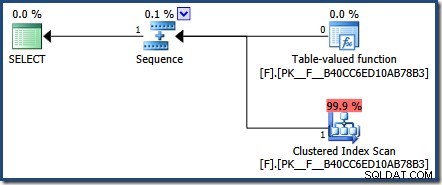
Niemniej jednak są sposoby, aby zobaczyć wąchanie parametrów w akcji z wbudowanymi funkcjami. Metodą, którą wybrałem tutaj, jest sprawdzenie pamięci podręcznej planu:
SELECT
DEQS.plan_generation_num,
DEQS.execution_count,
DEQS.last_logical_reads,
DEQS.last_elapsed_time,
DEQS.last_rows,
DEQP.query_plan
FROM sys.dm_exec_query_stats AS DEQS
CROSS APPLY sys.dm_exec_sql_text(DEQS.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DEQS.plan_handle) AS DEQP
WHERE
DEST.objectid = OBJECT_ID(N'dbo.F', N'TF');
Ten wynik pokazuje, że plan funkcji został wykonany raz, kosztem 201 odczytów logicznych z 2891 mikrosekundami, które upłynęły, a ostatnie wykonanie zwróciło jeden wiersz. Zwrócona reprezentacja planu XML pokazuje, że wartość parametru była powąchał:
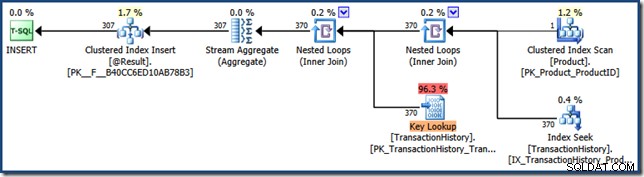

Teraz uruchom instrukcję ponownie, z innym parametrem:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'[H-R]%') AS Result; Z planu powykonawczego wynika, że funkcja zwróciła 306 wierszy:
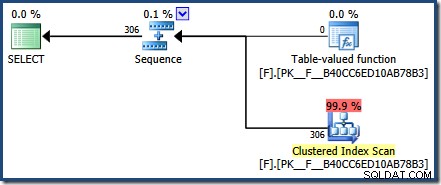
Zapytanie dotyczące pamięci podręcznej planu pokazuje, że buforowany plan wykonania funkcji został ponownie użyty (execution_count =2):

Pokazuje również znacznie większą liczbę odczytów logicznych i dłuższy czas w porównaniu z poprzednim przebiegiem. Jest to zgodne z ponownym użyciem zagnieżdżonych pętli i planu wyszukiwania, ale aby mieć całkowitą pewność, plan funkcji po wykonaniu może zostać przechwycony za pomocą Extended Events lub SQL Server Profiler narzędzie:
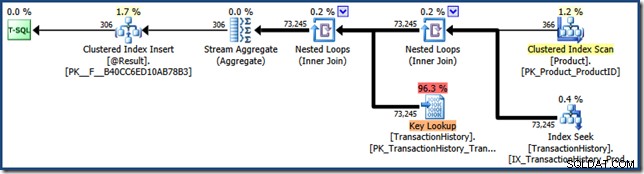

Ponieważ wąchanie parametrów dotyczy funkcji, moduły te mogą ucierpieć z powodu tych samych nieoczekiwanych zmian w wydajności, które są zwykle związane z procedurami składowanymi.
Na przykład przy pierwszym odwołaniu do funkcji może być buforowany plan, który nie używa równoległości. Kolejne wykonania z wartościami parametrów, które skorzystałyby z równoległości (ale ponownie wykorzystają buforowany plan szeregowy), wykażą nieoczekiwanie słabą wydajność.
Ten problem może być trudny do zidentyfikowania, ponieważ SQL Server nie zwraca oddzielnych planów po wykonaniu dla wywołań funkcji, jak widzieliśmy. Korzystanie z Wydarzeń rozszerzonych lub Profiler rutynowe przechwytywanie planów powykonawczych może być niezwykle zasobożerne, więc często sensowne jest użycie tej techniki w bardzo ukierunkowany sposób. Trudności związane z debugowaniem problemów z wrażliwością na parametry funkcji oznaczają, że jeszcze bardziej opłaca się przeprowadzać analizę (i kodować defensywnie), zanim funkcja trafi do produkcji.
Wykrywanie parametrów działa dokładnie w ten sam sposób w przypadku skalarnych funkcji zdefiniowanych przez użytkownika w języku T-SQL (chyba że są one wbudowane w SQL Server 2019 i nowsze). Wbudowane funkcje z wartościami tabeli nie generują oddzielnego planu wykonania dla każdego wywołania, ponieważ (jak sama nazwa wskazuje) są one wbudowane w zapytanie wywołujące przed kompilacją.
Strzeż się wąchanych wartości NULL
Wyczyść pamięć podręczną planów i poproś o szacunkową plan (przed wykonaniem) zapytania testowego:
SELECT
Result.ProductID,
Result.Name,
Result.TotalQty
FROM dbo.F(N'K%') AS Result; Zobaczysz dwa plany wykonania, z których drugi dotyczy wywołania funkcji:
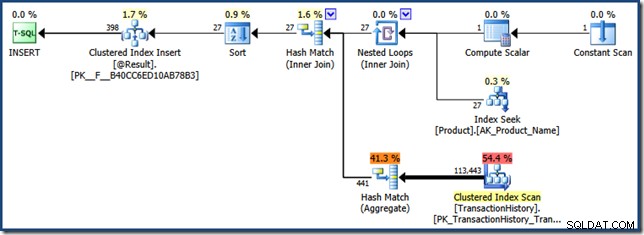
Ograniczenie podsłuchiwania parametrów z wbudowanymi funkcjami w szacowanych planach oznacza, że wartość parametru jest podsłuchiwana jako NULLs (nie „K%”):

W wersjach SQL Server sprzed 2012 r. ten plan (zoptymalizowany pod kątem NULLs) parametr) jest buforowany do ponownego użycia . To niefortunne, ponieważ NULLs jest mało prawdopodobne, aby była reprezentatywną wartością parametru, a na pewno nie była to wartość określona w zapytaniu.
SQL Server 2012 (i nowsze) nie buforuje planów wynikających z żądania „szacowanego planu”, chociaż nadal wyświetla plan funkcji zoptymalizowany pod kątem NULLs wartość parametru w czasie kompilacji.
Prosta i wymuszona parametryzacja
Instrukcja T-SQL ad-hoc zawierająca stałe wartości literału może być sparametryzowana przez SQL Server, ponieważ zapytanie kwalifikuje się do prostej parametryzacji lub ponieważ jest włączona opcja bazy danych dla wymuszonej parametryzacji (lub przewodnik po planie jest używany z tym samym skutkiem).
Tak sparametryzowana instrukcja również podlega podsłuchiwaniu parametrów. Następujące zapytanie kwalifikuje się do prostej parametryzacji:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
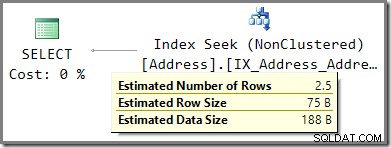
A.AddressLine1 = N'Heidestieg Straße 8664'; Szacunkowy plan wykonania pokazuje szacunkową liczbę 2,5 wiersza na podstawie wąchanej wartości parametru:
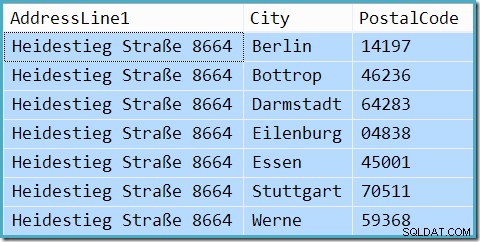
W rzeczywistości zapytanie zwraca 7 wierszy (oszacowanie kardynalności nie jest doskonałe, nawet jeśli wartości są wąchane):
W tym momencie możesz się zastanawiać, gdzie są dowody na to, że zapytanie zostało sparametryzowane, a wynikowa wartość parametru została przeszukana. Uruchom zapytanie po raz drugi z inną wartością:
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Winter der Böck 8550'; Zapytanie zwraca jeden wiersz:

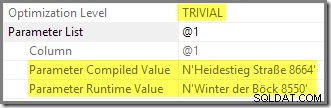
Plan wykonania pokazuje drugie wykonanie ponownie użyte sparametryzowanego planu, który został skompilowany przy użyciu sniffowanej wartości:
Parametryzacja i sniffing to osobne czynności
Instrukcja ad-hoc może być sparametryzowana przez SQL Server bez wartości parametrów są wąchane.
Aby zademonstrować, możemy użyć flagi śledzenia 4136, aby wyłączyć podsłuchiwanie parametrów dla partii, która będzie sparametryzowana przez serwer:
DBCC FREEPROCCACHE;
DBCC TRACEON (4136);
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Heidestieg Straße 8664';
GO
SELECT
A.AddressLine1,
A.City,
A.PostalCode
FROM Person.Address AS A
WHERE
A.AddressLine1 = N'Winter der Böck 8550';
GO
DBCC TRACEOFF (4136); Wynikiem skryptu są instrukcje, które są sparametryzowane, ale wartość parametru nie jest wykrywana w celu oszacowania liczności. Aby to zobaczyć, możemy sprawdzić pamięć podręczną planu:
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
DECP.cacheobjtype,
DECP.objtype,
DECP.usecounts,
DECP.plan_handle,
parameterized_plan_handle =
DEQP.query_plan.value
(
'(//StmtSimple)[1]/@ParameterizedPlanHandle',
'NVARCHAR(100)'
)
FROM sys.dm_exec_cached_plans AS DECP
CROSS APPLY sys.dm_exec_sql_text(DECP.plan_handle) AS DEST
CROSS APPLY sys.dm_exec_query_plan(DECP.plan_handle) AS DEQP
WHERE
DEST.[text] LIKE N'%AddressLine1%'
AND DEST.[text] NOT LIKE N'%XMLNAMESPACES%'; Wyniki pokazują dwa wpisy pamięci podręcznej dla zapytań ad-hoc, połączone ze sparametryzowanym (przygotowanym) planem zapytania przez uchwyt sparametryzowanego planu.
Sparametryzowany plan jest używany dwukrotnie:

Plan wykonania pokazuje inną szacunkową kardynalność teraz, gdy podsłuchiwanie parametrów jest wyłączone:
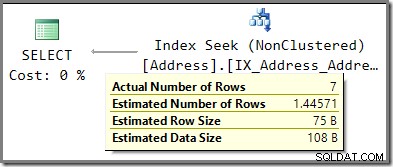
Porównaj oszacowanie 1.44571 wierszy z oszacowaniem dla 2,5 wiersza użytym, gdy włączone było podsłuchiwanie parametrów.
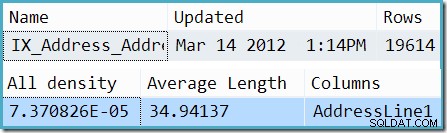
Gdy wąchanie jest wyłączone, oszacowanie pochodzi z informacji o średniej częstotliwości dla AddressLine1 kolumna. Wyciąg z DBCC SHOW_STATISTICS dane wyjściowe dla danego indeksu pokazują, w jaki sposób ta liczba została obliczona:pomnożenie liczby wierszy w tabeli (19 614) przez gęstość (7,370826e-5) daje oszacowanie wiersza 1.44571.
Uwaga boczna: Powszechnie uważa się, że tylko porównania liczb całkowitych przy użyciu unikalnego indeksu mogą kwalifikować się do prostej parametryzacji. Celowo wybrałem ten przykład (porównanie ciągów znaków przy użyciu nieunikalnego indeksu), aby temu zaprzeczyć.
Z RECOMPILE i OPTIONS (RECOMPILE)
W przypadku napotkania problemu z wrażliwością na parametry, powszechną radą na forach i stronach z pytaniami i odpowiedziami jest „użyj ponownej kompilacji” (zakładając, że inne opcje strojenia przedstawione wcześniej są nieodpowiednie). Niestety, ta rada jest często błędnie interpretowana i oznacza dodanie WITH RECOMPILE opcja procedury składowanej.
Używanie WITH RECOMPILE skutecznie przywraca nas do zachowania SQL Server 2000, gdzie cała procedura składowana jest ponownie kompilowany przy każdym wykonaniu.
lepsza alternatywa , w SQL Server 2005 i nowszych, jest użycie OPTION (RECOMPILE) wskazówka zapytania dotycząca tylko wypowiedzi który cierpi z powodu problemu z podsłuchiwaniem parametrów. Ta wskazówka dotycząca zapytania powoduje ponowną kompilację problematycznej instrukcji tylko. Plany wykonania dla innych instrukcji w ramach procedury składowanej są buforowane i ponownie używane jak zwykle.
Używanie WITH RECOMPILE oznacza również, że skompilowany plan procedury składowanej nie jest buforowany. W rezultacie żadne informacje o wydajności nie są przechowywane w DMV, takich jak sys.dm_exec_query_stats .
Użycie wskazówki dotyczącej zapytania zamiast tego oznacza, że skompilowany plan może być buforowany, a informacje o wydajności są dostępne w DMV (chociaż są one ograniczone do najnowszego wykonania, tylko dla danej instrukcji).
W przypadku wystąpień z kompilacją co najmniej SQL Server 2008 2746 (z dodatkiem Service Pack 1 z aktualizacją zbiorczą 5), przy użyciu OPTION (RECOMPILE) ma kolejną znaczącą przewagę ponad WITH RECOMPILE :Tylko OPTION (RECOMPILE) włącza optymalizację osadzania parametrów .
Optymalizacja osadzania parametrów
Wąchanie wartości parametrów umożliwia optymalizatorowi wykorzystanie wartości parametru do uzyskania oszacowań kardynalności. Oba WITH RECOMPILE i OPTION (RECOMPILE) dają w wyniku plany zapytań z szacunkami obliczonymi na podstawie rzeczywistych wartości parametrów przy każdym wykonaniu.
Optymalizacja osadzania parametrów idzie o krok dalej w tym procesie. Parametry zapytania są zastępowane ze stałymi wartościami literalnymi podczas parsowania zapytania.
Parser jest zdolny do zaskakująco złożonych uproszczeń, a późniejsza optymalizacja zapytań może jeszcze bardziej udoskonalić. Rozważ następującą procedurę składowaną, która zawiera WITH RECOMPILE opcja:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
WITH RECOMPILE
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC;
END; Procedura jest wykonywana dwukrotnie, z następującymi wartościami parametrów:
EXECUTE dbo.P @NameLike = N'K%', @Sort = 1; GO EXECUTE dbo.P @NameLike = N'[H-R]%', @Sort = 4;
Ponieważ WITH RECOMPILE jest używany, procedura jest w pełni rekompilowana przy każdym wykonaniu. Wartości parametrów są wychwytywane za każdym razem i używane przez optymalizator do obliczania szacunków kardynalności.
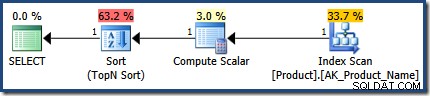
Plan wykonania pierwszej procedury jest dokładnie poprawny, szacując 1 wiersz:
Drugie wykonanie szacuje 360 wierszy, bardzo blisko 366 widocznych w czasie wykonywania:
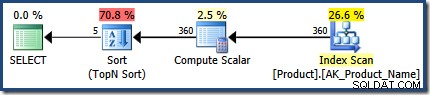
Oba plany używają tej samej ogólnej strategii wykonania:Przeskanuj wszystkie wiersze w indeksie, stosując WHERE predykat klauzuli jako rezydualny; oblicz CASE wyrażenie użyte w ORDER BY klauzula; i przeprowadź Sortowanie według N do góry na wynik CASE wyrażenie.
OPCJA (RECOMPILE)
Teraz ponownie utwórz procedurę składowaną za pomocą OPTION (RECOMPILE) wskazówka zapytania zamiast WITH RECOMPILE :
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END; Dwukrotne wykonanie procedury składowanej z tymi samymi wartościami parametrów co poprzednio daje drastycznie różne plany wykonania.
To jest pierwszy plan wykonania (z parametrami żądającymi nazw zaczynających się od „K”, uporządkowany według ProductID rosnąco):
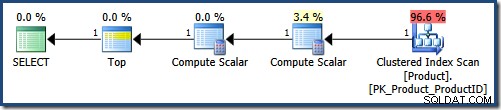
Parser osadza wartości parametrów w tekście zapytania, co daje następującą postać pośrednią:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
'K%' IS NULL
OR Name LIKE 'K%'
ORDER BY
CASE WHEN 1 = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN 1 = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN 1 = 3 THEN Name ELSE NULL END ASC,
CASE WHEN 1 = 4 THEN Name ELSE NULL END DESC;
Parser idzie dalej, usuwając sprzeczności i w pełni oceniając CASE wyrażenia. Powoduje to:
SELECT TOP (5)
ProductID,
Name
FROM Production.Product
WHERE
Name LIKE 'K%'
ORDER BY
ProductID ASC,
NULL DESC,
NULL ASC,
NULL DESC; Otrzymasz komunikat o błędzie, jeśli spróbujesz przesłać to zapytanie bezpośrednio do SQL Server, ponieważ porządkowanie według stałej wartości jest niedozwolone. Niemniej jednak jest to forma tworzona przez parser. Jest to dozwolone wewnętrznie, ponieważ powstało w wyniku zastosowania optymalizacji osadzania parametrów . Uproszczone zapytanie znacznie ułatwia życie optymalizatorowi zapytań:
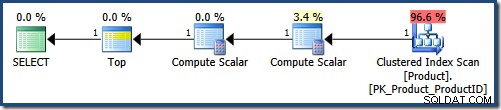
Skanowanie indeksu klastrowego stosuje LIKE predykat jako reszta. Skalar obliczeniowy dostarcza stałą NULLs wartości. Góra zwraca pierwszych 5 wierszy w kolejności podanej przez indeks klastrowy (unikając sortowania). W idealnym świecie optymalizator zapytań usunie także Compute Scalar który definiuje NULLs , ponieważ nie są one używane podczas wykonywania zapytania.
Drugie wykonanie przebiega dokładnie w tym samym procesie, w wyniku czego powstaje plan zapytania (dla nazw zaczynających się od liter „H” do „R”, uporządkowany według Name malejąco) w ten sposób:

Ten plan obejmuje nieklastrowe wyszukiwanie indeksu który obejmuje LIKE zakres, resztkowy LIKE predykat, stała NULLs jak poprzednio i górną (5). Optymalizator zapytań postanawia wykonać BACKWARD skanowanie zakresu w szukaniu indeksu aby ponownie uniknąć sortowania.
Porównaj powyższy plan z tym stworzonym za pomocą WITH RECOMPILE , który nie może korzystać z optymalizacji osadzania parametrów :
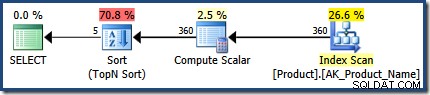
Ten przykład demonstracyjny mógłby zostać lepiej zaimplementowany jako seria IF oświadczenia w procedurze (po jednym dla każdej kombinacji wartości parametrów). Może to zapewnić podobne korzyści związane z planem zapytań bez konieczności kompilowania instrukcji za każdym razem. W bardziej złożonych scenariuszach ponowna kompilacja na poziomie instrukcji z osadzaniem parametrów zapewnianym przez OPTION (RECOMPILE) może być niezwykle przydatną techniką optymalizacji.
Ograniczenie umieszczania
Jest jeden scenariusz, w którym użycie OPTION (RECOMPILE) nie spowoduje zastosowania optymalizacji osadzania parametrów. Jeśli instrukcja przypisuje do zmiennej, wartości parametrów nie są osadzane:
CREATE PROCEDURE dbo.P
@NameLike nvarchar(50),
@Sort tinyint
AS
BEGIN
DECLARE
@ProductID integer,
@Name nvarchar(50);
SELECT TOP (1)
@ProductID = ProductID,
@Name = Name
FROM Production.Product
WHERE
@NameLike IS NULL
OR Name LIKE @NameLike
ORDER BY
CASE WHEN @Sort = 1 THEN ProductID ELSE NULL END ASC,
CASE WHEN @Sort = 2 THEN ProductID ELSE NULL END DESC,
CASE WHEN @Sort = 3 THEN Name ELSE NULL END ASC,
CASE WHEN @Sort = 4 THEN Name ELSE NULL END DESC
OPTION (RECOMPILE);
END;
Ponieważ SELECT instrukcja przypisuje teraz do zmiennej, tworzone plany zapytań są takie same, jak w przypadku WITH RECOMPILE zastosowano. Wartości parametrów są nadal wykrywane i używane przez optymalizator zapytań do szacowania liczności oraz OPTION (RECOMPILE) nadal kompiluje tylko pojedynczą instrukcję, tylko korzyść z osadzenia parametrów jest zgubiony.



