Ostatnio pojawiło się to kilka razy, zarówno na listach dyskusyjnych SO, jak i na listach dyskusyjnych PostgreSQL.
TL;DR za ostatnie dwa punkty:
(a) Większe shared_buffers mogą być przyczyną wolniejszego działania funkcji TRUNCATE na serwerze CI. Inna konfiguracja fsync lub użycie nośników rotacyjnych zamiast dysków SSD może również być wadą.
(b) TRUNCATE ma stały koszt, ale niekoniecznie wolniej niż DELETE , a ponadto wykonuje więcej pracy. Zobacz szczegółowe wyjaśnienie poniżej.
AKTUALIZACJA: Z tego posta wywiązała się ważna dyskusja na temat wydajności pgsql. Zobacz ten wątek.
AKTUALIZACJA 2: Do wersji 9.2beta3 dodano ulepszenia, które powinny w tym pomóc, zobacz ten post.
Szczegółowe wyjaśnienie TRUNCATE vs DELETE FROM :
Chociaż nie jestem ekspertem w tym temacie, rozumiem, że TRUNCATE ma prawie stały koszt na tabelę, podczas gdy DELETE wynosi co najmniej O(n) dla n wierszy; gorzej, jeśli istnieją jakiekolwiek klucze obce odwołujące się do usuwanej tabeli.
Zawsze zakładałem, że stały koszt TRUNCATE był niższy niż koszt DELETE na prawie pustym stole, ale to wcale nie jest prawda.
TRUNCATE table; robi więcej niż DELETE FROM table;
Stan bazy danych po TRUNCATE table jest prawie taki sam, jak gdybyś zamiast tego uruchomił:
DELETE FROM table;VACCUUM (FULL, ANALYZE) table;(tylko 9.0+, patrz przypis)
... choć oczywiście TRUNCATE w rzeczywistości nie osiąga swoich efektów za pomocą DELETE i VACUUM .
Chodzi o to, że DELETE i TRUNCATE rób różne rzeczy, więc nie porównujesz tylko dwóch poleceń z identycznymi wynikami.
Tabela DELETE FROM table; pozwala na pozostawanie martwych wierszy i rozrostu, umożliwia indeksom przenoszenie martwych wpisów, nie aktualizuje statystyk tabeli używanych przez planer zapytań itp.
TRUNCATE daje zupełnie nową tabelę i indeksy tak, jakby były po prostu CREATE wyd. To tak, jakbyś usunął wszystkie rekordy, ponownie zindeksował tabelę i wykonał VACUUM FULL .
Jeśli nie dbasz o to, czy w tabeli zostało resztki, ponieważ masz zamiar wypełnić ją ponownie, może być lepiej, gdy użyjesz DELETE FROM table; .
Ponieważ nie używasz VACUUM przekonasz się, że martwe wiersze i wpisy indeksu gromadzą się jako rozdęcie, które należy przeskanować, a następnie zignorować; to spowalnia wszystkie zapytania. Jeśli twoje testy w rzeczywistości nie tworzą i nie usuwają tak wielu danych, których możesz nie zauważyć lub nie obchodzić, i zawsze możesz wykonać VACUUM lub dwie w połowie testu, jeśli to zrobisz. Lepiej, niech agresywne ustawienia automatycznego odkurzania zapewnią, że autoodkurzacz zrobi to za Ciebie w tle.
Nadal możesz TRUNCATE wszystkie Twoje stoły po całości zestaw testowy uruchamia się, aby upewnić się, że w wielu uruchomieniach nie narastają żadne efekty. W wersji 9.0 i nowszych VACUUM (FULL, ANALYZE) table; globalnie na stole jest co najmniej tak samo dobre, jeśli nie lepsze, i jest o wiele łatwiejsze.
IIRC Pg ma kilka optymalizacji, co oznacza, że może zauważyć, że Twoja transakcja jest jedyną, która widzi tabelę i od razu oznacza bloki jako wolne. W testach, gdy chciałem stworzyć wzdęcie, musiałem mieć więcej niż jedno jednoczesne połączenie, aby to zrobić. Nie polegałbym jednak na tym.
DELETE FROM table; jest bardzo tani dla małych stołów bez referencji f/k
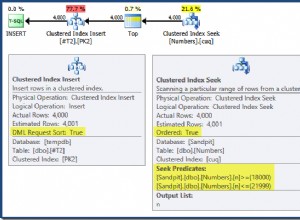
Aby DELETE wszystkie rekordy z tabeli bez odniesień do klucza obcego, wszystkie Pg muszą wykonać sekwencyjne skanowanie tabeli i ustawić xmax napotkanych krotek. Jest to bardzo tania operacja - w zasadzie odczyt liniowy i zapis półliniowy. AFAIK nie musi dotykać indeksów; nadal wskazują martwe krotki, dopóki nie zostaną oczyszczone przez późniejszą VACUUM oznacza to również bloki w tabeli zawierające tylko martwe krotki jako wolne.
DELETE drożeje tylko wtedy, gdy jest dużo rekordów, jeśli istnieje wiele odwołań do kluczy obcych, które należy sprawdzić, lub jeśli policzysz kolejną tabelę VACUUM (FULL, ANALYZE) table; potrzebne do dopasowania TRUNCATE efekty w ramach kosztu DELETE .
W moich testach tutaj, tabela DELETE FROM table; był zazwyczaj 4x szybszy niż TRUNCATE przy 0.5ms vs 2ms. To jest testowa baza danych na dysku SSD, działająca z fsync=off ponieważ nie obchodzi mnie, czy stracę wszystkie te dane. Oczywiście DELETE FROM table; nie wykonuje tej samej pracy, a jeśli pójdę z tabelą VACUUM (FULL, ANALYZE) table; to znacznie droższe 21 ms, więc DELETE jest wygrana tylko wtedy, gdy właściwie nie potrzebuję nieskazitelnego stołu.
TRUNCATE table; wykonuje o wiele więcej prac i sprzątania o stałych kosztach niż DELETE
Natomiast TRUNCATE musi wykonać dużo pracy. Musi alokować nowe pliki dla tabeli, jej tabelę TOAST, jeśli taka istnieje, oraz każdy indeks, jaki ma ta tabela. Nagłówki muszą być zapisane w tych plikach, a katalogi systemowe również mogą wymagać aktualizacji (nie jestem pewien w tym punkcie, nie sprawdzałem). Następnie musi zastąpić stare pliki nowymi lub usunąć stare i upewnić się, że system plików dogonił zmiany za pomocą operacji synchronizacji — fsync() lub podobnej — która zwykle opróżnia wszystkie bufory na dysk . Nie jestem pewien, czy synchronizacja jest pomijana, jeśli korzystasz z opcji (zjadanie danych) fsync=off .
Niedawno dowiedziałem się, że TRUNCATE musi także opróżnić wszystkie bufory PostgreSQL związane ze starą tabelą. Może to zająć nietrywialną ilość czasu z ogromnymi shared_buffers . Podejrzewam, że właśnie dlatego działa wolniej na twoim serwerze CI.
Saldo
W każdym razie widać, że TRUNCATE tabeli, która ma powiązaną tabelę TOAST (większość tak) i kilka indeksów może zająć kilka chwil. Niedługo, ale dłużej niż DELETE z prawie pustego stołu.
W związku z tym może być lepiej, jeśli zrobisz DELETE FROM table; .
--
Uwaga:w bazach danych starszych niż 9.0, CLUSTER table_id_seq ON table; ANALYZE table; lub VACUUM FULL ANALYZE table; REINDEX table; byłby bliższym odpowiednikiem TRUNCATE . VACUUM FULL impl zmieniono na znacznie lepszą w wersji 9.0.