Tak jak to masz, podobieństwo między każdym elementem a każdym innym elementem tabeli musi być obliczone (prawie sprzężenie krzyżowe). Jeśli Twoja tabela ma 1000 wierszy, to już 1 000 000 (!) obliczeń podobieństwa, przed można je sprawdzić pod kątem stanu i posortować. Skaluje się strasznie.
Użyj SET pg_trgm.similarity_threshold i % zamiast tego operatora. Oba są dostarczane przez pg_trgm moduł. W ten sposób trigramowy indeks GiST może być używany z doskonałym skutkiem.
Parametr konfiguracyjny pg_trgm.similarity_threshold zastąpiono funkcje set_limit() i show_limit() w Postgresie 9.6. Przestarzałe funkcje nadal działają (stan na Postgres 13). Ponadto wydajność indeksów GIN i GiST poprawiła się na wiele sposobów od czasu Postgres 9.1.
Spróbuj zamiast tego:
SET pg_trgm.similarity_threshold = 0.8; -- Postgres 9.6 or later
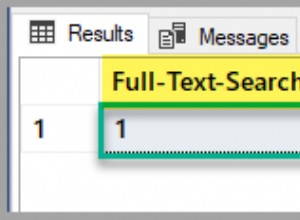
SELECT similarity(n1.name, n2.name) AS sim, n1.name, n2.name
FROM names n1
JOIN names n2 ON n1.name <> n2.name
AND n1.name % n2.name
ORDER BY sim DESC;
Szybciej o rzędy wielkości, ale wciąż wolno.
pg_trgm.similarity_threshold to opcja „dostosowana”, którą można obsługiwać jak każdą inną opcję. Zobacz:
- Zapytaj parametr (ustawienie postgresql.conf), np. „max_connections”
Możesz ograniczyć liczbę możliwych par, dodając warunki wstępne (takie jak dopasowanie pierwszych liter) przed łączenie krzyżowe (i obsługuje to za pomocą pasującego indeksu funkcjonalnego). Wydajność połączenia krzyżowego pogarsza się z O(N²) .
To nie działa ponieważ nie możesz odwoływać się do kolumn wyjściowych w WHERE lub HAVING klauzule:
WHERE ... sim > 0.8
Jest to zgodne ze standardem SQL (który jest obsługiwany dość luźno przez niektóre inne RDBMS). Z drugiej strony:
ORDER BY sim DESC
Działa ponieważ kolumny wyjściowe mogą być używane w GROUP BY i ORDER BY . Zobacz:
- Ponowne użycie wyniku obliczeń PostgreSQL w zapytaniu wybierającym
Przypadek testowy
Przeprowadziłem szybki test na moim starym serwerze testowym, aby zweryfikować moje roszczenia.
PostgreSQL 9.1.4. Czasy zrobione za pomocą EXPLAIN ANALYZE (najlepszy z 5).
CREATE TEMP table t AS
SELECT some_col AS name FROM some_table LIMIT 1000; -- real life test strings
Pierwsza runda testów z indeksem GIN:
CREATE INDEX t_gin ON t USING gin(name gin_trgm_ops); -- round1: with GIN index
Druga runda testów z indeksem GIST:
DROP INDEX t_gin;
CREATE INDEX t_gist ON t USING gist(name gist_trgm_ops);
Nowe zapytanie:
SELECT set_limit(0.8);
SELECT similarity(n1.name, n2.name) AS sim, n1.name, n2.name
FROM t n1
JOIN t n2 ON n1.name <> n2.name
AND n1.name % n2.name
ORDER BY sim DESC;
Użyty indeks GIN, 64 trafienia:całkowity czas działania:484,022 ms
Użyty indeks GIST, 64 trafienia:całkowity czas działania:248.772 ms
Stare zapytanie:
SELECT (similarity(n1.name, n2.name)) as sim, n1.name, n2.name
FROM t n1, t n2
WHERE n1.name != n2.name
AND similarity(n1.name, n2.name) > 0.8
ORDER BY sim DESC;
Indeks WZ nie wykorzystano, 64 trafienia:całkowity czas działania:6345.833 ms
Indeks GIST nie wykorzystany, 64 trafienia:całkowity czas działania:6335.975 ms
W przeciwnym razie identyczne wyniki. Rada jest dobra. A to dotyczy tylko 1000 wierszy !
GIN czy GiST?
GIN często zapewnia doskonałą wydajność odczytu:
- Różnica między indeksem GiST i GIN
Ale nie w tym konkretnym przypadku!
Można to dość skutecznie zaimplementować za pomocą indeksów GiST, ale nie indeksów GIN.
- Wielokolumnowy indeks na 3 polach z heterogenicznymi typami danych