Zakładając, że możemy po prostu użyć start_date aby zidentyfikować sąsiednie rekordy (tj. Nie ma przerw), możesz użyć podejścia polegającego na różnicy numerów wierszy:
select id, min(start_date) as mn_date, max(end_date) as mx_date, rate
from (select t.*,
row_number() over (partition by id order by start_date) as seqnum_i,
row_number() over (partition by id, rate order by start_date) as seqnum_ir
from t
) t
group by id (seqnum_i - seqnum_ir), rate;
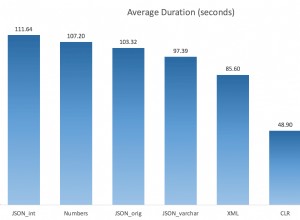
Aby zobaczyć, jak to działa, spójrz na wyniki podzapytania. Powinieneś być w stanie "zobaczyć", jak różnica dwóch numerów wierszy definiuje grupy sąsiednich rekordów z taką samą szybkością.