Kilka lat temu (na pgconf.eu 2014 w Madrycie) przedstawiłem prelekcję zatytułowaną „Archeologia wydajności”, która pokazała, jak zmieniła się wydajność w ostatnich wydaniach PostgreSQL. Wygłosiłem ten wykład, ponieważ uważam, że perspektywa długoterminowa jest interesująca i może dać nam spostrzeżenia, które mogą być bardzo cenne. Dla osób, które faktycznie pracują nad kodem PostgreSQL, takich jak ja, jest to przydatny przewodnik dla przyszłego rozwoju, a dla użytkowników PostgreSQL może pomóc w ocenie aktualizacji.
Postanowiłem więc powtórzyć to ćwiczenie i napisać kilka wpisów na blogu analizujących wydajność dla kilku wersji PostgreSQL. W rozmowie z 2014 r. zacząłem od PostgreSQL 7.4, który w tamtym momencie miał około 10 lat (wydany w 2003 r.). Tym razem zacznę od PostgreSQL 8.3, który ma około 12 lat.
Dlaczego nie zacząć ponownie od PostgreSQL 7.4? Istnieją trzy główne powody, dla których zdecydowałem się zacząć od PostgreSQL 8.3. Po pierwsze, ogólne lenistwo. Im starsza wersja, tym trudniejsze może być budowanie przy użyciu aktualnych wersji kompilatorów itp. Po drugie, uruchomienie odpowiednich testów porównawczych zajmuje trochę czasu, zwłaszcza przy większych ilościach danych, więc dodanie jednej głównej wersji może z łatwością wydłużyć czas pracy komputera o kilka dni. Po prostu nie wydawało się tego warte. I wreszcie, w wersji 8.3 wprowadzono szereg ważnych zmian – ulepszenia automatycznego odkurzania (domyślnie włączone, współbieżne procesy robocze,…), wyszukiwanie pełnotekstowe zintegrowane z rdzeniem, punkty kontrolne rozproszenia i tak dalej. Myślę więc, że rozpoczęcie od PostgreSQL 8.3 ma sens. Który został wydany około 12 lat temu, więc to porównanie obejmie dłuższy okres czasu.
Postanowiłem przetestować trzy podstawowe typy obciążeń – OLTP, analitykę i wyszukiwanie pełnotekstowe. Myślę, że OLTP i analityka są dość oczywistymi wyborami, ponieważ większość aplikacji to mieszanka tych dwóch podstawowych typów. Wyszukiwanie pełnotekstowe pozwala mi zademonstrować ulepszenia w specjalnych typach indeksów, które są również używane do indeksowania popularnych typów danych, takich jak JSONB, typy używane przez PostGIS itp.
Dlaczego w ogóle to robisz?
Czy rzeczywiście jest to warte wysiłku? W końcu cały czas robimy benchmarki podczas tworzenia, aby pokazać, że łatka pomaga i/lub nie powoduje regresji, prawda? Problem polega na tym, że są to zazwyczaj tylko „częściowe” testy porównawcze, porównujące dwa konkretne zatwierdzenia i zwykle z dość ograniczonym wyborem obciążeń, które naszym zdaniem mogą być istotne. Co ma sens – po prostu nie możesz uruchomić pełnej baterii obciążeń dla każdego zatwierdzenia.
Raz na jakiś czas (zwykle niedługo po wydaniu nowej głównej wersji PostgreSQL) ludzie przeprowadzają testy porównujące nową wersję z poprzednią, co jest miłe i zachęcam do przeprowadzania takich benchmarków (czy to jakiś standardowy benchmark, czy coś specyficznego dla twojej aplikacji). Trudno jednak połączyć te wyniki z perspektywą długoterminową, ponieważ te testy wykorzystują różne konfiguracje i sprzęt (zwykle nowszy dla nowszej wersji) i tak dalej. Dlatego trudno jest ogólnie osądzić zmiany.
To samo dotyczy wydajności aplikacji, która jest oczywiście „ostatecznym punktem odniesienia”. Ale ludzie mogą nie aktualizować do każdej głównej wersji (czasami mogą pominąć kilka wersji, np. z 9.5 do 12). A kiedy się aktualizują, często łączy się to z aktualizacją sprzętu itp. Nie wspominając o tym, że aplikacje ewoluują z czasem (nowe funkcje, dodatkowa złożoność), ilość danych i liczba jednoczesnych użytkowników rośnie itp.
To właśnie stara się pokazać ta seria blogów – długoterminowe trendy w wydajności PostgreSQL dla niektórych podstawowych obciążeń, dzięki czemu my – programiści – mamy ciepłe i niejasne wrażenie na temat dobrej pracy na przestrzeni lat. Aby pokazać użytkownikom, że chociaż PostgreSQL jest w tym momencie dojrzałym produktem, nadal istnieją znaczne ulepszenia w każdej nowej głównej wersji.
Nie jest moim celem używanie tych benchmarków do porównywania z innymi produktami bazodanowymi lub uzyskiwania wyników spełniających jakiekolwiek oficjalne rankingi (takie jak TPC-H). Moim celem jest po prostu kształcenie się jako programista PostgreSQL, może identyfikowanie i badanie niektórych problemów oraz dzielenie się odkryciami z innymi.
Uczciwe porównanie?
Nie sądzę, żeby takie porównania wersji wydanych na przestrzeni 12 lat nie były do końca uczciwe, ponieważ każde oprogramowanie jest tworzone w konkretnym kontekście – dobrym przykładem dla systemu bazodanowego jest sprzęt. Jeśli spojrzysz na maszyny, których używałeś 12 lat temu, ile miały rdzeni, ile pamięci RAM? Jakiego rodzaju pamięci używali?
Typowy serwer klasy średniej w 2008 roku miał może 8-12 rdzeni, 16 GB pamięci RAM i RAID z kilkoma dyskami SAS. Dzisiejszy typowy serwer klasy średniej może mieć kilkadziesiąt rdzeni, setki GB pamięci RAM i dysk SSD.
Tworzenie oprogramowania jest zorganizowane według priorytetów – zawsze jest więcej potencjalnych zadań, niż masz na to czasu, więc musisz wybrać zadania o najlepszym stosunku kosztów do korzyści dla swoich użytkowników (zwłaszcza tych, którzy bezpośrednio lub pośrednio finansują projekt). A w 2008 roku niektóre optymalizacje prawdopodobnie nie były jeszcze istotne – większość maszyn nie miała ekstremalnych ilości pamięci RAM, więc na przykład optymalizacja pod kątem dużych współdzielonych buforów nie była tego warta. Wiele wąskich gardeł procesora zostało przyćmionych przez I/O, ponieważ większość maszyn miała pamięć masową „wirującą rdzą”.
Uwaga:Oczywiście, już wtedy byli klienci używający całkiem dużych maszyn. Niektórzy używali Postgresa społecznościowego z różnymi poprawkami, inni zdecydowali się uruchomić z jednym z różnych forków Postgresa z dodatkowymi możliwościami (np. Masywna równoległość, zapytania rozproszone, używanie FPGA itp.). I to oczywiście wpłynęło również na rozwój społeczności.
Ponieważ z biegiem lat większe maszyny stały się bardziej popularne, więcej osób mogło pozwolić sobie na maszyny z dużą ilością pamięci RAM i dużą liczbą rdzeni, zmieniając stosunek kosztów do korzyści. Wąskie gardła zostały zbadane i rozwiązane, co pozwoliło nowszym wersjom działać lepiej.
Oznacza to, że taki benchmark jest zawsze trochę niesprawiedliwy – będzie faworyzował starszą lub nowszą wersję, w zależności od konfiguracji (sprzęt, konfiguracja). Próbowałem jednak wybrać parametry sprzętowe i konfiguracyjne, aby nie było tak źle dla starszych wersji.
Chodzi mi o to, że nie oznacza to, że starsze wersje PostgreSQL były gówniane – tak działa tworzenie oprogramowania. Zajmujesz się wąskimi gardłami, które mogą napotkać Twoi użytkownicy, a nie wąskimi gardłami, które mogą napotkać za 10 lat.
Sprzęt
Wolę robić testy porównawcze na fizycznym sprzęcie, do którego mam bezpośredni dostęp, ponieważ pozwala mi to kontrolować wszystkie szczegóły, mam dostęp do wszystkich szczegółów i tak dalej. Więc użyłem maszyny, którą mam w naszym biurze – nic wymyślnego, ale mam nadzieję, że wystarczająco dobre do tego celu.
- 2x E5-2620 v4 (16 rdzeni, 32 wątki)
- 64 GB pamięci RAM
- Intel Optane 900P 280 GB NVMe SSD (dane)
- 3 x 7,2 tys. SATA RAID0 (tymczasowy obszar tabel)
- jądro 5.6.15, ext4
- gcc 9.2.0, klang 9.0.1
Użyłem również drugiej – znacznie mniejszej – maszyny, z zaledwie 4 rdzeniami i 8 GB pamięci RAM, która generalnie wykazuje te same ulepszenia/regresje, tylko mniej wyraźne.
pgbench
Jako narzędzie do benchmarkingu wykorzystałem dobrze znany pgbench, używając najnowszej wersji (z PostgreSQL 13) do testowania wszystkich wersji. Eliminuje to możliwe odchylenia spowodowane optymalizacjami przeprowadzanymi w pgbench w czasie, dzięki czemu wyniki są bardziej porównywalne.
Test porównawczy testuje wiele różnych przypadków, zmieniając szereg parametrów, a mianowicie:
skala
- małe – dane mieszczą się we wspólnych buforach, pokazując problemy z blokowaniem itp.
- średni – dane większe niż współdzielone bufory, ale mieszczą się w pamięci RAM, zwykle związane z procesorem (lub ewentualnie I/O dla obciążeń odczytu i zapisu)
- duży – dane większe niż RAM, głównie związane z I/O
tryby
- tylko do odczytu – pgbench -S
- odczyt-zapis – pgbench -N
liczba klientów
- 1, 4, 8, 16, 32, 64, 128, 256
- liczba wątków pgbench (-j) jest odpowiednio dostosowywana
Wyniki
OK, spójrzmy na wyniki. Najpierw przedstawię wyniki z pamięci masowej NVMe, a następnie pokażę kilka interesujących wyników przy użyciu pamięci masowej SATA RAID.
SSD NVMe / tylko do odczytu
Dla małego zestawu danych (który w pełni pasuje do wspólnych buforów) wyniki tylko do odczytu wyglądają tak:
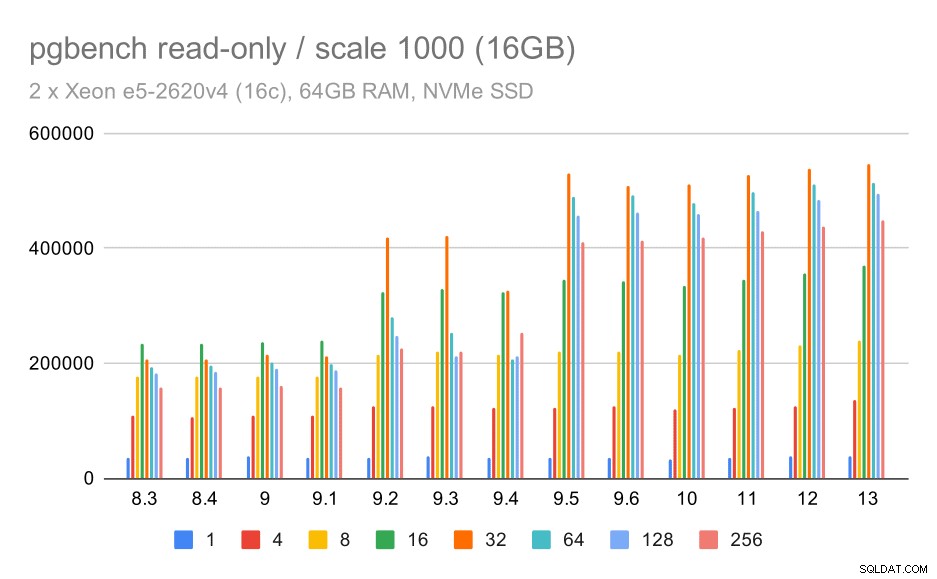
wyniki pgbench / tylko do odczytu na małym zestawie danych (skala 100, tj. 1,6 GB)
Wyraźnie widać, że w wersji 9.2 nastąpił znaczny wzrost przepustowości, która zawierała szereg ulepszeń wydajności, na przykład szybką ścieżkę blokowania. Przepustowość dla pojedynczego klienta faktycznie spada – z 47 tys. tps do zaledwie około 42 tys. Ale dla większej liczby klientów poprawa w wersji 9.2 jest całkiem jasna.
wyniki pgbench / tylko do odczytu na średnim zestawie danych (skala 1000, tj. 16 GB)
W przypadku średniego zestawu danych (który jest większy niż wspólne bufory, ale nadal mieści się w pamięci RAM) wydaje się, że nastąpiła pewna poprawa w wersji 9.2, chociaż nie tak wyraźna jak powyżej, a następnie znacznie wyraźniejsza poprawa w wersji 9.5, najprawdopodobniej dzięki ulepszeniom skalowalności blokady .
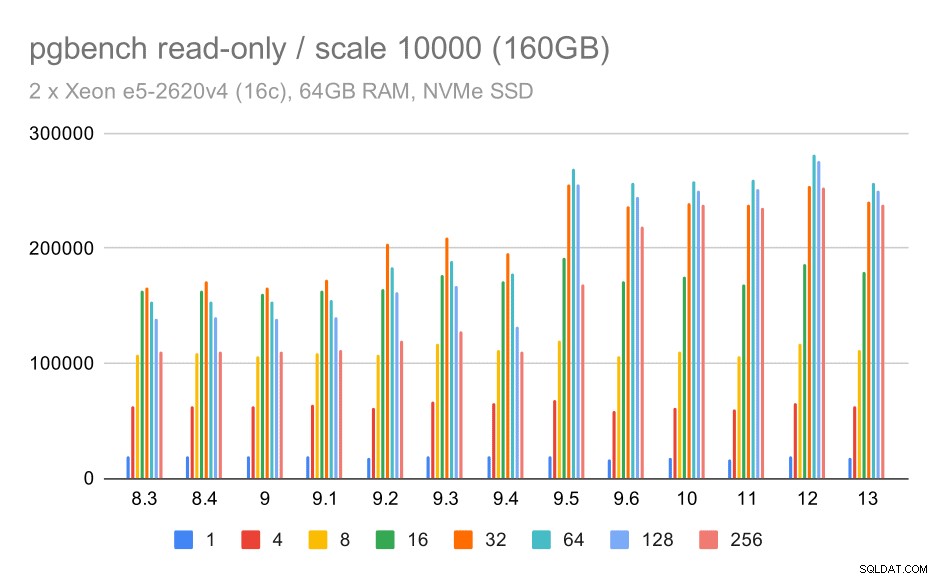
wyniki pgbench / tylko do odczytu na dużym zbiorze danych (skala 10000, tj. 160 GB)
W przypadku największego zestawu danych, który dotyczy głównie możliwości efektywnego wykorzystania pamięci, jest również pewne przyspieszenie – najprawdopodobniej także dzięki ulepszeniom 9.5.
NVMe SSD / odczyt-zapis
Wyniki odczytu i zapisu również wykazują pewną poprawę, chociaż nie tak wyraźną. Na małym zestawie danych wyniki wyglądają tak:
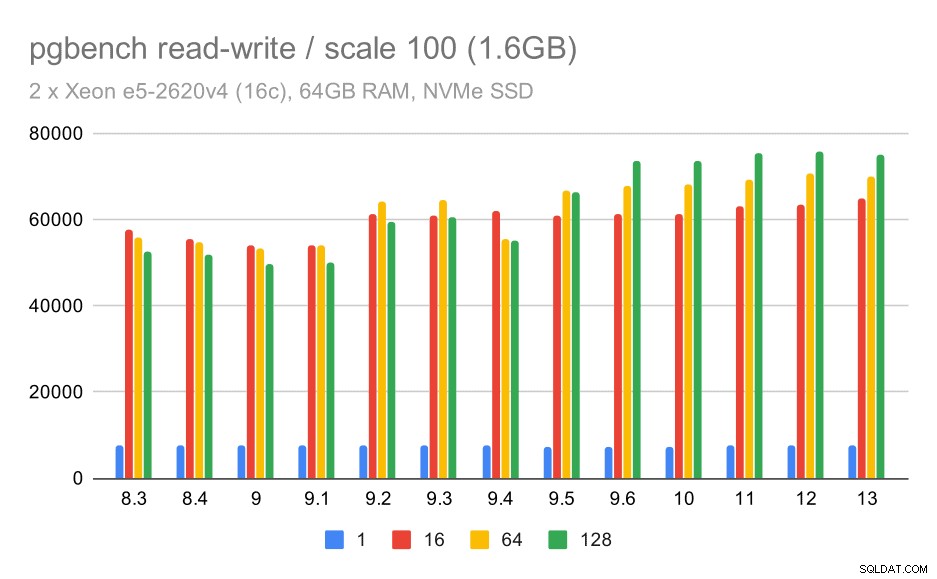
wyniki pgbench / odczyt-zapis na małym zestawie danych (skala 100, tj. 1,6 GB)
Zatem skromna poprawa z około 52 tys. do 75 tys. tps przy wystarczającej liczbie klientów.
W przypadku średniego zestawu danych poprawa jest znacznie wyraźniejsza – od około 27 tys. do 63 tys. tps, czyli przepustowość ponad dwukrotnie.
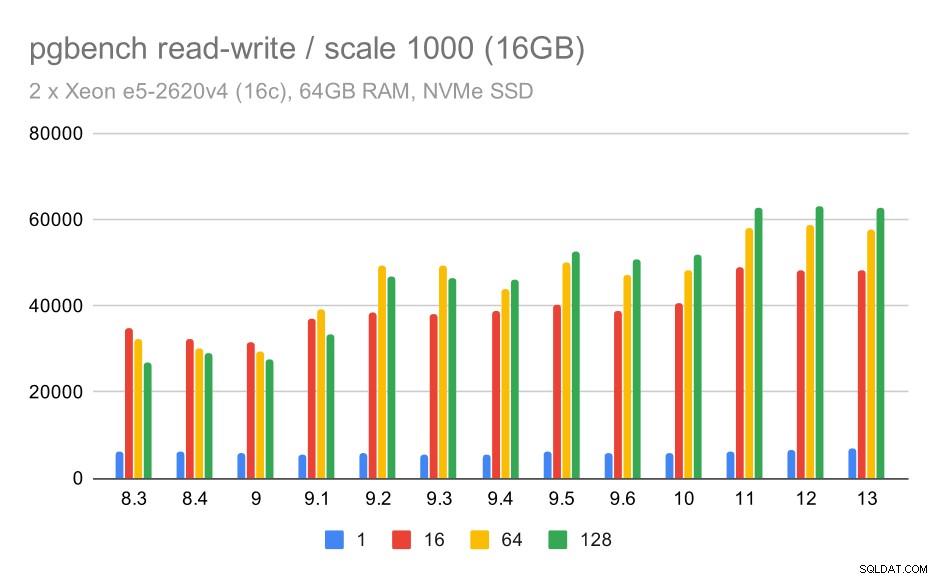
wyniki pgbench / odczyt-zapis na średnim zestawie danych (skala 1000, tj. 16 GB)
W przypadku największego zestawu danych widzimy podobną ogólną poprawę, ale wydaje się, że istnieje pewna regresja między 9,5 a 11.
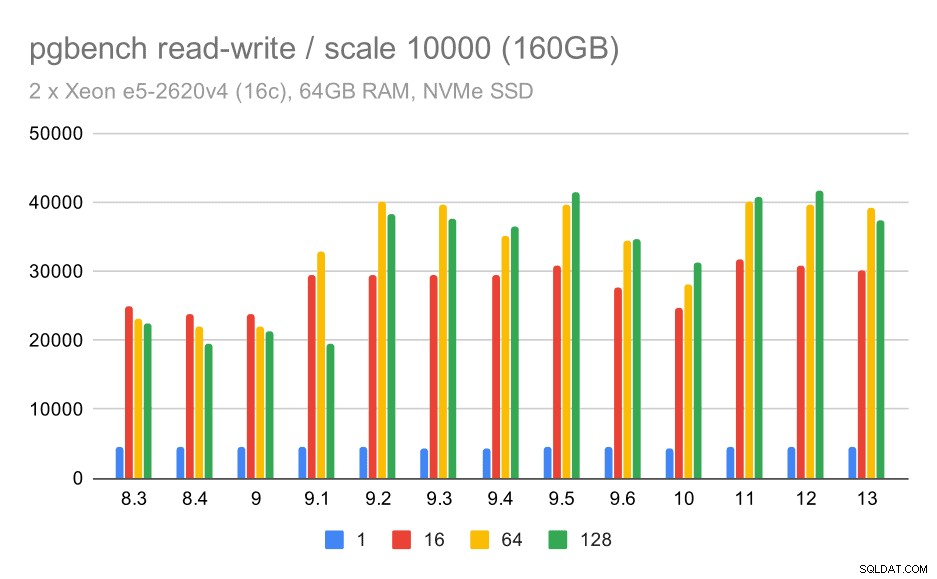
wyniki pgbench / odczyt-zapis na dużym zbiorze danych (skala 10000, tj. 160 GB)
SATA RAID / tylko do odczytu
W przypadku pamięci masowej SATA RAID wyniki tylko do odczytu nie są tak dobre. Możemy pominąć małe i średnie zbiory danych, dla których system przechowywania nie ma znaczenia. W przypadku dużego zestawu danych przepustowość jest nieco głośna, ale wydaje się, że z biegiem czasu faktycznie spada – szczególnie od czasu PostgreSQL 9.6. Nie wiem, jaki jest tego powód (nic w informacjach o wydaniu 9.6 nie wyróżnia się tak, jak wyraźny kandydat), ale wydaje się, że to jakiś rodzaj regresji.
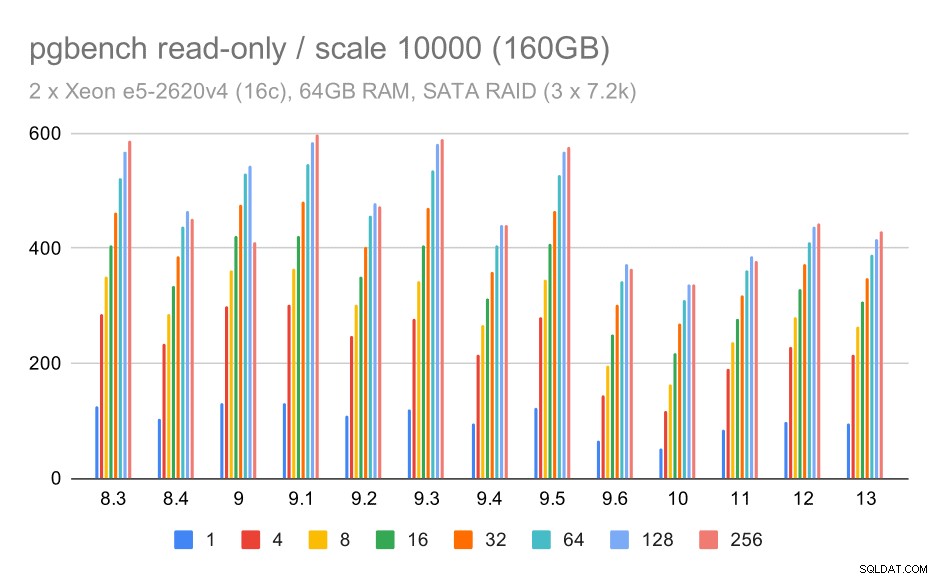
wyniki pgbench na SATA RAID / tylko do odczytu na dużym zestawie danych (skala 10000, tj. 160 GB)
SATA RAID / odczyt-zapis
Zachowanie odczytu i zapisu wydaje się jednak znacznie przyjemniejsze. Na małym zestawie danych przepustowość wzrasta z około 600 tps do ponad 6000 tps. Założę się, że dzieje się tak dzięki ulepszeniom zatwierdzania grupowego w wersjach 9.1 i 9.2.
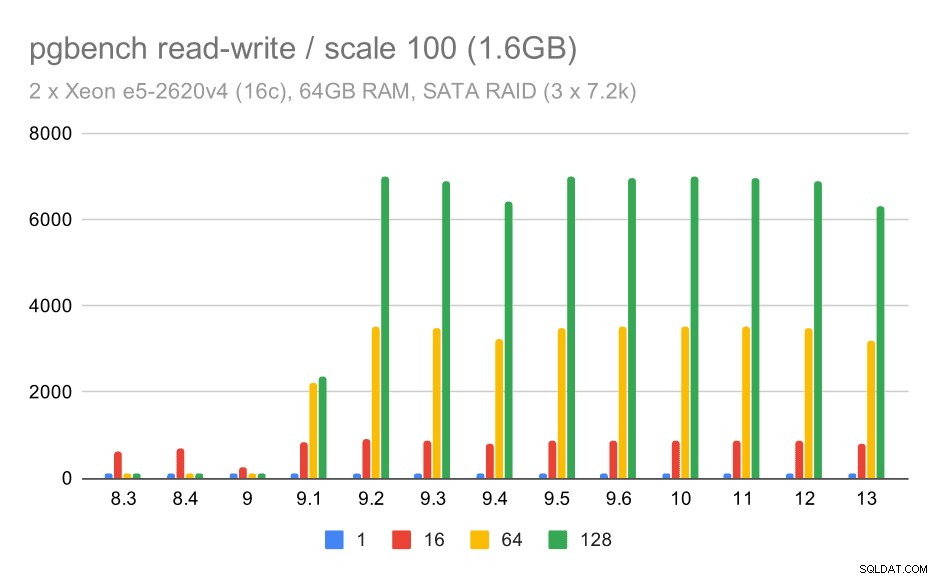
wyniki pgbench na SATA RAID / odczyt-zapis na małym zestawie danych (skala 100, tj. 1,6 GB)
W przypadku średniej i dużej skali widzimy podobną – ale mniejszą – poprawę, ponieważ pamięć masowa musi również obsługiwać żądania I/O dotyczące odczytu i zapisu bloków danych. W przypadku średniej skali wystarczy wykonać zapisy (ponieważ dane mieszczą się w pamięci RAM), w przypadku dużej skali musimy również wykonać odczyty – więc maksymalna przepustowość jest jeszcze niższa.
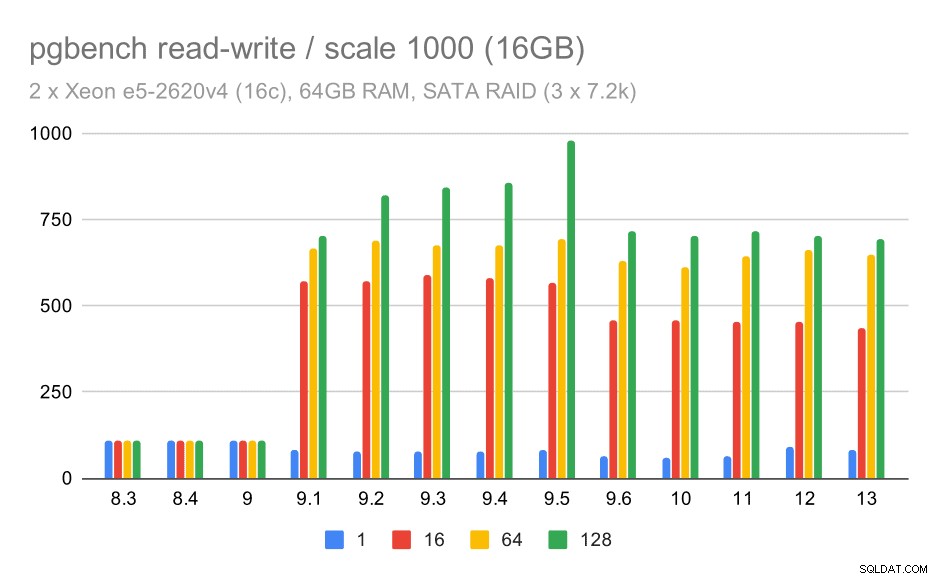
pgbench wyniki na SATA RAID / odczyt-zapis na średnim zestawie danych (skala 1000, tj. 16 GB)
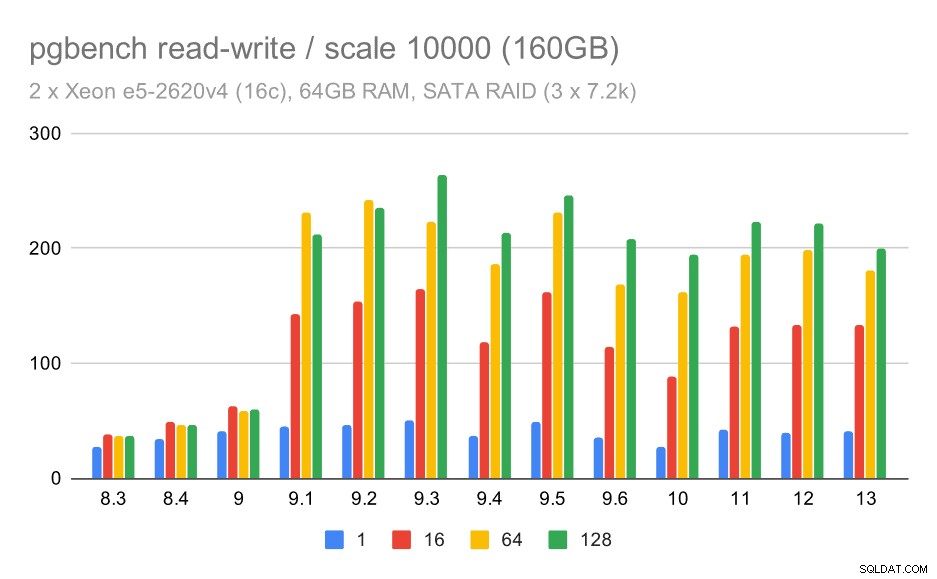
pgbench wyniki na SATA RAID / odczyt-zapis na dużym zestawie danych (skala 10000, tj. 160 GB)
Podsumowanie i przyszłość
Podsumowując, w przypadku konfiguracji NVMe wnioski wydają się całkiem pozytywne. W przypadku obciążenia tylko do odczytu istnieje umiarkowane przyspieszenie w wersji 9.2 i znaczne przyspieszenie w wersji 9.5, dzięki optymalizacji skalowalności, podczas gdy w przypadku obciążenia do odczytu i zapisu wydajność poprawiła się około 2 razy w czasie, w wielu wersjach / krokach.
W przypadku konfiguracji SATA RAID wnioski są jednak nieco mieszane. W przypadku obciążenia tylko do odczytu występuje duża zmienność / szum i możliwa regresja w wersji 9.6. W przypadku obciążenia odczytu i zapisu w wersji 9.1 nastąpiło ogromne przyspieszenie, w którym przepustowość nagle wzrosła ze 100 tps do około 600 tps.
A co z ulepszeniami w przyszłych wersjach PostgreSQL? Nie mam jasnego pojęcia, jaka będzie następna duża poprawa — jestem jednak pewien, że inni hakerzy PostgreSQL wpadną na genialne pomysły, które usprawnią działanie lub pozwolą wykorzystać dostępne zasoby sprzętowe. Przykładami takich ulepszeń są łata poprawiająca skalowalność wielu połączeń lub łatka dodająca obsługę nieulotnych buforów WAL. Możemy zobaczyć radykalne ulepszenia w zakresie przechowywania PostgreSQL (bardziej wydajny format na dysku, użycie bezpośredniego we/wy itp.), indeksowanie itp.