Dlaczego wykonanie zapytania zajmuje tyle czasu? Dlaczego nie ma indeksów? Prawdopodobnie słyszałeś o EXPLAIN w PostgreSQL. Jednak wciąż jest wiele osób, które nie mają pojęcia, jak z niego korzystać. Mam nadzieję, że ten artykuł pomoże użytkownikom poradzić sobie z tym wspaniałym narzędziem.
Ten artykuł jest autorską wersją Understanding EXPLAIN autorstwa Guillaume'a Lelarge'a. Ponieważ przegapiłem niektóre informacje, gorąco polecam zapoznanie się z oryginałem.
Diabeł nie jest tak czarny, jak go malują
Aby zoptymalizować zapytania, ważne jest zrozumienie logiki jądra PostgreSQL. Spróbuję wyjaśnić. To naprawdę nie jest takie skomplikowane.
EXPLAIN wyświetla niezbędne informacje, które wyjaśniają, co jądro robi dla każdego konkretnego zapytania.
Przyjrzyjmy się, co wyświetla polecenie EXPLAIN i zrozum, co dokładnie dzieje się w PostgreSQL. Możesz zastosować te informacje do PostgreSQL 9.2 i nowszych wersji.
Nasze zadania:
- Dowiedz się, jak czytać i rozumieć dane wyjściowe polecenia WYJAŚNIJ
- Zrozum, co dzieje się w PostgreSQL po wykonaniu zapytania
Pierwsze kroki
Będziemy ćwiczyć na stole testowym z milionem wierszy.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Spróbuj odczytać dane
EXPLAIN SELECT * FROM foo;
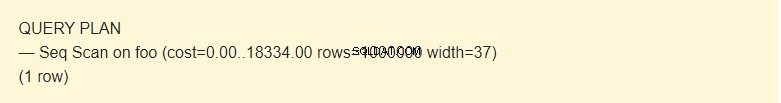
Dane z tabeli można odczytać na kilka sposobów. W naszym przypadku EXPLAIN powiadamia, że używane jest skanowanie sekwencyjne — sekwencyjne, odczytywane blok po bloku dane tabeli Foo.
Jaki jest koszt ?
Cóż, to nie czas, ale koncepcja mająca na celu oszacowanie kosztów operacji. Pierwsza wartość 0,00 to koszt uzyskania pierwszego wiersza. Druga wartość 18334,00 to koszt pobrania wszystkich wierszy.
Wiersze to przybliżona liczba wierszy zwracanych podczas wykonywania operacji Seq Scan. Program planujący zwraca tę wartość. W moim przypadku odpowiada rzeczywistej liczbie wierszy w tabeli.
Szerokość to średni rozmiar jednego wiersza w bajtach.
Spróbujmy dodać 10 wierszy.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

Wartość wierszy nie została zmieniona. Statystyki tabeli są stare. Aby zaktualizować statystyki, wywołaj polecenie ANALIZA.
Teraz wiersze wyświetl prawidłową liczbę wierszy.
Co się dzieje podczas wykonywania ANALIZY?
- Losowo, pewna liczba wierszy jest wybierana i odczytywana z tabeli.
- Zbierane są statystyki wartości według każdej kolumny.
Liczba wierszy odczytanych przez ANALIZĘ zależy od parametru default_statistics_target.
Rzeczywiste dane
Wszystko, co widzieliśmy powyżej w danych wyjściowych polecenia WYJAŚNIJ, jest tym, czego oczekuje planista. Spróbujmy porównać je z wynikami na rzeczywistych danych. Aby to zrobić, użyj opcji WYJAŚNIJ (ANALIZA).
EXPLAIN (ANALYZE) SELECT * FROM foo;

Takie zapytanie rzeczywiście zostanie wykonane. Tak więc, jeśli wykonasz EXPLAIN (ANALYZE) dla instrukcji INSERT, DELETE lub UPDATE, Twoje dane zostaną zmienione. Bądź ostrożny! W takich przypadkach użyj polecenia ROLLBACK.
Polecenie wyświetla następujące dodatkowe parametry:
- rzeczywisty czas to rzeczywisty czas w milisekundach poświęcony, odpowiednio, na uzyskanie pierwszego i wszystkich wierszy.
- wiersze to rzeczywista liczba wierszy otrzymanych przez Seq Scan.
- pętle to liczba razy, kiedy operacja Seq Scan musiała zostać wykonana.
- Całkowity czas działania to całkowity czas wykonania zapytania.
Dalsza lektura:
Optymalizacja zapytań w PostgreSQL. WYJAŚNIJ podstawy – część 2
Optymalizacja zapytań w PostgreSQL. WYJAŚNIJ podstawy – część 3



