Amazon wypuścił S3 na początku 2006 roku, a pierwsze narzędzie umożliwiające skryptom tworzenia kopii zapasowych PostgreSQL przesyłanie danych do chmury — s3cmd — narodziło się zaledwie rok później. Do 2010 roku (według moich umiejętności wyszukiwania w Google) blogi Open BI na ten temat. Można więc śmiało powiedzieć, że niektórzy administratorzy baz danych PostgreSQL tworzyli kopie zapasowe danych w AWS S3 już od 9 lat. Ale jak? A co się zmieniło w tym czasie? Chociaż s3cmd jest nadal przywoływane przez niektórych w kontekście znanych narzędzi do tworzenia kopii zapasowych PostgreSQL, metody odnotowały zmiany umożliwiające lepszą integrację z systemem plików lub natywnymi opcjami tworzenia kopii zapasowych PostgreSQL w celu osiągnięcia pożądanych celów odzyskiwania RTO i RPO.
Dlaczego Amazon S3
Jak wskazano w dokumentacji Amazon S3 (często zadawane pytania dotyczące S3 są bardzo dobrym punktem wyjścia), zalety korzystania z usługi S3 to:
- 99.999999999 (jedenaście dziewiątek) trwałość
- nieograniczone przechowywanie danych
- niskie koszty (nawet niższe w połączeniu z BitTorrentem)
- bezpłatny ruch przychodzący w sieci
- rozliczany jest tylko ruch wychodzący z sieci
Rozwiązania interfejsu AWS S3 CLI
Zestaw narzędzi AWS S3 CLI zapewnia wszystkie narzędzia potrzebne do przesyłania danych do iz pamięci S3, dlaczego więc nie skorzystać z tych narzędzi? Odpowiedź tkwi w szczegółach implementacji Amazon S3, które obejmują środki do obsługi ograniczeń i ograniczeń związanych z przechowywaniem obiektów:
- Maksymalny rozmiar 5 TB na przechowywany obiekt
- Maksymalny rozmiar obiektu PUT 5 GB
- przesyłanie wieloczęściowe zalecane dla obiektów większych niż 100 MB
- wybierz odpowiednią klasę pamięci zgodnie z tabelą wydajności S3
- skorzystaj z cyklu życia S3
- Model spójności danych S3
Jako przykład odnieś się do strony pomocy aws s3 cp:
--expected-size (string) Ten argument określa oczekiwany rozmiar strumienia w bajtach. Pamiętaj, że ten argument jest potrzebny tylko wtedy, gdy strumień jest przesyłany do s3, a rozmiar jest większy niż 5 GB. Nieuwzględnienie tego argumentu w tych warunkach może skutkować nieudanym przesyłaniem z powodu zbyt wielu części podczas przesyłania.
Unikanie tych pułapek wymaga dogłębnej znajomości ekosystemu S3, co starają się osiągnąć specjalnie zaprojektowane narzędzia do tworzenia kopii zapasowych PostgreSQL i S3.
Natywne narzędzia do tworzenia kopii zapasowych PostgreSQL z obsługą Amazon S3
Integracja S3 jest zapewniana przez niektóre z dobrze znanych narzędzi do tworzenia kopii zapasowych, implementując natywne funkcje tworzenia kopii zapasowych PostgreSQL.
BarmanS3
BarmanS3 jest zaimplementowany jako Barman Hook Scripts. Opiera się na AWS CLI, bez uwzględniania zaleceń i ograniczeń wymienionych powyżej. Prosta konfiguracja czyni go dobrym kandydatem do małych instalacji. Rozwój jest nieco utknięty, ostatnia aktualizacja około rok temu, dzięki czemu ten produkt jest wyborem dla tych, którzy już używają Barmana w swoich środowiskach.
S3 Zrzuty
S3dumps to aktywny projekt, zaimplementowany przy użyciu biblioteki Python Boto3 firmy Amazon. Instalacja jest łatwa do wykonania za pomocą pip. Chociaż polegamy na pakiecie SDK Amazon S3 Python, wyszukiwanie w kodzie źródłowym słów kluczowych wyrażeń regularnych, takich jak multi.*part lub storage.*class, nie ujawnia żadnych zaawansowanych funkcji S3, takich jak transfery wieloczęściowe.
pgBackRest
pgBackRest implementuje S3 jako opcję repozytorium. Jest to jedno z dobrze znanych narzędzi do tworzenia kopii zapasowych PostgreSQL, oferujące bogaty w funkcje zestaw opcji tworzenia kopii zapasowych, takich jak równoległe tworzenie kopii zapasowych i przywracanie, szyfrowanie i obsługa obszarów tabel. Jest to głównie kod C, który zapewnia szybkość i przepustowość, których szukamy, jednak jeśli chodzi o interakcję z API AWS S3, odbywa się to za cenę dodatkowej pracy wymaganej do wdrożenia funkcji przechowywania S3. Najnowsza wersja wprowadza wieloczęściowe przesyłanie S3.
WAL-G
WAL-G ogłoszony 2 lata temu jest aktywnie utrzymywany. To solidne narzędzie do tworzenia kopii zapasowych PostgreSQL implementuje klasy pamięci, ale nie umożliwia przesyłania wieloczęściowego (przeszukiwanie kodu dla CreateMultipartUpload nie znalazło żadnego wystąpienia).
PGHoard
pghoard został wydany około 3 lata temu. Jest to wydajne i bogate w funkcje narzędzie do tworzenia kopii zapasowych PostgreSQL z obsługą transferów wieloczęściowych S3. Nie oferuje żadnych innych funkcji S3, takich jak klasa pamięci i zarządzanie cyklem życia obiektów.
S3 jako lokalny system plików
Możliwość dostępu do pamięci S3 jako lokalnego systemu plików jest bardzo pożądaną funkcją, ponieważ otwiera możliwość korzystania z natywnych narzędzi do tworzenia kopii zapasowych PostgreSQL.
W przypadku środowisk Linux Amazon oferuje dwie opcje:NFS i iSCSI. Korzystają z AWS Storage Gateway.
NFS
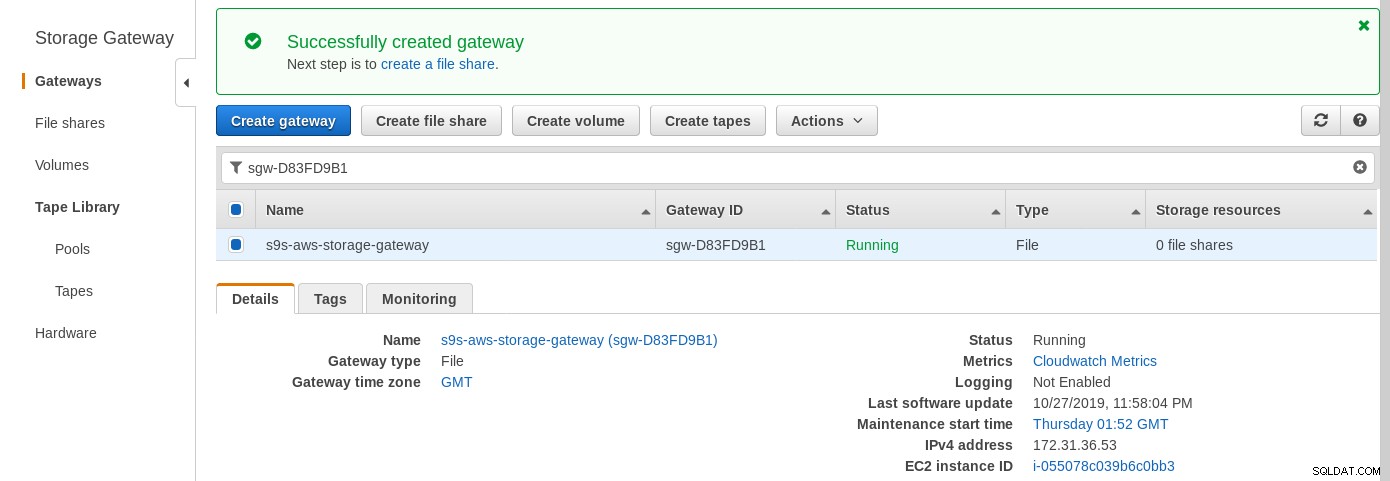
Lokalnie zainstalowany udział NFS jest dostarczany przez usługę AWS Storage Gateway File. Zgodnie z linkiem musimy utworzyć bramę plików.
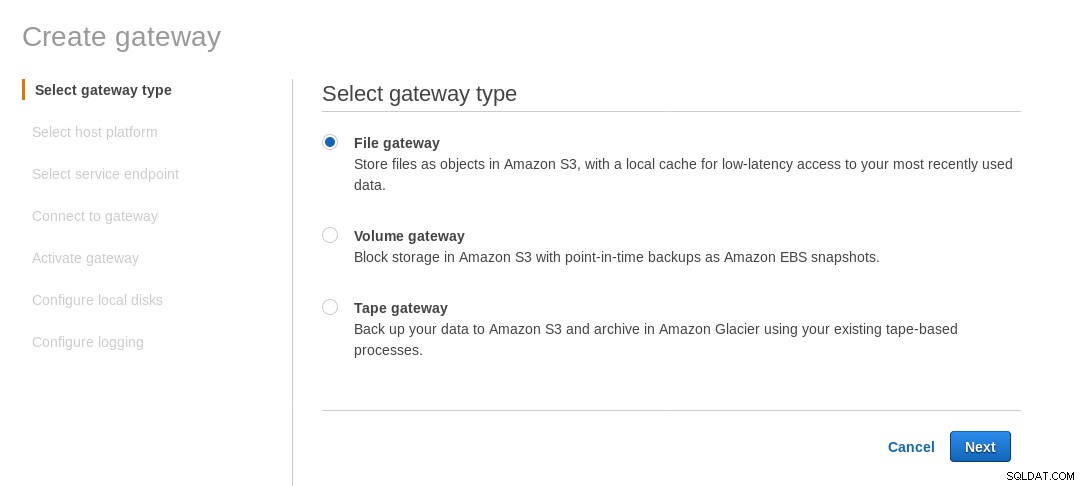
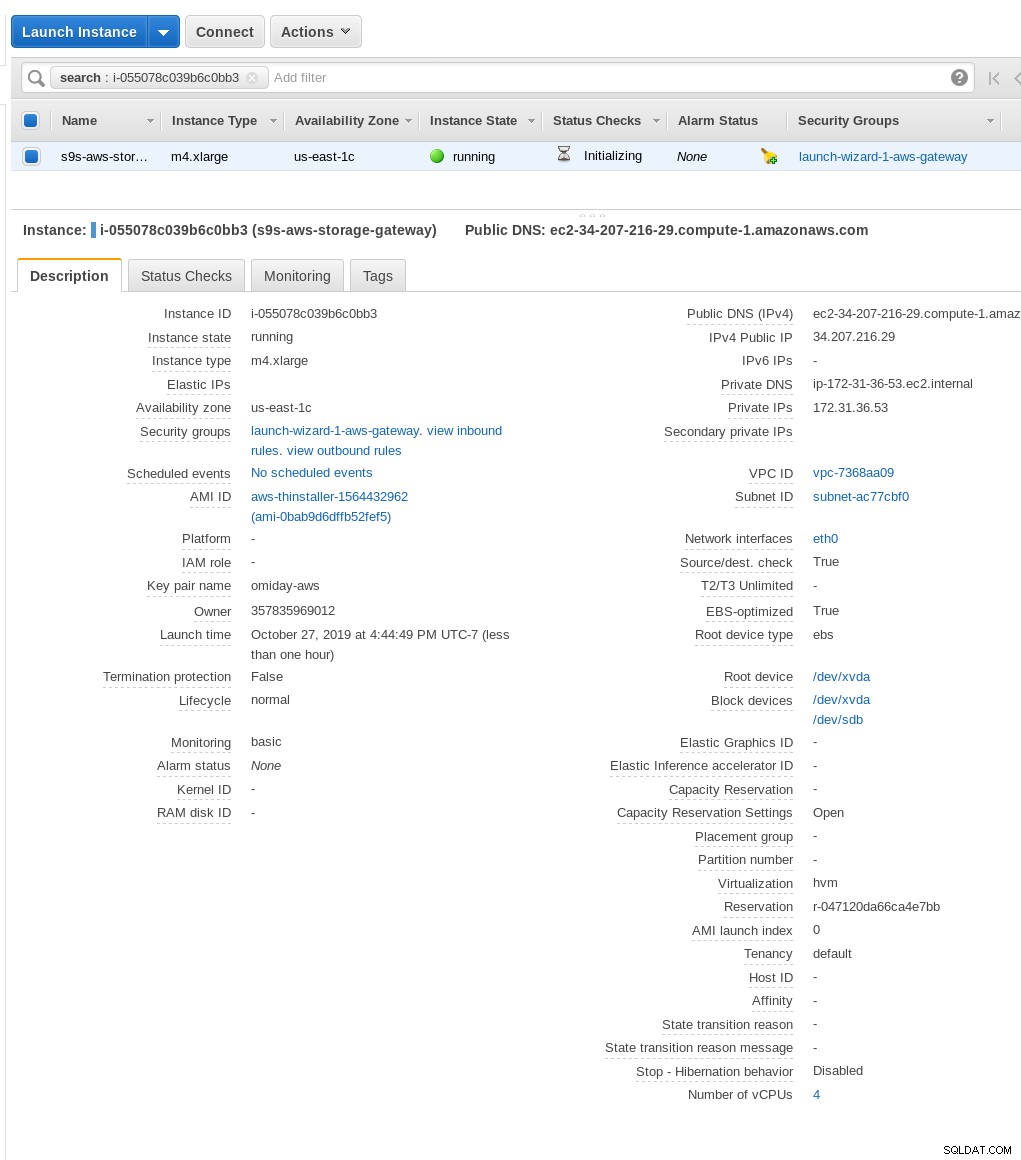
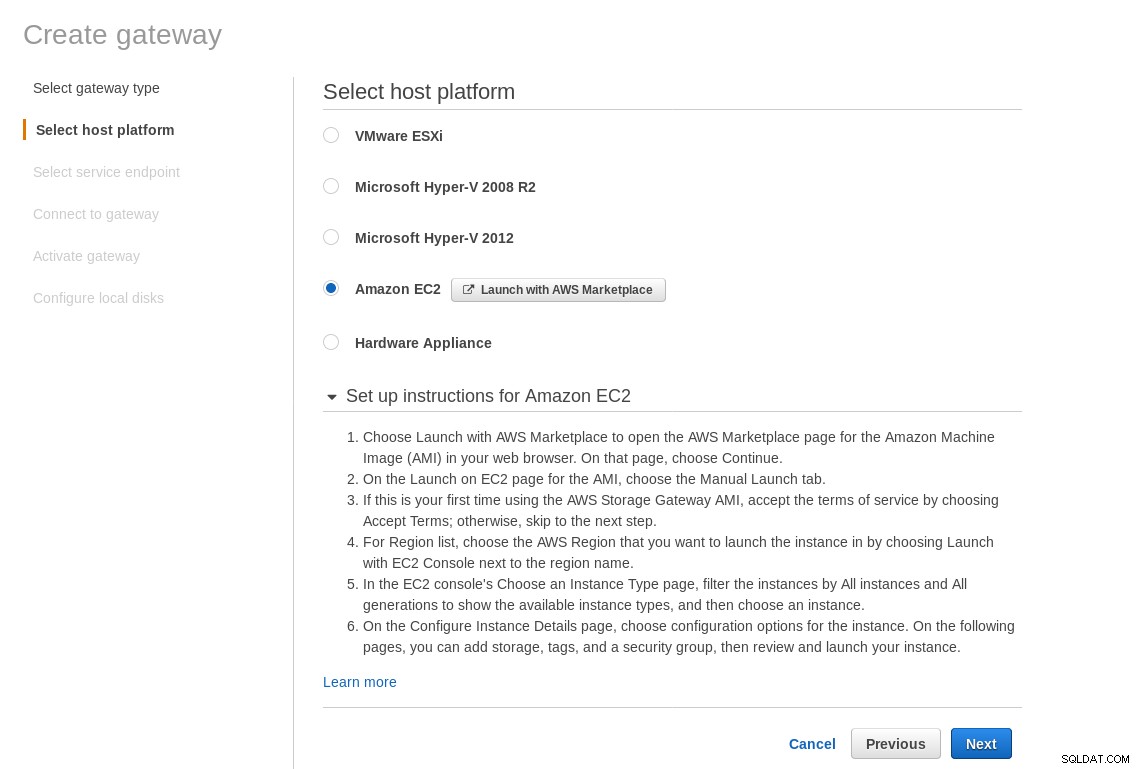
Na ekranie Wybierz platformę hosta wybierz Amazon EC2 i kliknij przycisk Uruchom instancję aby uruchomić kreatora EC2 do tworzenia instancji.
Teraz, z ciekawości tego Sysadmina, przyjrzyjmy się AMI używanemu przez kreatora, ponieważ daje nam to interesującą perspektywę na niektóre wewnętrzne elementy AWS. Znając identyfikator obrazu ami-0bab9d6dffb52fef5, spójrzmy na szczegóły:
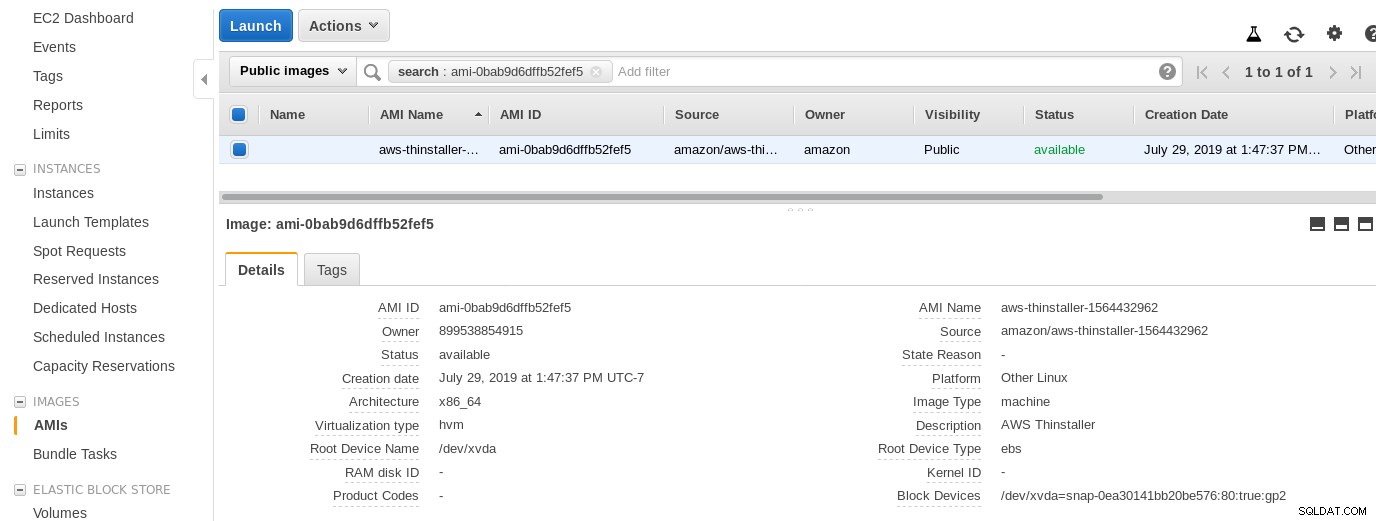
Jak pokazano powyżej, nazwa AMI to aws-thinstaller — więc co to jest „instalator”? Wyszukiwania internetowe ujawniają, że Thinstaller to narzędzie do zarządzania konfiguracją oprogramowania IBM Lenovo dla produktów Microsoft, o którym wspomniano najpierw w tym blogu z 2008 r., a później w tym poście na forum Lenovo i w tym zgłoszeniu serwisowym okręgu szkolnego. Nie miałem możliwości poznania tego, ponieważ moja praca administratora systemu Windows zakończyła się 3 lata wcześniej. Tak więc to AMI zostało zbudowane z produktem Thinstaller. Aby sprawy były jeszcze bardziej zagmatwane, system operacyjny AMI jest wymieniony jako „Inny Linux”, co można potwierdzić, wprowadzając SSH do systemu jako administrator.
Kreator ma problem:pomimo instrukcji konfiguracji zapory sieciowej EC2 moja przeglądarka przedawniała się podczas łączenia się z bramą pamięci masowej. Zezwalanie na port 80 jest udokumentowane w Wymaganiach portów — moglibyśmy argumentować, że kreator powinien albo wyświetlić listę wszystkich wymaganych portów, albo link do dokumentacji, jednak w duchu chmury odpowiedź brzmi „zautomatyzować” za pomocą narzędzi takich jak CloudFormation.
Kreator sugeruje również rozpoczęcie od wystąpienia o bardzo dużym rozmiarze.
Gdy brama magazynu będzie gotowa, skonfiguruj udział NFS, klikając przycisk Utwórz przycisk udostępniania plików w menu Brama:
Gdy udział NFS będzie gotowy, postępuj zgodnie z instrukcjami, aby zamontować system plików:
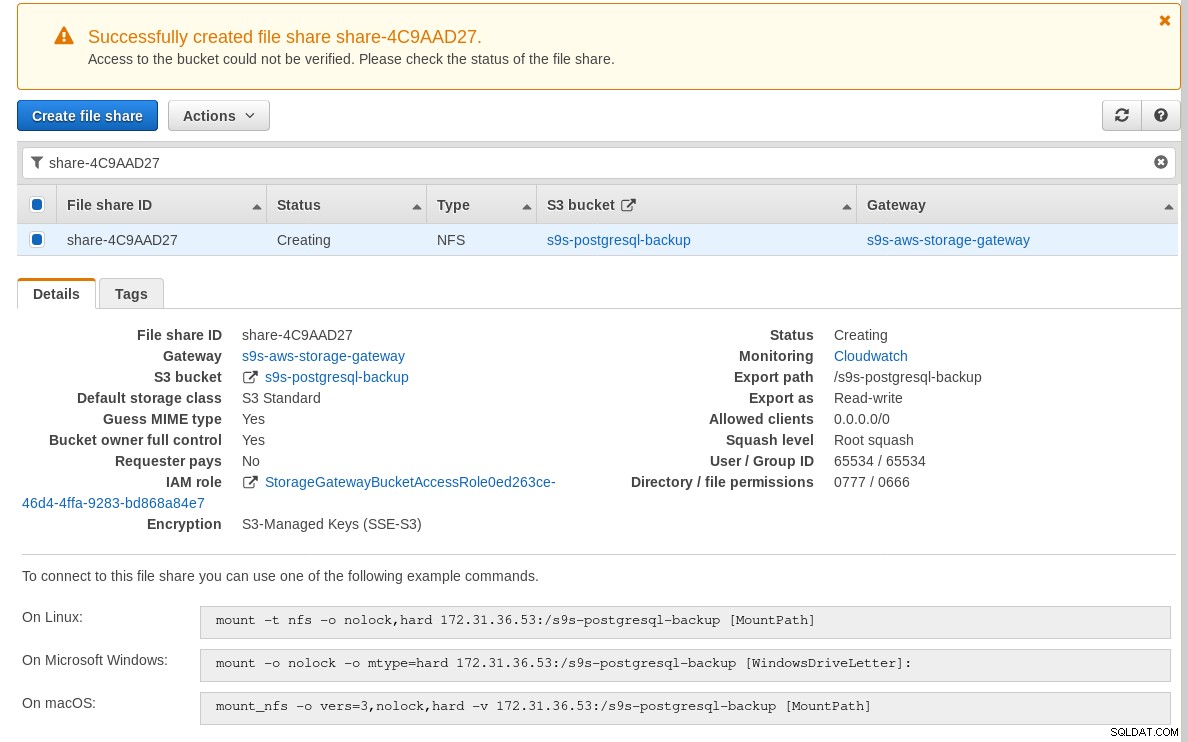
Zwróć uwagę, że na powyższym zrzucie ekranu polecenie mount odwołuje się do prywatnego adresu IP instancji adres. Aby zamontować z hosta publicznego, wystarczy użyć publicznego adresu instancji, jak pokazano w szczegółach instancji EC2 powyżej.
Kreator nie zablokuje się, jeśli zasobnik S3 nie istnieje w momencie tworzenia udziału plików, jednak po utworzeniu zasobnika S3 musimy ponownie uruchomić instancję, w przeciwnym razie polecenie mount nie powiedzie się z:
[example@sqldat.com ~]# mount -t nfs -o nolock,hard 34.207.216.29:/s9s-postgresql-backup /mnt
mount.nfs: mounting 34.207.216.29:/s9s-postgresql-backup failed, reason given by server: No such file or directorySprawdź, czy udział został udostępniony:
[example@sqldat.com ~]# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
34.207.216.29:/s9s-postgresql-backup 8.0E 0 8.0E 0% /mntTeraz przeprowadźmy szybki test:
example@sqldat.com[local]:54311 postgres# \l+ test
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
test | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 2763 MB | pg_default |
(1 row)
[example@sqldat.com ~]# date ; time pg_dump -d test | gzip -c >/mnt/test.pg_dump.gz ; date
Sun 27 Oct 2019 06:06:24 PM PDT
real 0m29.807s
user 0m15.909s
sys 0m2.040s
Sun 27 Oct 2019 06:06:54 PM PDTZauważ, że znacznik czasu ostatniej modyfikacji w zasobniku S3 jest około minuty później, co, jak wspomniano wcześniej, musi być zgodne z modelem spójności danych Amazon S3.
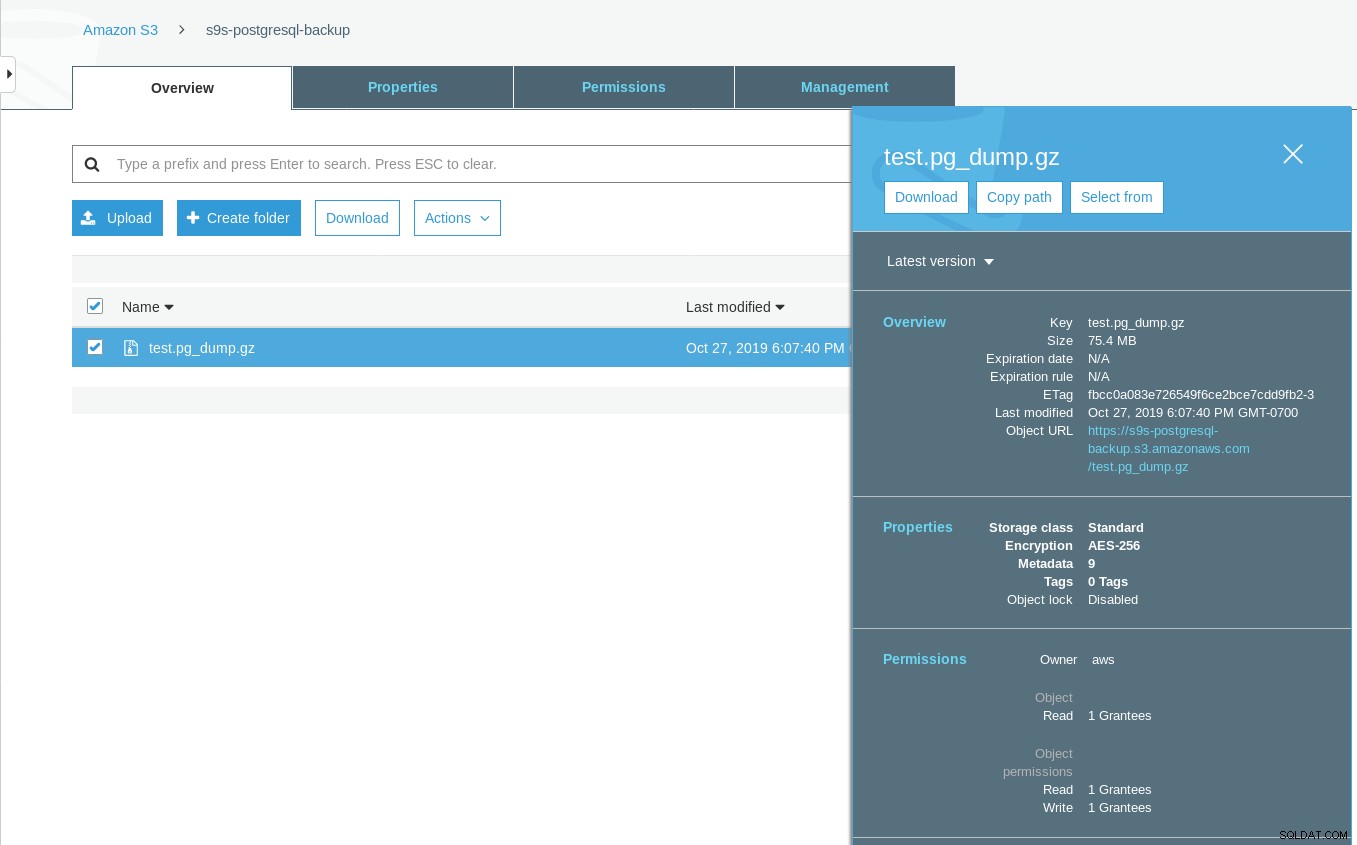
Oto bardziej wyczerpujący test:
~ $ for q in {0..20} ; do touch /mnt/touched-at-$(date +%Y%m%d%H%M%S) ;
sleep 1 ; done
~ $ aws s3 ls s3://s9s-postgresql-backup | nl
1 2019-10-27 19:50:40 0 touched-at-20191027194957
2 2019-10-27 19:50:40 0 touched-at-20191027194958
3 2019-10-27 19:50:40 0 touched-at-20191027195000
4 2019-10-27 19:50:40 0 touched-at-20191027195001
5 2019-10-27 19:50:40 0 touched-at-20191027195002
6 2019-10-27 19:50:40 0 touched-at-20191027195004
7 2019-10-27 19:50:40 0 touched-at-20191027195005
8 2019-10-27 19:50:40 0 touched-at-20191027195007
9 2019-10-27 19:50:40 0 touched-at-20191027195008
10 2019-10-27 19:51:10 0 touched-at-20191027195009
11 2019-10-27 19:51:10 0 touched-at-20191027195011
12 2019-10-27 19:51:10 0 touched-at-20191027195012
13 2019-10-27 19:51:10 0 touched-at-20191027195013
14 2019-10-27 19:51:10 0 touched-at-20191027195014
15 2019-10-27 19:51:10 0 touched-at-20191027195016
16 2019-10-27 19:51:10 0 touched-at-20191027195017
17 2019-10-27 19:51:10 0 touched-at-20191027195018
18 2019-10-27 19:51:10 0 touched-at-20191027195020
19 2019-10-27 19:51:10 0 touched-at-20191027195021
20 2019-10-27 19:51:10 0 touched-at-20191027195022
21 2019-10-27 19:51:10 0 touched-at-20191027195024Kolejny problem, o którym warto wspomnieć:po zabawie z różnymi konfiguracjami, tworzeniu i niszczeniu bram i udziałów, w pewnym momencie podczas próby aktywacji bramy plików otrzymywałem błąd wewnętrzny:
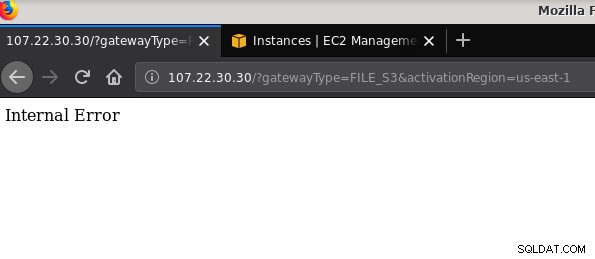
Wiersz poleceń zawiera więcej szczegółów, ale nie wskazuje na żaden problem:
~$ curl -sv "https://107.22.30.30/?gatewayType=FILE_S3&activationRegion=us-east-1"
* Trying 107.22.30.30:80...
* TCP_NODELAY set
* Connected to 107.22.30.30 (107.22.30.30) port 80 (#0)
> GET /?gatewayType=FILE_S3&activationRegion=us-east-1 HTTP/1.1
> Host: 107.22.30.30
> User-Agent: curl/7.65.3
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 500 Internal Server Error
< Date: Mon, 28 Oct 2019 06:33:30 GMT
< Content-type: text/html
< Content-length: 14
<
* Connection #0 to host 107.22.30.30 left intact
Internal Error~ $Ten post na forum wskazywał, że mój problem może mieć coś wspólnego z utworzonym przeze mnie punktem końcowym VPC. Moją poprawką było usunięcie punktu końcowego VPC, który skonfigurowałem podczas różnych prób i błędów iSCSI.
Podczas gdy S3 szyfruje dane w spoczynku, ruch sieciowy NFS to zwykły tekst. Oto zrzut pakietu tcpdump:
23:47:12.225273 IP 192.168.0.11.936 > 107.22.30.30.2049: Flags [P.], seq 2665:3377, ack 2929, win 501, options [nop,nop,TS val 1899459538 ecr 38013066], length 712: NFS request xid 3511704119 708 getattr fh 0,2/53
example@sqldat.com@.......k....... ...c..............
q7s..D.......PZ7...........................4........omiday.can.local...................................................5.......]...........!....................C...
..............&...........]....................# inittab is no longer used.
#
# ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.
#
# Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target
#
# systemd uses 'targets' instead of runlevels. By default, there are two main targets:
#
# multi-user.target: analogous to runlevel 3
# graphical.target: analogous to runlevel 5
#
# To view current default target, run:
# systemctl get-default
#
# To set a default target, run:
# systemctl set-default TARGET.target
..... .........0..
23:47:12.331592 IP 107.22.30.30.2049 > 192.168.0.11.936: Flags [P.], seq 2929:3109, ack 3377, win 514, options [nop,nop,TS val 38013174 ecr 1899459538], length 180: NFS reply xid 3511704119 reply ok 176 getattr NON 4 ids 0/33554432 sz -2138196387Dopóki ta wersja robocza IEE nie zostanie zatwierdzona, jedyną bezpieczną opcją łączenia się z zewnątrz AWS jest użycie tunelu VPN. To komplikuje konfigurację, dzięki czemu lokalna opcja NFS jest mniej atrakcyjna niż narzędzia oparte na FUSE, które omówię nieco później.
iSCSI
Ta opcja jest udostępniana przez usługę AWS Storage Gateway Volume. Po skonfigurowaniu usługi przejdź do sekcji konfiguracji klienta Linux iSCSI.
Przewaga korzystania z iSCSI nad NFS polega na możliwości korzystania z natywnych usług tworzenia kopii zapasowych, klonowania i migawek Amazon w chmurze. Aby uzyskać szczegółowe informacje i instrukcje krok po kroku, skorzystaj z łączy do kopii zapasowych AWS, klonowania woluminów i migawek EBS
Chociaż istnieje wiele zalet, istnieje ważne ograniczenie, które prawdopodobnie zniechęci wielu użytkowników:nie można uzyskać dostępu do bramy za pośrednictwem jej publicznego adresu IP. Tak więc, podobnie jak opcja NFS, to wymaganie zwiększa złożoność konfiguracji.
Pomimo wyraźnych ograniczeń i przekonania, że nie uda mi się dokończyć tej konfiguracji, nadal chciałem poczuć, jak to się robi. Kreator przekierowuje do ekranu konfiguracji AWS Marketplace.
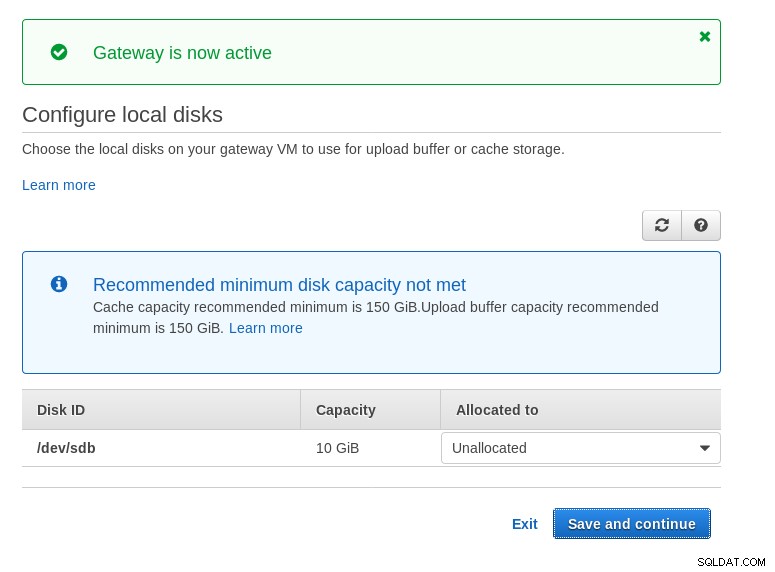
Należy pamiętać, że kreator Marketplace tworzy dysk dodatkowy, jednak nie jest on wystarczająco duży w rozmiar, dlatego nadal musimy dodać dwa wymagane woluminy, jak wskazano w instrukcjach konfiguracji hosta. Jeśli wymagania dotyczące przechowywania nie są spełnione, kreator zablokuje się na ekranie konfiguracji dysków lokalnych:
Oto rzut oka na ekran konfiguracji Amazon Marketplace:
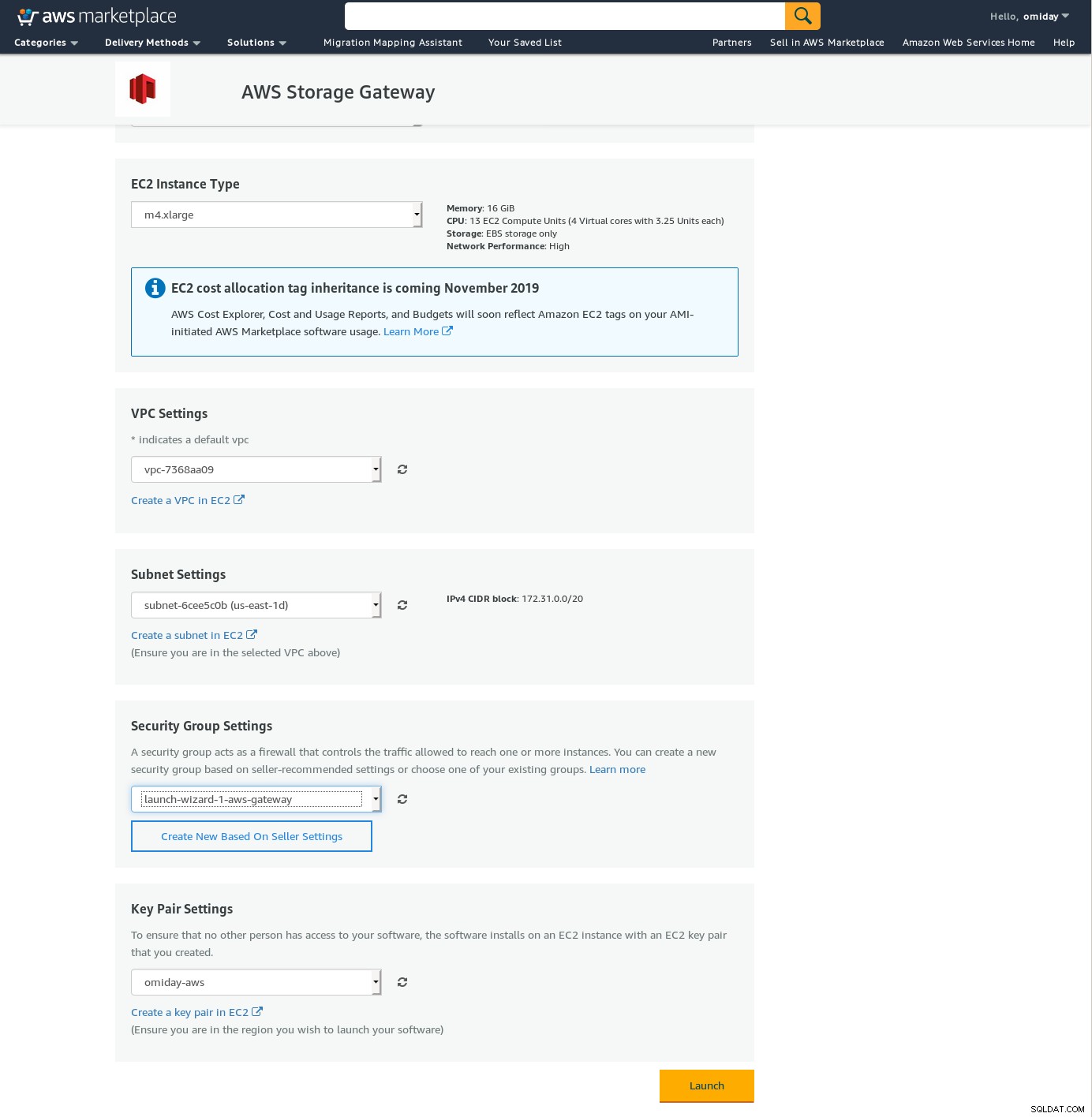
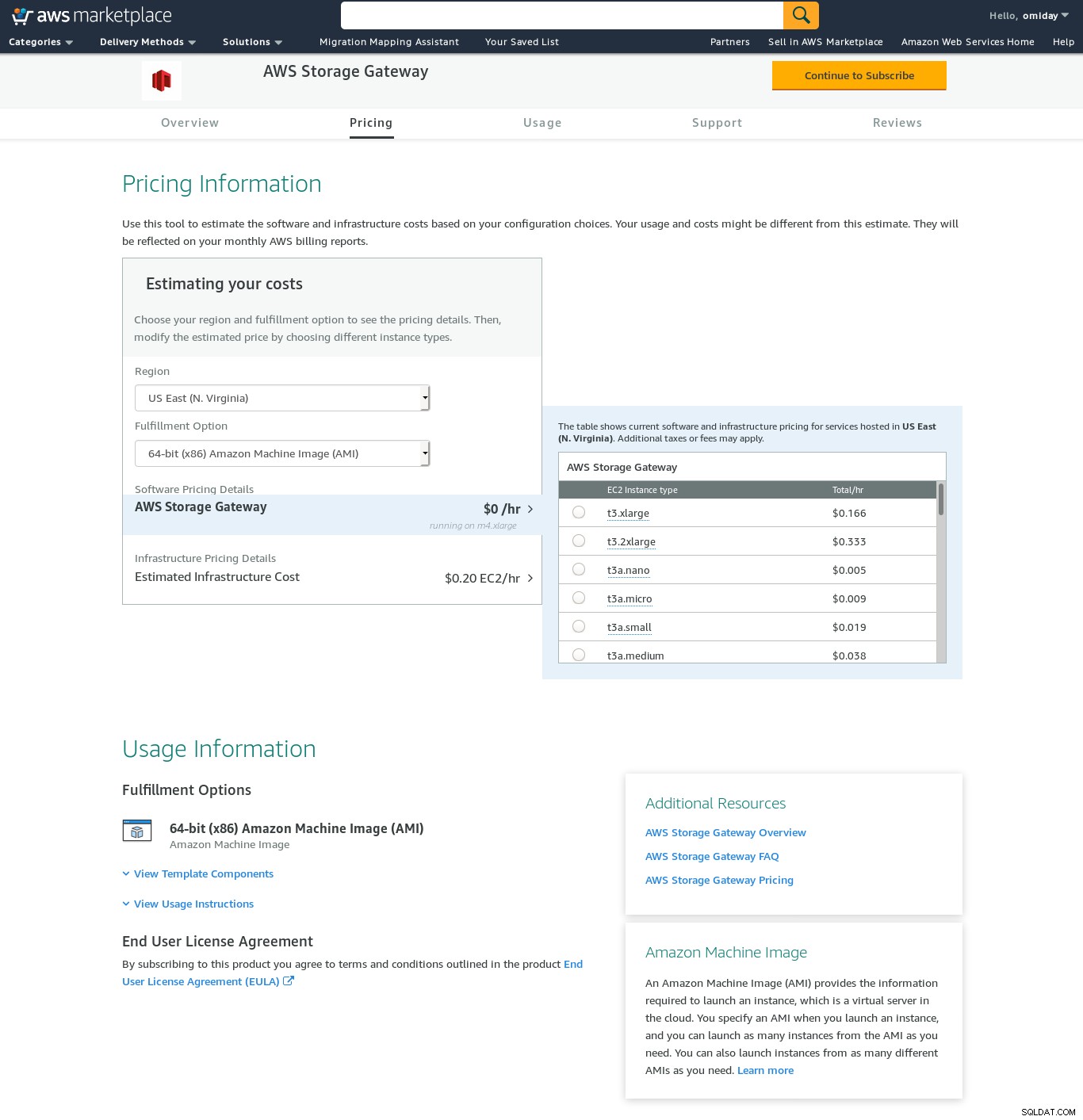
Istnieje interfejs tekstowy dostępny przez SSH (zaloguj się jako użytkownik sguser) który zapewnia podstawowe narzędzia do rozwiązywania problemów z siecią i inne opcje konfiguracji, których nie można wykonać za pomocą sieciowego interfejsu graficznego:
~ $ ssh example@sqldat.com
Warning: Permanently added 'ec2-3-231-96-109.compute-1.amazonaws.com,3.231.96.109' (ECDSA) to the list of known hosts.
'screen.xterm-256color': unknown terminal type.
AWS Storage Gateway Configuration
#######################################################################
## Currently connected network adapters:
##
## eth0: 172.31.1.185
#######################################################################
1: SOCKS Proxy Configuration
2: Test Network Connectivity
3: Gateway Console
4: View System Resource Check (0 Errors)
0: Stop AWS Storage Gateway
Press "x" to exit session
Enter command:I kilka innych ważnych punktów:
- W przeciwieństwie do konfiguracji NFS, nie ma bezpośredniego dostępu do pamięci S3, jak wspomniano w sekcji często zadawanych pytań dotyczących Volume Gateway.
- Dokumentacja AWS nalega na dostosowanie ustawień iSCSI w celu poprawy wydajności i bezpieczeństwa połączenia.
BEZPIECZNIK
W tej kategorii wymieniłem narzędzia oparte na FUSE, które zapewniają pełniejszą kompatybilność z S3 w porównaniu z narzędziami do tworzenia kopii zapasowych PostgreSQL i w przeciwieństwie do Amazon Storage Gateway umożliwiają transfer danych z lokalnego hosta do Amazon S3 bez dodatkowej konfiguracji. Taka konfiguracja może zapewnić pamięć S3 jako lokalny system plików, z którego mogą korzystać narzędzia do tworzenia kopii zapasowych PostgreSQL w celu skorzystania z takich funkcji, jak równoległy pg_dump.
bezpiecznik-s3fs
s3fs-fuse jest napisany w C++, języku obsługiwanym przez zestaw narzędzi Amazon S3 SDK, i jako taki dobrze nadaje się do implementacji zaawansowanych funkcji S3, takich jak przesyłanie wieloczęściowe, buforowanie, klasa pamięci S3, serwer- szyfrowanie boczne i wybór regionu. Jest również wysoce kompatybilny z POSIX.
Aplikacja jest dołączona do mojej Fedory 30, dzięki czemu instalacja jest prosta.
Aby przetestować:
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m35.761s
user 0m16.122s
sys 0m2.228s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 03:16:03 79110010 test.pg_dump-20191028-031535.gzZauważ, że prędkość jest nieco mniejsza niż w przypadku korzystania z Amazon Storage Gateway z opcją NFS. Rekompensuje to niższą wydajność, zapewniając system plików wysoce zgodny z POSIX.
S3QL
S3QL zapewnia funkcje S3, takie jak klasa pamięci masowej i szyfrowanie po stronie serwera. Wiele funkcji jest opisanych w wyczerpującej dokumentacji S3QL, jednak jeśli szukasz przesyłania wieloczęściowego, nigdzie o tym nie wspomniano. Dzieje się tak, ponieważ S3QL implementuje własny algorytm dzielenia plików w celu zapewnienia funkcji deduplikacji. Wszystkie pliki są podzielone na bloki o wielkości 10 MB.
Instalacja w systemie opartym na Red Hat jest prosta:zainstaluj wymagane zależności RPM przez yum:
sqlite-devel-3.7.17-8.14.amzn1.x86_64
fuse-devel-2.9.4-1.18.amzn1.x86_64
fuse-2.9.4-1.18.amzn1.x86_64
system-rpm-config-9.0.3-42.28.amzn1.noarch
python36-devel-3.6.8-1.14.amzn1.x86_64
kernel-headers-4.14.146-93.123.amzn1.x86_64
glibc-headers-2.17-260.175.amzn1.x86_64
glibc-devel-2.17-260.175.amzn1.x86_64
gcc-4.8.5-1.22.amzn1.noarch
gcc48-4.8.5-28.142.amzn1.x86_64
mpfr-3.1.1-4.14.amzn1.x86_64
libmpc-1.0.1-3.3.amzn1.x86_64
libgomp-6.4.1-1.45.amzn1.x86_64
libgcc48-4.8.5-28.142.amzn1.x86_64
cpp48-4.8.5-28.142.amzn1.x86_64
python36-pip-9.0.3-1.26.amzn1.noarch
python36-libs-3.6.8-1.14.amzn1.x86_64
python36-3.6.8-1.14.amzn1.x86_64
python36-setuptools-36.2.7-1.33.amzn1.noarchNastępnie zainstaluj zależności Pythona za pomocą pip3:
pip-3.6 install setuptools cryptography defusedxml apsw dugong pytest requests llfuse==1.3.6Ważną cechą tego narzędzia jest system plików S3QL utworzony na szczycie wiadra S3.
Głupcy
goofys jest opcją, gdy wydajność przewyższa zgodność z POSIX. Jego cele są przeciwieństwem s3fs-fuse. Koncentracja na szybkości znajduje również odzwierciedlenie w modelu dystrybucji. Dla Linuksa istnieją gotowe pliki binarne. Po pobraniu uruchom:
~/temp/goofys $ ./goofys s9s-postgresql-backup ~/mnt/s9s/I kopia zapasowa:
~/mnt/s9s $ time pg_dump -d test | gzip -c >test.pg_dump-$(date +%Y%m%d-%H%M%S).gz
real 0m27.427s
user 0m15.962s
sys 0m2.169s
~/mnt/s9s $ aws s3 ls s3://s9s-postgresql-backup
2019-10-28 04:29:05 79110010 test.pg_dump-20191028-042902.gzZauważ, że czas utworzenia obiektu na S3 to tylko 3 sekundy od znacznika czasu pliku.
ObjectFS
ObjectFS wydaje się być utrzymywany do około 6 miesięcy temu. Sprawdzenie przesyłania wieloczęściowego ujawnia, że nie jest on zaimplementowany. Z artykułu badawczego autora dowiadujemy się, że system jest nadal w fazie rozwoju, a ponieważ artykuł został wydany w 2019 roku, pomyślałem, że warto o tym wspomnieć.
Klienci S3
Jak wspomniano wcześniej, aby korzystać z interfejsu AWS S3 CLI, musimy wziąć pod uwagę kilka aspektów specyficznych dla przechowywania obiektów ogólnie, a Amazon S3 w szczególności. Jeśli jedynym wymaganiem jest możliwość przesyłania danych do iz pamięci S3, to zadanie może wykonać narzędzie, które ściśle przestrzega zaleceń Amazon S3.
s3cmd to jedno z narzędzi, które przetrwało próbę czasu. Ten blog Open BI 2010 mówi o tym w czasie, gdy S3 był nowym dzieckiem w bloku.
Ważne funkcje:
- szyfrowanie po stronie serwera
- automatyczne przesyłanie wieloczęściowe
- ograniczanie przepustowości
Przejdź do S3cmd:FAQ i Baza wiedzy, aby uzyskać więcej informacji.
Wnioski
Opcje dostępne do tworzenia kopii zapasowych klastra PostgreSQL w Amazon S3 różnią się metodami przesyłania danych i ich dopasowaniem do strategii Amazon S3.
AWS Storage Gateway uzupełnia obiektową pamięć masową S3 firmy Amazon, kosztem zwiększonej złożoności oraz dodatkowej wiedzy wymaganej w celu maksymalnego wykorzystania tej usługi. Na przykład wybór odpowiedniej liczby dysków wymaga starannego planowania, a dobre zrozumienie kosztów związanych z Amazon S3 jest koniecznością, aby zminimalizować koszty operacyjne.
Chociaż ma zastosowanie do dowolnej pamięci masowej w chmurze, nie tylko Amazon S3, decyzja o przechowywaniu danych w chmurze publicznej ma wpływ na bezpieczeństwo. Amazon S3 zapewnia szyfrowanie danych w spoczynku i danych w trakcie przesyłania, bez gwarancji zerowej wiedzy lub bez dowodów wiedzy. Organizacje, które chcą mieć pełną kontrolę nad swoimi danymi, powinny wdrożyć szyfrowanie po stronie klienta i przechowywać klucze szyfrowania poza swoją infrastrukturą AWS.
W przypadku komercyjnych alternatyw dla mapowania S3 na lokalny system plików warto sprawdzić produkty ObjectiveFS lub NetApp.
Wreszcie, organizacje, które chcą opracować własne narzędzia do tworzenia kopii zapasowych, albo opierając się na fundamencie zapewnianym przez wiele aplikacji open source, albo zaczynając od zera, powinny rozważyć użycie testu zgodności S3 udostępnionego w ramach projektu Ceph.