[ Część 1 | Część 2 | Część 3 | Część 4 ]
W części 3 tej serii pokazałem dwa obejścia, aby uniknąć poszerzenia IDENTITY kolumna – jedna, która po prostu kupuje Ci czas, i druga, która porzuca IDENTITY całkowicie. To pierwsze zapobiega konieczności zajmowania się zależnościami zewnętrznymi, takimi jak klucze obce, ale drugie nadal nie rozwiązuje tego problemu. W tym poście chciałem szczegółowo opisać podejście, które zastosowałbym, gdybym absolutnie musiał przejść do bigint , potrzebne do zminimalizowania przestojów i miały dużo czasu na planowanie.
Ze względu na wszystkie potencjalne blokery i potrzebę minimalnych zakłóceń, podejście może być postrzegane jako nieco złożone i staje się bardziej skomplikowane, jeśli używane są dodatkowe egzotyczne funkcje (powiedzmy, partycjonowanie, OLTP w pamięci lub replikacja) .
Na bardzo wysokim poziomie podejście polega na stworzeniu zestawu tabel cieni, gdzie wszystkie wstawki kierowane są do nowej kopii tabeli (z większym typem danych), a istnienie dwóch zestawów tabel jest równie przejrzyste jak to możliwe dla aplikacji i jej użytkowników.
Na bardziej szczegółowym poziomie zestaw kroków byłby następujący:
- Utwórz kopie w tle tabel z odpowiednimi typami danych.
- Zmień procedury składowane (lub kod ad hoc), aby używać bigint dla parametrów. (Może to wymagać modyfikacji poza listą parametrów, takich jak zmienne lokalne, tabele tymczasowe itp., ale w tym przypadku tak nie jest.)
- Zmień nazwy starych tabel i utwórz widoki o tych nazwach, które łączą stare i nowe tabele.
- Te widoki będą miały zamiast wyzwalaczy odpowiednie kierowanie operacji DML do odpowiednich tabel, dzięki czemu dane mogą być nadal modyfikowane podczas migracji.
- Wymaga to również usunięcia SCHEMABINDING ze wszystkich indeksowanych widoków, istniejących widoków, aby mieć połączenie między nowymi i starymi tabelami, a także modyfikacji procedur opartych na SCOPE_IDENTITY().
- Przenieś stare dane do nowych tabel porcjami.
- Sprzątanie, składające się z:
- Porzucanie tymczasowych widoków (co spowoduje porzucenie wyzwalaczy ZAMIAST).
- Zmienianie nazw nowych tabel z powrotem na oryginalne.
- Naprawienie procedur składowanych, aby przywrócić SCOPE_IDENTITY().
- Upuszczanie starych, teraz pustych tabel.
- Przywracanie SCHEMABINDING do zindeksowanych widoków i ponowne tworzenie indeksów klastrowych.
Prawdopodobnie możesz uniknąć wielu widoków i wyzwalaczy, jeśli możesz kontrolować dostęp do wszystkich danych za pomocą procedur składowanych, ale ponieważ ten scenariusz jest rzadki (i nie można ufać w 100%), pokażę trudniejszą trasę.
Początkowy schemat
Aby to podejście było jak najprostsze, jednocześnie rozwiązując wiele blokerów, o których wspomniałem wcześniej w serii, załóżmy, że mamy następujący schemat:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Tak więc prosta tabela personelu z klastrowaną kolumną IDENTITY, indeksem nieklastrowym, kolumną obliczoną opartą na kolumnie IDENTITY, widokiem indeksowanym i oddzielną tabelą HR/brud, która ma klucz obcy z powrotem do tabeli personelu (I niekoniecznie zachęcam do tego projektu, po prostu używam go w tym przykładzie). To wszystko sprawia, że problem jest bardziej skomplikowany, niż byłoby, gdybyśmy mieli samodzielną, niezależną tabelę.
Mając ten schemat, prawdopodobnie mamy pewne procedury składowane, które wykonują takie rzeczy, jak CRUD. Są to bardziej ze względu na dokumentację niż cokolwiek; Zamierzam wprowadzić zmiany w podstawowym schemacie tak, aby zmiana tych procedur była minimalna. Ma to na celu symulację faktu, że zmiana ad hoc SQL z aplikacji może nie być możliwa i może nie być konieczna (no cóż, o ile nie używasz ORM, który może wykrywać tabelę w porównaniu z widokiem).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Teraz dodajmy 5 wierszy danych do oryginalnych tabel:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Krok 1 – nowe tabele
Tutaj utworzymy nową parę tabel, odzwierciedlającą oryginały z wyjątkiem typu danych kolumn EmployeeID, początkowego inicjatora kolumny IDENTITY i tymczasowego przyrostka nazw:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Krok 2 – napraw parametry procedury
Procedury tutaj (i potencjalnie twój kod ad hoc, chyba że używa już większego typu liczb całkowitych) będą wymagały bardzo niewielkiej zmiany, aby w przyszłości były w stanie akceptować wartości EmployeeID wykraczające poza górne granice liczby całkowitej. Chociaż możesz argumentować, że jeśli zamierzasz zmienić te procedury, możesz po prostu wskazać je na nowe tabele, staram się udowodnić, że możesz osiągnąć ostateczny cel przy *minimalnej* ingerencji w istniejące, stałe kod.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Krok 3 – widoki i wyzwalacze
Niestety, nie można *wszystko* zrobić po cichu. Większość operacji możemy wykonywać równolegle i bez wpływu na współbieżne użycie, ale ze względu na SCHEMABINDING, indeksowany widok musi zostać zmieniony, a indeks później odtworzony.
Odnosi się to do wszystkich innych obiektów, które używają SCHEMABINDING i odwołują się do jednej z naszych tabel. Polecam zmienić go na widok nieindeksowany na początku operacji i po prostu odbudować indeks raz po migracji wszystkich danych, a nie wielokrotnie w trakcie procesu (ponieważ nazwy tabel będą wielokrotnie zmieniane). W rzeczywistości zamierzam zmienić widok, aby połączyć nową i starą wersję tabeli Pracownicy na czas trwania procesu.
Jeszcze jedna rzecz, którą musimy zrobić, to zmienić procedurę składowaną Employee_Add tak, aby tymczasowo używała @@IDENTITY zamiast SCOPE_IDENTITY(). Dzieje się tak, ponieważ wyzwalacz INSTEAD OF, który będzie obsługiwał nowe aktualizacje „Pracowników”, nie będzie miał widoczności wartości SCOPE_IDENTITY(). To oczywiście zakłada, że tabele nie mają wyzwalaczy after, które będą miały wpływ na @@IDENTITY. Miejmy nadzieję, że możesz zmienić te zapytania wewnątrz procedury składowanej (gdzie możesz po prostu wskazać INSERT na nową tabelę) lub kod aplikacji nie musi w pierwszej kolejności polegać na SCOPE_IDENTITY().
Zrobimy to w opcji SERIALIZABLE, aby żadne transakcje nie próbowały się wkraść, gdy obiekty są w ruchu. Jest to zestaw operacji w dużej mierze opartych wyłącznie na metadanych, więc powinien być szybki.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Krok 4 – Przenieś stare dane do nowej tabeli
Zamierzamy migrować dane porcjami, aby zminimalizować wpływ zarówno na współbieżność, jak i dziennik transakcji, zapożyczając podstawową technikę ze starego mojego posta „Rozbijaj duże operacje usuwania na porcje”. Zamierzamy wykonać te partie również w SERIALIZABLE, co oznacza, że będziesz chciał być ostrożny z rozmiarem partii, a dla zwięzłości pominąłem obsługę błędów.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Wyniki:
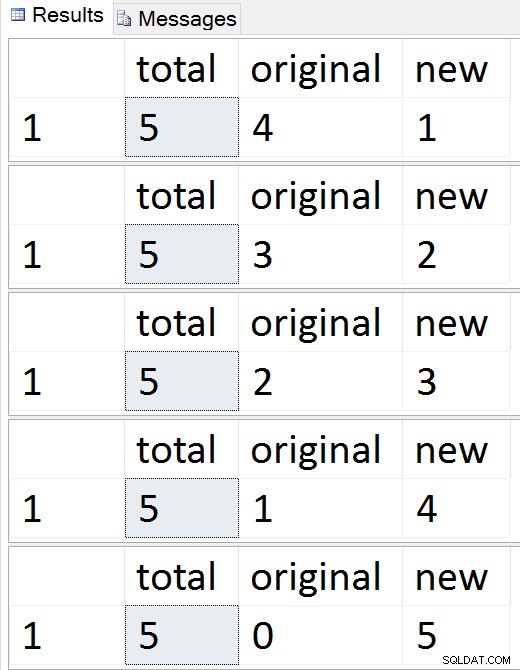 Zobacz migrację wierszy jeden po drugim
Zobacz migrację wierszy jeden po drugim
W dowolnym momencie tej sekwencji możesz testować wstawki, aktualizacje i usunięcia i należy je odpowiednio obsługiwać. Po zakończeniu migracji możesz przejść do pozostałej części procesu.
Krok 5 – Posprzątaj
Wymagana jest seria kroków, aby wyczyścić obiekty, które zostały tymczasowo utworzone i przywrócić Employees / EmployeeFile jako właściwych obywateli pierwszej klasy. Wiele z tych poleceń to po prostu operacje na metadanych – z wyjątkiem tworzenia indeksu klastrowego w widoku indeksowanym, wszystkie powinny być natychmiastowe.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO W tym momencie wszystko powinno wrócić do normalnego działania, chociaż warto rozważyć typowe czynności konserwacyjne po poważnych zmianach w schemacie, takie jak aktualizowanie statystyk, odbudowywanie indeksów lub usuwanie planów z pamięci podręcznej.
Wniosek
To dość złożone rozwiązanie tego, co powinno być prostym problemem. Mam nadzieję, że w pewnym momencie SQL Server umożliwi takie rzeczy jak dodanie/usunięcie właściwości IDENTITY, przebudowanie indeksów z nowymi docelowymi typami danych i zmianę kolumn po obu stronach relacji bez poświęcania relacji. W międzyczasie chciałbym usłyszeć, czy to rozwiązanie Ci pomoże, czy też masz inne podejście.
Wielkie podziękowania dla Jamesa Lupolta (@jlupoltsql) za pomoc w sprawdzeniu mojego podejścia i poddaniu go ostatecznemu testowi na jednym z jego własnych, prawdziwych stołów. (Poszło dobrze. Dzięki James!)
—
[ Część 1 | Część 2 | Część 3 | Część 4 ]