Jeśli Twój system opiera się na PostgreSQL i szukasz rozwiązań klastrowych dla wysokiej dostępności, chcemy Cię z wyprzedzeniem poinformować, że jest to złożone zadanie, ale nie niemożliwe do osiągnięcia.
Biorąc pod uwagę wymagania dotyczące odporności na awarie, oto kilka rozwiązań klastrowych o wysokiej dostępności do wyboru, które mogą pomóc.
PostgreSQL nie obsługuje natywnie żadnego rozwiązania klastrowego z wieloma wzorcami, takiego jak MySQL czy Oracle. Niemniej jednak wiele komercyjnych i społecznościowych produktów oferuje tę implementację, w tym replikację i równoważenie obciążenia dla PostgreSQL.
Na początek przejrzyjmy kilka podstawowych pojęć:
Co to jest wysoka dostępność?
Wysoka dostępność odnosi się do czasu, przez jaki usługa jest dostępna i jest zwykle definiowana przez uzgodniony poziom wydajności firmy.
Nadmiarowość jest podstawą wysokiej dostępności; w przypadku incydentu możesz bez problemu kontynuować obsługę i uzyskiwać dostęp do systemów.
Ciągłe odzyskiwanie
W przypadku wystąpienia incydentu, jeśli musisz przywrócić kopię zapasową, a następnie zastosować dzienniki WAL (rejestrowanie z wyprzedzeniem), czas odzyskiwania byłby bardzo długi i nie byłby wysoce dostępny.
Jeśli jednak masz kopie zapasowe i dzienniki zarchiwizowane na serwerze awaryjnym, możesz zastosować dzienniki, gdy się pojawią. Jeśli dzienniki są wysyłane i stosowane co minutę, baza awaryjna byłaby w ciągłym odzyskiwaniu i byłaby przestarzała do produkcji przez co najmniej jedną minutę.
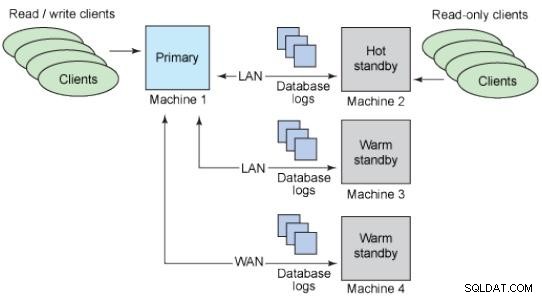
Bazy danych w stanie gotowości
Ideą rezerwowej bazy danych jest przechowywanie kopii produkcyjnej bazy danych, która zawsze zawiera te same dane i jest gotowa do użycia w przypadku incydentu.
Istnieje kilka sposobów klasyfikacji rezerwowej bazy danych.
Ze względu na charakter replikacji:
-
Wstrzymanie fizyczne:bloki dysku są kopiowane.
-
Tryby gotowości logicznej:przesyłanie strumieniowe zmian danych.
Według synchroniczności transakcji:
-
Asynchroniczny:istnieje możliwość utraty danych.
-
Synchroniczne:nie ma możliwości utraty danych; Zatwierdzenia w masterze czekają na odpowiedź trybu gotowości.
Według użycia:
-
Ciepłe czuwanie:nie obsługują połączeń.
-
Gorące czuwanie:obsługa połączeń tylko do odczytu.
Klastry
Klaster to grupa hostów pracujących razem i postrzegana jako jeden. Zapewnia to sposób na osiągnięcie skalowalności poziomej i możliwość przetwarzania większej ilości pracy przez dodanie serwerów.
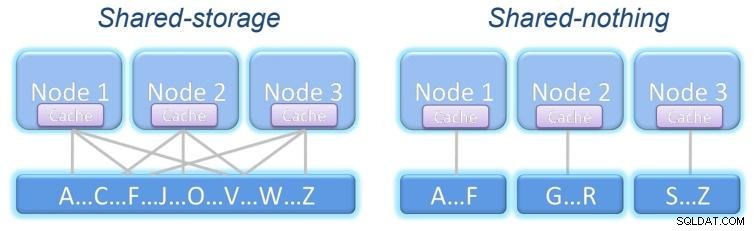
Może wytrzymać awarię węzła i kontynuować transparentną pracę. W zależności od tego, co jest udostępniane, istnieją dwa modele klastrów:
-
Pamięć współdzielona:wszystkie węzły mają dostęp do tej samej pamięci z tymi samymi informacjami.
-
Nic współużytkowane:każdy węzeł ma własną pamięć, która może zawierać te same informacje, co inne węzłów, w zależności od struktury naszego systemu.
Przyjrzyjmy się teraz niektórym opcjom klastrowania, które mamy w PostgreSQL.
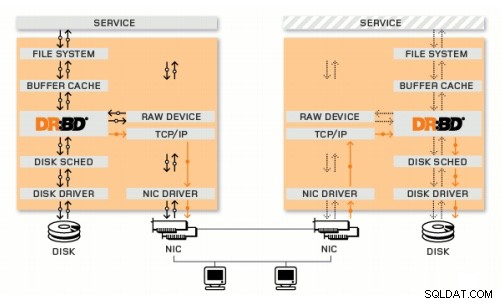
Rozproszone, replikowane urządzenie blokowe
DRBD to moduł jądra Linux, który implementuje synchroniczną replikację bloków przy użyciu sieci. W rzeczywistości nie implementuje klastra i nie obsługuje przełączania awaryjnego ani monitorowania. Potrzebujesz do tego dodatkowego oprogramowania, na przykład Corosync + Pacemaker + DRBD.
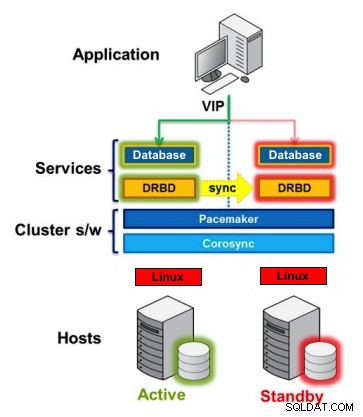
Przykład:
-
Corosync:obsługuje wiadomości między hostami.
-
Rozrusznik:uruchamia i zatrzymuje usługi, upewniając się, że działają tylko na jednym hoście.
-
DRBD:Synchronizuje dane na poziomie urządzeń blokowych.
ClusterControl
ClusterControl to bezagentowe oprogramowanie do zarządzania i automatyzacji klastrów baz danych. Pomaga wdrażać, monitorować, zarządzać i skalować serwer/klaster bazy danych bezpośrednio z interfejsu użytkownika. Może obsługiwać większość zadań administracyjnych wymaganych do utrzymania serwerów baz danych lub klastrów.
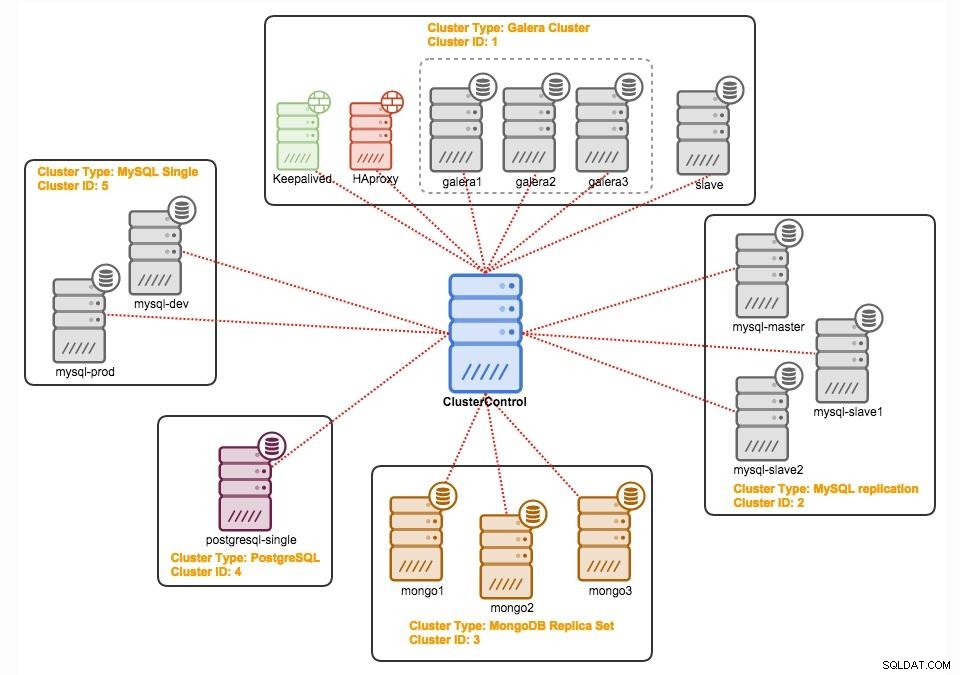
Dzięki ClusterControl możesz:
-
Wdrażaj samodzielne, replikowane lub zgrupowane bazy danych na wybranym stosie technologicznym.
-
Automatyzuj przełączanie awaryjne, odzyskiwanie i codzienne zadania w jednolity sposób w wielojęzycznych bazach danych i infrastrukturach dynamicznych.
-
Twórz pełne lub przyrostowe kopie zapasowe ręcznie lub zaplanuj je.
-
Prowadź ujednolicone i kompleksowe monitorowanie w czasie rzeczywistym całej infrastruktury bazy danych i serwerów.
-
Łatwo dodaj lub usuń węzeł za pomocą jednej akcji.
-
Klonuj swój klaster do innego centrum danych/dostawcy chmury
Jeśli masz incydent dotyczący PostgreSQL, Twój węzeł gotowości może zostać automatycznie przeniesiony do poziomu podstawowego.
To kompletne narzędzie, które oferuje pełne zarządzanie cyklem życia i automatyzację za pomocą jednej szyby. ClusterControl zapewnia również bezpłatną 30-dniową wersję próbną, dzięki czemu można ją ocenić bez żadnych zobowiązań.
Rubyrep
Rubyrep to rozwiązanie zapewniające asynchroniczną, multi-master, wieloplatformową replikację (zaimplementowaną w Ruby lub JRuby) i multi-DBMS (MySQL lub PostgreSQL).
Opiera się na wyzwalaczach i nie obsługuje DDL, użytkowników ani grantów. Jej głównym celem jest prostota użytkowania i administracji.
Niektóre funkcje obejmują:
-
Prosta konfiguracja
-
Prosta instalacja
-
Niezależne od platformy, niezależne od projektu tabeli.
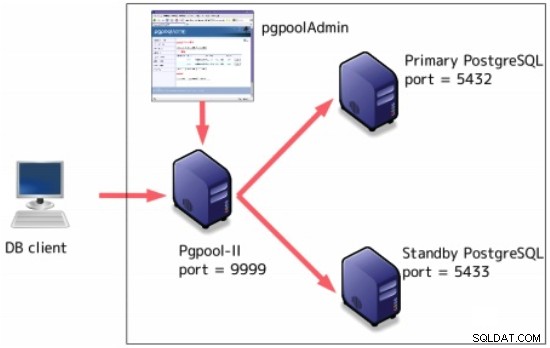
Pgpool-II
Pgpool-II to oprogramowanie pośrednie, które działa między serwerami PostgreSQL i klientem bazy danych PostgreSQL.
Niektóre funkcje obejmują:
-
Pula połączeń
-
Replikacja
-
Równoważenie obciążenia
-
Automatyczne przełączanie awaryjne
-
Zapytania równoległe
Może być skonfigurowany na szczycie replikacji strumieniowej:
Bucardo
Bucardo oferuje asynchroniczną replikację kaskadową master-slave, opartą na wierszach, z wykorzystaniem wyzwalaczy i kolejkowania w bazie danych oraz asynchroniczną replikację master-master, opartą na wierszach, z wykorzystaniem wyzwalaczy i niestandardowego rozwiązywania konfliktów.
Bucardo wymaga dedykowanej bazy danych i działa jako demon Perla, który komunikuje się z tą bazą danych i wszystkimi innymi bazami danych zaangażowanymi w replikację. Może działać jako multi-master lub multi-slave.
Replikacja typu master-slave obejmuje co najmniej jedno źródło prowadzące do jednego lub większej liczby celów. Źródłem musi być PostgreSQL, ale celami mogą być PostgreSQL, MySQL, Redis, Oracle, MariaDB, SQLite lub MongoDB.
Niektóre funkcje obejmują:
-
Równoważenie obciążenia
-
Slave nie są ograniczone i można je zapisywać
-
Replikacja częściowa
-
Replikacja na żądanie (zmiany mogą być przesyłane automatycznie lub w razie potrzeby)
-
Urządzenia podrzędne można "wstępnie ogrzać" w celu szybkiej konfiguracji
Wady:
-
Nie można obsłużyć DDL
-
Nie można obsługiwać dużych obiektów
-
Nie można przyrostowo replikować tabel bez unikalnego klucza
-
Nie będzie działać w wersjach starszych niż Postgres 8
Postgres-XC
Postgres-XC to projekt typu open source, który zapewnia skalowalne do zapisu, synchroniczne, symetryczne i przejrzyste rozwiązanie klastrowe PostgreSQL. Jest to zbiór ściśle powiązanych komponentów bazy danych, które można zainstalować na więcej niż jednym sprzęcie lub maszynie wirtualnej.
Skalowalny zapis oznacza, że Postgres-XC może być skonfigurowany z dowolną liczbą serwerów baz danych i obsługiwać znacznie więcej zapisów (aktualizacji instrukcji SQL) w porównaniu z tym, co może zrobić pojedynczy serwer bazy danych.
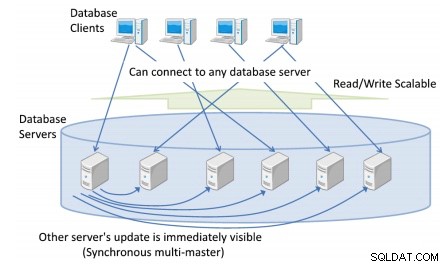
Możesz mieć więcej niż jeden serwer bazy danych, z którym łączą się klienci, zapewniając pojedynczy, spójny widok bazy danych obejmujący cały klaster.
Każda aktualizacja bazy danych z dowolnego serwera bazy danych jest natychmiast widoczna dla wszystkich innych transakcji działających na różnych masterach.
Przezroczysty oznacza, że nie musisz się martwić o to, jak Twoje dane są przechowywane w więcej niż jednym serwerze bazy danych wewnętrznie.
Możesz skonfigurować Postgres-XC, aby działał na wielu serwerach. Twoje dane są przechowywane w sposób rozproszony, partycjonowany lub replikowany, zgodnie z wyborem przez Ciebie dla każdej tabeli. Kiedy wysyłasz zapytania, Postgres-XC określa, gdzie przechowywane są dane docelowe i wysyła odpowiednie zapytania do serwerów zawierających dane docelowe.
Cytus
Citus to bezpośredni zamiennik PostgreSQL z wbudowanymi funkcjami wysokiej dostępności, takimi jak auto-sharding i replikacja. Citus dzieli bazę danych na fragmenty i replikuje wiele kopii każdego fragmentu w klastrze węzłów towarowych. Jeśli węzeł w klastrze stanie się niedostępny, Citus w sposób przezroczysty przekierowuje wszelkie zapisy lub zapytania do jednego z pozostałych węzłów, w których znajduje się kopia uszkodzonego fragmentu.
Niektóre funkcje obejmują:
-
Automatyczne dzielenie na fragmenty logiczne
-
Wbudowana replikacja
-
Replikacja z obsługą centrum danych na potrzeby odzyskiwania po awarii
-
Tolerancja błędów w połowie zapytania z zaawansowanym równoważeniem obciążenia
Możesz wydłużyć czas pracy swoich aplikacji czasu rzeczywistego obsługiwanych przez PostgreSQL i zminimalizować wpływ awarii sprzętu na wydajność. Możesz to osiągnąć dzięki wbudowanym narzędziom o wysokiej dostępności, które minimalizują kosztowną i podatną na błędy ręczną interwencję.
PostgresXL
PostgresXL to rozwiązanie do klastrowania typu „shared-nothing” z wieloma wzorcami, które może transparentnie dystrybuować tabelę na zestaw węzłów i wykonywać zapytania równolegle z tymi węzłami. Posiada dodatkowy składnik o nazwie Global Transaction Manager (GTM) zapewniający globalnie spójny widok klastra.
PostgresXL to skalowalny poziomo klaster baz danych SQL typu open source, wystarczająco elastyczny, aby obsługiwać różne obciążenia bazy danych:
-
Obciążenia wymagające intensywnego zapisu OLTP
-
Inteligencja biznesowa wymagająca równoległości MPP
-
Operacyjny magazyn danych
-
Sklep klucz-wartość
-
Geoprzestrzenne GIS
-
Środowiska o mieszanym obciążeniu
-
Środowiska hostowane przez dostawców z wieloma dzierżawcami

Komponenty:
-
Globalny monitor transakcji (GTM):Globalny monitor transakcji zapewnia spójność transakcji w całym klastrze.
-
Koordynator:Koordynator zarządza sesjami użytkowników i współdziała z GTM i węzłami danych.
-
Węzeł danych:Węzeł danych to miejsce, w którym przechowywane są rzeczywiste dane.
Zawijanie
Dostępnych jest wiele innych produktów do implementacji środowiska wysokiej dostępności dla PostgreSQL, ale musisz uważać na:
-
Nowe produkty, niewystarczająco przetestowane
-
Przerwane projekty
-
Ograniczenia
-
Koszty licencji
-
Bardzo złożone implementacje
-
Niebezpieczne rozwiązania
Wybierając rozwiązanie, z którego będziesz korzystać, weź pod uwagę również swoją infrastrukturę. Jeśli masz tylko jeden serwer aplikacji, bez względu na to, jak bardzo skonfigurowałeś wysoką dostępność baz danych, jeśli serwer aplikacji ulegnie awarii, jesteś niedostępny. Musisz dobrze przeanalizować pojedyncze punkty awarii w infrastrukturze i spróbować je rozwiązać.
Biorąc pod uwagę te punkty, możesz znaleźć rozwiązanie klastrowe o wysokiej dostępności, które dostosuje się do Twoich potrzeb i wymagań, bez bólu głowy. Jeśli szukasz dodatkowych zasobów HA dla swojej bazy danych PG, zapoznaj się z tym postem dotyczącym wdrażania PostgreSQL w celu zapewnienia wysokiej dostępności.
Aby być na bieżąco z rozwiązaniami do zarządzania bazami danych i najlepszymi praktykami, śledź nas na Twitterze i LinkedIn oraz subskrybuj nasz biuletyn.



