Ten post jest częścią samouczka Oracle SQL i będziemy omawiać funkcje analityczne w Oracle (Over by partition) z przykładami, szczegółowym wyjaśnieniem.
Przestudiowaliśmy już funkcję Oracle Aggregate, taką jak avg ,sum ,count. Weźmy przykład
Najpierw utwórzmy przykładowe dane
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
SQL> desc emp
Name Null? Type
---- ---- -----
EMPNO NOT NULL NUMBER(4)
ENAME VARCHAR2(10)
JOB VARCHAR2(9)
MGR NUMBER(4)
HIREDATE DATE
SAL NUMBER(7,2)
COMM NUMBER(7,2)
DEPTNO NUMBER(2)
SQL> desc dept
Name Null? Type
---- ----- ----
DEPTNO NOT NULL NUMBER(2)
DNAME VARCHAR2(14)
LOC VARCHAR2(13)
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
commit;
insert into emp values( 7839, 'Allen', 'MANAGER', 7839, to_date('17-11-1981','dd-mm-yyyy'), 20, null, 10 );
insert into emp values( 7782, 'CLARK', 'MANAGER', 7839, to_date('9-06-1981','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7934, 'MILLER', 'MANAGER', 7839, to_date('23-01-1982','dd-mm-yyyy'), 0, null, 10 );
insert into emp values( 7788, 'SMITH', 'ANALYST', 7788, to_date('17-12-1980','dd-mm-yyyy'), 800, null, 20 );
insert into emp values( 7902, 'ADAM, 'ANALYST', 7832, to_date('23-05-1987','dd-mm-yyyy'), 1100, null, 20 );
insert into emp values( 7876, 'FORD', 'ANALYST', 7566, to_date('3-12-1981','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7369, 'SCOTT', 'ANALYST', 7566, to_date('19-04-1987','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7698, 'JAMES', 'ANALYST', 7788, to_date('03-12-1981','dd-mm-yyyy'), 950, null, 30 );
insert into emp values( 7499, 'MARTIN', 'ANALYST', 7698, to_date('28-09-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7844, 'WARD', 'ANALYST', 7698, to_date('22-02-1981','dd-mm-yyyy'), 1250, null, 30 );
insert into emp values( 7654, 'TURNER', 'ANALYST', 7698, to_date('08-09-1981','dd-mm-yyyy'), 1500, null, 30 );
insert into emp values( 7521, 'ALLEN', 'ANALYST', 7698, to_date('20-02-1981','dd-mm-yyyy'), 1600, null, 30 );
insert into emp values( 7900, 'BLAKE', 'ANALYST', 77698, to_date('01-05-1981','dd-mm-yyyy'), 2850, null, 30 );
commit;
Teraz przykład funkcji agregujących zostanie podany poniżej
select count(*) from EMP; --------- 13 select sum (bytes) from dba_segments where tablespace_name='TOOLS'; ----- 100 SQL> select deptno ,count(*) from emp group by deptno; DEPTNO COUNT(*) ---------- ---------- 30 6 20 4 10 3
Tutaj widzimy, że zmniejsza to liczbę wierszy w każdym z zapytań. Teraz pojawiają się pytania, co zrobić, jeśli musimy również zwrócić wszystkie wiersze z count(*)
Do tego wyrocznia zapewniła zestaw funkcji analitycznych. Aby rozwiązać ostatni problem , możemy napisać jako
select empno ,deptno , count(*) over (partition by deptno) from emp group by deptno;
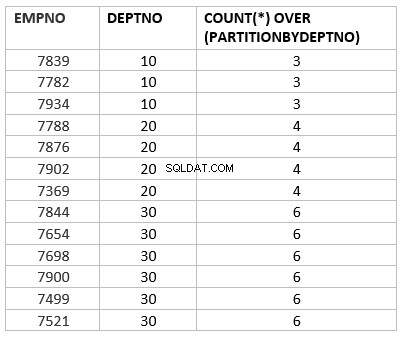
Tutaj count(*) over (partycja przez dept_no) jest analityczną wersją funkcji agregującej count. Główna praca z kluczem, która różni się od funkcji agregującej, polega na podzieleniu przez
Funkcje analityczne obliczają wartość zagregowaną na podstawie grupy wierszy. Różnią się one od funkcji agregujących tym, że zwracają wiele wierszy dla każdej grupy. Grupa wierszy nazywana jest oknem i jest zdefiniowana przez klauzulę analityczną.
Oto ogólna składnia
analytic_function([ arguments ]) OVER ([ query_partition_clause ] [ order_by_clause [ windowing_clause ] ])
Przykład
count(*) over (partition by deptno) avg(Sal) over (partition by deptno)
Przejdźmy do każdej części
query_partition_clause
Zdefiniował grupę wierszy. Może jak poniżej
partycja według deptno :grupa wierszy tego samego deptno
lub
() :Wszystkie wiersze
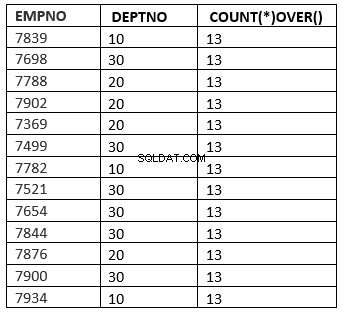
SQL> select empno ,deptno , count(*) over () from emp;
[ order_by_clause [ windowing_clause ] ]
Ta klauzula jest używana, gdy chcesz uporządkować wiersze w partycji. Jest to szczególnie przydatne, jeśli chcesz, aby funkcja analityczna uwzględniała kolejność wierszy.
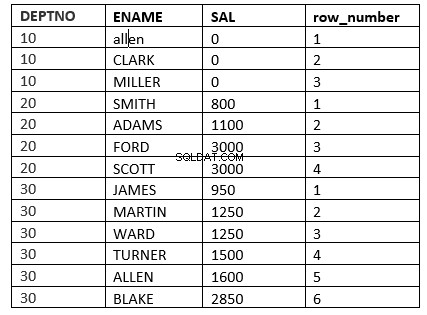
Przykładem będzie funkcja row_number
SQL> select deptno, ename, sal, row_number() over (partition by deptno order by sal) "row_number" from emp;
Innym przykładem może być
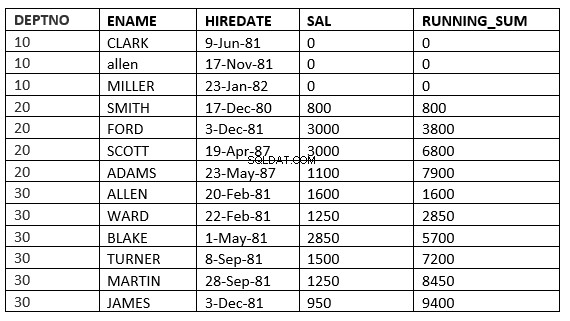
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Windowing_clause
Jest to zawsze używane z klauzulą order by i daje większą kontrolę nad zestawem wierszy w grupie
Z klauzulą Windowing, dla każdego wiersza definiowane jest przesuwane okno wierszy. Okno określa zakres wierszy użytych do wykonania obliczeń dla bieżącego wiersza. Rozmiary okien mogą być oparte na fizycznej liczbie wierszy lub logicznym przedziale, takim jak czas.
Podczas używania klauzuli order by i nic nie jest podane dla klauzuli_okiennej, poniżej domyślna wartość klauzuli_okiennej jest przyjmowana
ZAKRES MIĘDZY UNBOUNDED PRECEDING I CURRENT ROW lub RANGE UNBOUNDED PRECEDING
Oznacza to „Bieżący i poprzedni wiersz w bieżącym partycja to wiersze, które powinny być użyte w obliczeniach”
Poniższy przykład wyraźnie to potwierdza. To jest średnia krocząca w dziale
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE) running_sum from emp;
Teraz windowing_clause można zdefiniować na wiele sposobów
Najpierw zrozummy terminologię
WIERSZE określa okno w jednostkach fizycznych (wierszach).
ZAKRES określa okno jako logiczne przesunięcie. Klauzula okienkowa RANGE może być używana tylko z klauzulami ORDER BY zawierającymi kolumny lub wyrażenia liczb lub typów danych
PRECEDING – uzyskaj wiersze przed bieżącym.
OBSERWUJĄCE – uzyskaj wiersze po bieżącym.
BEZ OGRANICZENIA – gdy jest używany z PRECEDING lub FOLLOWING, zwraca wszystko przed lub po. BIEŻĄCY WIERSZ
Więc to jest ogólnie definiowane jako
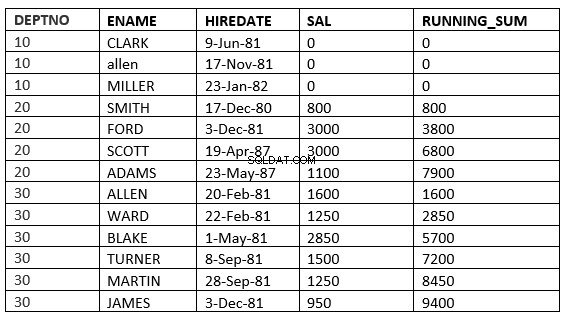
WIERSZE BEZ OGRANICZENIA POSTĘPUJĄCE :Bieżący i poprzedni wiersz w bieżącej partycji to wiersze, które powinny zostać użyte w obliczeniach
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS UNBOUNDED PRECEDING) running_sum from emp;
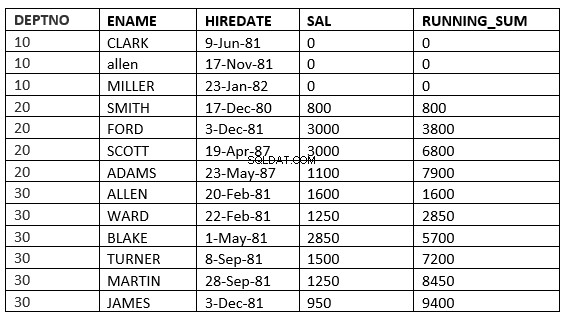
ZASIĘG BEZ OGRANICZEŃ POSTĘPOWANIE :Bieżące i poprzednie wiersze w bieżącej partycji to wiersze, które powinny być użyte w obliczeniach. Również ponieważ zakres jest określony, wszystkie przyjmują wartości, które są równe bieżącym wierszom.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE UNBOUNDED PRECEDING) running_sum from emp;
Możesz nie widzieć różnicy między zakresem a wierszami, ponieważ data_zatrudnienia jest różna dla wszystkich. Różnica stanie się bardziej wyraźna, jeśli użyjemy sal jako klauzuli kolejność po
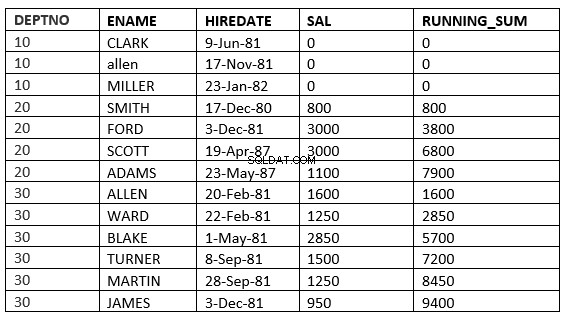
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal RANGE UNBOUNDED PRECEDING) running_sum from emp;
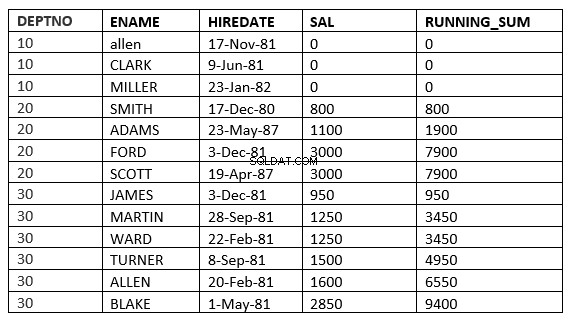
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by sal ROWS UNBOUNDED PRECEDING) running_sum from emp;
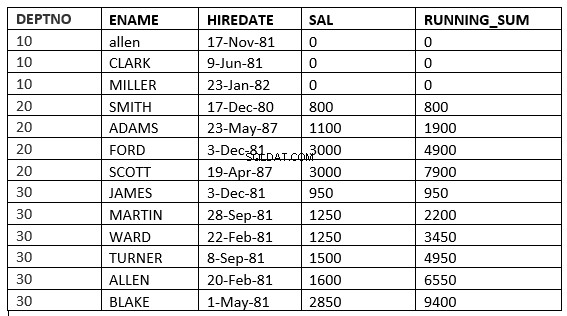
Różnicę znajdziesz w linii 6
RANGE value_expr PRECEDING :Okno zaczyna się od wiersza, którego wartość ORDER BY to wiersze wyrażenia liczbowego mniejsze lub poprzedzające bieżący wiersz, a kończy się na bieżącym przetwarzanym wierszu.
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE 365 PRECEDING) running_sum from emp;
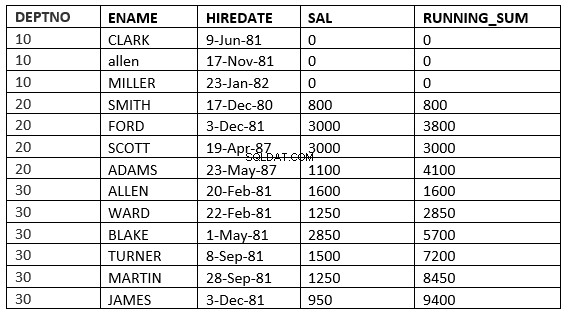
Tutaj pobiera wszystkie wiersze, w których wartość daty zatrudnienia przypada w ciągu 365 dni poprzedzających wartość daty zatrudnienia w bieżącym wierszu
ROWS value_expr PRECEDING :Okno zaczyna się podanym wierszem i kończy bieżącym przetwarzanym wierszem
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS 2 PRECEDING) running_sum from emp;
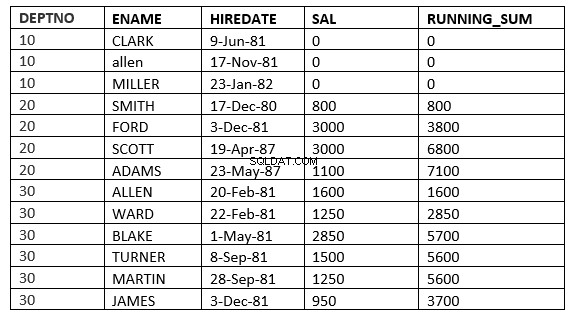
Tutaj okno zaczyna się od 2 wierszy poprzedzających bieżący wiersz
ZAKRES MIĘDZY BIEŻĄCYM WIERSZEM a value_expr NASTĘPUJĄCYMI :Okno zaczyna się od bieżącego wiersza i kończy wierszem, którego wartość ORDER BY jest liczbą wierszy wyrażenia mniejszą niż lub następującą
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
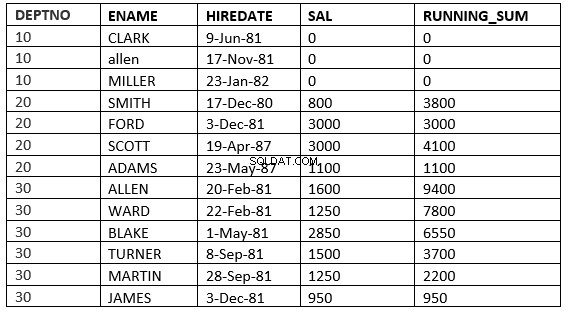
WIERSZE MIĘDZY BIEŻĄCYM WIERSZEM a value_expr PO :Okno zaczyna się bieżącym wierszem i kończy wierszami po bieżącym
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE ROWS between current row and 1 FOLLOWING) running_sum from emp;
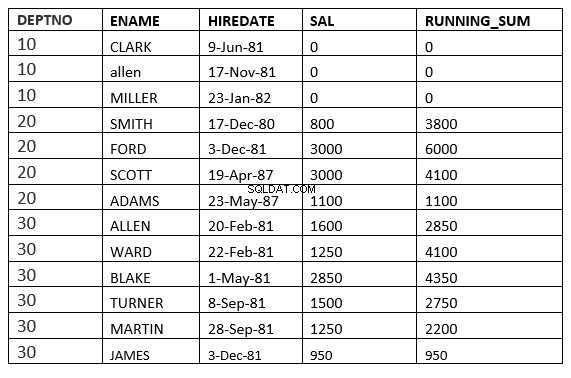
ZAKRES MIĘDZY NIEOGRANICZONYM POSTĘPOWANIEM A NIEOGRANICZONYM NASTĘPUJĄCYM
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING ) running_sum from emp;
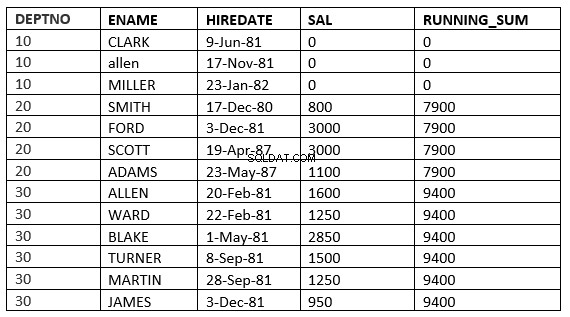
ZAKRES POMIĘDZY value_expr POPRZEDNIE a value_expr NASTĘPNY
SQL> select deptno, ename,hiredate, sal,sum(sal) over (partition by deptno order by HIREDATE RANGE BETWEEN 365 PRECEDING and 365 FOLLOWING ) running_sum from emp; 2 DEPTNO ENAME HIREDATE SAL RUNNING_SUM ---------- ---------- --------------- ---------- ----------- 10 CLARK 09-JUN-81 0 0 10 ALLEN 17-NOV-81 0 0 10 MILLER 23-JAN-82 0 0 20 SMITH 17-DEC-80 800 3800 20 FORD 03-DEC-81 3000 3800 20 SCOTT 19-APR-87 3000 4100 20 ADAMS 23-MAY-87 1100 4100 30 ALLEN 20-FEB-81 1600 9400 30 WARD 22-FEB-81 1250 9400 30 BLAKE 01-MAY-81 2850 9400 30 TURNER 08-SEP-81 1500 9400 30 MARTIN 28-SEP-81 1250 9400 30 JAMES 03-DEC-81 950 9400 13 rows selected.
Niektóre ważne uwagi
(1)Funkcje analityczne to ostatni zestaw operacji wykonywanych w zapytaniu, z wyjątkiem końcowej klauzuli ORDER BY. Wszystkie sprzężenia i wszystkie klauzule WHERE, GROUP BY i HAVING są uzupełniane przed przetworzeniem funkcji analitycznych. Dlatego funkcje analityczne mogą pojawiać się tylko na liście wyboru lub w klauzuli ORDER BY.
(2)Funkcje analityczne są powszechnie używane do obliczania agregacji skumulowanych, przenoszenia, wyśrodkowania i raportowania.
Mam nadzieję, że podoba Ci się to szczegółowe wyjaśnienie funkcji analitycznych w oracle (poniżej klauzuli partycji)
Powiązane artykuły
Funkcja LEAD w Oracle
Funkcja DENSE w Oracle
Funkcja Oracle LITAGG
Agregacja danych za pomocą funkcji grupowych
https://docs.oracle.com/cd/E11882_01/ server.112/e41084/functions004.htm