Najprostszy i najczystszy sposób na Spring Boot 2.x z Heroku i Postgres
Przeczytałem wszystkie odpowiedzi, ale nie znalazłem tego, czego szukał Jonik:
Szukam najprostszego, najczystszego sposobu łączenia się z HerokuPostgres w aplikacji Spring Boot przy użyciu JPA/Hibernacji
Proces rozwoju, którego większość ludzi chce używać z Spring Boot &Heroku, obejmuje lokalną bazę danych H2 w pamięci do testowania i szybkich cykli rozwoju – oraz bazę danych Heroku Postgres do testowania i produkcji w Heroku.
- Po pierwsze – nie musisz do tego używać profili Spring!
- Po drugie:nie musisz pisać/zmieniać żadnego kodu!
Przyjrzyjmy się krok po kroku, co musimy zrobić. Mam przykładowy projekt, który zapewnia w pełni działające wdrożenie i konfigurację Heroku dla Postgresa - tylko ze względu na kompletność, jeśli chcesz sam to przetestować:github.com/jonashackt/spring-boot-vuejs.
Pom.xml
Potrzebujemy następujących zależności:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- In-Memory database used for local development & testing -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<!-- Switch back from Spring Boot 2.x standard HikariCP to Tomcat JDBC,
configured later in Heroku (see https://stackoverflow.com/a/49970142/4964553) -->
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jdbc</artifactId>
</dependency>
<!-- PostgreSQL used in Staging and Production environment, e.g. on Heroku -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.2</version>
</dependency>
Jedną trudną rzeczą jest użycie tomcat-jdbc , ale omówimy to za sekundę.
Konfiguruj zmienne środowiskowe w Heroku
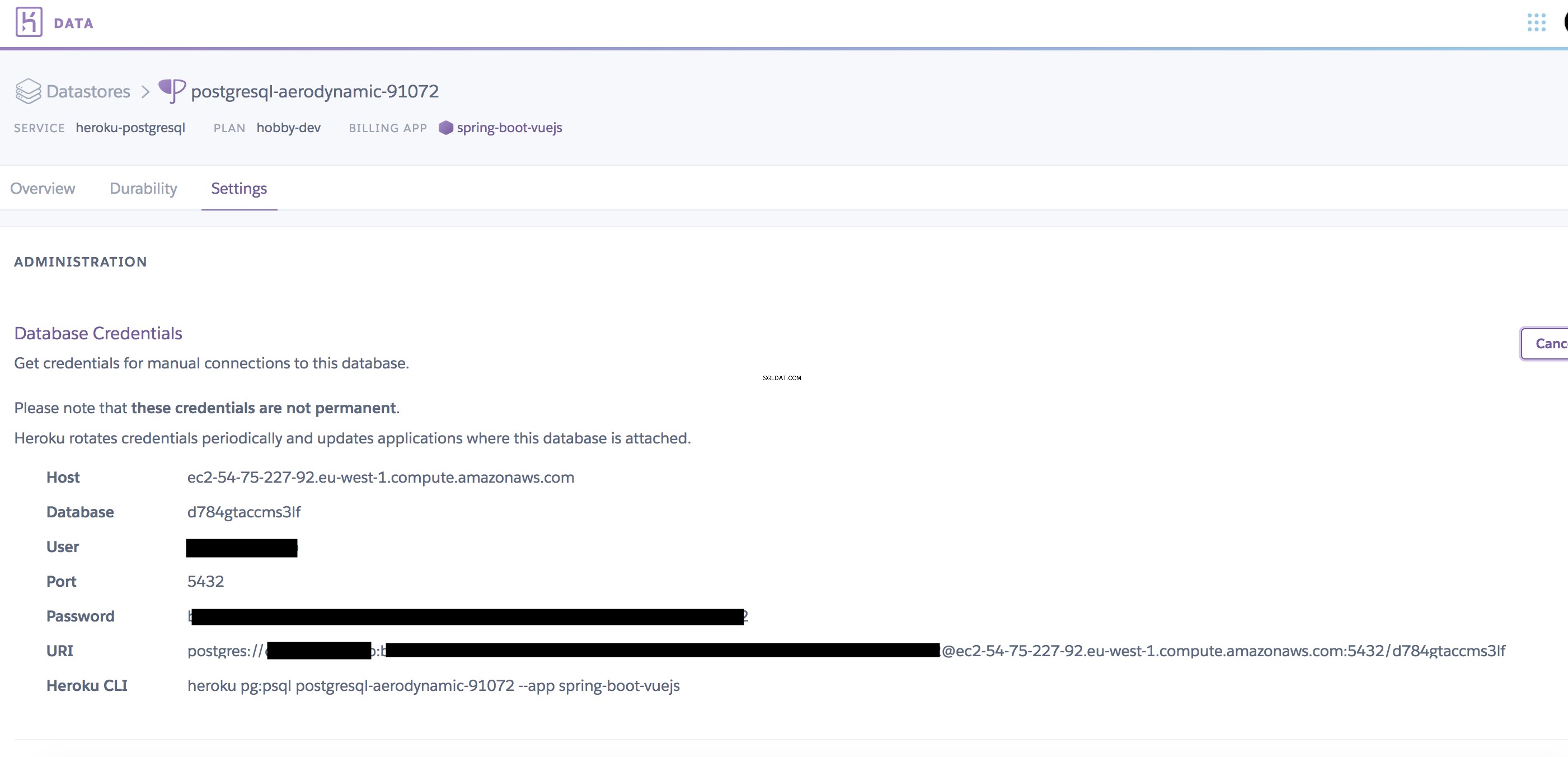
W Heroku zmienne środowiskowe nazywają się Config Vars . Dobrze słyszałeś, wszystko, co musimy zrobić, to skonfigurować zmienne środowiskowe! Potrzebujemy tylko właściwych. Dlatego przejdź do https://data.heroku.com/ (zakładam, że istnieje już baza danych Postgres skonfigurowana dla twojej aplikacji Heroku, co jest zachowaniem domyślnym).
Teraz kliknij odpowiedni Datastore swojej aplikacji i przejdź do Settings patka. Następnie kliknij View Credentials... , który powinien wyglądać podobnie do tego:
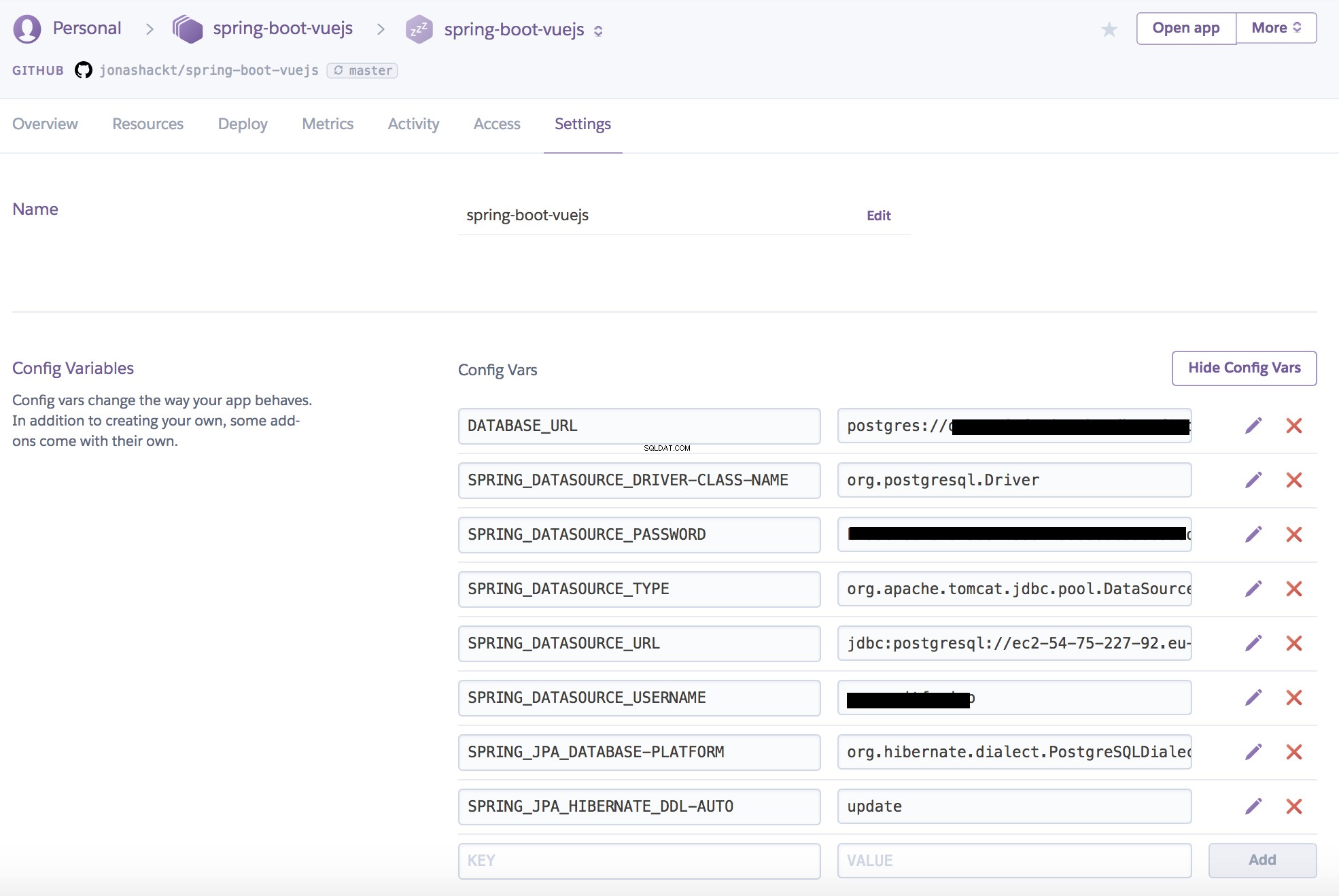
Teraz otwórz nową kartę przeglądarki i przejdź do Settings aplikacji Heroku zakładka również. Kliknij Reveal Config Vars i utwórz następujące zmienne środowiskowe:
SPRING_DATASOURCE_URL=jdbc :postgresql ://TwójPostgresHerokuHostNameHere :5432/Twoja baza danychPostgresHerokuNameHere (uwaga na wiodącyjdbc:iqldodatek dopostgres!)SPRING_DATASOURCE_USERNAME=YourPostgresHerokuUserNameHereSPRING_DATASOURCE_PASSWORD=YourPostgresHerokuPasswordHereSPRING_DATASOURCE_DRIVER-CLASS-NAME=org.postgresql.Driver(nie zawsze jest to potrzebne, ponieważ Spring Boot może to wywnioskować dla większości baz danych z adresu URL, tylko dla kompletności tutaj)SPRING_JPA_DATABASE-PLATFORM=org.hibernate.dialect.PostgreSQLDialectSPRING_DATASOURCE_TYPE=org.apache.tomcat.jdbc.pool.DataSourceSPRING_JPA_HIBERNATE_DDL-AUTO=update(spowoduje to automatyczne utworzenie tabel zgodnie z encjami JPA, co jest naprawdę świetne - ponieważ nie musisz przeszkadzać wCREATEinstrukcje SQL lub pliki DDL)
W Heroku powinno to wyglądać tak:
Teraz to wszystko, co musisz zrobić! Twoja aplikacja Heroku jest uruchamiana ponownie za każdym razem, gdy zmieniasz zmienną konfiguracyjną - więc Twoja aplikacja powinna teraz działać lokalnie w H2 i powinna być gotowa do połączenia z PostgreSQL po wdrożeniu w Heroku.
Tylko jeśli pytasz:dlaczego konfigurujemy Tomcat JDBC zamiast Hikari
Jak zapewne zauważyłeś, dodaliśmy tomcat-jdbc zależność od naszego pom.xml i skonfigurowany SPRING_DATASOURCE_TYPE=org.apache.tomcat.jdbc.pool.DataSource jako zmienna środowiskowa. W dokumentach jest tylko niewielka wskazówka na temat tego powiedzenia
Można całkowicie ominąć ten algorytm i określić pulę połączeń, która ma być używana, ustawiając właściwość spring.datasource.type. Jest to szczególnie ważne, jeśli uruchamiasz aplikację w kontenerze Tomcat, ...
Jest kilka powodów, dla których wróciłem do Tomcat pooling DataSource zamiast używać standardowego HikariCP Spring Boot 2.x. Jak już wyjaśniłem tutaj, jeśli nie określisz spring.datasource.url , Spring spróbuje automatycznie podłączyć wbudowaną bazę danych im-memory H2 zamiast naszej bazy PostgreSQL. Problem z Hikari polega na tym, że obsługuje tylko spring.datasource.jdbc-url .
Po drugie, jeśli spróbuję użyć konfiguracji Heroku, jak pokazano dla Hikari (więc pomijam SPRING_DATASOURCE_TYPE i zmiana SPRING_DATASOURCE_URL na SPRING_DATASOURCE_JDBC-URL ) Natrafiam na następujący wyjątek:
Caused by: java.lang.RuntimeException: Driver org.postgresql.Driver claims to not accept jdbcUrl, jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE
Więc nie dostałem Spring Boot 2.x działającego na Heroku i Postgres z HikariCP, ale z Tomcat JDBC - i nie chcę też hamować mojego procesu rozwoju zawierającego lokalną bazę danych H2 opisaną z góry. Pamiętaj:Szukaliśmy najprostszego, najczystszego sposobu łączenia się z Heroku Postgres w aplikacji Spring Boot przy użyciu JPA/Hibernacji!