Czasami trudno jest zarządzać dużą ilością danych w firmie, zwłaszcza przy wykładniczym wzroście analizy danych i wykorzystania Internetu Rzeczy. W zależności od rozmiaru, ta ilość danych może wpłynąć na wydajność twoich systemów i prawdopodobnie będziesz musiał przeskalować swoje bazy danych lub znaleźć sposób, aby to naprawić. Istnieją różne sposoby skalowania baz danych PostgreSQL, a jednym z nich jest sharding. W tym blogu zobaczymy, czym jest sharding i jak skonfigurować go w PostgreSQL za pomocą ClusterControl, aby uprościć zadanie.
Co to jest fragmentowanie?
Sharding to działanie polegające na optymalizacji bazy danych poprzez oddzielenie danych z dużej tabeli na wiele małych. Mniejsze tabele to Shards (lub partycje). Partycjonowanie i dzielenie na fragmenty to podobne koncepcje. Główna różnica polega na tym, że sharding oznacza, że dane są rozłożone na wiele komputerów, podczas gdy partycjonowanie polega na grupowaniu podzbiorów danych w jednej instancji bazy danych.
Istnieją dwa rodzaje shardingu:
-
Podział na fragmenty poziome:Każda nowa tabela ma taki sam schemat jak duża tabela, ale unikatowe wiersze. Jest to przydatne, gdy zapytania mają tendencję do zwracania podzbioru wierszy, które są często zgrupowane razem.
-
Podział na fragmenty pionowe:Każda nowa tabela ma schemat, który jest podzbiorem oryginalnego schematu tabeli. Jest to przydatne, gdy zapytania zwracają tylko podzbiór kolumn danych.
Zobaczmy przykład:
Oryginalna tabela
| ID | Nazwa | Wiek | Kraj |
|---|---|---|---|
| 1 | James Smith | 26 | USA |
| 2 | Mary Johnson | 31 | Niemcy |
| 3 | Robert Williams | 54 | Kanada |
| 4 | Jennifer Brown | 47 | Francja |
Podział pionowy
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | Nazwa | Wiek | ID | Kraj |
| 1 | James Smith | 26 | 1 | USA |
| 2 | Mary Johnson | 31 | 2 | Niemcy |
| 3 | Robert Williams | 54 | 3 | Kanada |
| 4 | Jennifer Brown | 47 | 4 | Francja |
Podział na fragmenty w poziomie
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Nazwa | Wiek | Kraj | ID | Nazwa | Wiek | Kraj |
| 1 | James Smith | 26 | USA | 3 | Robert Williams | 54 | Kanada |
| 2 | Mary Johnson | 31 | Niemcy | 4 | Jennifer Brown | 47 | Francja |
Teraz, gdy przejrzeliśmy niektóre koncepcje shardingu, przejdźmy do następnego kroku.
Jak wdrożyć klaster PostgreSQL?
Do tego zadania użyjemy ClusterControl. Jeśli nie używasz jeszcze ClusterControl, możesz go zainstalować i wdrożyć lub zaimportować aktualną bazę danych PostgreSQL, wybierając opcję „Importuj” i postępuj zgodnie z instrukcjami, aby skorzystać ze wszystkich funkcji ClusterControl, takich jak kopie zapasowe, automatyczne przełączanie awaryjne, alerty, monitorowanie i inne .
Aby przeprowadzić wdrożenie z ClusterControl, po prostu wybierz opcję „Wdróż” i postępuj zgodnie z wyświetlanymi instrukcjami.
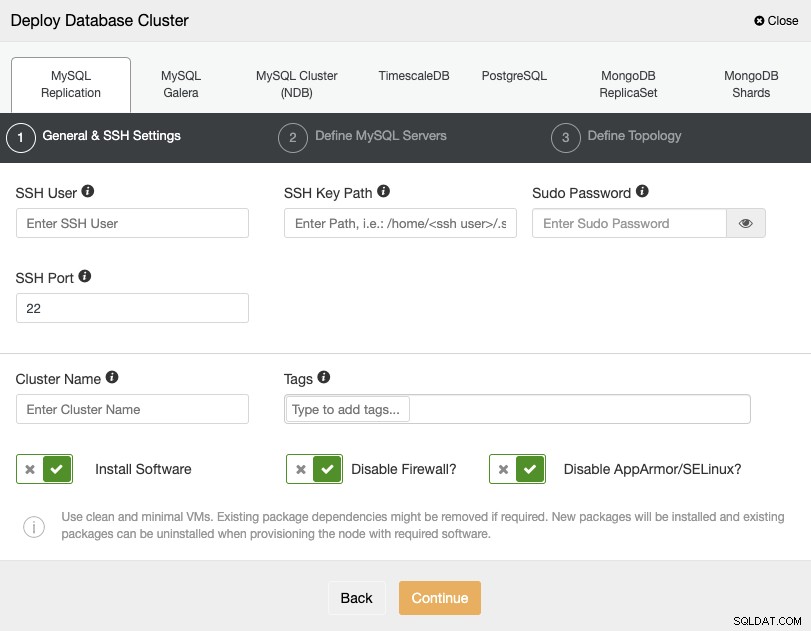
Wybierając PostgreSQL, musisz podać swojego użytkownika, klucz lub hasło oraz Port do łączenia się przez SSH z Twoimi serwerami. Możesz również dodać nazwę dla swojego nowego klastra, a jeśli chcesz, możesz również użyć ClusterControl do zainstalowania odpowiedniego oprogramowania i konfiguracji.
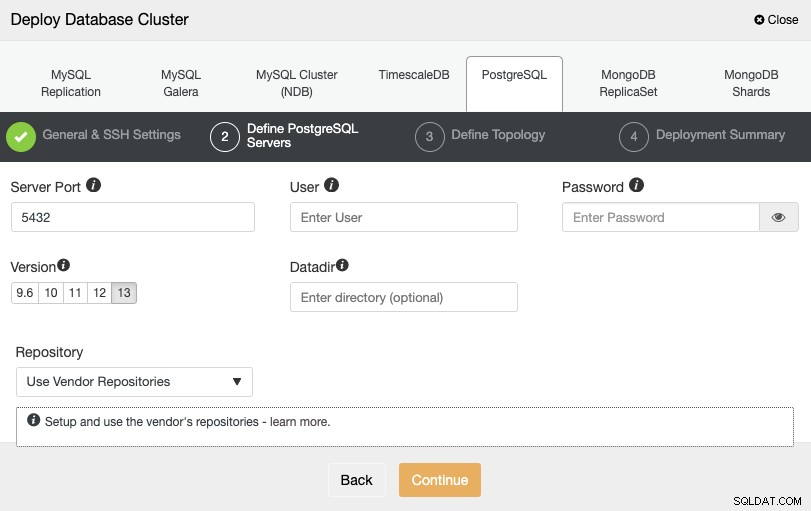
Po skonfigurowaniu informacji dostępu SSH należy zdefiniować poświadczenia bazy danych , wersja i katalog danych (opcjonalnie). Możesz także określić, którego repozytorium chcesz użyć.
W następnym kroku musisz dodać swoje serwery do klastra, który zamierzasz utworzyć przy użyciu adresu IP lub nazwy hosta.
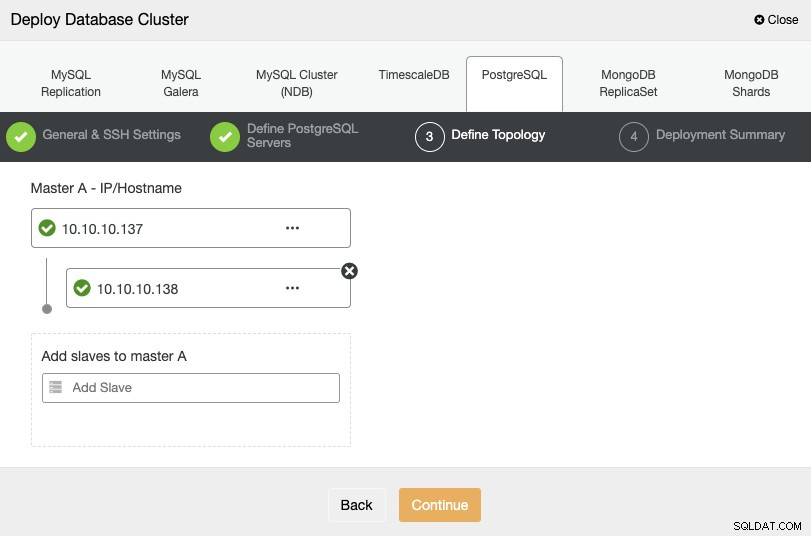
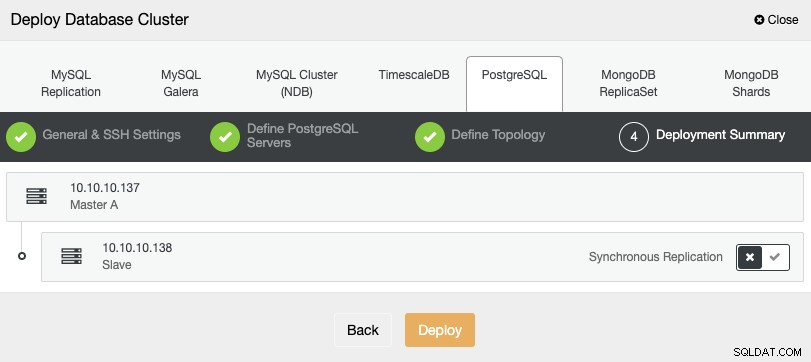
W ostatnim kroku możesz wybrać, czy twoja replikacja będzie synchroniczna, czy Asynchronicznie, a następnie po prostu naciśnij „Wdróż”.
Po zakończeniu zadania zobaczysz swój nowy klaster PostgreSQL w główny ekran ClusterControl.

Po utworzeniu klastra możesz wykonać na nim kilka zadań jak dodanie modułu równoważenia obciążenia (HAProxy), puli połączeń (pgBouncer) lub nowej repliki.
Powtórz proces, aby mieć co najmniej dwa oddzielne klastry PostgreSQL do skonfigurowania shardingu, co jest następnym krokiem.
Jak skonfigurować sharding PostgreSQL?
Teraz skonfigurujemy sharding za pomocą partycji PostgreSQL i Foreign Data Wrapper (FDW). Ta funkcjonalność umożliwia PostgreSQL dostęp do danych przechowywanych na innych serwerach. Jest to rozszerzenie dostępne domyślnie w powszechnej instalacji PostgreSQL.
Będziemy używać następującego środowiska:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersAby włączyć rozszerzenie FDW, wystarczy uruchomić następujące polecenie na głównym serwerze, w tym przypadku Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONTeraz utwórzmy tabelę klienci podzieloną według zarejestrowanej daty:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);I następujące partycje:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Te partycje są lokalne. Teraz wstawmy kilka wartości testowych i sprawdźmy je:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Tutaj możesz wysłać zapytanie do głównej partycji, aby zobaczyć wszystkie dane:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Lub nawet zapytaj o odpowiednią partycję:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Jak widać, dane zostały umieszczone w różnych partycjach, zgodnie z zarejestrowaną datą. Teraz w węźle zdalnym, w tym przypadku Shard2, stwórzmy kolejną tabelę:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Musisz utworzyć ten serwer Shard2 w Shard1 w ten sposób:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');I użytkownik, który ma do niego dostęp:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Teraz utwórz TABELĘ ZAGRANICZNĄ w Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;I wstawmy dane do tej nowej zdalnej tabeli z Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Jeśli wszystko poszło dobrze, powinieneś być w stanie uzyskać dostęp do danych zarówno z fragmentu 1, jak i fragmentu 2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Odłamek2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)To wszystko. Teraz używasz shardingu w swoim klastrze PostgreSQL.
Wnioski
Partycjonowanie i sharding w PostgreSQL to dobre funkcje. Pomaga w przypadku, gdy musisz rozdzielić dane w dużej tabeli, aby poprawić wydajność, a nawet usunąć dane w łatwy sposób, między innymi. Ważnym punktem podczas korzystania z dzielenia na fragmenty jest wybranie dobrego klucza fragmentu, który najlepiej dystrybuuje dane między węzłami. Możesz także użyć ClusterControl, aby uprościć wdrażanie PostgreSQL i skorzystać z niektórych funkcji, takich jak monitorowanie, alerty, automatyczne przełączanie awaryjne, tworzenie kopii zapasowych, przywracanie do określonego punktu w czasie i wiele innych.