Mój przyjaciel Peter Larsson wysłał mi wyzwanie T-SQL polegające na dopasowaniu podaży do popytu. Jeśli chodzi o wyzwania, jest to ogromne. To dość powszechna potrzeba w prawdziwym życiu; jest prosty do opisania i dość łatwy do rozwiązania z rozsądną wydajnością przy użyciu rozwiązania opartego na kursorze. Trudną częścią jest rozwiązanie go za pomocą wydajnego rozwiązania opartego na zestawie.
Kiedy Peter wysyła mi łamigłówkę, zazwyczaj odpowiadam, proponując rozwiązanie, a on zwykle wymyśla lepsze, genialne rozwiązanie. Czasami podejrzewam, że wysyła mi łamigłówki, aby zmotywować się do znalezienia świetnego rozwiązania.
Ponieważ zadanie reprezentuje powszechną potrzebę i jest tak interesujące, zapytałem Petera, czy nie miałby nic przeciwko, gdybym podzielił się nim i jego rozwiązaniami z czytelnikami sqlperformance.com, a on chętnie mi na to pozwolił.
W tym miesiącu przedstawię wyzwanie i klasyczne rozwiązanie oparte na kursorach. W kolejnych artykułach przedstawię rozwiązania oparte na zestawach — w tym te, nad którymi pracowaliśmy z Peterem.
Wyzwanie
Wyzwanie polega na przeszukiwaniu tabeli o nazwie Aukcje, którą tworzysz za pomocą następującego kodu:
DROP TABLE IF EXISTS dbo.Auctions;
CREATE TABLE dbo.Auctions
(
ID INT NOT NULL IDENTITY(1, 1)
CONSTRAINT pk_Auctions PRIMARY KEY CLUSTERED,
Code CHAR(1) NOT NULL
CONSTRAINT ck_Auctions_Code CHECK (Code = 'D' OR Code = 'S'),
Quantity DECIMAL(19, 6) NOT NULL
CONSTRAINT ck_Auctions_Quantity CHECK (Quantity > 0)
); Ta tabela zawiera wpisy popytu i podaży. Wpisy popytu są oznaczone kodem D, a wpisy podaży S. Twoim zadaniem jest dopasowanie ilości podaży i popytu na podstawie zamówienia ID, zapisując wynik do tabeli tymczasowej. Wpisy mogą reprezentować zlecenia kupna i sprzedaży kryptowalut, takie jak BTC/USD, zlecenia kupna i sprzedaży akcji, takie jak MSFT/USD, lub dowolny inny przedmiot lub towar, w którym trzeba dopasować podaż do popytu. Zauważ, że we wpisach Aukcje brakuje atrybutu ceny. Jak wspomniano, należy dopasować ilości podaży i popytu na podstawie zamówienia identyfikatora. Ta kolejność mogła wynikać z ceny (rosnąca dla wpisów podaży i malejąca dla wpisów popytu) lub z innych odpowiednich kryteriów. W tym wyzwaniu ideą było uproszczenie sprawy i założenie, że identyfikator już reprezentuje odpowiednią kolejność dopasowywania.
Jako przykład użyj następującego kodu, aby wypełnić tabelę Aukcje małym zestawem przykładowych danych:
SET NOCOUNT ON; DELETE FROM dbo.Auctions; SET IDENTITY_INSERT dbo.Auctions ON; INSERT INTO dbo.Auctions(ID, Code, Quantity) VALUES (1, 'D', 5.0), (2, 'D', 3.0), (3, 'D', 8.0), (5, 'D', 2.0), (6, 'D', 8.0), (7, 'D', 4.0), (8, 'D', 2.0), (1000, 'S', 8.0), (2000, 'S', 6.0), (3000, 'S', 2.0), (4000, 'S', 2.0), (5000, 'S', 4.0), (6000, 'S', 3.0), (7000, 'S', 2.0); SET IDENTITY_INSERT dbo.Auctions OFF;
Powinieneś dopasować ilości podaży i popytu w ten sposób:
- Ilość 5,0 jest dopasowana dla Popytu 1 i Podaży 1000, uszczuplając Popyt 1 i pozostawiając 3.0 Podaży 1000
- Ilość 3,0 jest dopasowana dla Popytu 2 i Podaży 1000, wyczerpując zarówno Popyt 2, jak i Podaż 1000
- Ilość 6,0 jest dopasowana dla Popytu 3 i Podaży 2000, pozostawiając 2,0 Popytu 3 i uszczuplając podaż 2000
- Ilość 2,0 jest dopasowana dla Popytu 3 i Podaży 3000, wyczerpując zarówno Popyt 3, jak i Podaż 3000
- Ilość 2,0 jest dopasowana dla Popytu 5 i Podaży 4000, wyczerpując zarówno Popyt 5, jak i Podaż 4000
- Ilość 4.0 jest dopasowana dla Popytu 6 i Podaży 5000, pozostawiając 4.0 Popytu 6 i uszczuplając Podaż 5000
- Ilość 3,0 jest dopasowana do Demand 6 i Supply 6000, pozostawiając 1.0 Demand 6 i uszczuplając Supply 6000
- Ilość 1.0 jest dopasowywana dla Popytu 6 i Podaży 7000, zmniejszając Popyt 6 i pozostawiając 1.0 Podaży 7000
- Ilość 1,0 jest dopasowana dla Popytu 7 i Podaży 7000, pozostawiając 3,0 dla Popytu 7 i uszczuplając Podaż 7000; Popyt 8 nie jest dopasowany do żadnych wpisów podaży i dlatego pozostaje z pełną ilością 2.0
Twoje rozwiązanie powinno zapisać następujące dane w wynikowej tabeli tymczasowej:
DemandID SupplyID TradeQuantity ----------- ----------- -------------- 1 1000 5.000000 2 1000 3.000000 3 2000 6.000000 3 3000 2.000000 5 4000 2.000000 6 5000 4.000000 6 6000 3.000000 6 7000 1.000000 7 7000 1.000000
Duży zestaw przykładowych danych
Aby przetestować wydajność rozwiązań, potrzebujesz większego zestawu przykładowych danych. Aby w tym pomóc, możesz użyć funkcji GetNums, którą tworzysz, uruchamiając następujący kod:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Ta funkcja zwraca sekwencję liczb całkowitych z żądanego zakresu.
Po uruchomieniu tej funkcji możesz użyć poniższego kodu dostarczonego przez Petera, aby wypełnić tabelę Aukcje przykładowymi danymi, dostosowując dane wejściowe zgodnie z potrzebami:
DECLARE
-- test with 50K, 100K, 150K, 200K in each of variables @Buyers and @Sellers
-- so total rowcount is double (100K, 200K, 300K, 400K)
@Buyers AS INT = 200000,
@Sellers AS INT = 200000,
@BuyerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@BuyerMaxQuantity AS DECIMAL(19, 6) = 99.999999,
@SellerMinQuantity AS DECIMAL(19, 6) = 0.000001,
@SellerMaxQuantity AS DECIMAL(19, 6) = 99.999999;
DELETE FROM dbo.Auctions;
INSERT INTO dbo.Auctions(Code, Quantity)
SELECT Code, Quantity
FROM ( SELECT 'D' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@BuyerMaxQuantity - @BuyerMinQuantity)))
/ 1000000E + @BuyerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Buyers)
UNION ALL
SELECT 'S' AS Code,
(ABS(CHECKSUM(NEWID())) % (1000000 * (@SellerMaxQuantity - @SellerMinQuantity)))
/ 1000000E + @SellerMinQuantity AS Quantity
FROM dbo.GetNums(1, @Sellers) ) AS X
ORDER BY NEWID();
SELECT Code, COUNT(*) AS Items
FROM dbo.Auctions
GROUP BY Code; Jak widać, możesz dostosować liczbę kupujących i sprzedających, a także minimalną i maksymalną ilość kupujących i sprzedających. Powyższy kod określa 200 000 kupujących i 200 000 sprzedających, co daje łącznie 400 000 wierszy w tabeli Aukcje. Ostatnie zapytanie informuje, ile wpisów popytu (D) i podaży (S) zostało zapisanych w tabeli. Zwraca następujące dane wyjściowe dla wyżej wymienionych danych wejściowych:
Code Items ---- ----------- D 200000 S 200000
Mam zamiar przetestować wydajność różnych rozwiązań za pomocą powyższego kodu, ustawiając liczbę kupujących i sprzedających na:50 000, 100 000, 150 000 i 200 000. Oznacza to, że otrzymam następującą całkowitą liczbę wierszy w tabeli:100 000, 200 000, 300 000 i 400 000. Oczywiście możesz dostosować dane wejściowe, aby przetestować wydajność swoich rozwiązań.
Rozwiązanie oparte na kursorach
Peter dostarczył rozwiązanie oparte na kursorach. Jest dość prosty, co jest jedną z jego ważnych zalet. Będzie używany jako punkt odniesienia.
Rozwiązanie wykorzystuje dwa kursory:jeden dla wpisów popytu uporządkowanych według ID, a drugi dla wpisów podaży uporządkowanych według ID. Aby uniknąć pełnego skanowania i sortowania według kursora, utwórz następujący indeks:
CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity);
Oto kompletny kod rozwiązania:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #PairingsCursor;
CREATE TABLE #PairingsCursor
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
DECLARE curDemand CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS DemandID, Quantity FROM dbo.Auctions WHERE Code = 'D' ORDER BY ID;
DECLARE curSupply CURSOR LOCAL FORWARD_ONLY READ_ONLY FOR
SELECT ID AS SupplyID, Quantity FROM dbo.Auctions WHERE Code = 'S' ORDER BY ID;
DECLARE @DemandID AS INT, @DemandQuantity AS DECIMAL(19, 6),
@SupplyID AS INT, @SupplyQuantity AS DECIMAL(19, 6);
OPEN curDemand;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
OPEN curSupply;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DemandQuantity <= @SupplyQuantity
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @DemandQuantity);
SET @SupplyQuantity -= @DemandQuantity;
FETCH NEXT FROM curDemand INTO @DemandID, @DemandQuantity;
END;
ELSE
BEGIN
IF @SupplyQuantity > 0
BEGIN
INSERT #PairingsCursor(DemandID, SupplyID, TradeQuantity)
VALUES(@DemandID, @SupplyID, @SupplyQuantity);
SET @DemandQuantity -= @SupplyQuantity;
END;
FETCH NEXT FROM curSupply INTO @SupplyID, @SupplyQuantity;
END;
END;
CLOSE curDemand;
DEALLOCATE curDemand;
CLOSE curSupply;
DEALLOCATE curSupply; Jak widać, kod zaczyna się od utworzenia tabeli tymczasowej. Następnie deklaruje dwa kursory i pobiera wiersz z każdego z nich, zapisując bieżącą ilość popytu do zmiennej @DemandQuantity i bieżącą ilość podaży do @SupplyQuantity. Następnie przetwarza wpisy w pętli, o ile ostatnie pobranie zakończyło się pomyślnie. Kod stosuje następującą logikę w ciele pętli:
Jeśli aktualna ilość popytu jest mniejsza lub równa aktualnej ilości podaży, kod wykonuje następujące czynności:
- Zapisuje wiersz do tabeli tymczasowej z bieżącym parowaniem, z ilością popytu (@DemandQuantity) jako dopasowaną ilością
- Odejmuje bieżącą ilość popytu od bieżącej ilości podaży (@SupplyQuantity)
- Pobiera następny wiersz z kursora popytu
W przeciwnym razie kod wykonuje następujące czynności:
- Sprawdza, czy aktualna ilość dostaw jest większa od zera, a jeśli tak, wykonuje następujące czynności:
- Zapisuje wiersz do tabeli tymczasowej z bieżącym parowaniem, z ilością podaży jako dopasowaną ilością
- Odejmuje bieżącą ilość podaży od aktualnej ilości popytu
- Pobiera następny wiersz z kursora podaży
Po zakończeniu pętli nie ma więcej par do dopasowania, więc kod po prostu czyści zasoby kursora.
Z punktu widzenia wydajności otrzymujesz typowe obciążenie związane z pobieraniem i zapętlaniem kursora. Z drugiej strony, to rozwiązanie wykonuje jedno uporządkowane przejście nad danymi popytu i jedno uporządkowane przejście nad danymi podaży, przy czym każde z nich wykorzystuje wyszukiwanie i skanowanie zakresu we wcześniej utworzonym indeksie. Plany zapytań kursorowych są pokazane na rysunku 1.

Rysunek 1:Plany zapytań kursora
Ponieważ plan wykonuje wyszukiwanie i uporządkowane skanowanie zakresu każdej z części (zapotrzebowanie i podaż) bez udziału sortowania, ma skalowanie liniowe. Zostało to potwierdzone przez wyniki, które uzyskałem podczas testowania, jak pokazano na rysunku 2.
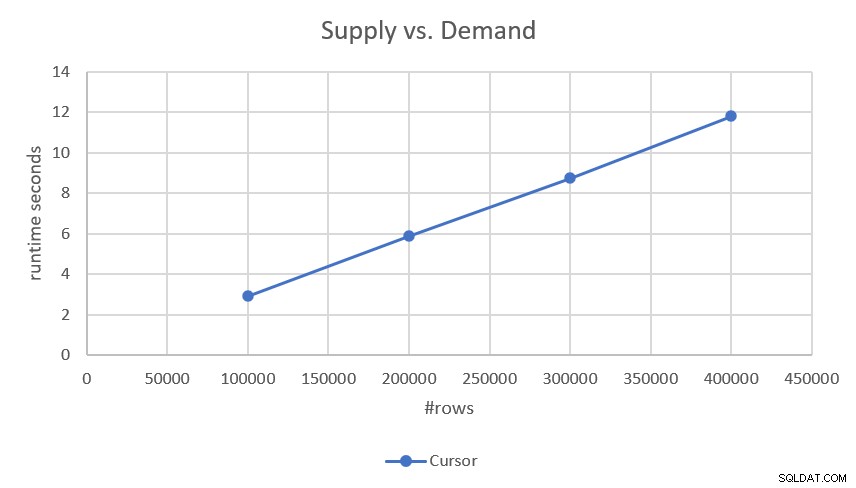
Rysunek 2:Wydajność rozwiązania opartego na kursorach
Jeśli interesują Cię bardziej precyzyjne czasy działania, oto one:
- 100 000 wierszy (50 000 żądań i 50 000 dostaw):2,93 sekundy
- 200 000 wierszy:5,89 sekundy
- 300 000 wierszy:8,75 sekundy
- 400 000 wierszy:11,81 sekundy
Biorąc pod uwagę, że rozwiązanie ma skalowanie liniowe, możesz łatwo przewidzieć czas działania z innymi skalami. Na przykład przy milionie wierszy (powiedzmy 500 000 żądań i 500 000 materiałów eksploatacyjnych) uruchomienie powinno zająć około 29,5 sekundy.
Wyzwanie trwa
Rozwiązanie oparte na kursorze ma skalowanie liniowe i jako takie nie jest złe. Ale wiąże się to z typowym pobieraniem kursora i pętlą. Oczywiście możesz zmniejszyć ten narzut, implementując ten sam algorytm przy użyciu rozwiązania opartego na CLR. Pytanie brzmi, czy możesz wymyślić skuteczne rozwiązanie oparte na zestawie do tego zadania?
Jak wspomniano, od przyszłego miesiąca omówię rozwiązania oparte na zestawach — zarówno słabo działające, jak i dobrze działające. W międzyczasie, jeśli sprostasz wyzwaniu, sprawdź, czy możesz wymyślić własne rozwiązania oparte na zestawach.
Aby zweryfikować poprawność swojego rozwiązania, najpierw porównaj jego wynik z pokazanym tutaj dla małego zestawu przykładowych danych. Możesz również sprawdzić poprawność wyniku rozwiązania za pomocą dużego zestawu przykładowych danych, sprawdzając, czy różnica symetryczna między wynikiem rozwiązania kursora a Twoim jest pusta. Zakładając, że wynik kursora jest przechowywany w tabeli tymczasowej o nazwie #PairingsCursor, a Twój w tabeli tymczasowej o nazwie #MyPairings, możesz użyć następującego kodu, aby to osiągnąć:
(SELECT * FROM #PairingsCursor EXCEPT SELECT * FROM #MyPairings) UNION ALL (SELECT * FROM #MyPairings EXCEPT SELECT * FROM #PairingsCursor);
Wynik powinien być pusty.
Powodzenia!
[ Przejdź do rozwiązań:Część 1 | Część 2 | Część 3 ]